Aplicando tu red neuronal convolucional: ¡Webinar a pedido y preguntas frecuentes ya disponibles!
por Denny Lee y Cyrielle Simeone
Prueba este notebook en Databricks
El 25 de octubre, presentamos un webinar en vivo —Aplicación de su red neuronal convolucional— con Denny Lee, gerente técnico de Marketing de Producto en Databricks. Este es el tercer webinar de una serie gratuita sobre los fundamentos del deep learning de Databricks.

En este seminario web, profundizamos en las Redes Neuronales Convolucionales (CNN), un tipo particular de redes neuronales que asumen que las entradas son imágenes y que han demostrado ser muy eficaces para la clasificación de imágenes y el reconocimiento de objetos.
En particular, hablamos sobre:
- Arquitectura CNN, con nodos dispuestos en 3D con un ancho, una altura y una profundidad, lo que permite aplicar filtros convolucionales para extraer características.
- Cómo funcionan los kernels convolucionales (filtros), lo que incluye cómo elegir los tamaños de filtro, los pasos (strides) y el relleno (padding) para extraer características de las regiones de píxeles en tus imágenes de entrada.
- Técnicas de pooling, o submuestreo, para reducir el tamaño de la imagen y así disminuir el número de parámetros y el riesgo de sobreajuste.
Demostramos algunos de estos conceptos con Keras (backend de TensorFlow) en Databricks y aquí tienes un enlace a nuestro notebook para que empieces hoy mismo:
Todavía puedes ver la Parte 1 y la Parte 2 a continuación:


Si deseas acceso gratuito a la plataforma Databricks Unified Analytics Platform y probar nuestros notebooks en ella, puedes acceder a una prueba gratuita aquí.
Hacia el final, tuvimos una sesión de preguntas y respuestas, y a continuación se encuentran las preguntas y sus respuestas, agrupadas por temas.
Fundamentos
P: ¿Realmente necesito entender las matemáticas detrás de las redes neuronales para usarlas?
Si bien no es completamente necesario entender las matemáticas detrás de las redes neuronales para usarlas, es importante comprender estos fundamentos para elegir los algoritmos correctos y saber cómo optimizar, mejorar y diseñar tus modelos de aprendizaje profundo (y aprendizaje automático). Un buen artículo sobre este tema es The Mathematics of Machine Learning de Wale Akinfaderin.
Red neuronal convolucional
P: ¿Por qué usar las CNN en lugar de redes neuronales regulares? Y, ¿cómo se usan las CNN en la vida real?, ¿puedes compartir ejemplos de sus aplicaciones?
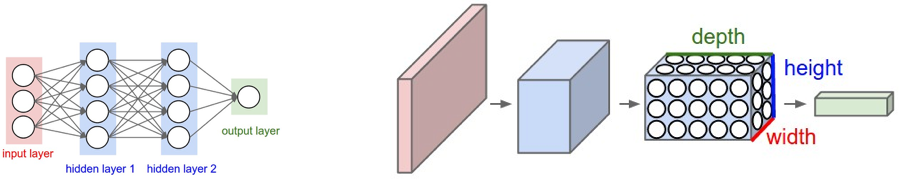
Fuente: https://cs231n.github.io/convolutional-networks/
Como se analiza más a fondo en Entrenamiento de redes neuronales, las redes neuronales convolucionales (CNNs) son similares a las redes neuronales artificiales regulares, pero las primeras hacen suposiciones explícitas de que la entrada son imágenes. El problema es que las redes neuronales artificiales totalmente conectadas (como se muestra en el gráfico de la izquierda) no escalan bien con las imágenes. Por ejemplo, una imagen de 200 píxeles x 200 píxeles x 3 canales de color (p. ej., RGB) daría como resultado 120,000 pesos. Cuanto más grande o compleja sea la imagen (en cuanto a canales), más pesos se necesitarán. En el caso de las CNN, los nodos solo se conectan a una pequeña región de la capa anterior organizada en 3D (ancho, alto, profundidad). Como los nodos no están totalmente conectados, esto reduce la cantidad de pesos (es decir, cardinalidad), lo que permite que la red complete sus pasadas más rápidamente.
P: Una CNN es una red de capas, tamaño y tipo. ¿Cómo los elijo? ¿Basado en qué? En otras palabras, ¿cómo diseño mi arquitectura?
Como se indica en Introducción a las redes neuronales: seminario web a pedido y preguntas frecuentes ya disponibles, si bien existen reglas generales sobre tu punto de partida (p. ej., empezar con una capa oculta y expandir en consecuencia, el número de nodos de entrada es igual a la dimensión de las características, etc.), lo fundamental es que necesitarás hacer pruebas. Es decir, entrena tu modelo y luego ejecuta las corridas de prueba o de validación contra ese modelo para comprender la exactitud (mientras más alta, mejor) y la pérdida (mientras más baja, mejor). En cuanto al diseño de tu arquitectura, es mejor empezar con las arquitecturas mejor comprendidas e investigadas (p. ej., AlexNet, LeNet-5, Inception, VGG, ResNet, etc.). A partir de aquí, puedes ajustar el número, el tamaño y el tipo de capas a medida que ejecutas tus experimentos.
P: ¿Por qué usar la función softmax para la capa totalmente conectada?
Cuando trabajamos con regresión logística, esto presupone una distribución de Bernoulli para nuestra clasificación binaria. Cuando se necesita aplicar una clasificación a más de dos clases (como en nuestro problema de clasificación de MNIST), se requiere la generalización de la distribución de Bernoulli, que es una distribución multinomial. El tipo de regresión que se aplica a la distribución multinomial (multiclasificador) se conoce como regresión softmax. Para MNIST, estamos clasificando dígitos escritos a mano para algún valor entre 0, ..., 9 en la capa totalmente conectada, de ahí el uso de softmax.
P: ¿El tamaño del filtro es siempre un número impar?
Un enfoque común para el tamaño del filtro es f x f, donde f es un número impar. Aunque no se menciona explícitamente, en la diapositiva 39 de Aplicación de redes neuronales, f es un número impar porque el objetivo es convolucionar el píxel de origen y sus píxeles circundantes. El mínimo indispensable sería un tamaño de filtro de 3 x 3, ya que eso sería el píxel de origen + 1 píxel hacia afuera en el espacio 2D.

Al tener un tamaño f par, esto resultaría en la convolución de menos de la mitad de los píxeles alrededor del píxel de origen. Para profundizar, puede encontrar una buena respuesta de Stack Overflow a esta pregunta en https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186.
P: ¿Cómo puedo implementar una CNN con una longitud de entrada variable? Es decir, ¿alguna sugerencia para los datos de entrenamiento que tienen imágenes de tamaño variable?
En general, necesitarías cambiar el tamaño de tus imágenes o rellenarlas con ceros para que todas las imágenes de entrada para tu CNN tengan el mismo tamaño. Existen algunos enfoques que involucran LSTM, RNN o redes neuronales recursivas (especialmente para datos de texto) que pueden manejar entradas de tamaño variable, aunque ten en cuenta que esta suele ser una tarea no trivial.
Entorno y recursos de ML
P: Soy un usuario de pago de Databricks. Sé cómo ejecutar Keras en mi PC, pero todavía no dentro de Databricks.
Cuando uses Databricks, inicia un clúster de Databricks Runtime for Machine Learning que incluye, entre otros, Keras, TensorFlow, XGBoost, Horovod y scikit-learn. Para obtener más información, consulta Anuncio de Databricks Runtime for Machine Learning.
P: ¿Tuvimos una sesión similar para ML?
Hay varios seminarios web de Databricks excelentes disponibles; los que se centran en Machine Learning incluyen (entre otros):
- Presentación de MLflow: infraestructura para un ciclo de vida de machine learning completo
- Paralelizar código R con Apache® Spark
- Puesta en producción de modelos de Apache Spark™ MLlib para el servicio de predicciones en tiempo real
- Cómo Databricks y el machine learning están impulsando el futuro de la genómica
- GraphFrames: grafos basados en DataFrames para Apache® Spark™
- Apache® Spark™ MLlib: De Inicio rápido a Scikit-Learn
RECURSOS
- Machine Learning 101
- Demo de MNIST con ConvNetJS de Andrej Karpathy
- ¿Qué es la retropropagación en las redes neuronales?
- CS231n: Redes Neuronales Convolucionales para el Reconocimiento Visual
- Con especial énfasis en CS231n: Lecture 7: Convolution Neural Networks
- Redes neuronales y aprendizaje profundo
- TensorFlow
- Caja de herramientas de visualización profunda
- Retropropagación con TensorFlow
- TensorFrames: Google TensorFlow con Apache Spark
- Integración de bibliotecas de aprendizaje profundo con Apache Spark
- Construye, escala e implementa canalizaciones de aprendizaje profundo con facilidad
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.