Evolución del esquema en operaciones de fusión y métricas operativas en Delta Lake
Delta Lake 0.6.0 introduce la evolución del esquema y mejoras de rendimiento en las métricas de fusión y operativas en el historial de la tabla
por Tathagata Das y Denny Lee
Obtén una vista previa anticipada del nuevo ebook de O'Reilly de O'Reilly para obtener la guía paso a paso que necesitas para empezar a usar Delta Lake.
Prueba este notebook para reproducir los pasos descritos a continuación.
Recientemente anunciamos el lanzamiento de Delta Lake 0.6.0, que introduce la evolución del esquema y mejoras de rendimiento en las operaciones de fusión (merge) y métricas operativas en el historial de tablas. Las características clave de este lanzamiento son:
- Soporte para la evolución del esquema en operaciones de fusión (#170): Ahora puedes evolucionar automáticamente el esquema de la tabla con la operación de fusión. Esto es útil en escenarios donde deseas actualizar (upsert) datos de cambios en una tabla y el esquema de los datos cambia con el tiempo. En lugar de detectar y aplicar cambios de esquema antes de actualizar, la fusión puede evolucionar el esquema y actualizar los cambios simultáneamente.
- Mejora del rendimiento de fusión con re-particionamiento automático (#349): Al fusionar tablas particionadas, puedes optar por re-particionar automáticamente los datos por las columnas de partición antes de escribir en la tabla. En casos donde la operación de fusión en una tabla particionada es lenta porque genera demasiados archivos pequeños (#345), habilitar el re-particionamiento automático (spark.delta.merge.repartitionBeforeWrite) puede mejorar el rendimiento.
- Mejora del rendimiento cuando no hay cláusula de inserción (#342): Ahora puedes obtener un mejor rendimiento en una operación de fusión si no tiene ninguna cláusula de inserción.
- Métricas de operación en DESCRIBE HISTORY (#312): Ahora puedes ver métricas de operación (por ejemplo, número de archivos y filas modificadas) para todas las escrituras, actualizaciones y eliminaciones en una tabla Delta en el historial de la tabla.
- Soporte para leer tablas Delta desde cualquier sistema de archivos (#347): Ahora puedes leer tablas Delta en cualquier sistema de almacenamiento con una implementación de Hadoop FileSystem. Sin embargo, escribir en tablas Delta todavía requiere configurar una implementación de LogStore que proporcione las garantías necesarias en el sistema de almacenamiento.
Evolución del Esquema en Operaciones de Fusión
Como se señaló en versiones anteriores de Delta Lake, Delta Lake incluye la capacidad de ejecutar operaciones de fusión para simplificar tus operaciones de inserción/actualización/eliminación en una sola operación atómica, así como la capacidad de aplicar y evolucionar tu esquema (más detalles también se pueden encontrar en esta charla técnica). Con el lanzamiento de Delta Lake 0.6.0, ahora puedes evolucionar tu esquema dentro de una operación de fusión.
Mostremos esto usando un ejemplo oportuno; puedes encontrar la muestra de código original en este notebook. Comenzaremos con un pequeño subconjunto del Repositorio de Datos del Nuevo Coronavirus COVID-19 (2019-nCoV) de Johns Hopkins CSSE que hemos puesto a disposición en /databricks-datasets. Este es un conjunto de datos comúnmente utilizado por investigadores y analistas para obtener información sobre el número de casos de COVID-19 en todo el mundo. Uno de los problemas con los datos es que el esquema cambia con el tiempo.
Por ejemplo, los archivos que representan los casos de COVID-19 del 1 al 21 de marzo (a partir del 30 de abril de 2020) tienen el siguiente esquema:
Pero los archivos del 22 de marzo en adelante (a partir del 30 de abril) tenían columnas adicionales, incluyendo FIPS, Admin2, Active y Combined_Key.
En nuestra muestra de código, renombramos algunas de las columnas (por ejemplo, Long_ -> Longitude, Province/State -> Province_State, etc.) ya que son semánticamente iguales. En lugar de evolucionar el esquema de la tabla, simplemente renombramos las columnas.
Si la preocupación principal fuera simplemente fusionar los esquemas, podríamos usar la característica de evolución de esquema de Delta Lake usando la opción “mergeSchema” en DataFrame.write(), como se muestra en la siguiente declaración.
Pero, ¿qué sucede si necesitas actualizar un valor existente y fusionar el esquema al mismo tiempo? Con Delta Lake 0.6.0, esto se puede lograr con la evolución del esquema para operaciones de fusión. Para visualizar esto, comencemos revisando old_data, que es una fila.
A continuación, simularemos una entrada de actualización que sigue el esquema de new_data
y unimos simulated_update y new_data con un total de 40 filas.
Establecemos el siguiente parámetro para configurar tu entorno para la evolución automática del esquema:
Ahora podemos ejecutar una operación única y atómica para actualizar los valores (del 21/03/2020) y fusionar el nuevo esquema con la siguiente declaración.
Revisemos la tabla Delta Lake con la siguiente declaración:
Métricas Operacionales
Puedes profundizar en las métricas operacionales observando el historial de la tabla de Delta Lake (columna operationMetrics) en la Spark UI ejecutando la siguiente instrucción:
A continuación se muestra una salida abreviada del comando anterior.
Notarás dos versiones de la tabla, una para el esquema antiguo y otra para el esquema nuevo. Al revisar las métricas operacionales a continuación, se indica que se insertaron 39 filas y se actualizó 1 fila.
Puedes entender más sobre los detalles detrás de estas métricas operacionales yendo a la pestaña SQL dentro de la Spark UI.
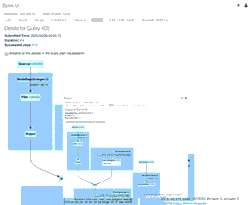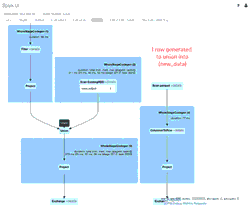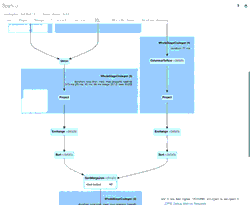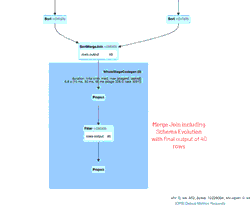
El GIF animado destaca los componentes principales de la Spark UI para tu revisión.
- 39 filas iniciales de un archivo (para 4/11/2020 con el esquema nuevo) que crearon el DataFrame new_data inicial
- 1 fila de actualización simulada generada que se uniría con el DataFrame new_data
- 1 fila del archivo (para 3/21/2020 con el esquema antiguo) que creó el DataFrame old_data.
- Un SortMergeJoin utilizado para unir los dos DataFrames y ser persistidos en nuestra tabla de Delta Lake.
Para profundizar en cómo interpretar estas métricas operacionales, consulta la charla técnica Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work.

Empieza con Delta Lake 0.6.0
Prueba Delta Lake con los fragmentos de código anteriores en tu instancia de Apache Spark 2.4.5 (o superior) (en Databricks, prueba esto con DBR 6.6+). Delta Lake hace que tus data lakes sean más confiables (ya sea que crees uno nuevo o migres uno existente). Para obtener más información, consulta https://delta.io/ y únete a la comunidad de Delta Lake a través de Slack y Google Group. Puedes seguir todas las próximas versiones y características planificadas en los hitos de GitHub. También puedes probar Delta Lake administrado en Databricks con una cuenta gratuita.
Créditos
Queremos agradecer a los siguientes colaboradores por las actualizaciones, cambios en la documentación y contribuciones en Delta Lake 0.6.0: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.