Una historia de tres API de Apache Spark: RDD frente a DataFrames y Datasets
Cuándo usarlas y por qué
por Jules Damji
De todos los placeres de los desarrolladores, ninguno es más atractivo que un conjunto de APIs que los hagan productivos, que sean fáciles de usar, intuitivas y expresivas. Uno de los atractivos de Apache Spark para los desarrolladores han sido sus APIs fáciles de usar, para operar sobre grandes conjuntos de datos, en varios idiomas: Scala, Java, Python y R.
En este blog, exploraré tres conjuntos de APIs —RDDs, DataFrames y Datasets— disponibles en Apache Spark 2.2 y versiones posteriores; por qué y cuándo deberías usar cada conjunto; describiré sus beneficios de rendimiento y optimización; y enumeraré escenarios en los que usar DataFrames y Datasets en lugar de RDDs. Principalmente, me centraré en DataFrames y Datasets, porque en Apache Spark 2.0, estas dos APIs están unificadas.
Nuestra principal motivación detrás de esta unificación es nuestra búsqueda para simplificar Spark limitando el número de conceptos que tienes que aprender y ofreciendo formas de procesar datos estructurados. Y a través de la estructura, Spark puede ofrecer abstracciones y APIs de alto nivel como construcciones de lenguaje específicas del dominio.
Resilient Distributed Dataset (RDD)
RDD fue la API principal orientada al usuario en Spark desde su inicio. En esencia, un RDD es una colección distribuida inmutable de elementos de tus datos, particionada en nodos de tu clúster que pueden operarse en paralelo con una API de bajo nivel que ofrece transformaciones y acciones.
¿Cuándo usar RDDs?
Considera estos escenarios o casos de uso comunes para usar RDDs cuando:
- quieres transformaciones y acciones de bajo nivel y control sobre tu conjunto de datos;
- tus datos no están estructurados, como flujos multimedia o flujos de texto;
- quieres manipular tus datos con construcciones de programación funcional en lugar de expresiones específicas del dominio;
- no te importa imponer un esquema, como formato columnar, al procesar o acceder a atributos de datos por nombre o columna; y
- puedes renunciar a algunos beneficios de optimización y rendimiento disponibles con DataFrames y Datasets para datos estructurados y semiestructurados.
¿Qué pasa con los RDDs en Apache Spark 2.0?
Puedes preguntar: ¿Están los RDDs siendo relegados a ciudadanos de segunda clase? ¿Están siendo deprecados?
¡La respuesta es un rotundo NO!
Es más, como notarás a continuación, puedes moverte sin problemas entre DataFrame o Dataset y RDDs a voluntad —mediante simples llamadas a métodos de API— y DataFrames y Datasets se construyen sobre RDDs.
DataFrames
Al igual que un RDD, un DataFrame es una colección distribuida inmutable de datos. A diferencia de un RDD, los datos se organizan en columnas con nombre, como una tabla en una base de datos relacional. Diseñado para facilitar aún más el procesamiento de grandes conjuntos de datos, DataFrame permite a los desarrolladores imponer una estructura a una colección distribuida de datos, permitiendo abstracciones de alto nivel; proporciona una API de lenguaje específico del dominio para manipular tus datos distribuidos; y hace que Spark sea accesible a una audiencia más amplia, más allá de los ingenieros de datos especializados.
En nuestra vista previa del webinar de Apache Spark 2.0 y la publicación posterior, mencionamos que en Spark 2.0, las APIs de DataFrame se fusionarán con las APIs de Datasets, unificando las capacidades de procesamiento de datos en todas las bibliotecas. Debido a esta unificación, los desarrolladores ahora tienen menos conceptos que aprender o recordar, y trabajan con una única API de alto nivel y segura en cuanto a tipos llamada Dataset.
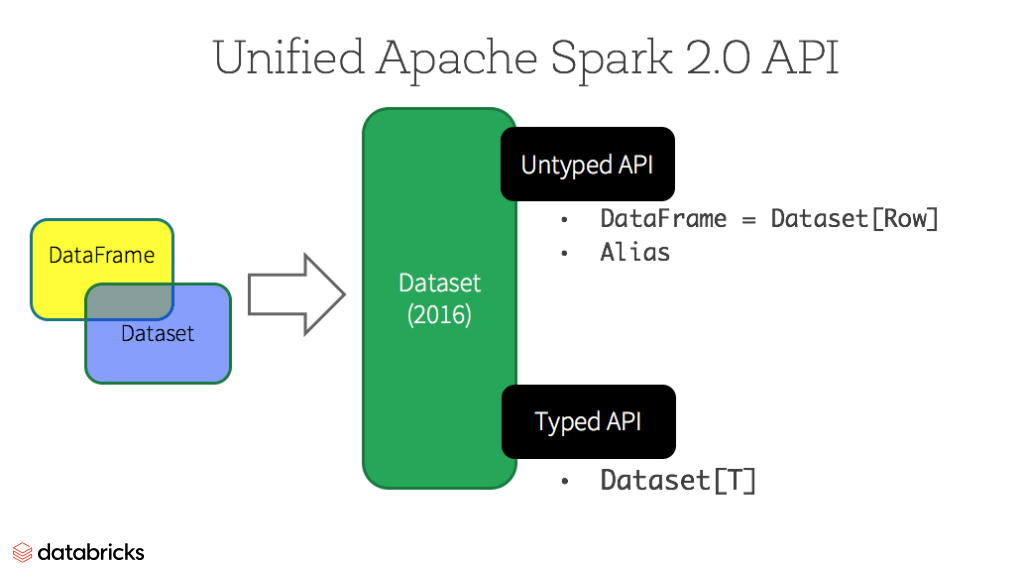
Datasets
A partir de Spark 2.0, Dataset adopta dos características de API distintas: una API fuertemente tipada y una API no tipada, como se muestra en la tabla a continuación. Conceptualmente, considera DataFrame como un alias para una colección de objetos genéricos Dataset[Row], donde un Row es un objeto JVM genérico no tipado. Dataset, por el contrario, es una colección de objetos JVM fuertemente tipados, dictados por una clase de caso que defines en Scala o una clase en Java.
APIs Tipadas y No Tipadas
| Idioma | Abstracción Principal |
|---|---|
| Scala | Dataset[T] & DataFrame (alias para Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Nota: Dado que Python y R no tienen seguridad de tipos en tiempo de compilación, solo tenemos APIs no tipadas, a saber, DataFrames.
Beneficios de las APIs de Dataset
Como desarrollador de Spark, te beneficias de las APIs unificadas de DataFrame y Dataset en Spark 2.0 de varias maneras.
1. Tipado estático y seguridad de tipos en tiempo de ejecución
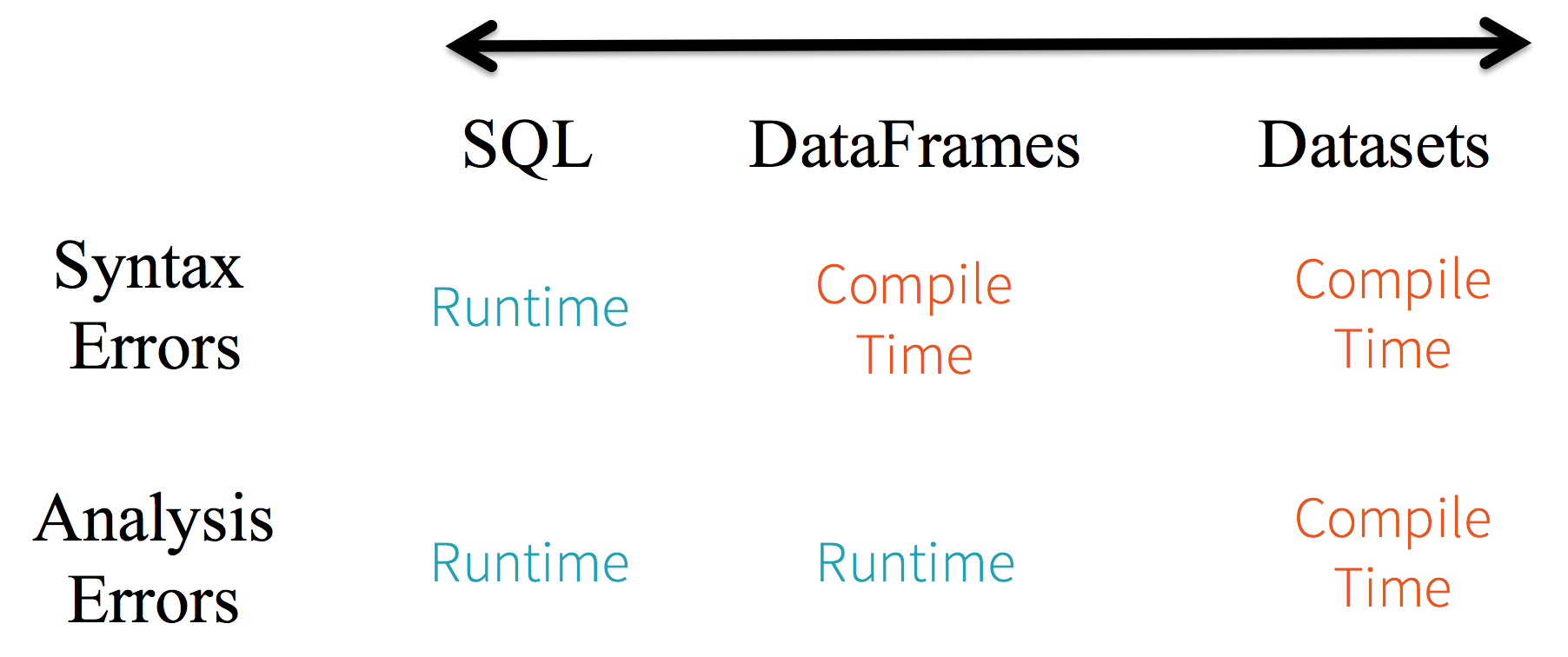
Considera el tipado estático y la seguridad en tiempo de ejecución como un espectro, con SQL siendo el menos restrictivo y Dataset el más restrictivo. Por ejemplo, en tus consultas de cadena de Spark SQL, no conocerás un error de sintaxis hasta el tiempo de ejecución (lo que podría ser costoso), mientras que en DataFrames y Datasets puedes detectar errores en tiempo de compilación (lo que ahorra tiempo y costos de desarrollo). Es decir, si invocas una función en DataFrame que no forma parte de la API, el compilador la detectará. Sin embargo, no detectará un nombre de columna inexistente hasta el tiempo de ejecución.
En el extremo del espectro se encuentra Dataset, el más restrictivo. Dado que las APIs de Dataset se expresan como funciones lambda y objetos tipados de JVM, cualquier desajuste de parámetros tipados se detectará en tiempo de compilación. Además, tu error de análisis también se puede detectar en tiempo de compilación, al usar Datasets, ahorrando así tiempo y costos de desarrollo.
Todo esto se traduce en un espectro de seguridad de tipos a lo largo de la sintaxis y los errores de análisis en tu código Spark, siendo Datasets el más restrictivo pero productivo para un desarrollador.
2. Abstracción de alto nivel y vista personalizada de datos estructurados y semiestructurados
DataFrames, como colección de Datasets[Row], ofrecen una vista personalizada y estructurada de tus datos semiestructurados. Por ejemplo, digamos que tienes un enorme conjunto de datos de eventos de dispositivos IoT, expresado en JSON. Dado que JSON es un formato semiestructurado, se presta bien a emplear Dataset como una colección de Dataset[DeviceIoTData] fuertemente tipada y específica.
Podrías expresar cada entrada JSON como DeviceIoTData, un objeto personalizado, con una clase de caso de Scala.
A continuación, podemos leer los datos de un archivo JSON.
Tres cosas suceden aquí internamente en el código anterior:
- Spark lee el JSON, infiere el esquema y crea una colección de DataFrames.
- En este punto, Spark convierte tus datos en DataFrame = Dataset[Row], una colección de objetos Row genéricos, ya que no conoce el tipo exacto.
- Ahora, Spark convierte el Dataset[Row] -> Dataset[DeviceIoTData], un objeto Scala JVM específico del tipo, según lo dictado por la clase DeviceIoTData.
La mayoría de nosotros que trabajamos con datos estructurados estamos acostumbrados a ver y procesar datos de manera columnar o a acceder a atributos específicos dentro de un objeto. Con Dataset como una colección de objetos Dataset[ElementType] tipados, obtienes sin problemas tanto seguridad en tiempo de compilación como una vista personalizada para objetos JVM fuertemente tipados. Y tu Dataset[T] fuertemente tipado resultante del código anterior se puede mostrar o procesar fácilmente con métodos de alto nivel.
3. Facilidad de uso de las API con estructura
Aunque la estructura puede limitar el control sobre lo que tu programa Spark puede hacer con los datos, introduce semánticas enriquecidas y un conjunto fácil de operaciones específicas del dominio que se pueden expresar como construcciones de alto nivel. Sin embargo, la mayoría de los cálculos se pueden realizar con las API de alto nivel de Dataset. Por ejemplo, es mucho más sencillo realizar operaciones agg, select, sum, avg, map, filter o groupBy accediendo a los campos de datos de un objeto de tipo Dataset DeviceIoTData que utilizando los campos de datos de las filas RDD.
Expresar tu cálculo en una API específica del dominio es mucho más simple y fácil que con expresiones de tipo álgebra relacional (en RDDs). Por ejemplo, el siguiente código filter() y map() para crear otro Dataset inmutable.
4. Rendimiento y Optimización
Además de todos los beneficios anteriores, no puedes pasar por alto la eficiencia de espacio y las ganancias de rendimiento al usar las API de DataFrames y Dataset por dos razones.
Primero, debido a que las API de DataFrame y Dataset se basan en el motor Spark SQL, utiliza Catalyst para generar un plan de consulta lógico y físico optimizado. En las API de DataFrame/Dataset de R, Java, Scala o Python, todas las consultas de tipo relacional pasan por el mismo optimizador de código, proporcionando eficiencia de espacio y velocidad. Mientras que la API de tipo Dataset[T] está optimizada para tareas de ingeniería de datos, el Dataset[Row] sin tipo (un alias de DataFrame) es aún más rápido y adecuado para análisis interactivos.

Segundo, dado que Spark como compilador entiende tu objeto JVM de tipo Dataset, mapea tu objeto JVM específico de tipo a la representación de memoria interna de Tungsten usando Encoders. Como resultado, los Encoders de Tungsten pueden serializar/deserializar eficientemente objetos JVM, así como generar bytecode compacto que puede ejecutarse a velocidades superiores.
¿Cuándo debo usar DataFrames o Datasets?
- Si deseas semánticas enriquecidas, abstracciones de alto nivel y API específicas del dominio, usa DataFrame o Dataset.
- Si tu procesamiento requiere expresiones de alto nivel, filtros, mapas, agregaciones, promedios, sumas, consultas SQL, acceso a columnas y uso de funciones lambda sobre datos semiestructurados, usa DataFrame o Dataset.
- Si deseas un mayor grado de seguridad de tipos en tiempo de compilación, objetos JVM tipados, aprovechar la optimización de Catalyst y beneficiarte de la generación de código eficiente de Tungsten, usa Dataset.
- Si deseas unificación y simplificación de API entre las bibliotecas de Spark, usa DataFrame o Dataset.
- Si eres un usuario de R, usa DataFrames.
- Si eres un usuario de Python, usa DataFrames y recurre a RDDs si necesitas más control.
Ten en cuenta que siempre puedes interactuar o convertir sin problemas de DataFrame y/o Dataset a RDD, mediante una simple llamada al método .rdd. Por ejemplo,
Uniendo todo
En resumen, la elección de cuándo usar RDD o DataFrame y/o Dataset parece obvia. Mientras que el primero te ofrece funcionalidad y control de bajo nivel, el segundo permite vistas y estructuras personalizadas, ofrece operaciones de alto nivel y específicas del dominio, ahorra espacio y se ejecuta a velocidades superiores.
Al examinar las lecciones aprendidas de las primeras versiones de Spark —cómo simplificar Spark para los desarrolladores, cómo optimizarlo y hacerlo eficiente— decidimos elevar las API RDD de bajo nivel a una abstracción de alto nivel como DataFrame y Dataset y construir esta abstracción de datos unificada en todas las bibliotecas sobre el optimizador Catalyst y Tungsten.
Elige una — las API de DataFrames y/o Dataset o RDD — que cumpla tus necesidades y caso de uso, pero no me sorprendería si caes en el grupo de la mayoría de los desarrolladores que trabajan con datos estructurados y semiestructurados.
¿Qué sigue?
Puedes probar Apache Spark 2.2 en Databricks.
También puedes ver la presentación de Spark Summit sobre Una historia de tres API de Apache Spark: RDDs vs DataFrames y Datasets
Si aún no te has registrado, prueba Databricks ahora.
En las próximas semanas, tendremos una serie de blogs sobre Structured Streaming. Mantente atento.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.