Large Language Models
Accelerate innovation using generative AI and large language models with Databricks

What are large language models?
Large language models (LLMs) are machine learning models that are very effective at performing language-related tasks such as translation, answering questions, chat and content summarization, as well as content and code generation. LLMs distill value from huge datasets and make that “learning” accessible out of the box. Databricks makes it simple to access these LLMs to integrate into your workflows as well as platform capabilities to augment, fine-tune and pre-train your own LLMs using your own data for better domain performance.

Natural language processing with LLMs
S&P Global uses large language models on Databricks to better understand the key differences and similarities in companies’ filings, helping asset managers build a more diverse portfolio.
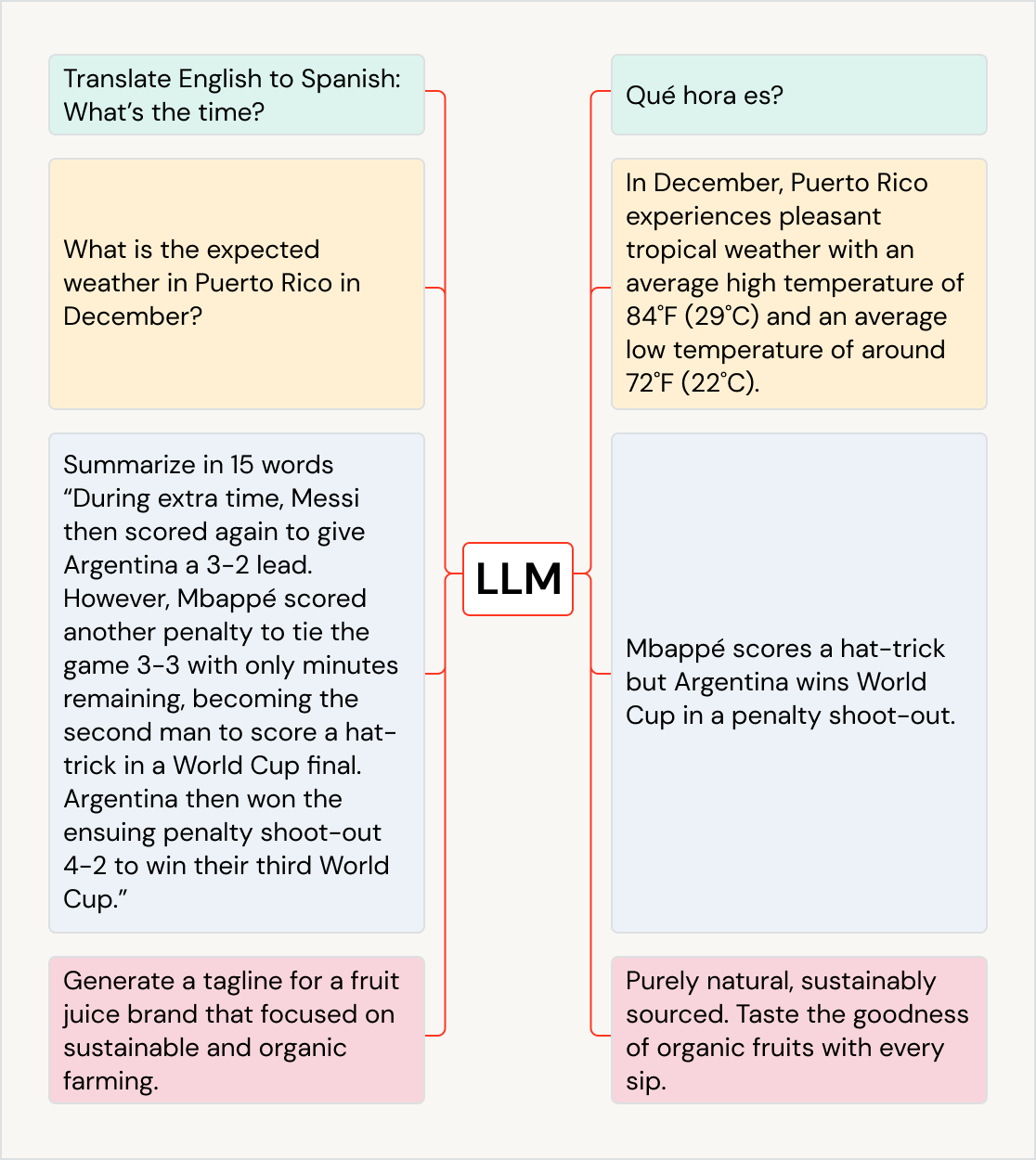
Leverage LLMs for a variety of use cases
LLMs can drive business impact across use cases and industries — translate text into other languages, improve customer experience with chatbots and AI assistants, organize and classify customer feedback to the right departments, summarize large documents, such as earnings calls and legal documents, create new marketing content, and generate software code from natural language. They can even be used to feed into other models, such as those that generate art. Some popular LLMs are the GPT family of models (e.g., ChatGPT), BERT, Llama, MPT and Anthropic.
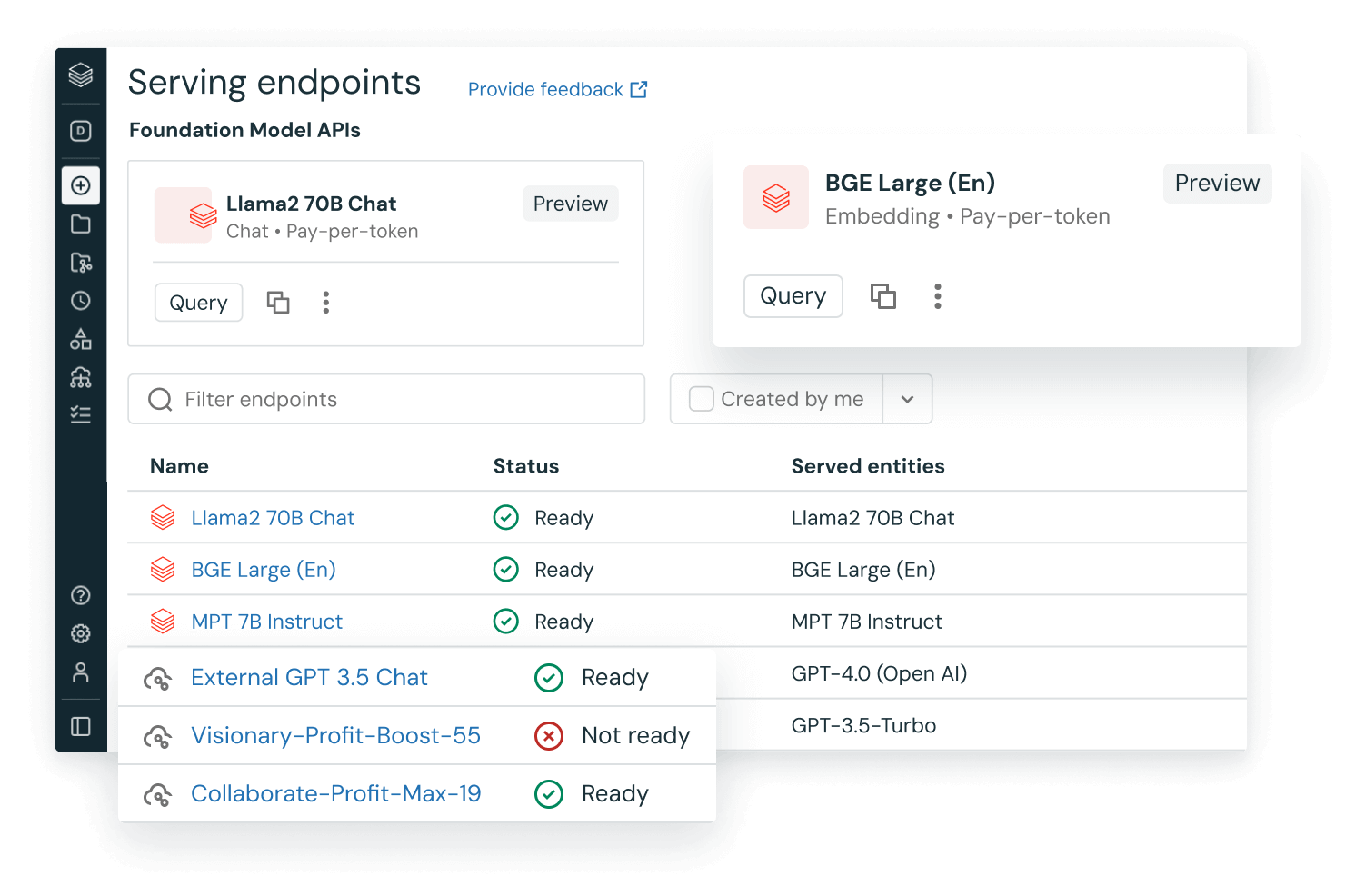
Use generative AI and large language models
Databricks allows you to start with an existing large language model like Llama 2, MPT, BGE, OpenAI or Anthropic and augment or fine-tune it with your enterprise data or build your own custom LLM from scratch through pre-training. Any existing LLMs can be deployed, governed, queried and monitored. We make it easy to extend these models using techniques like retrieval augmented generation (RAG), parameter-efficient fine-tuning (PEFT) or standard fine-tuning.
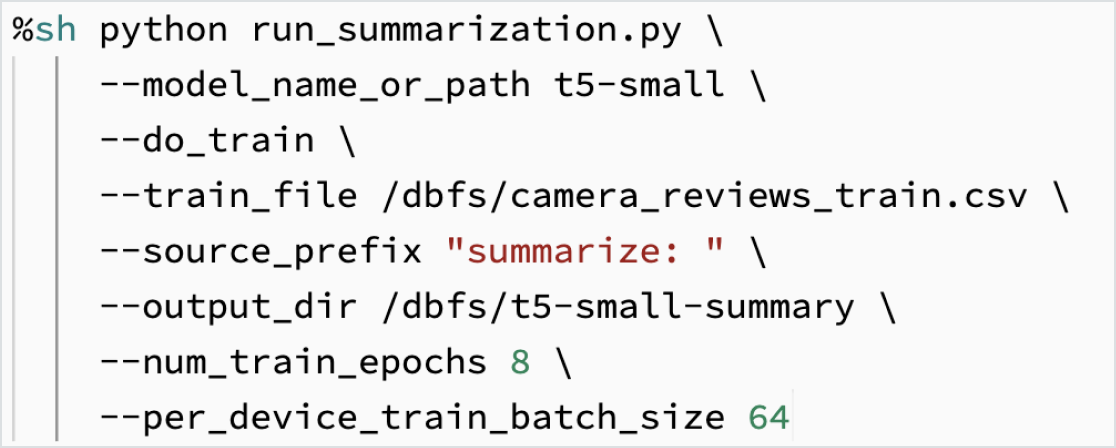
Fine-tune LLMs using your data
Customize a model on your data for your specific task. With the support of open source tooling, such as Hugging Face and DeepSpeed, you can quickly and efficiently take a foundation LLM and start training with your own data to have more accuracy for your domain and workload. This also gives you control to govern the data used for training so you can make sure you’re using AI responsibly.

Pre-train your own custom LLM
Build your own LLM model from scratch with Databricks Pre-training to ensure the foundational knowledge of the model is tailored to your specific domain. The result is a custom model that is uniquely differentiated and trained with your organization’s unique data. Databricks Pre-training is an optimized training solution that can build new multibillion-parameter LLMs in days with up to 10x lower training costs.
Built-in LLMOps (MLOps for LLMs)
Use built-in and production-ready MLOps with Managed MLflow for model tracking, management and deployment. Once the model is deployed, you can monitor things like latency, data drift and more with the ability to trigger retraining pipelines — all on the same unified Databricks Data Intelligence Platform for end-to-end LLMOps.
Data and models on a unified platform
Most models will be trained more than once, so having the training data on the same ML platform will become crucial for both performance and cost. Training LLMs on the Data Intelligence Platform gives you access to first-rate tools and compute — within an extremely cost-effective data lake — and lets you continue to retrain models as your data evolves over time.