Presentamos Delta Time Travel para lagos de datos a gran escala
Obtén una vista previa anticipada del nuevo ebook de O'Reilly con la guía paso a paso que necesitas para empezar a usar Delta Lake.
Control de versiones de datos para reproducir experimentos, revertir y auditar datos
Estamos encantados de presentar las capacidades de viaje en el tiempo en Databricks Delta Lake, el motor de análisis unificado de próxima generación construido sobre Apache Spark, para todos nuestros usuarios. Con esta nueva función, Delta versiona automáticamente los big data que almacenas en tu data lake, y puedes acceder a cualquier versión histórica de esos datos. Esta gestión temporal de datos simplifica tu pipeline de datos al facilitar la auditoría, la reversión de datos en caso de escrituras o eliminaciones accidentales incorrectas, y la reproducción de experimentos e informes. Tu organización finalmente puede estandarizarse en un repositorio de big data limpio, centralizado y versionado en tu propio almacenamiento en la nube para tu análisis.

Desafíos comunes con datos cambiantes
- Auditar cambios de datos: La auditoría de cambios de datos es fundamental tanto desde el punto de vista del cumplimiento de datos como de la simple depuración para comprender cómo han cambiado los datos con el tiempo. Las organizaciones que pasan de sistemas de datos tradicionales a tecnologías de big data y la nube luchan en tales escenarios.
- Reproducir experimentos e informes: Durante el entrenamiento de modelos, los científicos de datos ejecutan varios experimentos con diferentes parámetros en un conjunto de datos determinado. Cuando los científicos revisan sus experimentos después de un período de tiempo para reproducir los modelos, normalmente los datos de origen han sido modificados por pipelines upstream. Muchas veces, se ven sorprendidos por tales cambios de datos upstream y, por lo tanto, luchan por reproducir sus experimentos. Algunos científicos y organizaciones diseñan las mejores prácticas creando múltiples copias de los datos, lo que genera un aumento de los costos de almacenamiento. Lo mismo ocurre con los analistas que generan informes.
- Reversiones: Los pipelines de datos a veces pueden escribir datos incorrectos para los consumidores downstream. Esto puede ocurrir debido a problemas que van desde inestabilidades de infraestructura hasta datos desordenados o errores en el pipeline. Para los pipelines que realizan simples anexos a directorios o a una tabla, las reversiones se pueden abordar fácilmente mediante particionamiento basado en fechas. Con actualizaciones y eliminaciones, esto puede volverse muy complicado, y los ingenieros de datos normalmente tienen que diseñar un pipeline complejo para lidiar con tales escenarios.
Presentación del viaje en el tiempo
Las capacidades de viaje en el tiempo de Delta simplifican la creación de pipelines de datos para los casos de uso anteriores. A medida que escribes en una tabla o directorio de Delta, cada operación se versiona automáticamente. Puedes acceder a las diferentes versiones de los datos de dos maneras:
1. Usando una marca de tiempo
Sintaxis de Scala:
Puedes proporcionar la marca de tiempo o la cadena de fecha como una opción al lector de DataFrame:
En Python:
Sintaxis SQL:
Si el código del lector está en una biblioteca a la que no tienes acceso, y si estás pasando parámetros de entrada a la biblioteca para leer datos, aún puedes viajar en el tiempo para una tabla pasando la marca de tiempo en formato yyyyMMddHHmmssSSS a la ruta:
2. Usando un número de versión
En Delta, cada escritura tiene un número de versión, y puedes usar el número de versión para viajar en el tiempo también.
Sintaxis de Scala:
Sintaxis de Python:
Sintaxis SQL:
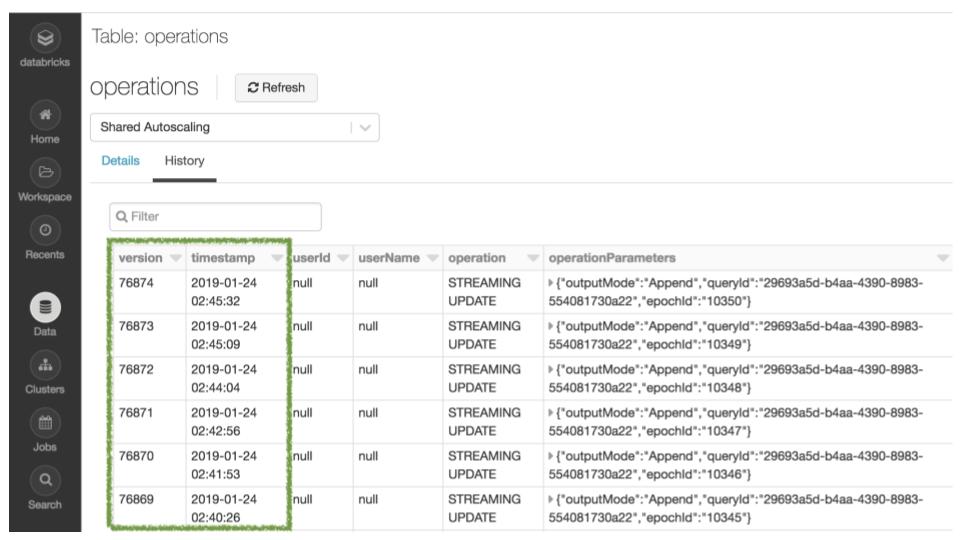
Auditar cambios de datos
Puedes ver el historial de cambios de la tabla usando el comando DESCRIBE HISTORY o a través de la interfaz de usuario.
Reproducir experimentos e informes
El viaje en el tiempo también juega un papel importante en el machine learning y la ciencia de datos. La reproducibilidad de los modelos y experimentos es una consideración clave para los científicos de datos, ya que a menudo crean cientos de modelos antes de poner uno en producción, y en ese proceso que consume mucho tiempo les gustaría volver a modelos anteriores. Sin embargo, dado que la gestión de datos a menudo está separada de las herramientas de ciencia de datos, esto es muy difícil de lograr.
Databricks resuelve este problema de reproducibilidad integrando las capacidades de viaje en el tiempo de Delta con MLflow, una plataforma de código abierto para el ciclo de vida del machine learning. Para un entrenamiento de machine learning reproducible, puedes simplemente registrar una URL con marca de tiempo en la ruta como un parámetro de MLflow para rastrear qué versión de los datos se utilizó para cada trabajo de entrenamiento. Esto te permite volver a configuraciones y conjuntos de datos anteriores para reproducir modelos anteriores. No necesitas coordinarte con equipos upstream sobre los datos ni preocuparte por clonar datos para diferentes experimentos. Este es el poder del Análisis Unificado, donde la ciencia de datos está estrechamente ligada a la ingeniería de datos.
Reversiones
El viaje en el tiempo también facilita las reversiones en caso de escrituras incorrectas. Por ejemplo, si tu trabajo de pipeline de GDPR tuvo un error que eliminó accidentalmente información del usuario, puedes arreglar fácilmente el pipeline:
También puedes corregir actualizaciones incorrectas de la siguiente manera:
Vista fijada de una tabla Delta en continua actualización a través de múltiples trabajos downstream
Con las consultas AS OF, ahora puedes fijar la instantánea de una tabla Delta en continua actualización para múltiples trabajos downstream. Considera una situación en la que una tabla Delta se actualiza continuamente, digamos cada 15 segundos, y hay un trabajo downstream que lee periódicamente de esta tabla Delta y actualiza diferentes destinos. En tales escenarios, normalmente deseas una vista consistente de la tabla Delta de origen para que todas las tablas de destino reflejen el mismo estado. Ahora puedes manejar fácilmente tales escenarios de la siguiente manera:
Consultas para análisis de series temporales simplificadas
El viaje en el tiempo también simplifica el análisis de series temporales. Por ejemplo, si deseas saber cuántos clientes nuevos agregaste durante la última semana, tu consulta podría ser muy simple como esta:
Conclusión
El viaje en el tiempo en Delta mejora enormemente la productividad de los desarrolladores. Ayuda a:
- Los científicos de datos a gestionar mejor sus experimentos
- Los ingenieros de datos a simplificar sus canalizaciones y revertir escrituras erróneas
- Los analistas de datos a realizar informes sencillos
Las organizaciones finalmente pueden estandarizar un repositorio de big data limpio, centralizado y versionado en su propio almacenamiento en la nube para análisis. Estamos encantados de ver lo que podrán lograr con esta nueva función.
La función está disponible como vista previa pública para todos los usuarios. Obtenga más información sobre la función. Para verla en acción, regístrese para una prueba gratuita de Databricks.
Visite el centro en línea de Delta Lake para obtener más información, descargar el último código y unirse a la comunidad de Delta Lake.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.