Ejecución Adaptativa de Consultas: Acelerando Spark SQL en Tiempo de Ejecución
Lee Rise of the Data Lakehouse para explorar por qué los lakehouses son la arquitectura de datos del futuro con el padre del data warehouse, Bill Inmon.
Este es un esfuerzo de ingeniería conjunto entre el equipo de ingeniería de Databricks Apache Spark — Wenchen Fan, Herman van Hovell y MaryAnn Xue — y el equipo de ingeniería de Intel —Ke Jia, Haifeng Chen y Carson Wang.
Consulta el notebook de AQE para probar la solución que se describe a continuación o profundiza en el funcionamiento interno de la Plataforma Databricks Lakehouse
A lo largo de los años, ha habido un esfuerzo extenso y continuo para mejorar el optimizador de consultas y el planificador de Spark SQL con el fin de generar planes de ejecución de consultas de alta calidad. Una de las mayores mejoras es el marco de optimización basado en costos que recopila y aprovecha una variedad de estadísticas de datos (por ejemplo, recuento de filas, número de valores distintos, valores NULL, valores máx./mín., etc.) para ayudar a Spark a elegir mejores planes. Ejemplos de estas técnicas de optimización basadas en costos incluyen la elección del tipo de join correcto (broadcast hash join vs. sort merge join), la selección del lado de build correcto en un hash-join o el ajuste del orden de join en un multi-way join. Sin embargo, las estadísticas obsoletas y las estimaciones de cardinalidad imperfectas pueden llevar a planes de consulta subóptimos. Adaptive Query Execution, nuevo en la próxima versión de Apache Spark 3.0 y disponible en Databricks Runtime 7.0, ahora busca abordar estos problemas reoptimizando y ajustando los planes de consulta en función de las estadísticas de tiempo de ejecución recopiladas en el proceso de ejecución de la consulta.
El marco de Adaptive Query Execution (AQE)
Una de las preguntas más importantes para Adaptive Query Execution es cuándo reoptimizar. Los operadores de Spark a menudo se canalizan y se ejecutan en procesos paralelos. Sin embargo, un shuffle o un broadcast exchange rompen esta canalización. Los llamamos puntos de materialización y usamos el término "query stages" para denotar subsecciones delimitadas por estos puntos de materialización en una consulta. Cada query stage materializa su resultado intermedio y la siguiente etapa solo puede proceder si todos los procesos paralelos que ejecutan la materialización se han completado. Esto proporciona una oportunidad natural para la reoptimización, ya que es cuando las estadísticas de datos de todas las particiones están disponibles y las operaciones sucesivas aún no han comenzado.
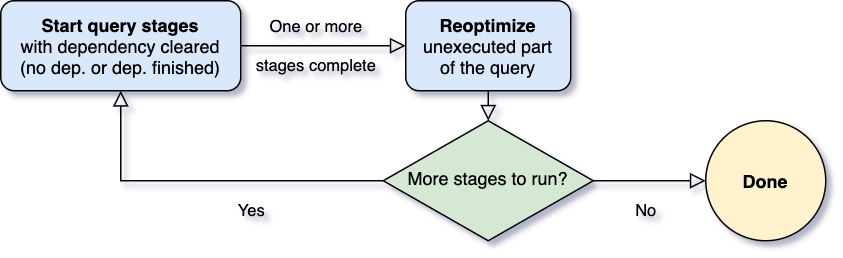
Cuando se inicia la consulta, el marco de Adaptive Query Execution primero activa todas las etapas hoja — las etapas que no dependen de ninguna otra etapa. Tan pronto como una o más de estas etapas terminan de materializarse, el marco las marca como completas en el plan de consulta físico y actualiza el plan de consulta lógico en consecuencia, con las estadísticas de tiempo de ejecución recuperadas de las etapas completadas. Basándose en estas nuevas estadísticas, el marco ejecuta el optimizador (con una lista seleccionada de reglas de optimización lógica), el planificador físico, así como las reglas de optimización física, que incluyen las reglas físicas regulares y las reglas específicas de ejecución adaptativa, como la coalescencia de particiones, el manejo de skew joins, etc. Ahora que tenemos un plan de consulta recién optimizado con algunas etapas completadas, el marco de ejecución adaptativa buscará y ejecutará nuevas etapas de consulta cuyas etapas secundarias se hayan materializado por completo, y repetirá el proceso de ejecución-reoptimización-ejecución anterior hasta que la consulta completa termine.
En Spark 3.0, el marco de AQE se envía con tres características:
- Coalescencia dinámica de particiones de shuffle
- Cambio dinámico de estrategias de join
- Optimización dinámica de skew joins
Las siguientes secciones hablarán sobre estas tres características en detalle.
Coalescencia dinámica de particiones de shuffle
Al ejecutar consultas en Spark para manejar datos muy grandes, el shuffle generalmente tiene un impacto muy importante en el rendimiento de las consultas, entre muchas otras cosas. El shuffle es un operador costoso ya que necesita mover datos a través de la red, de modo que los datos se redistribuyen de la manera requerida por los operadores posteriores.
Una propiedad clave del shuffle es el número de particiones. El número óptimo de particiones depende de los datos, pero los tamaños de los datos pueden diferir enormemente de una etapa a otra, de una consulta a otra, lo que hace que este número sea difícil de ajustar:
- Si hay muy pocas particiones, entonces el tamaño de los datos de cada partición puede ser muy grande, y las tareas para procesar estas particiones grandes pueden necesitar volcar datos al disco (por ejemplo, cuando se involucra sort o aggregate) y, como resultado, ralentizar la consulta.
- Si hay demasiadas particiones, entonces el tamaño de los datos de cada partición puede ser muy pequeño, y habrá muchas lecturas de datos de red pequeñas para leer los bloques de shuffle, lo que también puede ralentizar la consulta debido al patrón de E/S ineficiente. Tener un gran número de tareas también supone una mayor carga para el planificador de tareas de Spark.
Para resolver este problema, podemos establecer un número relativamente grande de particiones de shuffle al principio, y luego combinar particiones pequeñas adyacentes en particiones más grandes en tiempo de ejecución al observar las estadísticas de archivos de shuffle.
Por ejemplo, digamos que estamos ejecutando la consulta SELECT max(i)FROM tbl GROUP BY j. Los datos de entrada tbl son bastante pequeños, por lo que solo hay dos particiones antes de agrupar. El número inicial de particiones de shuffle se establece en cinco, por lo que después de la agrupación local, los datos parcialmente agrupados se barajan en cinco particiones. Sin AQE, Spark iniciará cinco tareas para realizar la agregación final. Sin embargo, hay tres particiones muy pequeñas aquí, y sería un desperdicio iniciar una tarea separada para cada una de ellas.
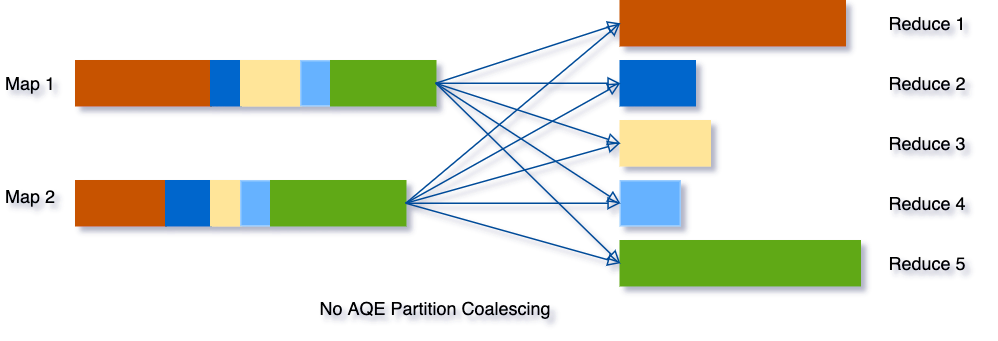
En cambio, AQE combina estas tres particiones pequeñas en una y, como resultado, la agregación final ahora solo necesita realizar tres tareas en lugar de cinco.

Cambio dinámico de estrategias de join
Spark admite varias estrategias de join, entre las cuales broadcast hash join suele ser la más eficiente si un lado del join cabe bien en la memoria. Y por esta razón, Spark planifica un broadcast hash join si el tamaño estimado de una relación de join es inferior al umbral de tamaño de broadcast. Pero varias cosas pueden hacer que esta estimación de tamaño falle — como la presencia de un filtro muy selectivo — o que la relación de join sea una serie de operadores complejos distintos de un simple escaneo.
Para resolver este problema, AQE ahora replanifica la estrategia de join en tiempo de ejecución basándose en el tamaño más preciso de la relación de join. Como se puede ver en el siguiente ejemplo, el lado derecho del join resulta ser mucho más pequeño que la estimación y también lo suficientemente pequeño como para ser transmitido, por lo que después de la reoptimización de AQE, el sort merge join planificado estáticamente se convierte ahora en un broadcast hash join.
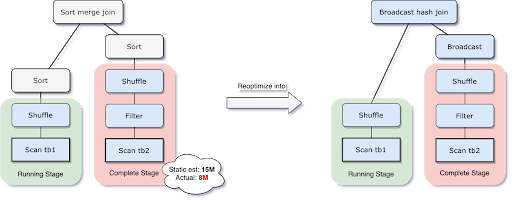
Para el broadcast hash join convertido en tiempo de ejecución, podemos optimizar aún más el shuffle regular a un shuffle localizado (es decir, un shuffle que lee por mapper en lugar de por reducer) para reducir el tráfico de red.
Optimización dinámica de skew joins
El skew de datos ocurre cuando los datos se distribuyen de manera desigual entre las particiones en el clúster. Un skew severo puede degradar significativamente el rendimiento de las consultas, especialmente con los joins. La optimización de skew join de AQE detecta automáticamente dicho skew a partir de las estadísticas de archivos de shuffle. Luego divide las particiones sesgadas en subparticiones más pequeñas, que se unirán a la partición correspondiente del otro lado respectivamente.
Tomemos este ejemplo de la tabla A unida a la tabla B, en la que la tabla A tiene una partición A0 significativamente más grande que sus otras particiones.
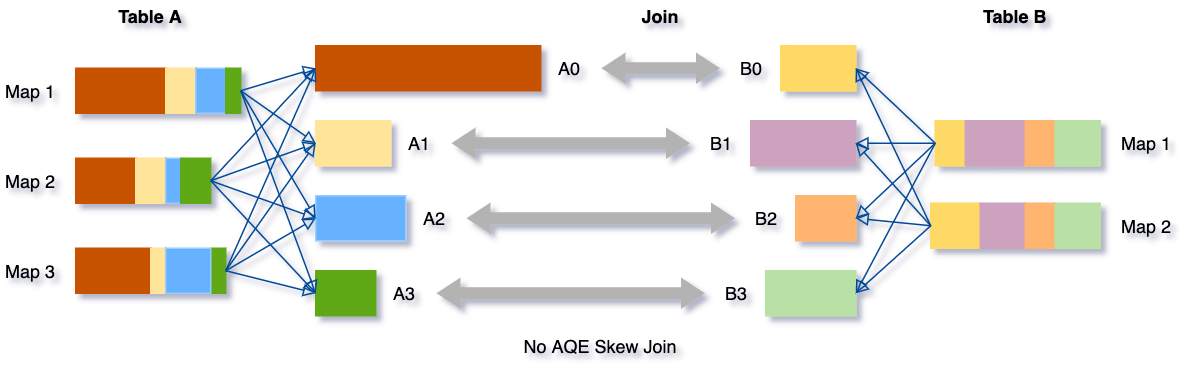
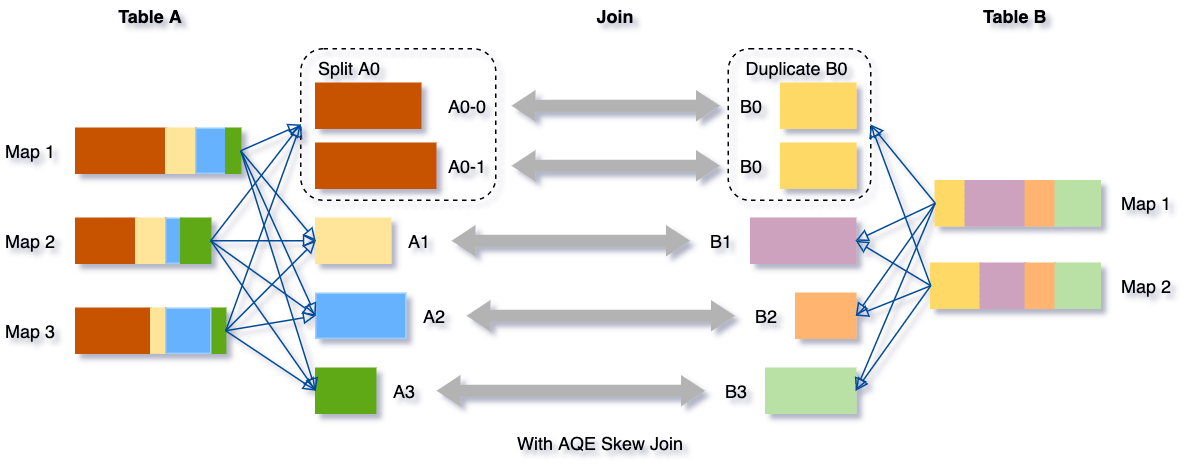
Sin esta optimización, habría cuatro tareas ejecutando el sort merge join, con una tarea tardando mucho más. Después de esta optimización, habrá cinco tareas ejecutando el join, pero cada tarea tardará aproximadamente la misma cantidad de tiempo, lo que resultará en un mejor rendimiento general.
Ganancias de rendimiento TPC-DS de AQE
En nuestros experimentos utilizando datos y consultas TPC-DS, Adaptive Query Execution produjo una aceleración de hasta 8 veces en el rendimiento de las consultas y 32 consultas tuvieron más de 1.1 veces de aceleración. A continuación, se muestra un gráfico de las 10 consultas TPC-DS con la mayor mejora de rendimiento por AQE.
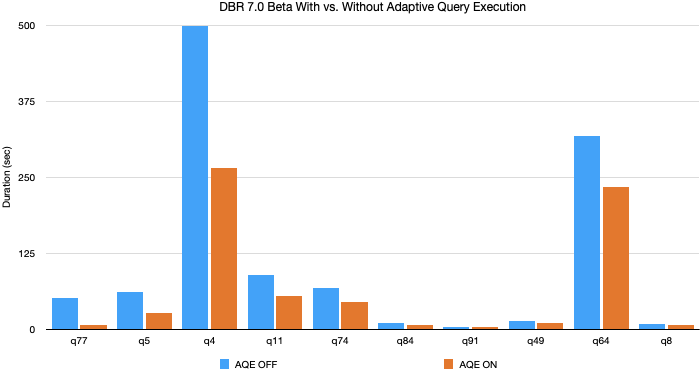
La mayoría de estas mejoras provienen de la coalescencia dinámica de particiones y el cambio dinámico de estrategia de join, ya que los datos TPC-DS generados aleatoriamente no tienen skew. Sin embargo, hemos visto mejoras aún mayores en cargas de trabajo de producción en las que se aprovechan las tres características de AQE.
Habilitando AQE
AQE se puede habilitar configurando el parámetro SQL spark.sql.adaptive.enabled a true (por defecto false en Spark 3.0), y se aplica si la consulta cumple los siguientes criterios:
- No es una consulta de streaming
- Contiene al menos un intercambio (generalmente cuando hay un operador de join, agregación o ventana) o una subconsulta
Al hacer que la optimización de consultas dependa menos de estadísticas estáticas, AQE ha resuelto una de las mayores dificultades de la optimización basada en costos de Spark: el equilibrio entre el costo de recopilación de estadísticas y la precisión de la estimación. Para lograr la mejor precisión de estimación y resultado de planificación, generalmente se requiere mantener estadísticas detalladas y actualizadas, y algunas de ellas son costosas de recopilar, como los histogramas de columnas, que se pueden usar para mejorar la estimación de selectividad y cardinalidad o para detectar el skew de datos. AQE ha eliminado en gran medida la necesidad de tales estadísticas, así como el esfuerzo de ajuste manual. Además, AQE también ha hecho que la optimización de consultas SQL sea más resistente a la presencia de UDF arbitrarias y a los cambios impredecibles en el conjunto de datos, por ejemplo, un aumento o disminución repentina en el tamaño de los datos, skew de datos frecuente y aleatorio, etc. Ya no es necesario "conocer" sus datos con anticipación. AQE identificará los datos y mejorará el plan de consulta a medida que se ejecuta la consulta, aumentando el rendimiento de la consulta para análisis más rápidos y el rendimiento del sistema.
Obtenga más información sobre Spark 3.0 en nuestro webinar de presentación. Pruebe AQE en Spark 3.0 hoy mismo gratis en Databricks como parte de nuestro Databricks Runtime 7.0.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.