Una mirada completa a las fechas y marcas de tiempo en Apache Spark™ 3.0
por Maxim Gekk, Wenchen Fan y Hyukjin Kwon
Apache Spark es una herramienta muy popular para procesar datos estructurados y no estructurados. Cuando se trata de procesar datos estructurados, admite muchos tipos de datos básicos, como entero, largo, doble, cadena, etc. Spark también admite tipos de datos más complejos, como Date y Timestamp, que a menudo son difíciles de entender para los desarrolladores. En esta entrada de blog, profundizamos en los tipos Date y Timestamp para ayudarte a comprender completamente su comportamiento y cómo evitar algunos problemas comunes. En resumen, este blog cubre cuatro partes:
- La definición del tipo Date y el calendario asociado. También cubre el cambio de calendario en Spark 3.0.
- La definición del tipo Timestamp y cómo se relaciona con las zonas horarias. También explica el detalle de la resolución del desplazamiento de la zona horaria y los sutiles cambios de comportamiento en la nueva API de tiempo en Java 8, que es utilizada por Spark 3.0.
- Las API comunes para construir valores de fecha y hora en Spark.
- Las trampas comunes y las mejores prácticas para recopilar objetos de fecha y hora en el controlador de Spark.
Fecha y calendario
La definición de una Date es muy simple: es una combinación de los campos de año, mes y día, como (año=2012, mes=12, día=31). Sin embargo, los valores del año, mes y día tienen restricciones, de modo que el valor de la fecha sea un día válido en el mundo real. Por ejemplo, el valor del mes debe estar entre 1 y 12, el valor del día debe estar entre 1 y 28/29/30/31 (dependiendo del año y el mes), y así sucesivamente.
Estas restricciones están definidas por uno de muchos calendarios posibles. Algunos de ellos solo se usan en regiones específicas, como el calendario lunar. Algunos de ellos solo se usan en la historia, como el calendario juliano. En este punto, el calendario gregoriano es el estándar internacional de facto y se utiliza en casi todo el mundo para fines civiles. Fue introducido en 1582 y se extiende para admitir fechas anteriores a 1582 también. Este calendario extendido se llama el calendario gregoriano proléptico.
A partir de la versión 3.0, Spark utiliza el calendario gregoriano proléptico, que ya está siendo utilizado por otros sistemas de datos como pandas, R y Apache Arrow. Antes de Spark 3.0, utilizaba una combinación del calendario juliano y gregoriano: para fechas anteriores a 1582, se utilizaba el calendario juliano; para fechas posteriores a 1582, se utilizaba el calendario gregoriano. Esto se hereda de la API heredada java.sql.Date, que fue reemplazada en Java 8 por java.time.LocalDate, que también utiliza el calendario gregoriano proléptico.
Cabe destacar que el tipo Date no tiene en cuenta las zonas horarias.
Marca de tiempo y zona horaria
El tipo Timestamp extiende el tipo Date con nuevos campos: hora, minuto, segundo (que puede tener una parte fraccionaria) y junto con una zona horaria global (con ámbito de sesión). Define un instante de tiempo concreto en la Tierra. Por ejemplo, (año=2012, mes=12, día=31, hora=23, minuto=59, segundo=59.123456) con zona horaria de sesión UTC+01:00. Al escribir valores de marca de tiempo en fuentes de datos no textuales como Parquet, los valores son solo instantes (como marcas de tiempo en UTC) que no tienen información de zona horaria. Si escribe y lee un valor de marca de tiempo con una zona horaria de sesión diferente, puede ver valores diferentes de los campos de hora/minuto/segundo, pero en realidad son el mismo instante de tiempo concreto.
Los campos de hora, minuto y segundo tienen rangos estándar: 0–23 para horas y 0–59 para minutos y segundos. Spark admite segundos fraccionarios con precisión de hasta microsegundos. El rango válido para las fracciones es de 0 a 999,999 microsegundos.
En cualquier instante concreto, podemos observar muchos valores diferentes de relojes de pared, dependiendo de la zona horaria.
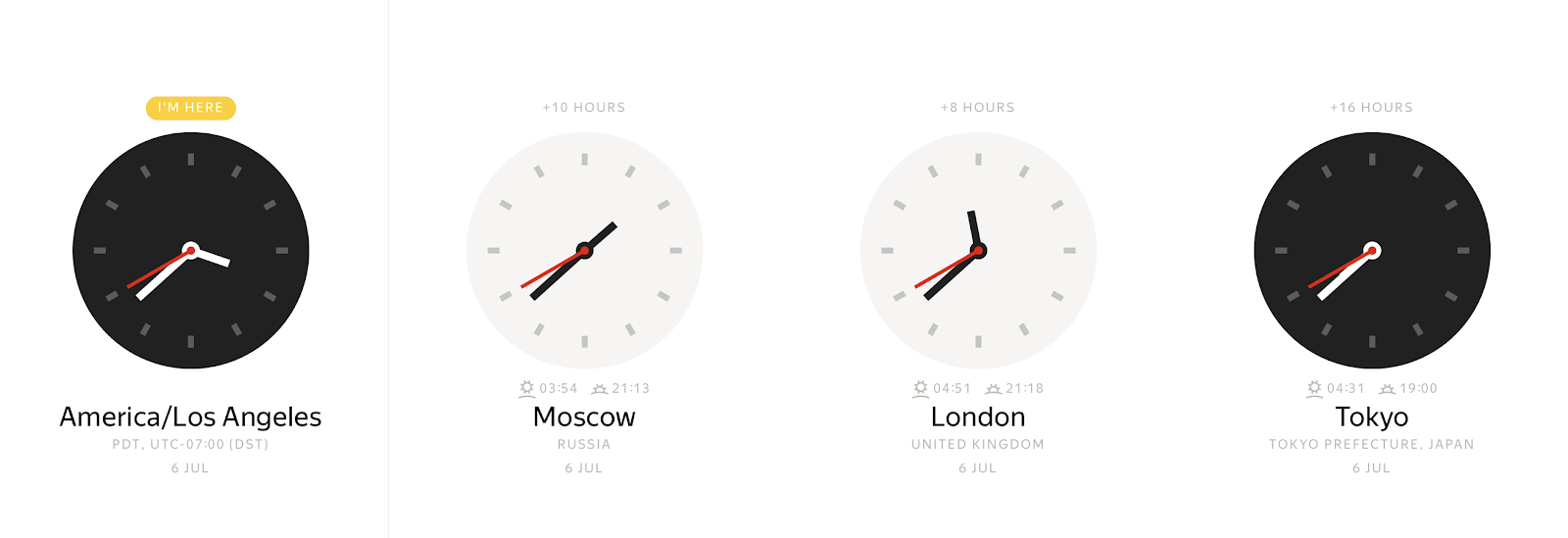
Y a la inversa, cualquier valor en los relojes de pared puede representar muchos instantes de tiempo diferentes. El desplazamiento de la zona horaria nos permite vincular de forma inequívoca una marca de tiempo local a un instante de tiempo. Por lo general, los desplazamientos de zona horaria se definen como desplazamientos en horas desde Greenwich Mean Time (GMT) o UTC+0 (Tiempo Universal Coordinado). Dicha representación de la información de la zona horaria elimina la ambigüedad, pero es inconveniente para los usuarios finales. Los usuarios prefieren indicar una ubicación en el mundo como America/Los_Angeles o Europe/Paris.
Este nivel adicional de abstracción de los desplazamientos de zona facilita las cosas, pero trae sus propios problemas. Por ejemplo, ahora tenemos que mantener una base de datos especial de zonas horarias para mapear nombres de zonas horarias a desplazamientos. Dado que Spark se ejecuta en la JVM, delega el mapeo a la biblioteca estándar de Java, que carga datos de la Base de Datos de Zonas Horarias de la Autoridad de Números Asignados de Internet (IANA TZDB). Además, el mecanismo de mapeo en la biblioteca estándar de Java tiene algunos matices que influyen en el comportamiento de Spark. Nos centramos en algunos de estos matices a continuación.
Desde Java 8, el JDK ha expuesto una nueva API para la manipulación de fechas y horas y la resolución de desplazamientos de zonas horarias, y Spark migró a esta nueva API en la versión 3.0. Aunque el mapeo de nombres de zonas horarias a desplazamientos tiene la misma fuente, IANA TZDB, se implementa de manera diferente en Java 8 y superior en comparación con Java 7.
Como ejemplo, echemos un vistazo a una marca de tiempo anterior al año 1883 en la zona horaria 
America/Los_Angeles: 1883-11-10 00:00:00. Este año destaca de otros porque el 18 de noviembre de 1883, todos los ferrocarriles de América del Norte cambiaron a un nuevo sistema de hora estándar que en adelante regiría sus horarios.
Usando la API de tiempo de Java 7, podemos obtener el desplazamiento de la zona horaria en la marca de tiempo local como -08:00:
Las funciones de la API de Java 8 devuelven un resultado diferente:
Antes del 18 de noviembre de 1883, la hora del día era un asunto local, y la mayoría de las ciudades y pueblos utilizaban alguna forma de hora solar local, mantenida por un reloj conocido (en la torre de una iglesia, por ejemplo, o en la ventana de un joyero). Es por eso que vemos un desplazamiento de zona horaria tan extraño.
El ejemplo demuestra que las funciones de Java 8 son más precisas y tienen en cuenta los datos históricos de IANA TZDB. Después de cambiar a la API de tiempo de Java 8, Spark 3.0 se benefició automáticamente de la mejora y se volvió más preciso en cómo resuelve los desplazamientos de zona horaria.
Como mencionamos anteriormente, Spark 3.0 también cambió al calendario gregoriano proléptico para el tipo de fecha. Lo mismo ocurre con el tipo de marca de tiempo. El estándar ISO SQL:2016 declara que el rango válido para las marcas de tiempo es de 0001-01-01 00:00:00 a 9999-12-31 23:59:59.999999. Spark 3.0 se ajusta completamente al estándar y admite todas las marcas de tiempo en este rango. En comparación con Spark 2.4 y anteriores, debemos destacar los siguientes subrangos:
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Spark 2.4 utiliza el calendario juliano y no se ajusta al estándar. Spark 3.0 corrige el problema y aplica el calendario gregoriano proléptico en operaciones internas sobre marcas de tiempo, como obtener el año, mes, día, etc. Debido a los diferentes calendarios, algunas fechas que existen en Spark 2.4 no existen en Spark 3.0. Por ejemplo, 1000-02-29 no es una fecha válida porque 1000 no es un año bisiesto en el calendario gregoriano. Además, Spark 2.4 resuelve incorrectamente el nombre de la zona horaria a los desplazamientos de zona para este rango de marcas de tiempo.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Este es un rango válido de marcas de tiempo locales en Spark 3.0, en contraste con Spark 2.4 donde tales marcas de tiempo no existían.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Spark 3.0 resuelve correctamente los desplazamientos de zona horaria utilizando datos históricos de IANA TZDB. En comparación con Spark 3.0, Spark 2.4 puede resolver incorrectamente los desplazamientos de zona a partir de nombres de zona horaria en algunos casos, como mostramos anteriormente en el ejemplo.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Tanto Spark 3.0 como Spark 2.4 cumplen con el estándar SQL ANSI y utilizan el calendario gregoriano en operaciones de fecha y hora, como la obtención del día del mes.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Spark 2.4 puede resolver los desfases horarios y, en particular, los desfases de horario de verano de forma incorrecta debido al error #8073446 de JDK. Spark 3.0 no sufre este defecto.
Otro aspecto del mapeo de nombres de zonas horarias a desfases es la superposición de marcas de tiempo locales que puede ocurrir debido al horario de verano (DST) o al cambio a otro desfase horario estándar. Por ejemplo, el 3 de noviembre de 2019, 02:00:00, los relojes se adelantaron 1 hora a las 01:00:00. La marca de tiempo local 
2019-11-03 01:30:00 America/Los_Angeles puede mapearse a 2019-11-03 01:30:00 UTC-08:00 o 2019-11-03 01:30:00 UTC-07:00. Si no especificas el desfase y solo estableces el nombre de la zona horaria (por ejemplo, '2019-11-03 01:30:00 America/Los_Angeles'), Spark 3.0 tomará el desfase anterior, que normalmente corresponde al "verano". El comportamiento difiere de Spark 2.4, que toma el desfase de "invierno". En caso de una brecha, donde los relojes avanzan, no hay un desfase válido. Para un cambio típico de horario de verano de una hora, Spark moverá dichas marcas de tiempo a la siguiente marca de tiempo válida correspondiente al horario de "verano".
Como podemos ver en los ejemplos anteriores, el mapeo de nombres de zonas horarias a desfases es ambiguo y no es uno a uno. En los casos en que sea posible, recomendamos especificar desfases horarios exactos al crear marcas de tiempo, por ejemplo timestamp '2019-11-03 01:30:00 UTC-07:00'.
Pasemos del mapeo de nombres de zona a desfases y veamos el estándar SQL ANSI. Define dos tipos de marcas de tiempo:
TIMESTAMP WITHOUT TIME ZONEoTIMESTAMP: Marca de tiempo local como (AÑO, MES, DÍA, HORA, MINUTO, SEGUNDO). Estos tipos de marcas de tiempo no están vinculados a ninguna zona horaria y, de hecho, son marcas de tiempo de reloj de pared.TIMESTAMP WITH TIME ZONE: Marca de tiempo con zona horaria como (AÑO, MES, DÍA, HORA, MINUTO, SEGUNDO, HORA_ZONA_HORARIA, MINUTO_ZONA_HORARIA). Las marcas de tiempo representan un instante en la zona horaria UTC + un desfase de zona horaria (en horas y minutos) asociado a cada valor.
El desfase de zona horaria de un TIMESTAMP WITH TIME ZONE no afecta al punto físico en el tiempo que representa la marca de tiempo, ya que este está completamente representado por el instante de tiempo UTC dado por los otros componentes de la marca de tiempo. En cambio, el desfase de zona horaria solo afecta al comportamiento predeterminado de un valor de marca de tiempo para la visualización, la extracción de componentes de fecha/hora (por ejemplo, EXTRACT) y otras operaciones que requieren conocer una zona horaria, como sumar meses a una marca de tiempo.
Spark SQL define el tipo de marca de tiempo como TIMESTAMP WITH SESSION TIME ZONE, que es una combinación de los campos (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) donde el campo YEAR a SECOND identifica un instante de tiempo en la zona horaria UTC, y donde SESSION TZ se toma de la configuración SQL spark.sql.session.timeZone. La zona horaria de la sesión se puede establecer como:
- Desfase de zona
'(+|-)HH:mm'. Esta forma nos permite definir un punto físico en el tiempo sin ambigüedades. - Nombre de zona horaria en forma de ID de región
'area/city', como'America/Los_Angeles'. Esta forma de información de zona horaria sufre algunos de los problemas que describimos anteriormente, como la superposición de marcas de tiempo locales. Sin embargo, cada instante de tiempo UTC se asocia sin ambigüedades con un desfase de zona horaria para cualquier ID de región, y como resultado, cada marca de tiempo con una zona horaria basada en ID de región puede convertirse sin ambigüedades a una marca de tiempo con un desfase de zona.
Por defecto, la zona horaria de la sesión se establece en la zona horaria predeterminada de la máquina virtual de Java.
TIMESTAMP WITH SESSION TIME ZONE de Spark es diferente de:
TIMESTAMP WITHOUT TIME ZONE, porque un valor de este tipo puede mapearse a múltiples instantes físicos de tiempo, pero cualquier valor deTIMESTAMP WITH SESSION TIME ZONEes un instante físico de tiempo concreto. El tipo SQL puede emularse utilizando un desfase de zona horaria fijo en todas las sesiones, por ejemplo, UTC+0. En ese caso, podríamos considerar las marcas de tiempo en UTC como marcas de tiempo locales.TIMESTAMP WITH TIME ZONE, porque según el estándar SQL, los valores de columna de este tipo pueden tener diferentes desfases de zona horaria. Spark SQL no admite esto.
Debemos notar que las marcas de tiempo asociadas a una zona horaria global (con ámbito de sesión) no son algo inventado recientemente por Spark SQL. Los SGBDR como Oracle también proporcionan un tipo similar para las marcas de tiempo: TIMESTAMP WITH LOCAL TIME ZONE.
Construcción de fechas y marcas de tiempo
Spark SQL proporciona varios métodos para construir valores de fecha y marca de tiempo:
- Constructores predeterminados sin parámetros:
CURRENT_TIMESTAMP()yCURRENT_DATE(). - A partir de otros tipos primitivos de Spark SQL, como
INT,LONGySTRING. - A partir de tipos externos como
datetimede Python o clases de Javajava.time.LocalDate/Instant. - Deserialización de fuentes de datos CSV, JSON, Avro, Parquet, ORC u otras.
La función MAKE_DATE introducida en Spark 3.0 toma tres parámetros: YEAR, MONTH del año y DAY del mes, y crea un valor DATE. Todos los parámetros de entrada se convierten implícitamente al tipo INT siempre que sea posible. La función comprueba que las fechas resultantes sean fechas válidas en el calendario gregoriano proléptico, de lo contrario devuelve NULL. Por ejemplo, en PySpark:
Para mostrar el contenido del DataFrame, llamamos a la acción show(), que convierte las fechas a cadenas en los ejecutores y transfiere las cadenas al controlador para mostrarlas en la consola:
De forma similar, podemos crear valores de marca de tiempo a través de las funciones MAKE_TIMESTAMP. Al igual que MAKE_DATE, realiza la misma validación para los campos de fecha y, además, acepta campos de hora HOUR (0-23), MINUTE (0-59) y SECOND (0-60). SECOND tiene el tipo Decimal(precisión = 8, escala = 6) porque los segundos se pueden pasar con la parte fraccionaria hasta precisión de microsegundo. Por ejemplo, en PySpark:
Como hicimos para las fechas, mostremos el contenido del DataFrame ts usando la acción show(). De manera similar, show() convierte las marcas de tiempo a cadenas, pero ahora tiene en cuenta la zona horaria de la sesión definida por la configuración SQL spark.sql.session.timeZone. Veremos esto en los siguientes ejemplos.
Spark no puede crear la última marca de tiempo porque esta fecha no es válida: 2019 no es un año bisiesto.
Es posible que notes que no proporcionamos información de zona horaria en el ejemplo anterior. En ese caso, Spark toma una zona horaria de la configuración SQL spark.sql.session.timeZone y la aplica a las invocaciones de funciones. También puedes elegir una zona horaria diferente pasándola como último parámetro de MAKE_TIMESTAMP. Aquí tienes un ejemplo en PySpark:
Como demuestra el ejemplo, Spark tiene en cuenta las zonas horarias especificadas, pero ajusta todas las marcas de tiempo locales a la zona horaria de la sesión. Las zonas horarias originales pasadas a la función MAKE_TIMESTAMP se perderán porque el tipo TIMESTAMP WITH SESSION TIME ZONE asume que todos los valores pertenecen a una zona horaria y ni siquiera almacena una zona horaria por cada valor. Según la definición de TIMESTAMP WITH SESSION TIME ZONE, Spark almacena marcas de tiempo locales en la zona horaria UTC y utiliza la zona horaria de la sesión al extraer campos de fecha y hora o al convertir las marcas de tiempo a cadenas.
Además, las marcas de tiempo se pueden construir a partir del tipo LONG mediante conversión. Si una columna LONG contiene el número de segundos desde la época 1970-01-01 00:00:00Z, se puede convertir a TIMESTAMP de Spark SQL:
Desafortunadamente, este enfoque no nos permite especificar la parte fraccionaria de los segundos. En el futuro, Spark SQL proporcionará funciones especiales para crear marcas de tiempo a partir de segundos, milisegundos y microsegundos desde la época: timestamp_seconds(), timestamp_millis() y timestamp_micros().
Otra forma es construir fechas y marcas de tiempo a partir de valores del tipo STRING. Podemos crear literales usando palabras clave especiales:
o mediante conversión, que podemos aplicar a todos los valores de una columna:
Las cadenas de marca de tiempo de entrada se interpretan como marcas de tiempo locales en la zona horaria especificada o en la zona horaria de la sesión si se omite una zona horaria en la cadena de entrada. Las cadenas con patrones inusuales se pueden convertir a marca de tiempo usando la función to_timestamp(). Los patrones admitidos se describen en Patrones de fecha y hora para formatear y analizar:
La función se comporta de manera similar a CAST si no se especifica ningún patrón.
Para mayor facilidad de uso, Spark SQL reconoce valores de cadena especiales en todos los métodos anteriores que aceptan una cadena y devuelven una marca de tiempo y una fecha:
- epoch es un alias para date '1970-01-01' o timestamp
'1970-01-01 00:00:00Z' - now es la marca de tiempo o fecha actual en la zona horaria de la sesión. Dentro de una misma consulta, siempre produce el mismo resultado.
- today es el inicio del día actual para el tipo
TIMESTAMPo simplemente la fecha actual para el tipoDATE. - tomorrow es el inicio del día siguiente para marcas de tiempo o simplemente el día siguiente para el tipo
DATE. - yesterday es el día anterior al actual o su inicio para el tipo
TIMESTAMP.
Por ejemplo:
Una de las grandes características de Spark es la creación de Datasets a partir de colecciones existentes de objetos externos en el lado del driver, y la creación de columnas de tipos correspondientes. Spark convierte instancias de tipos externos en representaciones internas semánticamente equivalentes. PySpark permite crear un Dataset con columnas DATE y TIMESTAMP a partir de colecciones de Python, por ejemplo:
PySpark convierte los objetos datetime de Python en representaciones internas de Spark SQL en el lado del driver utilizando la zona horaria del sistema, que puede ser diferente de la configuración de la zona horaria de la sesión de Spark spark.sql.session.timeZone. Los valores internos no contienen informaci�ón sobre la zona horaria original. Las operaciones futuras sobre las fechas y marcas de tiempo paralelizadas tendrán en cuenta solo la zona horaria de las sesiones de Spark SQL según la definición del tipo TIMESTAMP WITH SESSION TIME ZONE.
De manera similar a como demostramos anteriormente para las colecciones de Python, Spark reconoce los siguientes tipos como tipos de fecha y hora externos en las API de Java/Scala:
- java.sql.Date y java.time.LocalDate como tipos externos para el tipo DATE de Spark SQL
- java.sql.Timestamp y java.time.Instant para el tipo TIMESTAMP.
Hay una diferencia entre los tipos java.sql.* y java.time.*. java.time.LocalDate y java.time.Instant se añadieron en Java 8, y los tipos se basan en el calendario gregoriano proléptico — el mismo calendario que utiliza Spark a partir de la versión 3.0. java.sql.Date y java.sql.Timestamp tienen otro calendario subyacente — el calendario híbrido (Juliano + Gregoriano desde 1582-10-15), que es el mismo que el calendario heredado utilizado por las versiones de Spark anteriores a la 3.0. Debido a los diferentes sistemas de calendario, Spark tiene que realizar operaciones adicionales durante las conversiones a representaciones internas de Spark SQL, y rebasar las fechas/marcas de tiempo de entrada de un calendario a otro. La operación de rebase tiene una pequeña sobrecarga para las marcas de tiempo modernas después del año 1900, y puede ser más significativa para las marcas de tiempo antiguas.
El siguiente ejemplo muestra la creación de marcas de tiempo a partir de colecciones de Scala. En el primer ejemplo, construimos un objeto java.sql.Timestamp a partir de una cadena. El método valueOf interpreta las cadenas de entrada como una marca de tiempo local en la zona horaria predeterminada de la JVM, que puede ser diferente de la zona horaria de la sesión de Spark. Si necesita construir instancias de java.sql.Timestamp o java.sql.Date en una zona horaria específica, le recomendamos que consulte java.text.SimpleDateFormat (y su método setTimeZone) o java.util.Calendar.
De manera similar, podemos crear una columna DATE a partir de colecciones de java.sql.Date o java.LocalDate. La paralelización de instancias de java.LocalDate es completamente independiente de la zona horaria de la sesión de Spark o de la zona horaria predeterminada de la JVM, pero no podemos decir lo mismo de la paralelización de instancias de java.sql.Date. Hay matices:
- Las instancias de
java.sql.Daterepresentan fechas locales en la zona horaria predeterminada de la JVM en el driver - Para conversiones correctas a valores de Spark SQL, la zona horaria predeterminada de la JVM en el driver y los ejecutores debe ser la misma.
Para evitar cualquier problema relacionado con el calendario y la zona horaria, recomendamos los tipos de Java 8 java.LocalDate/Instant como tipos externos en la paralelización de colecciones de Java/Scala de marcas de tiempo o fechas.
Recopilación de fechas y marcas de tiempo
La operación inversa a la paralelización es recopilar fechas y marcas de tiempo desde los ejecutores de vuelta al driver y devolver una colección de tipos externos. Por ejemplo, podemos traer el DataFrame de vuelta al driver mediante la acción collect():
Spark transfiere los valores internos de las columnas de fechas y marcas de tiempo como instantes de tiempo en la zona horaria UTC desde los ejecutores al controlador, y realiza conversiones a objetos datetime de Python en la zona horaria del sistema en el controlador, sin usar la zona horaria de la sesión de Spark SQL. collect() es diferente de la acción show() descrita en la sección anterior. show() utiliza la zona horaria de la sesión al convertir marcas de tiempo a cadenas, y recopila las cadenas resultantes en el controlador.
En las API de Java y Scala, Spark realiza las siguientes conversiones de forma predeterminada:
- Los valores
DATEde Spark SQL se convierten en instancias dejava.sql.Date. - Las marcas de tiempo se convierten en instancias de
java.sql.Timestamp.
Ambas conversiones se realizan en la zona horaria predeterminada de la JVM en el controlador. De esta manera, para tener los mismos campos de fecha y hora que podemos obtener a través de Date.getDay(), getHour(), etc. y a través de las funciones de Spark SQL DAY, HOUR, la zona horaria predeterminada de la JVM en el controlador y la zona horaria de la sesión en los ejecutores deben ser las mismas.
De forma similar a la creación de fechas/marcas de tiempo a partir de java.sql.Date/Timestamp, Spark 3.0 realiza un rebase del calendario gregoriano proléptico al calendario híbrido (juliano + gregoriano). Esta operación es casi gratuita para fechas modernas (después del año 1582) y marcas de tiempo (después del año 1900), pero podría generar cierta sobrecarga para fechas y marcas de tiempo antiguas.
Podemos evitar estos problemas relacionados con el calendario y pedirle a Spark que devuelva tipos java.time, que se agregaron desde Java 8. Si configuramos la configuración de SQL spark.sql.datetime.java8API.enabled en true, la acción Dataset.collect() devolverá:
java.time.LocalDatepara el tipoDATEde Spark SQLjava.time.Instantpara el tipoTIMESTAMPde Spark SQL
Ahora las conversiones no sufren los problemas relacionados con el calendario porque los tipos de Java 8 y Spark SQL 3.0 se basan ambos en el calendario gregoriano proléptico. La acción collect() ya no depende de la zona horaria predeterminada de la JVM. Las conversiones de marcas de tiempo no dependen de la zona horaria en absoluto. En cuanto a la conversión de fechas, utiliza la zona horaria de la sesión de la configuración de SQL spark.sql.session.timeZone. Por ejemplo, veamos un Dataset con columnas DATE y TIMESTAMP, configuremos la zona horaria predeterminada de la JVM en Europa/Moscú, pero la zona horaria de la sesión en America/Los_Angeles.
La acción show() imprime la marca de tiempo en la hora de la sesión America/Los_Angeles, pero si recopilamos el Dataset, se convertirá a java.sql.Timestamp y se imprimirá en Europe/Moscow mediante el método toString:
En realidad, la marca de tiempo local 2020-07-01 00:00:00 es 2020-07-01T07:00:00Z en UTC. Podemos observar esto si habilitamos la API de Java 8 y recopilamos el Dataset:
El objeto java.time.Instant se puede convertir a cualquier marca de tiempo local más tarde, independientemente de la zona horaria global de la JVM. Esta es una de las ventajas de java.time.Instant sobre java.sql.Timestamp. El primero requiere cambiar la configuración global de la JVM, lo que influye en otras marcas de tiempo de la misma JVM. Por lo tanto, si sus aplicaciones procesan fechas o marcas de tiempo en diferentes zonas horarias, y las aplicaciones no deben chocar entre sí al recopilar datos en el controlador a través de la API Dataset.collect() de Java/Scala, recomendamos cambiar a la API de Java 8 utilizando la configuración de SQL spark.sql.datetime.java8API.enabled.
Conclusión
En esta entrada de blog, describimos los tipos DATE y TIMESTAMP de Spark SQL. Mostramos cómo construir columnas de fecha y marca de tiempo a partir de otros tipos primitivos de Spark SQL y tipos externos de Java, y cómo recopilar columnas de fecha y marca de tiempo de vuelta al controlador como tipos externos de Java. Desde la versión 3.0, Spark cambió del calendario híbrido, que combina los calendarios juliano y gregoriano, al calendario gregoriano proléptico (ver SPARK-26651 para más detalles). Esto permitió a Spark eliminar muchos problemas como los que demostramos anteriormente. Para la compatibilidad con versiones anteriores, Spark todavía devuelve marcas de tiempo y fechas en el calendario híbrido (java.sql.Date y java.sql.Timestamp) desde las acciones de recopilación. Para evitar problemas de resolución de calendario y zona horaria al usar las acciones de recopilación de Java/Scala, la API de Java 8 se puede habilitar a través de la configuración de SQL spark.sql.datetime.java8API.enabled. Pruébelo hoy mismo gratis en Databricks como parte de nuestro Databricks Runtime 7.0.

Libro O'Reilly Learning Spark
La 2ª edición gratuita incluye actualizaciones sobre Spark 3.0, como las nuevas sugerencias de tipos de Python para Pandas UDFs, la nueva implementación de fecha/hora, etc.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.