Concentre-se nas cargas de trabalho de dados, não na infraestrutura
Spark totalmente gerenciado e sem versão para todas as suas cargas de trabalho de dados e IA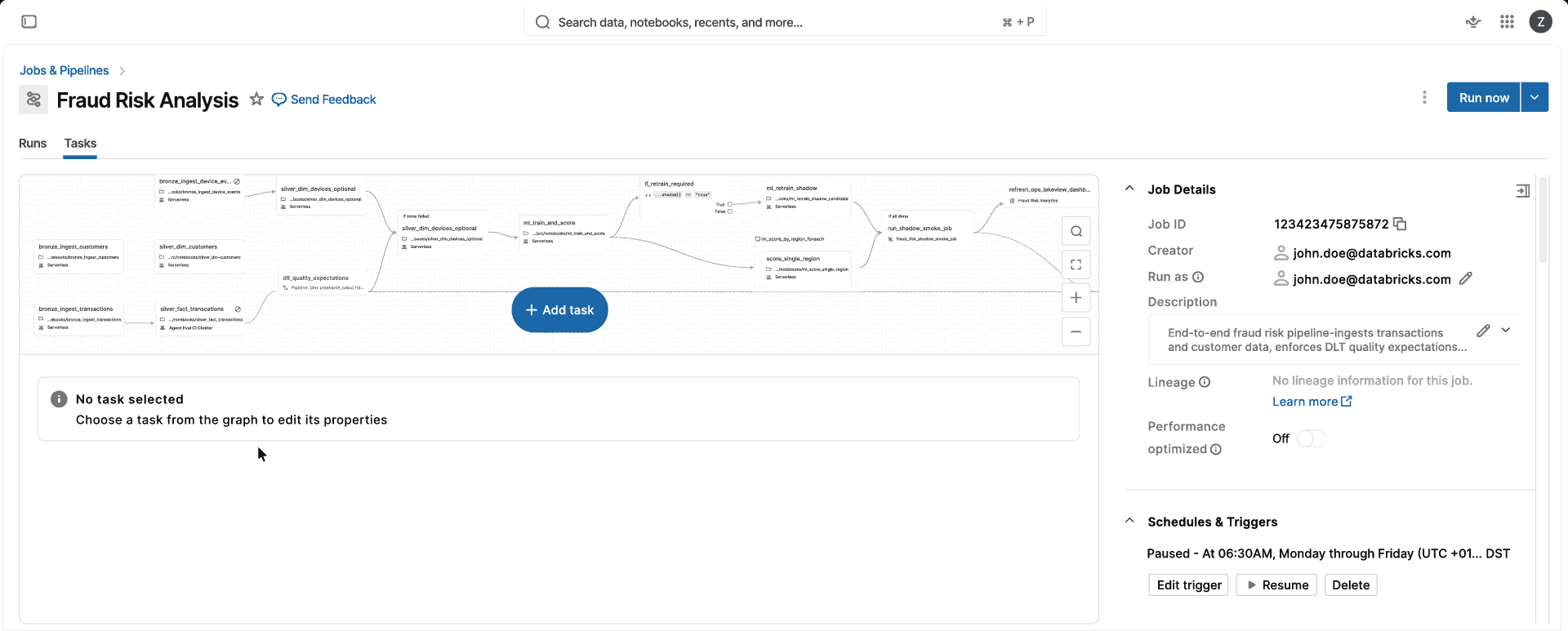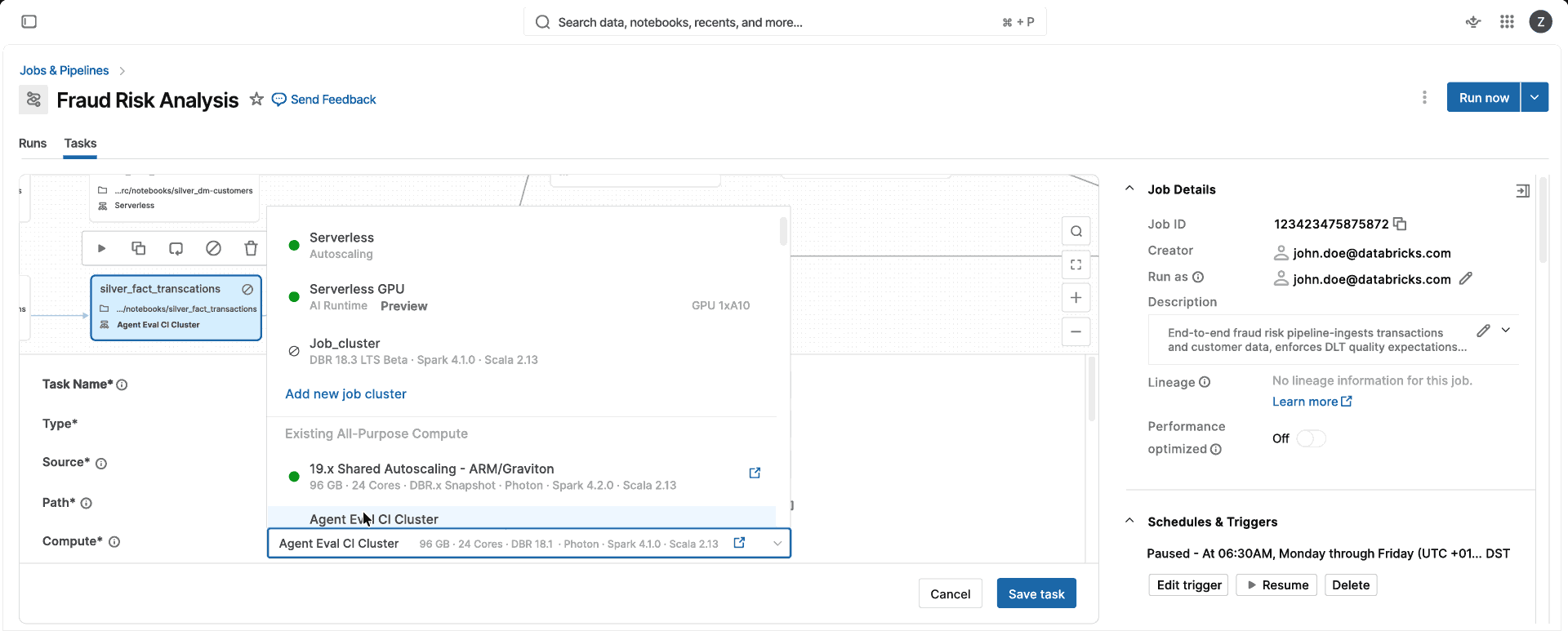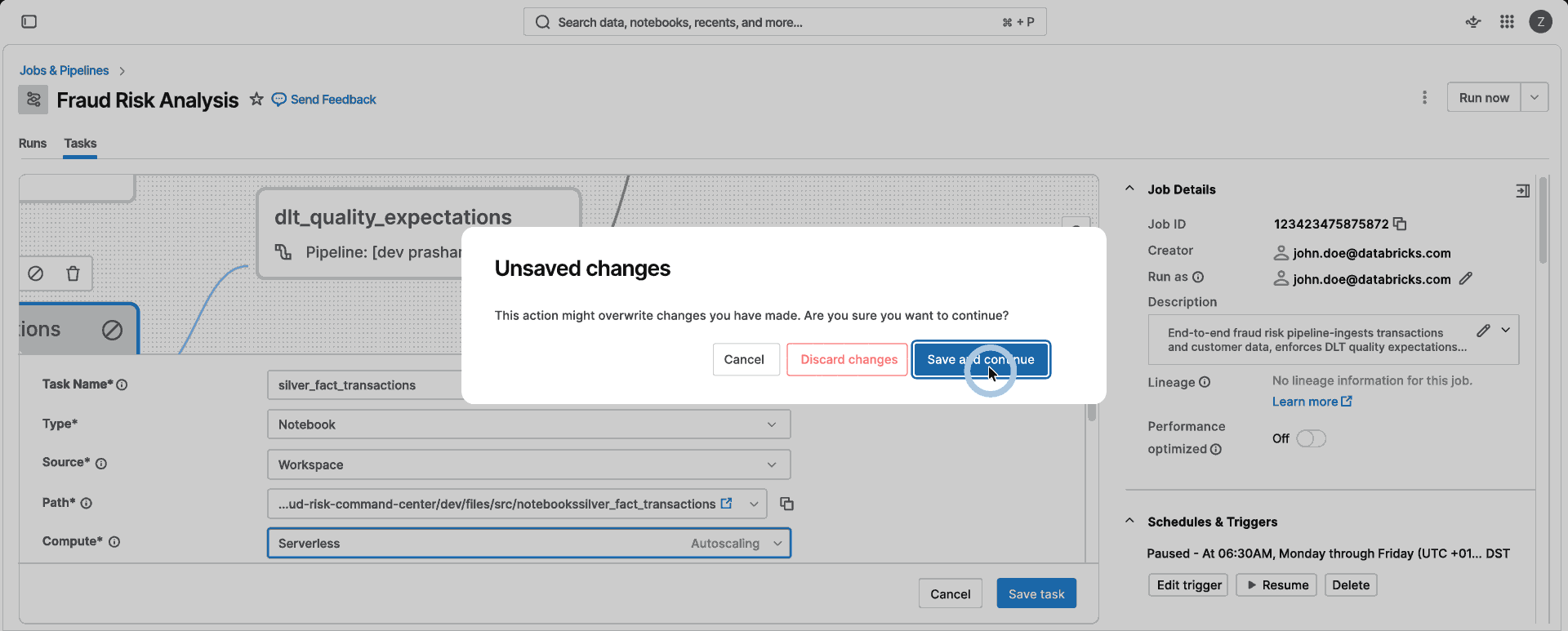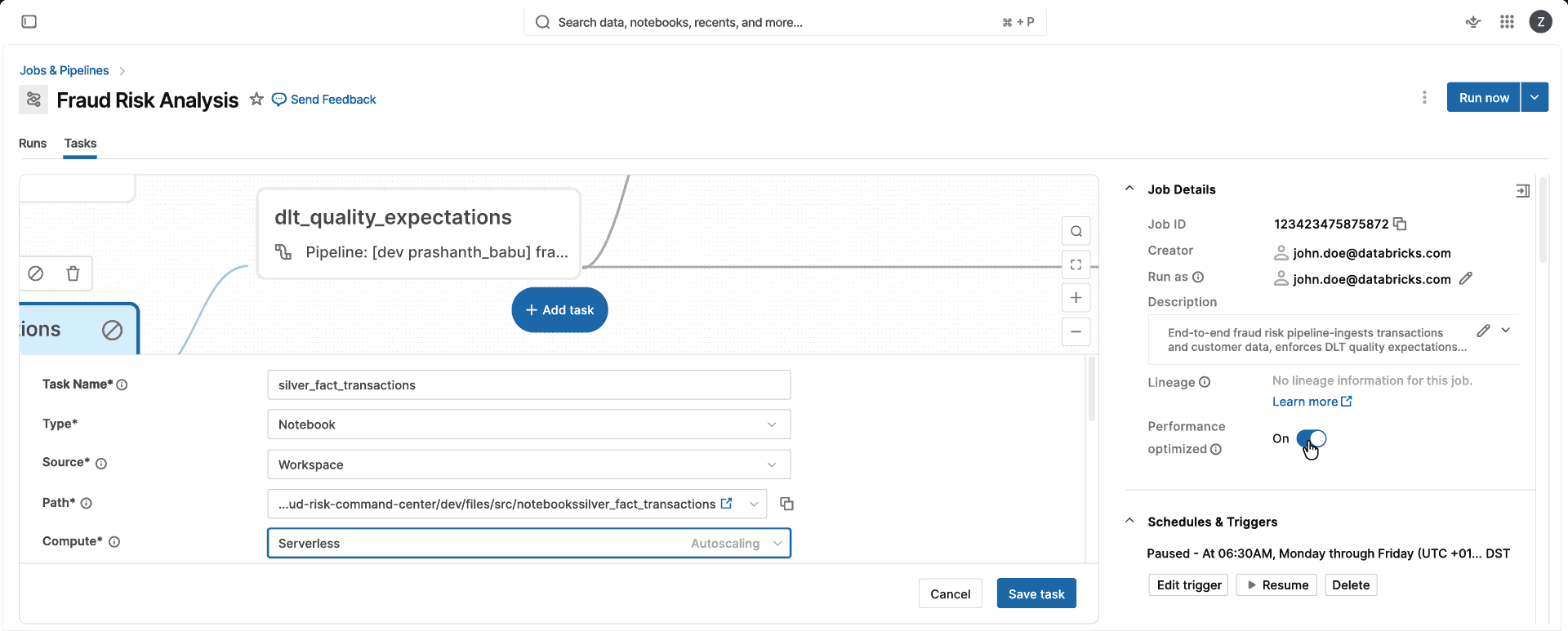
AS PRINCIPAIS EMPRESAS USAM Serverless compute
Escolha seu objetivo de negócio, não a infra
Execute cargas de trabalho de dados e AI em computação que dimensiona, atualiza e otimiza automaticamente, sem gerenciamento de infraestrutura.Totalmente gerenciado
Um compute. Sem decisões sobre otimização para CPU, otimização para memória ou classe de instância, nem configuração de cluster para gerenciar. Escolha o modo Padrão ou Otimizado para Desempenho, e o Databricks selecionará automaticamente a instância e os tipos de compute corretos (VM única ou cluster do Spark) para você, para que sua equipe possa entregar produtos de dados em vez de gerenciar o compute.
De alto desempenho
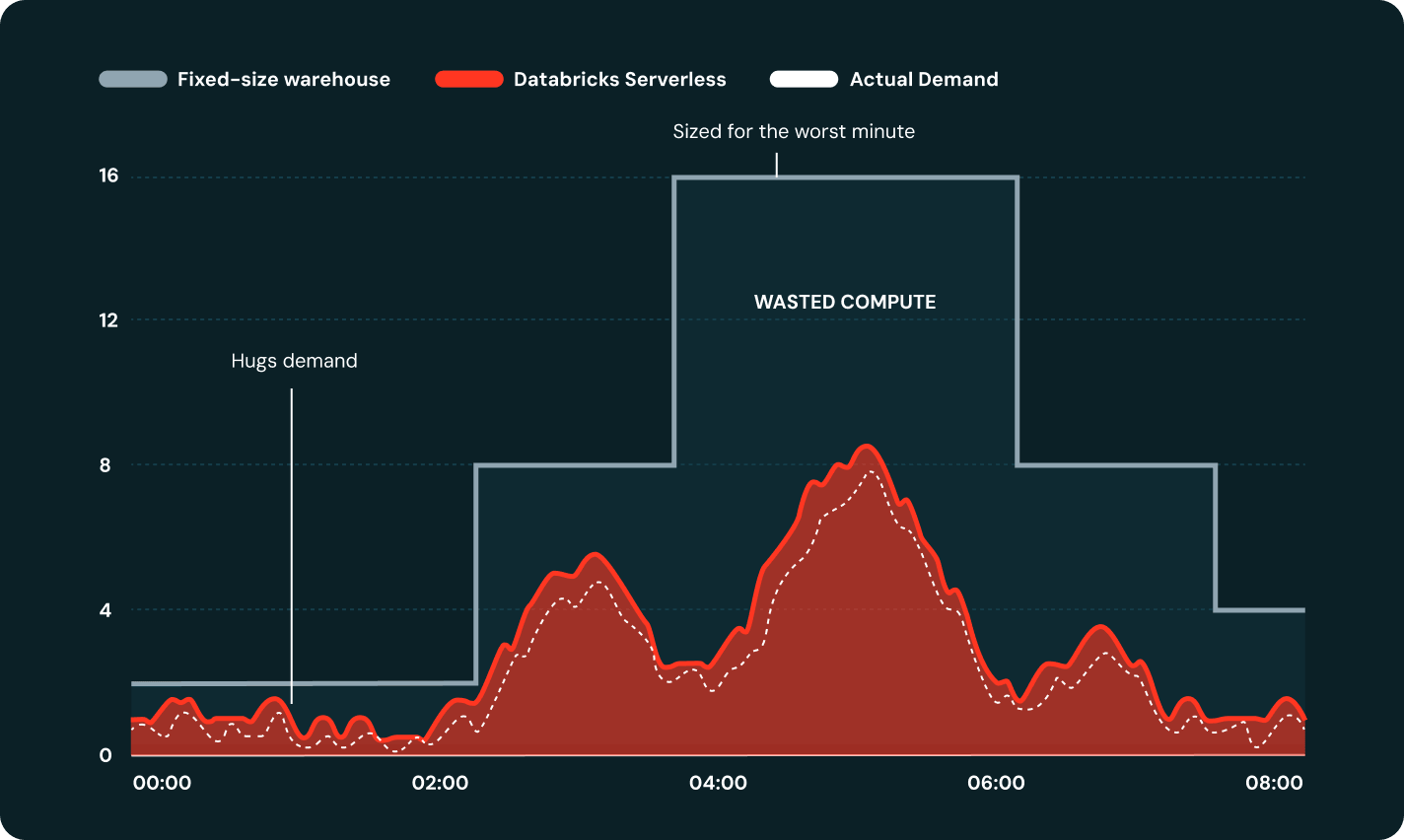
O Serverless inicia em segundos, não em minutos, carrega ambientes do cache e se dimensiona automaticamente para a demanda da carga de trabalho. O modo Padrão oferece processamento em lotes com bom custo-benefício, enquanto o modo Otimizado para Desempenho geralmente executa jobs sensíveis à latência 2x mais rápido que os clusters clássicos.
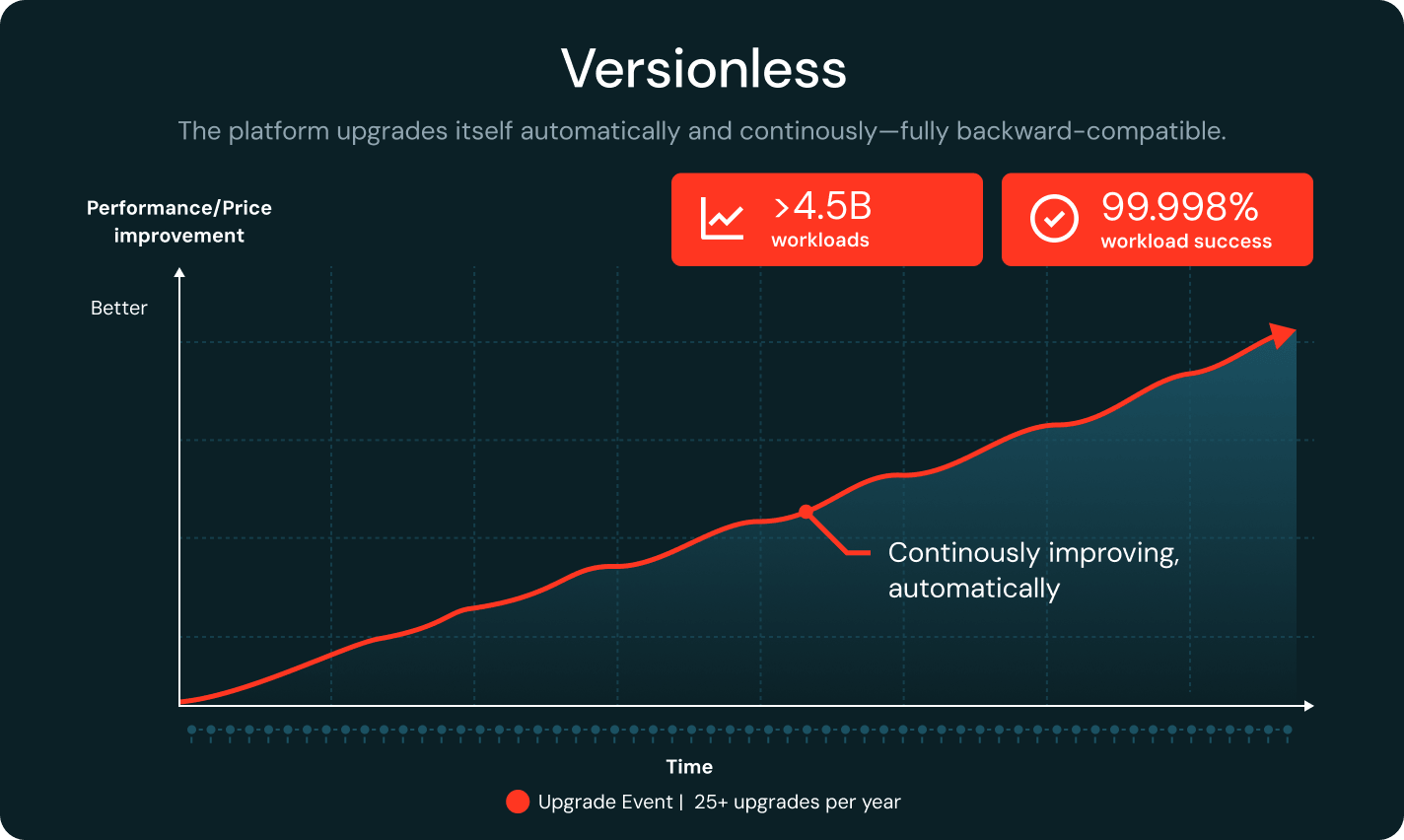
Sem versão
O Databricks atualiza continuamente o runtime, mantendo-se totalmente retrocompatível. A detecção de regressão pins as cargas de trabalho em versões estáveis automaticamente. Com mais de 25 atualizações por ano e 99,998% de sucesso da carga de trabalho, as equipes economizam até 20% do tempo de engenharia.
compute que simplesmente funciona
Pare de gerenciar a infraestrutura e comece a executar suas cargas de trabalho de dados e AI em uma compute totalmente gerenciada, com autoscale e sem versão.O Serverless é atualizado de forma contínua e automática, mantendo-se totalmente compatível com versões anteriores e as cargas de trabalho em execução sem intervenção.
Escolha o modo Padrão para cargas de trabalho em lote com custo otimizado ou o modo Otimizado para desempenho para jobs sensíveis à latência, que normalmente executa jobs 2x mais rápido que os clusters clássicos.
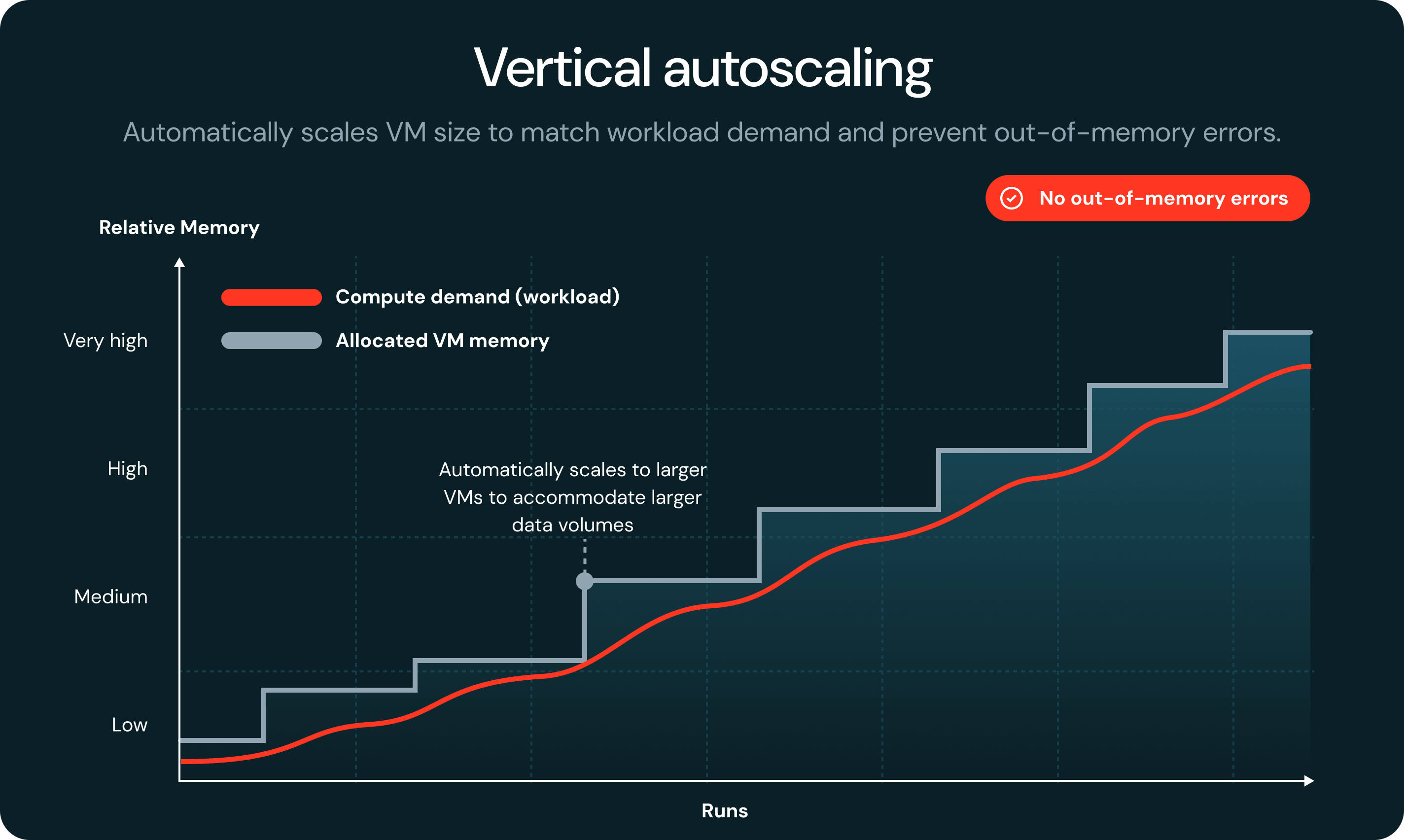
Quando uma tarefa fica sem memória, o serverless detecta a falha automaticamente e a reinicia em uma VM maior, sem falhas no job ou intervenção manual necessária.
Os ambientes de biblioteca são armazenados em cache globalmente, então, quando um usuário da sua organização executa um ambiente com um conjunto específico de pacotes, ele fica pronto em segundos para todos os outros.
O Serverless dimensiona a computação para mais ou para menos em segundos, não em minutos, ajustando-se automaticamente à demanda da carga de trabalho sem precisar configurar o cluster.
O Serverless repete automaticamente tarefas com falha e contorna falhas em nível de nuvem, mantendo os pipelines em dia sem precisar de intervenção de plantão.
Mais recursos
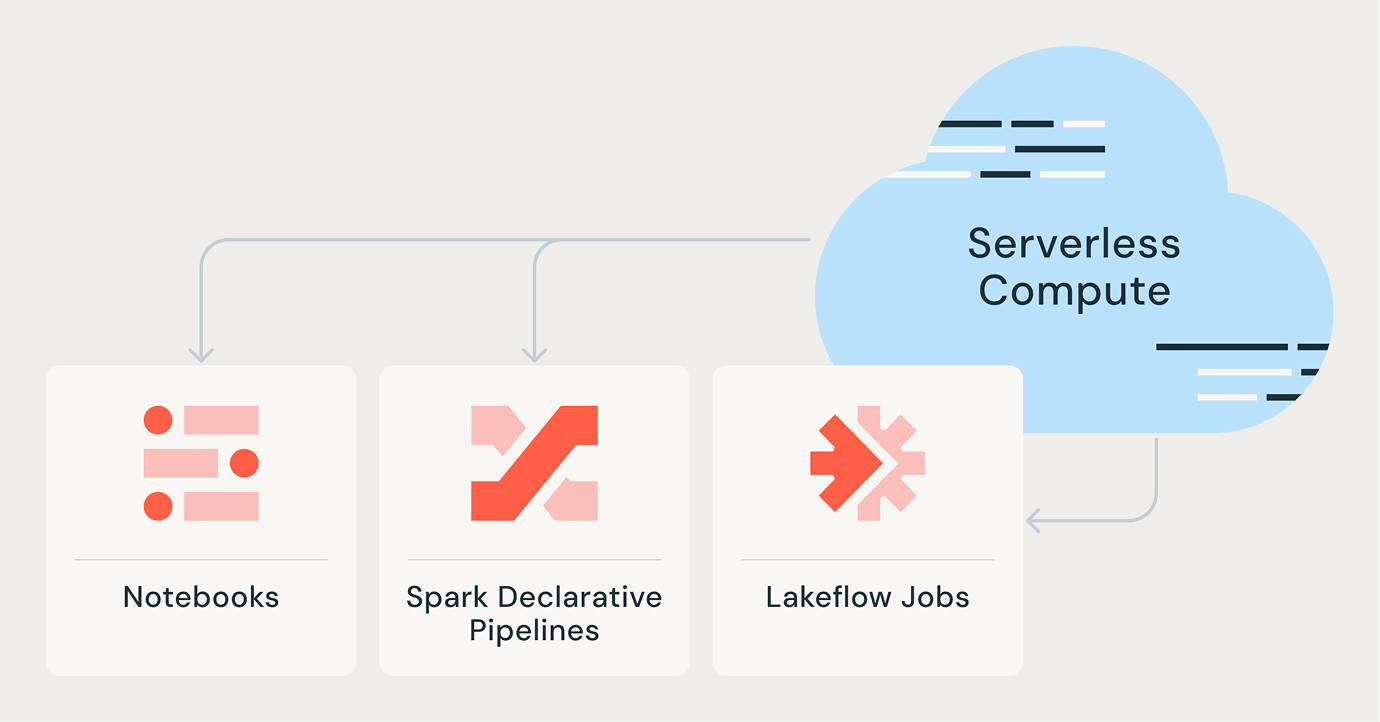
Serverless para qualquer carga de trabalho

Query data sem gerenciar o compute do warehouse.
Os SQL warehouses Serverless da Databricks são iniciados em segundos e escalados automaticamente para atender à demanda, para que os analistas sempre tenham a computação pronta. Sem decisões de dimensionamento, sem clusters parados e sem sobrecarga de infraestrutura. Apenas consultas rápidas e confiáveis.




O preço baseado no uso ajuda a controlar despesas
Pague apenas pelos produtos que usar por segundo.Descubra mais
Saiba mais sobre produtos que usam serverless compute
Jobs do Lakeflow
Capacite as equipes para automatizar e orquestrar melhor qualquer fluxo de trabalho de ETL, analítica e IA com observabilidade detalhada, alta confiabilidade e amplo suporte a tipos de tarefas.

Databricks SQL
Um data warehouse inteligente e auto-otimizado construído em arquitetura lakehouse, oferecendo a melhor relação preço/desempenho do mercado.

Pipelines Declarativos do Spark
Simplifique o ETL em lotes e transmissão com qualidade de dados automatizada, captura de dados de alterações (CDC), ingestão de dados, transformações e governança unificada.

Notebooks
Aumente a produtividade da equipe com os notebooks colaborativos da Databricks, que permitem colaboração em tempo real e fluxos de trabalho simplificados de ciência de dados.

Databricks Apps
Crie aplicativos usando estruturas comuns, implementações serverless e governança integrada. Forneça soluções significativas aos usuários sem o gerenciamento complexo de infraestrutura.

Lakebase
Postgres integrado ao lakehouse, desenvolvido para cargas de trabalho operacionais modernas.
Dê um passo adiante
Conteúdo relacionado
FAQ sobre Serverless compute
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos na transformação dos seus dados