Aplicación de cifrado a nivel de columna y evitación de duplicación de datos con PII
Uso de bibliotecas de cifrado Fernet, UDF y secretos de Databricks para proteger discretamente datos PII
por Keyuri Shah y Fred Kimball
Esta es una publicación invitada de Keyuri Shah, ingeniera de software principal, y Fred Kimball, ingeniero de software, Northwestern Mutual.
Proteger la PII (información de identificación personal) es muy importante, ya que el número de violaciones de datos y registros con información confidencial expuesta cada día tiende al alza. Para evitar ser la próxima víctima y proteger a los usuarios del robo de identidad y el fraude, necesitamos incorporar múltiples capas de seguridad de datos e información.
Como usamos la plataforma Databricks, debemos asegurarnos de que solo permitimos que las personas adecuadas accedan a la información confidencial. Utilizando una combinación de bibliotecas de cifrado Fernet, funciones definidas por el usuario (UDF) y secretos de Databricks, Northwestern Mutual ha desarrollado un proceso para cifrar la información PII y permitir que solo aquellos con una necesidad comercial la descifren, sin pasos adicionales necesarios para el lector de datos.
La necesidad de proteger la PII
Gestionar cualquier cantidad de datos de clientes hoy en día casi siempre requiere proteger la PII. Este es un gran riesgo para organizaciones de todos los tamaños, ya que casos como la violación de datos de Capital One resultaron en el robo de millones de registros confidenciales de clientes debido a un simple error de configuración. Si bien el cifrado del dispositivo de almacenamiento y el enmascaramiento de columnas a nivel de tabla son medidas de seguridad efectivas, el acceso interno no autorizado a estos datos confidenciales sigue representando una gran amenaza. Por lo tanto, necesitamos una solución que restrinja a un usuario normal con acceso a archivos o tablas a recuperar información confidencial dentro de Databricks.
Sin embargo, también necesitamos que aquellos con una necesidad comercial puedan leer información confidencial. No queremos que haya una diferencia en cómo cada tipo de usuario lee la tabla. Tanto las lecturas normales como las descifradas deben ocurrir en el mismo objeto Delta Lake para simplificar la construcción de consultas para el análisis de datos y la construcción de informes.
Creación del proceso para aplicar el cifrado a nivel de columna
Dados estos requisitos de seguridad, buscamos crear un proceso que fuera seguro, discreto y fácil de administrar. El siguiente diagrama proporciona una descripción general de alto nivel de los componentes necesarios para este proceso.
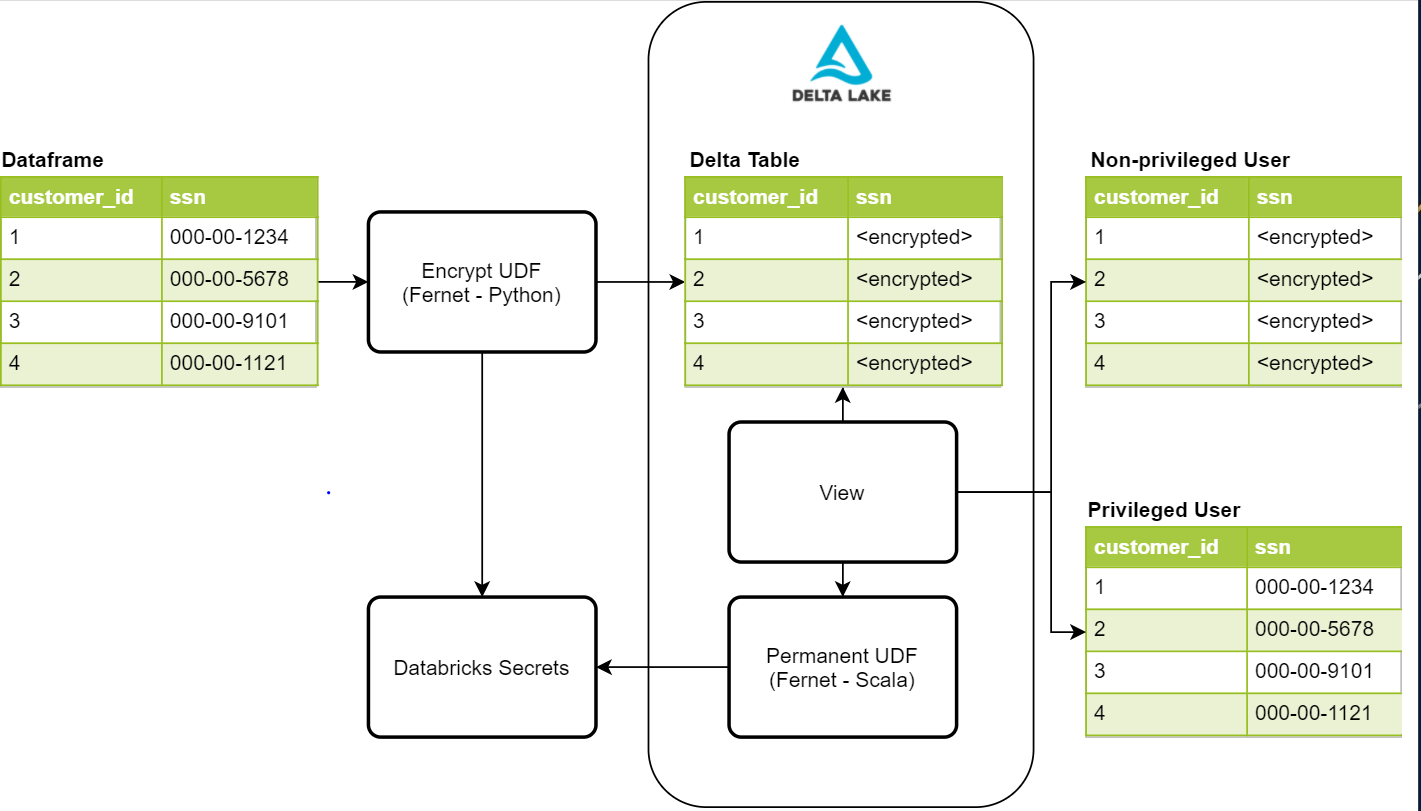
Escritura de PII protegida con Fernet
El primer paso en este proceso es proteger los datos cifrándolos. Una solución posible es la biblioteca Python Fernet. Fernet utiliza cifrado simétrico, que está construido con varias primitivas criptográficas estándar. Esta biblioteca se utiliza dentro de una UDF de cifrado que nos permitirá cifrar cualquier columna dada en un dataframe. Para almacenar la clave de cifrado, utilizamos secretos de Databricks con controles de acceso para permitir solo a nuestro proceso de ingesta de datos acceder a ella. Una vez que los datos se escriben en nuestras tablas de Delta Lake, las columnas PII que contienen valores como el número de seguro social, número de teléfono, número de tarjeta de crédito y otros identificadores serán imposibles de leer para un usuario no autorizado.
Lectura de datos protegidos desde una vista con UDF personalizada
Una vez que tenemos los datos confidenciales escritos y protegidos, necesitamos una forma para que los usuarios privilegiados lean los datos confidenciales. Lo primero que hay que hacer es crear una UDF permanente para agregar a la instancia de Hive que se ejecuta en Databricks. Para que una UDF sea permanente, debe estar escrita en Scala. Afortunadamente, Fernet también tiene una implementación de Scala que podemos aprovechar para nuestras lecturas descifradas. Esta UDF también accede al mismo secreto que utilizamos en la escritura cifrada para realizar el descifrado y, en este caso, se agrega a la configuración de Spark del clúster. Esto requiere que agreguemos controles de acceso al clúster para usuarios privilegiados y no privilegiados para controlar su acceso a la clave. Una vez creada la UDF, podemos usarla dentro de nuestras definiciones de vista para que los usuarios privilegiados vean los datos descifrados.
Actualmente, tenemos dos objetos de vista para un solo conjunto de datos, uno para usuarios privilegiados y otro para no privilegiados. La vista para usuarios no privilegiados no tiene la UDF, por lo que verán los valores PII como valores cifrados. La otra vista para usuarios privilegiados tiene la UDF, por lo que pueden ver los valores descifrados en texto plano para sus necesidades comerciales. El acceso a estas vistas también está controlado por los controles de acceso a tablas proporcionados por Databricks.
En un futuro cercano, queremos aprovechar una nueva función de Databricks llamada funciones de vista dinámica. Estas funciones de vista dinámica nos permitirán usar una sola vista y devolver fácilmente los valores cifrados o descifrados según el grupo de Databricks del que sean miembros. Esto reducirá la cantidad de objetos que creamos en nuestro Delta Lake y simplificará nuestras reglas de control de acceso a tablas.
Cualquiera de las implementaciones permite a los usuarios realizar su desarrollo o análisis sin preocuparse por si necesitan descifrar los valores leídos de la vista y solo permite el acceso a aquellos con una necesidad comercial.
Ventajas de este método de cifrado a nivel de columna
En resumen, las ventajas de usar este proceso son:
- El cifrado se puede realizar utilizando bibliotecas Python o Scala existentes
- Los datos PII confidenciales tienen una capa adicional de seguridad al almacenarse en Delta Lake
- El mismo objeto Delta Lake es utilizado por usuarios con todos los niveles de acceso a dicho objeto
- Los analistas no tienen obstáculos, independientemente de si están autorizados a leer PII
Como ejemplo de cómo podría ser esto, el siguiente notebook puede proporcionar alguna orientación:
Recursos adicionales:
Bibliotecas Fernet
Crear UDF permanente
Funciones de vista dinámica
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.