Supervised vs. Unsupervised Learning: Understanding the differences and capabilities of each ML approach
- Supervised vs. unsupervised learning serve different purposes: supervised learning uses labeled data to make precise predictions and classifications, while unsupervised learning finds hidden patterns in raw, unlabeled data, making each better suited for different business goals.
- Modern ML blends both approaches: techniques like semi-supervised and self-supervised learning combine the strengths of each paradigm.
- The real challenge is building systems: successful enterprise ML depends on orchestrating both approaches within reliable data pipelines, strong governance, and continuous evaluation throughout the model lifecycle.
Machine learning systems learn from data to make predictions, classify information or discover patterns that would be difficult for humans to identify manually.
What is supervised learning?
In supervised learning, models are trained using labeled data, where each input is paired with a known output. The model learns by comparing its predictions against these correct answers and iteratively reducing error.
At the core of this process are machine learning models that learn explicit relationships between features and outcomes. The presence of labeled data provides clear guidance, making supervised learning well-suited for problems where accuracy, traceability and repeatability are essential.
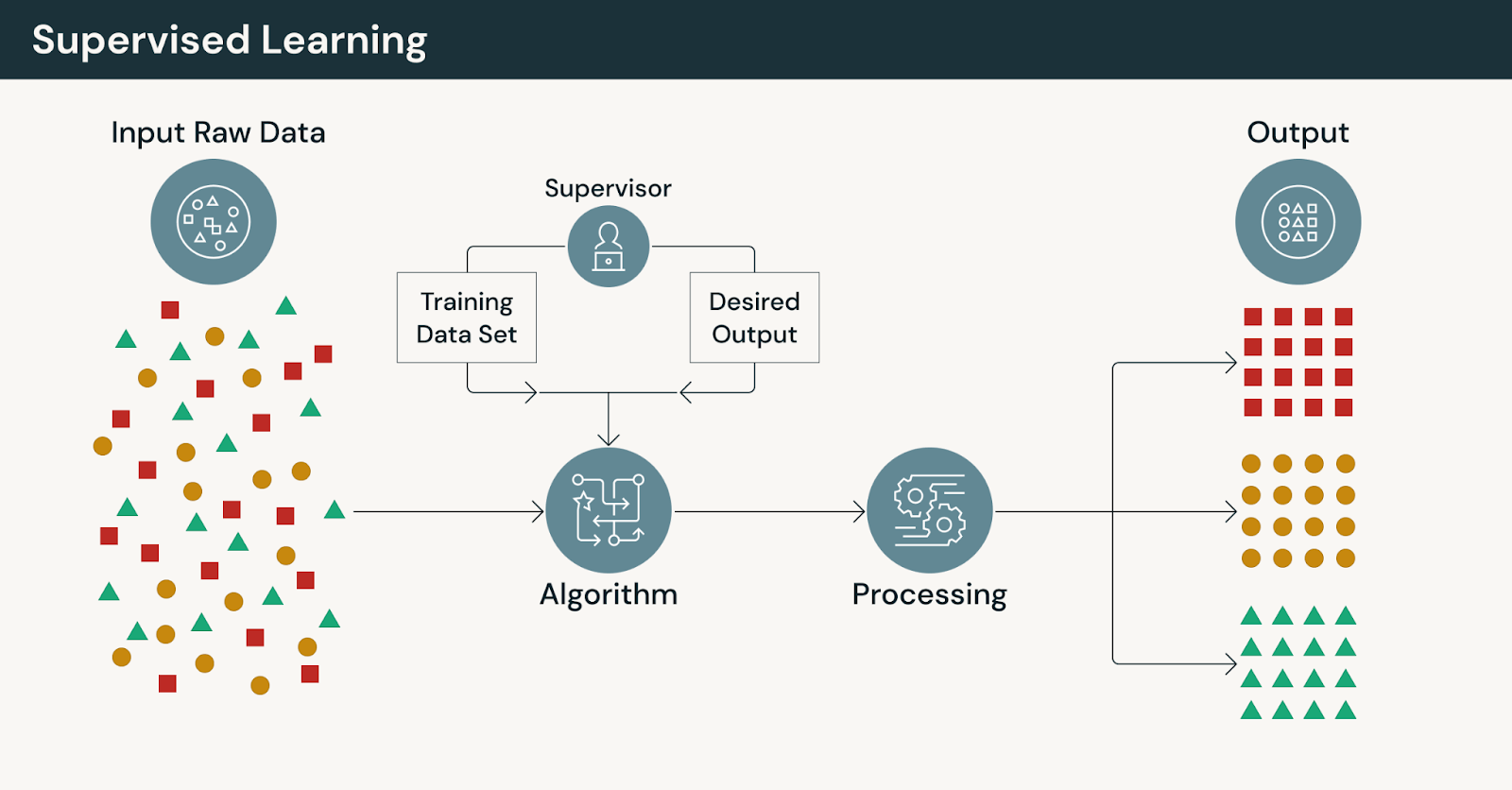
How supervised learning works
A typical supervised learning workflow includes:
- Collecting historical training data with known outcomes
- Preparing and validating labeled training datasets
- Engineering features that capture relevant signals
- Training and evaluating models against ground truth
- Deploying models and tracking performance over time
This workflow depends on the availability and quality of labels — a constraint that often becomes more pronounced as data volume grows.
Types of supervised learning
Supervised learning problems generally fall into two categories:
- Classification: Assigning input data to predefined classes, such as spam versus legitimate email or positive versus negative sentiment.
- Regression: Predicting continuous values, such as demand forecasts, pricing, or risk scores. Transportation companies use regression models to predict flight times based on historical route performance, seasonal patterns and operational factors, helping optimize scheduling and set accurate customer expectations.
In both cases, model performance can be measured directly against known outcomes, which simplifies evaluation and accountability.
Common supervised learning applications
Supervised machine learning is commonly used for:
- Email filtering and content moderation
- Sentiment analysis in customer feedback
- Forecasting and predictive analytics
- Image and document classification
Many natural language processing applications rely on supervised fine-tuning to adapt general-purpose models to domain-specific tasks, policies or vocabularies.
Supervised learning across industries
Supervised learning applications span virtually every sector, with some use cases having become foundational to modern digital infrastructure.
Cybersecurity: Spam detection systems analyze billions of emails daily, using supervised models trained on labeled examples of legitimate and malicious messages. Modern spam detection goes beyond simple keyword matching, incorporating sender reputation, message structure, attachment analysis and behavioral patterns.
Healthcare and life sciences: Supervised learning involves training predictive models on labeled biomedical and genomic data to identify patterns associated with disease-related variants and therapeutic targets. By applying these models within a scalable analytics platform, researchers can quantify relationships between genetic features and clinical outcomes, enabling more accurate prediction of drug targets and accelerating hypothesis-driven discovery.
Financial services: Supervised learning was used to train risk and fraud detection models on labeled historical transaction data, enabling the system to distinguish between legitimate and suspicious activity. By learning from known outcomes—such as confirmed fraud cases or validated customer behaviors—the models improved real-time detection accuracy while reducing false positives. Deployed within a scalable data platform, these supervised models supported faster decision-making and more resilient financial risk management.
Retail and consumer goods: Using labeled historical sales, pricing, and promotional data, predictive models were trained to forecast demand and optimize inventory decisions at scale. By learning from known outcomes—such as prior product movement and regional demand patterns—the system improved forecast accuracy across thousands of locations. This enabled more precise replenishment, reduced stockouts, and tighter alignment between supply chain operations and customer demand.
Customer experiences: Predictive models were trained on unified and labeled customer interaction and profile data to learn patterns that help segment audiences and predict customer behaviors. These supervised models enabled more accurate customer insights, supporting targeted marketing and personalization strategies. This resulted in faster delivery of actionable insights that improve customer engagement and experience across channels.
Media and entertainment: Labeled gameplay, engagement, and behavioral data were used to train predictive models that identify patterns in player activity and content interaction. By learning from known outcomes—such as churn signals, in-game behaviors, and community trends—the system enabled more accurate forecasting and faster content optimization. This supported improved player experiences, better live operations decisions, and data-driven development across a global gaming ecosystem.
Each application shares a common requirement: reliable labeled training data that accurately represents the problem space and ongoing monitoring to detect when model performance degrades.
What is unsupervised learning?
Rather than learning from labeled examples, unsupervised machine learning analyzes unlabeled data to identify patterns, structure or relationships without predefined targets.
This makes unsupervised learning especially valuable early in ML projects, when teams may not yet know what questions to ask — or when labeling data is impractical or cost-prohibitive.
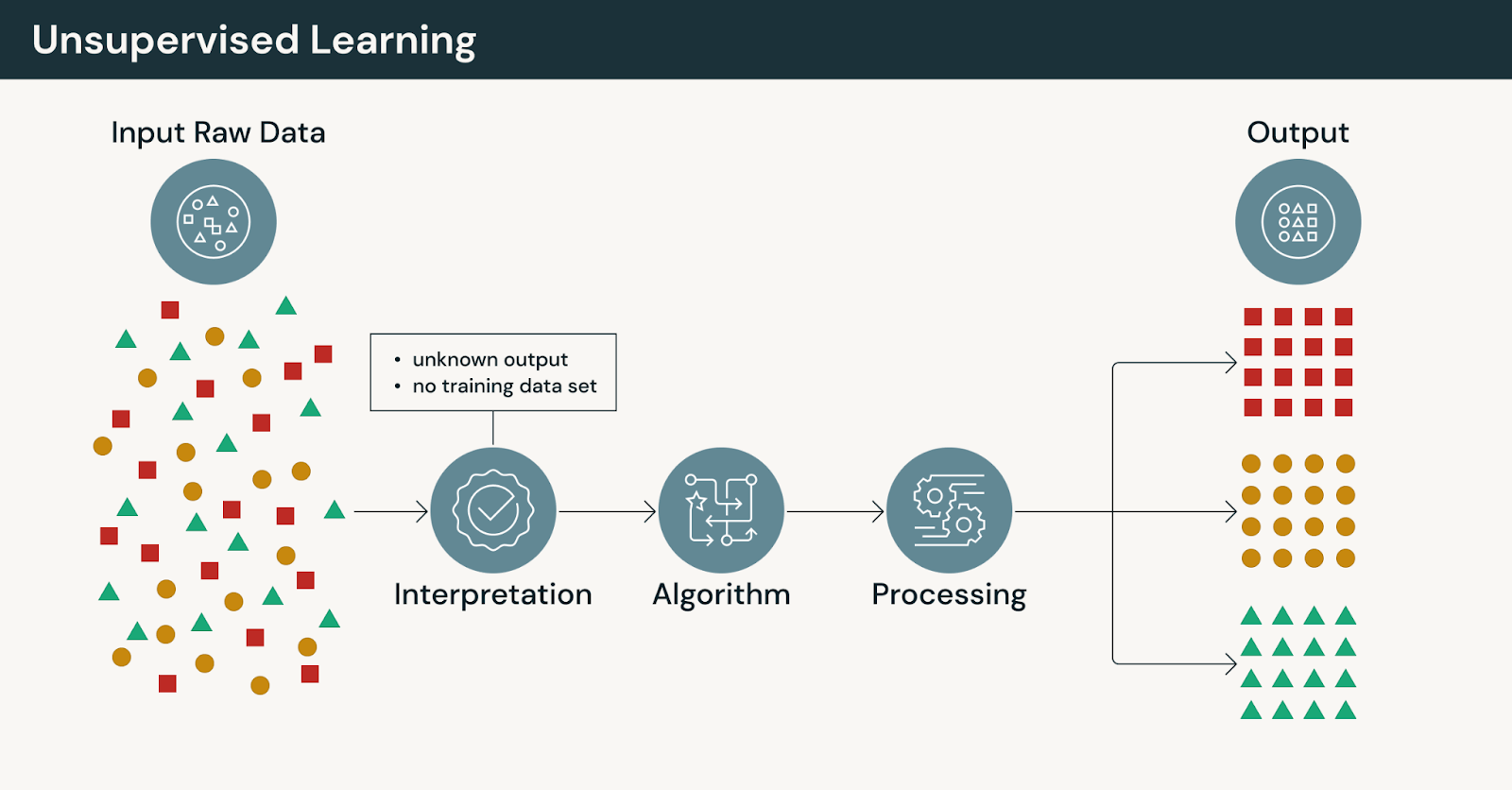
How unsupervised learning works
In unsupervised learning:
- Models operate without explicit human-provided labels
- Algorithms group, compress, or organize data based on similarity
- Outputs require interpretation and validation by domain experts
Because there are no correct answers, unsupervised learning emphasizes exploration rather than prediction.
Types of unsupervised learning
Common unsupervised techniques include:
- Clustering: Grouping similar data points to reveal structure
- Dimensionality reduction: Simplifying complex datasets for analysis
- Association rule learning: Identifying relationships between variables
Many of these methods rely on clustering algorithms to surface patterns that were not explicitly defined in advance.
Common unsupervised learning applications
Unsupervised machine learning is widely used for:
- Customer segmentation strategies in marketing and personalization, using clustering to group similar data points by behavior, preferences and value rather than predetermined categories
- Anomaly detection systems for fraud prevention and operational monitoring
- Exploratory data analysis and behavioral pattern discovery
- Large-scale similarity search and grouping
- Market basket analysis and product recommendation systems, where algorithms like the Apriori algorithm discover purchase patterns and product associations without being told which items should be related
As organizations accumulate more raw data, unsupervised learning offers a way to extract value without waiting for exhaustive labeling efforts.
Key differences between supervised and unsupervised learning
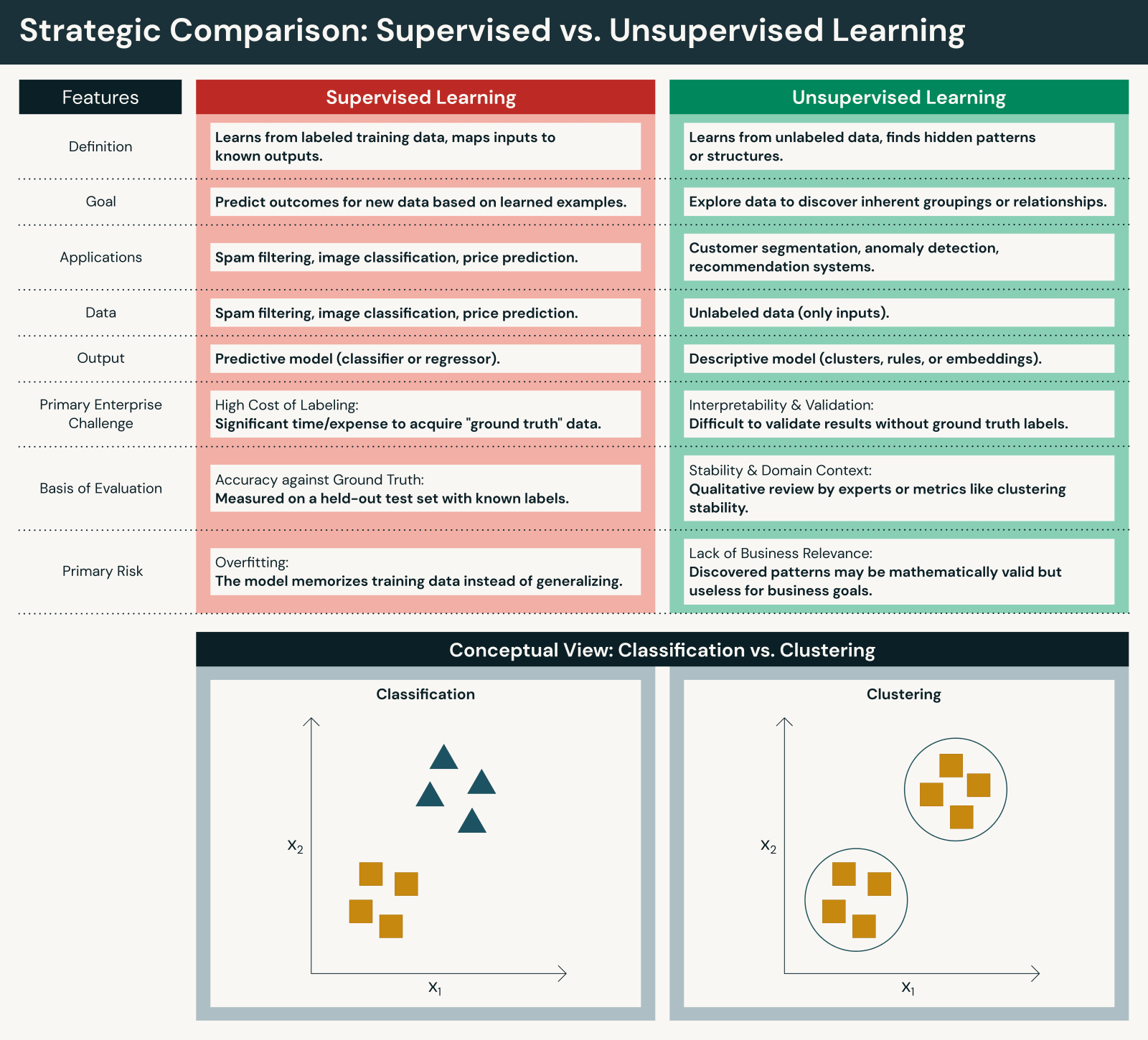
Although both approaches are foundational, they differ in important ways:
Data and human effort
- Supervised learning requires labeled datasets, often created through manual annotation or expert review. While supervised machine learning requires significant human intervention for labeling, this human intervention ensures accuracy aligns with business objectives.
- Unsupervised learning works directly on raw data, reducing upfront preparation but increasing interpretation effort. Unsupervised machine learning reduces human intervention during training but requires human intervention for interpreting results.
Objectives
- Supervised learning focuses on prediction and classification against known outcomes to predict outcomes with precision.
- Unsupervised learning focuses on discovery and insight generation to uncover patterns in data.
Evaluation and transparency
- Supervised models can be evaluated using clear performance metrics against correct answers (accuracy, precision, recall, F1, RMSE, etc.).
- Unsupervised learning models require indirect evaluation and domain context to assess usefulness (silhouette scores, elbow method, domain expert validation, etc.).
Scalability
- Supervised learning often scales more slowly due to labeling constraints.
- Unsupervised learning scales naturally with data volume but may produce noisier results.
In enterprise environments, these key differences drive teams toward hybrid approaches rather than exclusive choices.
The agentic AI playbook for the enterprise

Semi-supervised and self-supervised learning
Modern ML systems increasingly blend paradigms:
Semi-supervised learning combines a small, labeled dataset with a much larger pool of unlabeled data, reducing labeling costs while retaining predictive accuracy.
Self-supervised learning goes further by allowing models to generate their own training signals from raw data. This approach underpins many modern foundation models and has shifted supervised learning into a refinement role rather than a starting point.
These techniques enable organizations to:
- Leverage existing data assets at scale
- Adapt more quickly to new data distributions
- Reduce dependence on manual labeling
It's worth noting that supervised and unsupervised learning don't represent the complete machine learning landscape. Reinforcement learning is a third major paradigm in which agents learn optimal behaviors through trial-and-error interactions with environments, receiving rewards or penalties for their actions. While reinforcement learning falls outside the supervised vs unsupervised spectrum, modern systems increasingly combine all three approaches depending on task requirements.
When to use supervised vs. unsupervised learning
In practice, the right choice depends on data, goals, and operational constraints.
Assess your data
- Do you have reliable labels today?
- Can you maintain labeling quality as data grows?
- How often does your data change?
Define your objective
- Predict outcomes? Supervised learning fits.
- Explore unknown structure? Unsupervised learning is often the right entry point.
Plan for the full lifecycle
Regardless of approach, successful systems depend on reliable data engineering pipelines that move data from ingestion through training and into production consistently.
Many teams begin with unsupervised exploration, then introduce supervised learning once targets and metrics are well defined.
Why unified data and AI governance is critical for an enterprise ML strategy
As ML systems scale, enterprises must manage access, lineage, compliance and accountability.
This is where unified data governance becomes critical. Governing data and models consistently across workflows ensures that insights are trustworthy and systems remain auditable as they evolve.
Addressing common questions
Is linear regression supervised or unsupervised?
Linear regression is supervised learning because it requires labeled output values.
What is the main difference between supervised and unsupervised learning?
Supervised learning predicts known outcomes using labeled data. Unsupervised learning discovers patterns in unlabeled data.
What you need to know going forward
Several trends are reshaping enterprise ML:
- Self-supervised learning dominates foundation model training.
- Supervised learning increasingly serves as a precision layer.
- Clustering and embeddings are becoming core enterprise capabilities.
- Evaluation and governance are growing in importance as unlabeled data use expands.
These shifts reinforce the need to think in systems, not silos.
Challenges and limitations
Both supervised and unsupervised learning play essential roles in enterprise ML, but each comes with trade-offs that teams must plan for early.
Supervised learning challenges
Data requirements are often the biggest constraint. Creating labeled datasets can be time-consuming and expensive, especially when labeling requires domain expertise. In many cases, model accuracy is directly tied to label quality, making inconsistent or biased annotations a serious risk.
Supervised models also face overfitting risks. When models learn training data too closely, they may perform well in evaluation but fail to generalize to new data or unseen data. Common mitigations include cross-validation, regularization techniques, and expanding training datasets to better reflect real-world variability.
Scalability concerns emerge as data volumes grow. Human-in-the-loop labeling does not scale linearly, and manual processes can become bottlenecks for large or fast-moving projects. Without careful planning, supervised workflows can struggle to keep pace with business demands.
Unsupervised learning challenges
Unsupervised learning introduces a different set of issues, starting with interpretation difficulty. Clusters or patterns may not have an obvious meaning without domain context, and discovered structure does not always align with business objectives. Extracting value often requires close collaboration between data scientists and subject matter experts.
Validation complexity is another challenge. With no ground truth labels, it can be difficult to objectively assess model quality. Teams often rely on proxy metrics, business alignment or comparative evaluation across multiple algorithms to build confidence in results.
Finally, algorithm selection requires experimentation. Outcomes can vary significantly based on parameter choices, distance measures or preprocessing steps, making iteration unavoidable.
Machine learning best practices
Across both approaches, several practices consistently improve outcomes:
- Ensure high-quality input data, including proper handling of missing values and outliers
- Start with a clear problem definition before selecting an approach
- Implement data quality checks and validation processes early
- Use appropriate evaluation metrics for each paradigm
- Begin with exploratory data analysis before committing to production workflows
Reliable data engineering solutions provide the foundation for applying these practices consistently, helping teams move from experimentation to production with greater confidence.
What you need to know in 2026
Several shifts are already reshaping enterprise ML practice.
1. Self-supervised pretraining now underpins most modern foundation models
Most state-of-the-art models — including large language models, computer vision systems and multimodal architectures — are now trained primarily using self-supervised learning. Rather than relying on human-labeled datasets, these models generate their own training signals from raw data, such as predicting the next token in a sequence or reconstructing masked portions of an input.
This shift reflects a practical reality: enterprises possess vast amounts of unlabeled data, but labeling at scale is costly and slow. Self-supervised learning allows organizations to extract value from existing data assets while building representations that can later be adapted to specific tasks.
2. Supervised fine-tuning has moved into a refinement role
Supervised learning has not disappeared — but its role has changed. Instead of serving as the primary training mechanism, supervised fine-tuning is increasingly used to refine, align and validate models for well-defined business objectives.
This approach enables teams to focus labeling efforts where precision matters most, such as regulatory requirements, safety constraints or domain-specific accuracy, while avoiding unnecessary labeling earlier in the pipeline.
3. Embeddings are now core enterprise capabilities
Embeddings have become core enterprise infrastructure. Foundation models increasingly output vector embeddings that capture semantic meaning across text, images, audio, and structured data. These embeddings power similarity search, retrieval, personalization, anomaly detection, and recommendation systems at scale.
Clustering and other similarity-based methods are important—but they are downstream applications of embeddings rather than peer paradigms. The strategic shift is not toward clustering itself, but toward embedding-centric architectures that enable unified search, retrieval, and reasoning across enterprise data.
As organizations operationalize AI, embeddings become connective tissue between self-supervised pretraining, supervised fine-tuning, and downstream applications. They provide a common representational layer that supports both exploration and precision workflows within modern, unified data platforms.
Build systems, not sides
Supervised and unsupervised learning solve different problems — and modern ML systems need both. Supervised machine learning excels when you have labeled data and need precise, accountable predictions or classifications. Unsupervised machine learning thrives when the goal is discovery, helping teams uncover patterns and insights in raw data without predefined outputs. When labeled data is limited, semi supervised learning approaches bridge the gap by combining both paradigms.
The real challenge is not choosing between supervised vs unsupervised learning, but building systems that can combine approaches, evolve over time and operate reliably in production. Effective teams start by assessing their data availability, clarifying whether their primary goal is prediction or exploration, and evaluating the resources required to support each approach.
Machine learning strategies are rarely static. Unsupervised exploration often informs later supervised model development, while supervised fine-tuning brings precision and validation to systems built on broader representations. Over time, insights must flow into business intelligence and analytics where they can inform decisions and drive outcomes.
To go deeper, explore these resources:
- A Compact Guide to Fine-Tuning and Pre-Training LLMs — Learn techniques for fine-tuning and pre-training your LLM
Get the guide - The Big Book of Generative AI — Best practices for building production-quality GenAI applications
Download - The Big Book of Machine Learning Use Cases — Get everything you need to put machine learning to work
Read now
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.