Presentación de perfiles de datos en Databricks Notebook
Simplificando el análisis exploratorio de datos
por Edward Gan, Moonsoo Lee y Austin Ford
Antes de que un científico de datos pueda escribir un informe sobre análisis o entrenar un modelo de machine learning (ML), necesita comprender la estructura y el contenido de sus datos. Este análisis exploratorio de datos es iterativo, y cada etapa del ciclo a menudo implica las mismas técnicas básicas: visualizar distribuciones de datos y calcular estadísticas resumidas como recuento de filas, recuento de nulos, media, frecuencias de elementos, etc. Desafortunadamente, generar manualmente estas visualizaciones y estadísticas es engorroso y propenso a errores, especialmente para conjuntos de datos grandes. Para abordar este desafío y simplificar el análisis exploratorio de datos, presentamos capacidades de perfilado de datos en Databricks Notebook.
Perfilado de datos en el Notebook
Los equipos de datos que trabajan en un clúster que ejecuta DBR 9.1 o una versión más reciente tienen dos formas de generar perfiles de datos en el Notebook: a través de la interfaz de usuario de salida de celda y a través de la biblioteca dbutils. Al ver el contenido de un DataFrame utilizando la función display de Databricks (AWS|Azure|Google) o los resultados de una consulta SQL, los usuarios verán una pestaña “Data Profile” a la derecha de la pestaña “Table” en la salida de la celda. Hacer clic en esta pestaña ejecutará automáticamente un nuevo comando que genera un perfil de los datos en el DataFrame. El perfil incluirá estadísticas resumidas para columnas numéricas, de cadena y de fecha, así como histogramas de las distribuciones de valores para cada columna. Tenga en cuenta que este comando perfilará todo el conjunto de datos en el DataFrame o los resultados de la consulta SQL, no solo la porción mostrada en la tabla (que puede estar truncada).
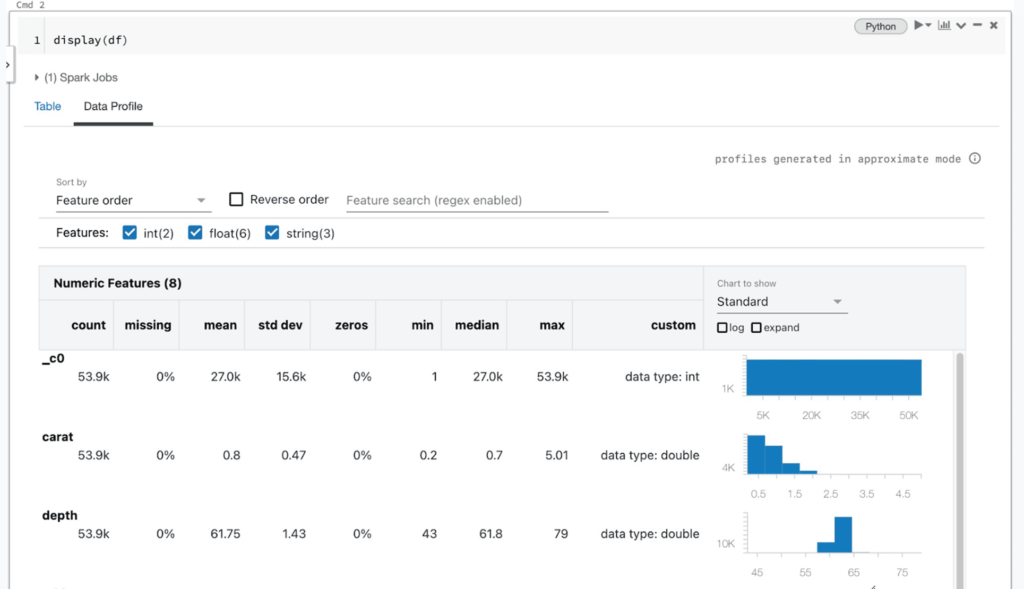
En segundo plano, la interfaz de usuario del notebook emite un nuevo comando para calcular un perfil de datos, que se implementa a través de una consulta Apache Spark™ generada automáticamente para cada conjunto de datos. Esta funcionalidad también está disponible a través de la API de dbutils en Python, Scala y R, utilizando el comando dbutils.data.summarize(df). Para obtener más información, consulte la documentación (AWS|Azure|Google).
¡Pruebe los perfiles de datos hoy mismo al previsualizar Dataframes en los notebooks de Databricks!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.