Presentación de Pandas UDF para PySpark
Cómo ejecutar tu código Python nativo con PySpark, rápidamente.
por Li Jin
La Edición Gratuita ha reemplazado a la Edición Comunitaria, ofreciendo funciones mejoradas sin costo alguno. Empieza a usar Edición Gratuita hoy mismo.
NOTA: Spark 3.0 introdujo un nuevo pandas UDF. Puedes encontrar más detalles en la siguiente publicación del blog: Nuevos Pandas UDF y sugerencias de tipo de Python en la próxima versión de Apache Spark 3.0
Esta es una publicación comunitaria invitada de Li Jin, ingeniera de software en Two Sigma Investments, LP en Nueva York. Este blog también se publica en Two Sigma
Prueba este notebook en Databricks
ACTUALIZACIÓN: Este blog se actualizó el 22 de febrero de 2018 para incluir algunos cambios.
Esta publicación de blog presenta las funciones Pandas UDF (también conocidas como UDF vectorizadas) en la próxima versión 2.3 de Apache Spark, que mejora sustancialmente el rendimiento y la usabilidad de las funciones definidas por el usuario (UDF) en Python.
En los últimos años, Python se ha convertido en el idioma predeterminado para los científicos de datos. Paquetes como pandas, numpy, statsmodel y scikit-learn han ganado gran adopción y se han convertido en las herramientas principales. Al mismo tiempo, Apache Spark se ha convertido en el estándar de facto en el procesamiento de big data. Para permitir que los científicos de datos aprovechen el valor del big data, Spark agregó una API de Python en la versión 0.7, con soporte para funciones definidas por el usuario. Estas funciones definidas por el usuario operan fila por fila, y por lo tanto sufren una alta sobrecarga de serialización e invocación. Como resultado, muchos pipelines de datos definen UDF en Java y Scala y luego las invocan desde Python.
Pandas UDF construidas sobre Apache Arrow te brindan lo mejor de ambos mundos: la capacidad de definir UDF de bajo overhead y alto rendimiento completamente en Python.
En Spark 2.3, habrá dos tipos de Pandas UDF: escalares y de mapa agrupado. A continuación, ilustramos su uso con cuatro programas de ejemplo: Sumar Uno, Probabilidad Acumulada, Restar Media, Regresión Lineal de Mínimos Cuadrados Ordinarios.
UDF escalares de Pandas
Las UDF escalares de Pandas se utilizan para vectorizar operaciones escalares. Para definir una UDF escalar de Pandas, simplemente usa @pandas_udf para anotar una función de Python que tome pandas.Series como argumentos y devuelva otra pandas.Series del mismo tamaño. A continuación, ilustramos usando dos ejemplos: Sumar Uno y Probabilidad Acumulada.
Sumar Uno
Calcular v + 1 es un ejemplo simple para demostrar las diferencias entre las UDF fila por fila y las UDF escalares de Pandas. Ten en cuenta que los operadores de columna integrados pueden funcionar mucho más rápido en este escenario.
Usando UDF fila por fila:
Usando Pandas UDF:
Los ejemplos anteriores definen una UDF fila por fila "plus_one" y una UDF escalar de Pandas "pandas_plus_one" que realiza la misma computación "sumar uno". Las definiciones de UDF son las mismas excepto por los decoradores de función: "udf" vs "pandas_udf".
En la versión fila por fila, la función definida por el usuario toma un double "v" y devuelve el resultado de "v + 1" como un double. En la versión de Pandas, la función definida por el usuario toma un pandas.Series "v" y devuelve el resultado de "v + 1" como un pandas.Series. Debido a que "v + 1" está vectorizado en pandas.Series, la versión de Pandas es mucho más rápida que la versión fila por fila.
Ten en cuenta que hay dos requisitos importantes al usar UDF escalares de pandas:
- Las series de entrada y salida deben tener el mismo tamaño.
- Cómo se divide una columna en múltiples
pandas.Serieses interno de Spark, y por lo tanto, el resultado de la función definida por el usuario debe ser independiente de la división.
Probabilidad Acumulada
Este ejemplo muestra un uso más práctico de la UDF escalar de Pandas: calcular la probabilidad acumulada de un valor en una distribución normal N(0,1) usando el paquete scipy.
stats.norm.cdf funciona tanto con un valor escalar como con pandas.Series, y este ejemplo también se puede escribir con UDF fila por fila. Similar al ejemplo anterior, la versión de Pandas se ejecuta mucho más rápido, como se muestra más adelante en la sección "Comparación de rendimiento".
UDF de mapa agrupado de Pandas
Los usuarios de Python están bastante familiarizados con el patrón split-apply-combine en el análisis de datos. Las UDF de mapa agrupado de Pandas están diseñadas para este escenario y operan sobre todos los datos de un grupo, por ejemplo, "para cada fecha, aplica esta operación".
Las UDF de mapa agrupado de Pandas primero dividen un DataFrame de Spark en grupos según las condiciones especificadas en el operador groupby, aplican una función definida por el usuario (pandas.DataFrame -> pandas.DataFrame) a cada grupo, combinan y devuelven los resultados como un nuevo DataFrame de Spark.
Las UDF de mapa agrupado de Pandas utilizan el mismo decorador de función pandas_udf que las UDF escalares de Pandas, pero tienen algunas diferencias:
- Entrada de la función definida por el usuario:
- Escalar:
pandas.Series - Mapa agrupado:
pandas.DataFrame
- Escalar:
- Salida de la función definida por el usuario:
- Escalar:
pandas.Series - Mapa agrupado:
pandas.DataFrame
- Escalar:
- Semántica de agrupación:
- Escalar: sin semántica de agrupación
- Mapa agrupado: definido por la cláusula "groupby"
- Tamaño de salida:
- Escalar: igual que el tamaño de entrada
- Mapa agrupado: cualquier tamaño
- Tipos de retorno en el decorador de función:
- Escalar: un
DataTypeque especifica el tipo de lapandas.Seriesdevuelta - Mapa agrupado: un
StructTypeque especifica el nombre y tipo de cada columna delpandas.DataFramedevuelto
- Escalar: un
A continuación, repasaremos dos ejemplos para ilustrar los casos de uso de las UDF de mapa agrupado de Pandas.
Restar Media
Este ejemplo muestra un uso simple de las UDF de mapa agrupado de Pandas: restar la media de cada valor dentro del grupo.
En este ejemplo, restamos la media de v de cada valor de v para cada grupo. La semántica de agrupación se define por la función "groupby", es decir, cada pandas.DataFrame de entrada a la función definida por el usuario tiene el mismo valor "id". El esquema de entrada y salida de esta función definida por el usuario es el mismo, por lo que pasamos "df.schema" al decorador pandas_udf para especificar el esquema.
Las UDF de mapa agrupado de Pandas también se pueden llamar como funciones independientes de Python en el driver. Esto es muy útil para depurar, por ejemplo:
En el ejemplo anterior, primero convertimos un pequeño subconjunto de DataFrame de Spark a un pandas.DataFrame, y luego ejecutamos subtract_mean como una función independiente de Python sobre él. Después de verificar la lógica de la función, podemos llamar a la UDF con Spark sobre todo el conjunto de datos.
Regresión Lineal de Mínimos Cuadrados Ordinarios
El último ejemplo muestra cómo ejecutar la regresión lineal OLS para cada grupo usando statsmodels. Para cada grupo, calculamos beta b = (b1, b2) para X = (x1, x2) según el modelo estadístico Y = bX + c.
Este ejemplo demuestra que las UDF de Pandas con mapa agrupado se pueden usar con cualquier función arbitraria de Python: pandas.DataFrame -> pandas.DataFrame. El pandas.DataFrame devuelto puede tener un número diferente de filas y columnas que la entrada.
Comparación de rendimiento
Por último, queremos mostrar una comparación de rendimiento entre las UDF de fila a fila y las UDF de Pandas. Ejecutamos microbenchmarks para tres de los ejemplos anteriores (más uno, probabilidad acumulativa y resta de la media).
Configuración y metodología
Ejecutamos el benchmark en un clúster Spark de un solo nodo en Databricks Community Edition.
Detalles de la configuración:
Datos: Un DataFrame de 10 millones de filas con una columna Int y una columna Double
Clúster: 6.0 GB de memoria, 0.88 núcleos, 1 DBU
Versión del Databricks runtime: Última RC (4.0, Scala 2.11)
Para la implementación detallada del benchmark, consulta el Notebook de UDF de Pandas.
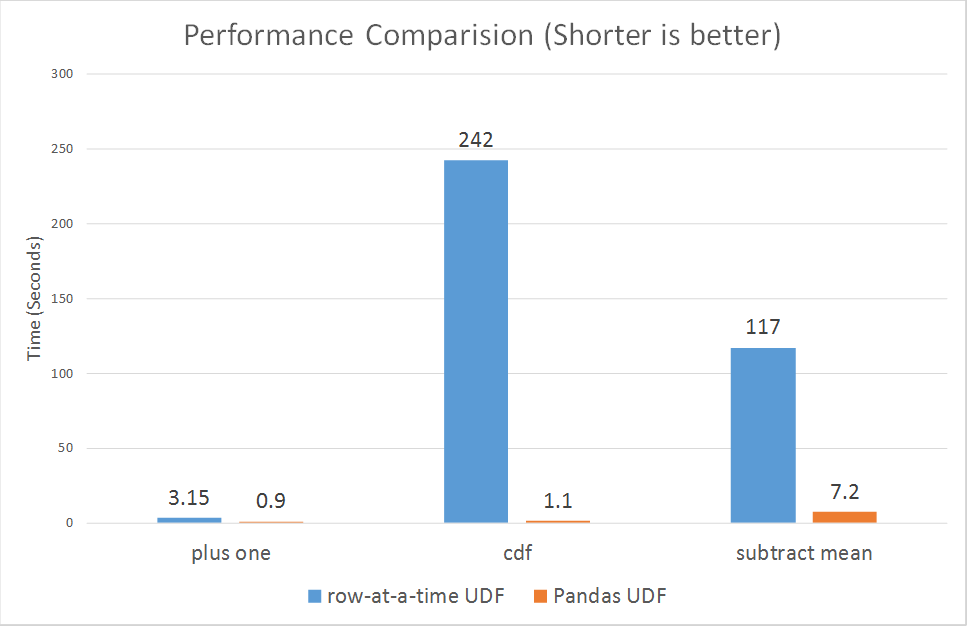
Como se muestra en los gráficos, las UDF de Pandas rinden mucho mejor que las UDF de fila a fila en todos los ámbitos, desde 3x hasta más de 100x.
Conclusión y trabajo futuro
La próxima versión de Spark 2.3 sienta las bases para mejorar sustancialmente las capacidades y el rendimiento de las funciones definidas por el usuario en Python. En el futuro, planeamos introducir soporte para UDF de Pandas en agregaciones y funciones de ventana. El trabajo relacionado se puede seguir en SPARK-22216.
Las UDF de Pandas son un gran ejemplo del esfuerzo de la comunidad de Spark. Nos gustaría agradecer a Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li y muchos otros por sus contribuciones. Finalmente, un agradecimiento especial a la comunidad de Apache Arrow por hacer posible este trabajo.
¿Qué sigue?
Puedes probar el notebook de UDF de Pandas y esta función ya está disponible como parte de la versión beta de Databricks Runtime 4.0.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.