Escalado de cálculos de SHAP con PySpark y UDF de Pandas
por Sepideh Ebrahimi y P. Patel
Motivación
Con la proliferación de aplicaciones de modelos de Machine Learning (ML) y, especialmente, de Deep Learning (DL) en la toma de decisiones, se está volviendo más crucial ver a través de la caja negra y justificar decisiones de negocio clave basadas en los resultados de dichos modelos. Por ejemplo, si un modelo de ML rechaza la solicitud de préstamo de un cliente o le asigna un riesgo crediticio en un préstamo entre pares a un cliente determinado, darles a los responsables del negocio una explicación de por qué se tomó esta decisión podría ser una herramienta poderosa para fomentar la adopción de los modelos. En muchos casos, el ML interpretable no es solo un requisito del negocio, sino también un requisito normativo para comprender por qué se le dio una determinada decisión u opción a un cliente. SHapley Additive exPlanations (SHAP) es una herramienta importante que se puede aprovechar para la IA explicable y para ayudar a generar confianza en el resultado de los modelos de ML y las redes neuronales en la resolución de problemas de negocio.
SHAP es un framework de última generación para la explicación de modelos basado en la teoría de juegos. El enfoque implica encontrar una relación lineal entre las características de un modelo y el resultado del modelo para cada punto de datos en su conjunto de datos. Con este framework, puede interpretar el resultado de su modelo de forma global o local. La interpretabilidad global te ayuda a comprender cuánto contribuye cada característica a los resultados de forma positiva o negativa. Por otro lado, la interpretabilidad local te ayuda a comprender el efecto de cada característica para una observación determinada.
Las implementaciones SHAP más comunes y ampliamente adoptadas en la comunidad científica de datos se ejecutan en máquinas de un solo nodo, lo que significa que realizan todos los cálculos en un solo núcleo, independientemente del número de núcleos disponibles. Por lo tanto, no aprovechan las capacidades de cálculo distribuido y están limitadas por las restricciones de un solo núcleo.
En esta publicación, mostraremos una forma sencilla de paralelizar los cálculos de valores SHAP en varias máquinas, específicamente para la interpretabilidad local. A continuación, explicaremos cómo esta solución se adapta al creciente número de filas y columnas del conjunto de datos. Por último, destacaremos algunas de nuestras conclusiones sobre lo que funciona y lo que se debe evitar al paralelizar los cálculos SHAP con Spark.
SHAP de nodo único
Para lograr la explicabilidad, SHAP convierte un modelo en un Explainer; luego, las predicciones individuales del modelo se explican aplicándoles el Explainer. Existen varias implementaciones de cálculos de valores de SHAP en diferentes lenguajes de programación, incluida una muy popular en Python. Con esta implementación, para obtener explicaciones para cada observación, puede aplicar un explicador adecuado para su modelo. El siguiente fragmento de código ilustra cómo aplicar un TreeExplainer a un Random Forest Classifier.
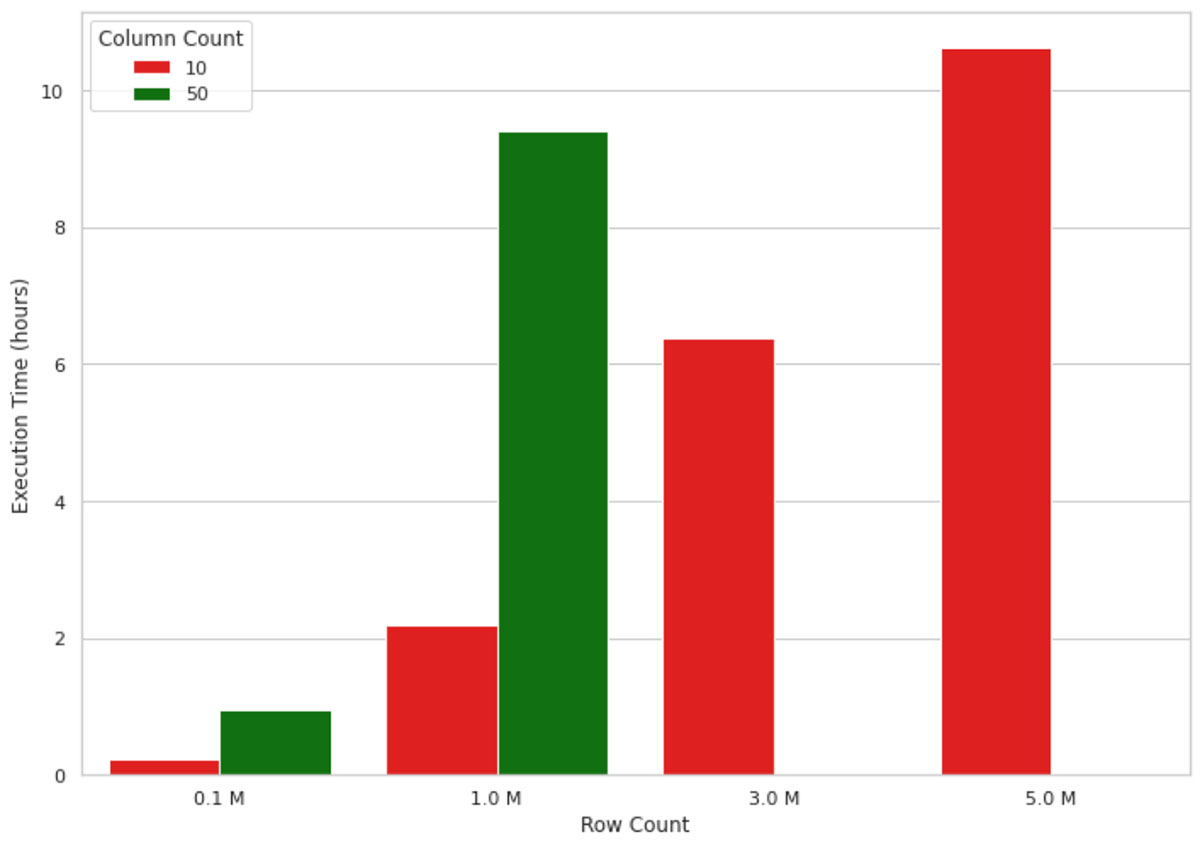
Este método funciona bien para volúmenes de datos pequeños, pero cuando se trata de explicar el resultado de un modelo de ML para millones de registros, no escala bien debido a la naturaleza de nodo único de la implementación. Por ejemplo, la visualización en la figura 1 a continuación muestra el aumento en el tiempo de ejecución de un cálculo de valor SHAP en una máquina de nodo único (4 núcleos y 30.5 GB de memoria) para un número creciente de registros. La máquina se quedó sin memoria para datos con dimensiones mayores a 1 millón de filas y 50 columnas, por lo tanto, esos valores faltan en la figura. Como se puede ver, el tiempo de ejecución crece de forma casi lineal con el número de registros, lo que no es sostenible en escenarios reales. Esperar, por ejemplo, 10 horas para entender por qué un modelo de machine learning ha hecho una predicción no es ni eficiente ni aceptable en muchos entornos empresariales.
Una forma de resolver este problema es mediante el uso del cálculo aproximado. Puedes establecer el argumento approximate en True en el método shap_values. De esa manera, las divisiones inferiores del árbol tendrán ponderaciones más altas y no hay garantía de que los valores SHAP sean consistentes con el cálculo exacto. Esto acelerará los cálculos, pero podrías obtener una explicación inexacta del resultado de tu modelo. Además, el argumento aproximado solo está disponible en los TreeExplainers.
Un enfoque alternativo sería aprovechar un marco de procesamiento distribuido como Apache Spark™ para paralelizar la aplicación del Explainer en múltiples núcleos.
Escalado de cálculos de SHAP con PySpark
Para distribuir los cálculos SHAP, estamos trabajando con esta implementación de Python y las funciones definidas por el usuario (UDF) de Pandas en PySpark. Estamos utilizando el conjunto de datos kddcup99 para crear un detector de intrusiones en la red, un modelo predictivo capaz de distinguir entre conexiones maliciosas, denominadas intrusiones o ataques, y conexiones normales y legítimas. Se sabe que este conjunto de datos tiene fallas para fines de detección de intrusiones. Sin embargo, en esta publicación, nos centramos exclusivamente en los cálculos del valor SHAP y no en la semántica del modelo de aprendizaje automático subyacente.
Los dos modelos que construimos para nuestros experimentos son clasificadores Random Forest simples entrenados en conjuntos de datos con 10 y 50 características para mostrar la escalabilidad de la solución en diferentes números de columnas. Ten en cuenta que el conjunto de datos original tiene menos de 50 columnas, y hemos replicado algunas de estas columnas para alcanzar el volumen de datos deseado. Los volúmenes de datos con los que hemos experimentado van desde 4 MB hasta 1.85 GB.
Antes de profundizar en el código, demos un repaso rápido de cómo funcionan los Dataframes de Spark y las UDF. Los Dataframes de Spark se distribuyen (por filas) en un clúster; cada agrupación de filas se denomina partición y cada partición (por defecto) puede ser procesada por 1 núcleo. Así es como Spark logra fundamentalmente el procesamiento en paralelo. Las UDF de Pandas son una opción natural, ya que pandas puede integrarse fácilmente con SHAP y ofrece un buen rendimiento. Una UDF de pandas, a veces conocida como UDF vectorizada, nos da un mejor rendimiento que las UDF de Python al utilizar Apache Arrow para optimizar la transferencia de datos.
El fragmento de código siguiente muestra cómo paralelizar la aplicación de un Explainer con una función definida por el usuario (UDF) de Pandas en PySpark. Definimos una función definida por el usuario (UDF) de pandas llamada calculate_shap y luego pasamos esta función a mapInPandas. A continuación, este método se utiliza para aplicar el método paralelizado al marco de datos PySpark. Utilizaremos esta UDF para ejecutar nuestras pruebas de rendimiento SHAP.
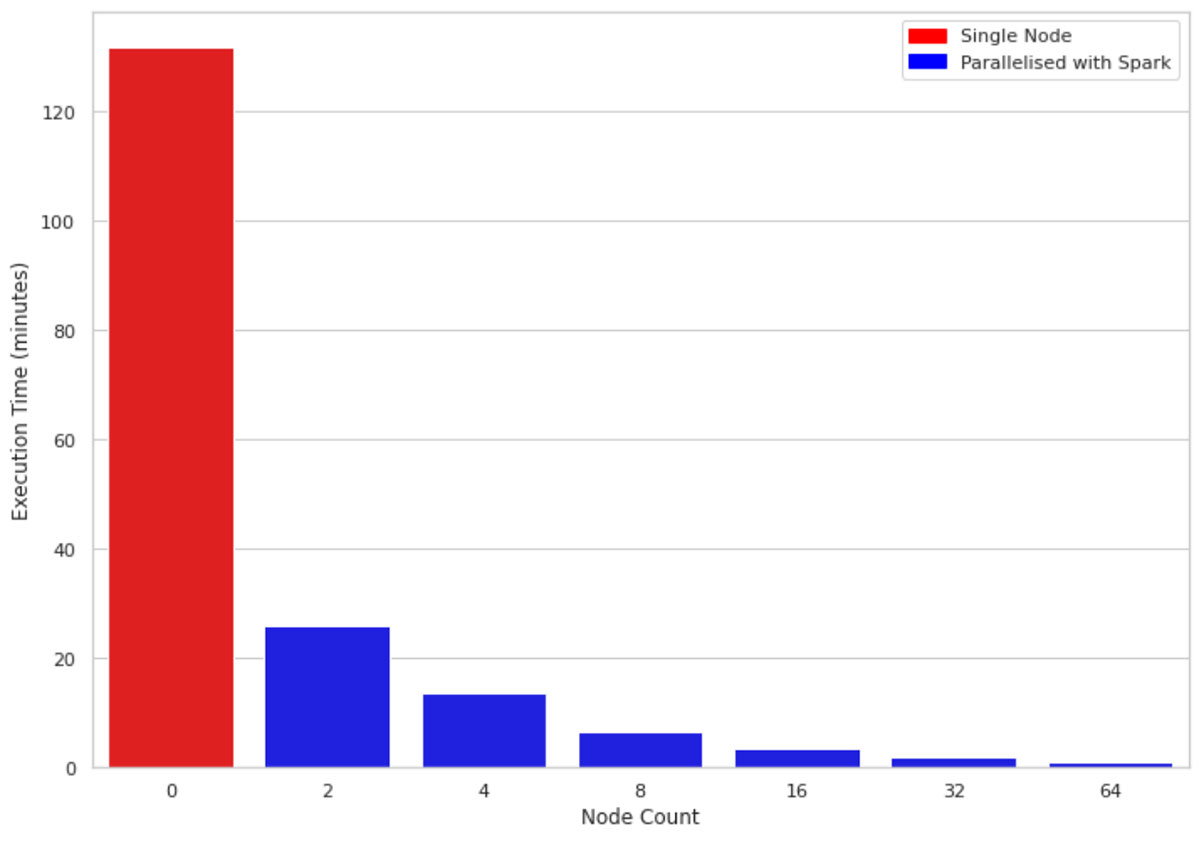
La Figura 2 compara el tiempo de ejecución de 1 millón de filas y 10 columnas en una máquina de un solo nodo frente a clústeres de tamaños 2, 4, 8, 16, 32 y 64, respectivamente. Las máquinas subyacentes para todos los clústeres son similares (4 núcleos y 30.5 GB de memoria). Una observación interesante es que el código paralelizado aprovecha todos los núcleos de los nodos del clúster. Por lo tanto, incluso el uso de un clúster de tamaño 2 mejora el rendimiento casi 5 veces.
Escalado con el aumento del tamaño de los datos
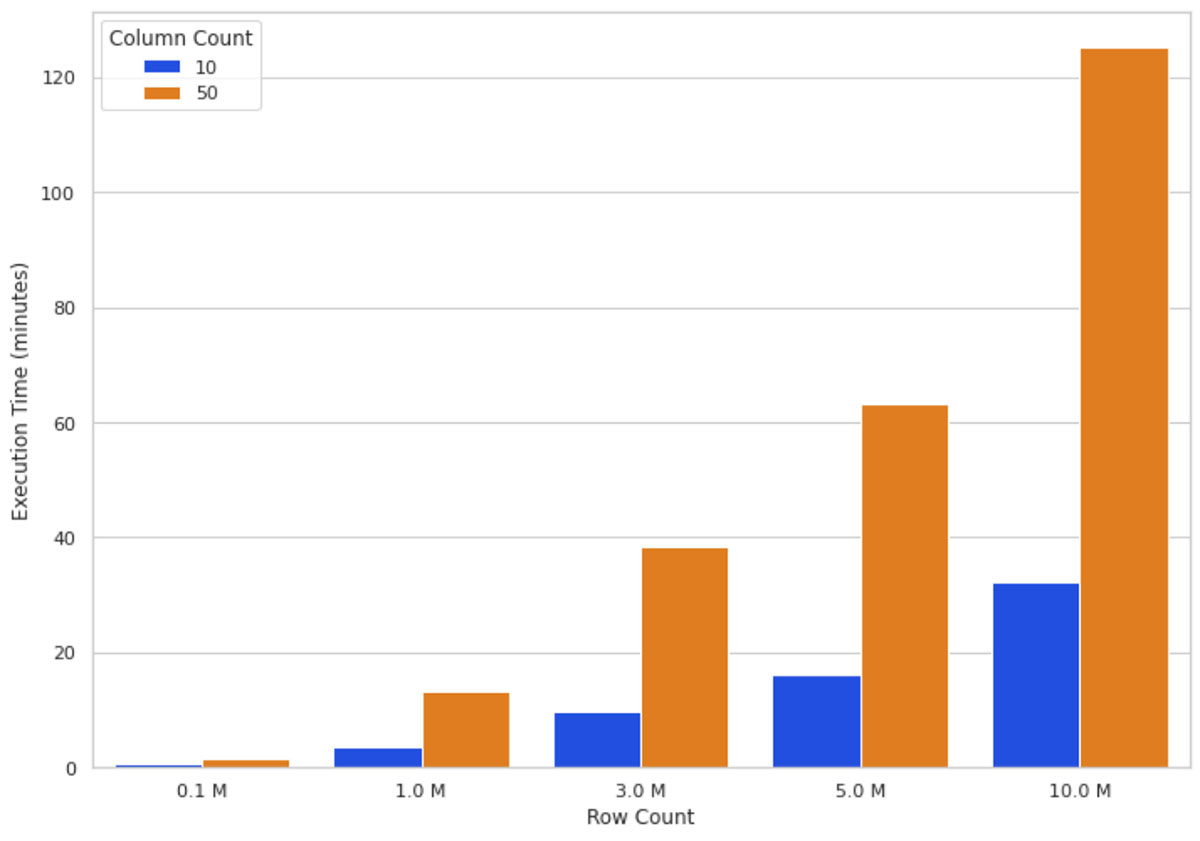
Debido a cómo se implementa SHAP, las características adicionales tienen un mayor impacto en el rendimiento que las filas adicionales. Ahora sabemos que los valores de SHAP se pueden calcular más rápido con Spark y UDF de Pandas. A continuación, veremos cómo se desempeña SHAP con características/columnas adicionales.
Intuitivamente, un aumento en el tamaño de los datos significa más cálculos que el algoritmo SHAP debe procesar. La Figura 3 ilustra los tiempos de ejecución de los valores SHAP en un clúster de 16 nodos para diferentes números de filas y columnas. Puedes ver que el escalado de las filas aumenta el tiempo de ejecución de manera casi directamente proporcional, es decir, duplicar el número de filas casi duplica el tiempo de ejecución. El escalado del número de columnas tiene una relación proporcional con el tiempo de ejecución; agregar una columna aumenta el tiempo de ejecución en casi un 80 %.
Estas observaciones (Figura 2 y Figura 3) nos llevaron a concluir que cuantos más datos tengas, más podrás escalar tu computación horizontalmente (añadiendo más nodos de trabajo) para mantener un tiempo de ejecución razonable.
¿Cuándo considerar la paralelización?
Las preguntas que queríamos responder son: ¿cuándo vale la pena la paralelización? ¿Cuándo se debería empezar a usar PySpark para paralelizar los cálculos de SHAP, incluso sabiendo que podría aumentar el cómputo? Configuramos un experimento para medir el efecto de duplicar el tamaño del clúster en la mejora del tiempo de ejecución del cálculo de SHAP. El objetivo del experimento es determinar qué tamaño de datos justifica añadir más recursos horizontales (es decir, agregar más nodos de trabajo) al problema.
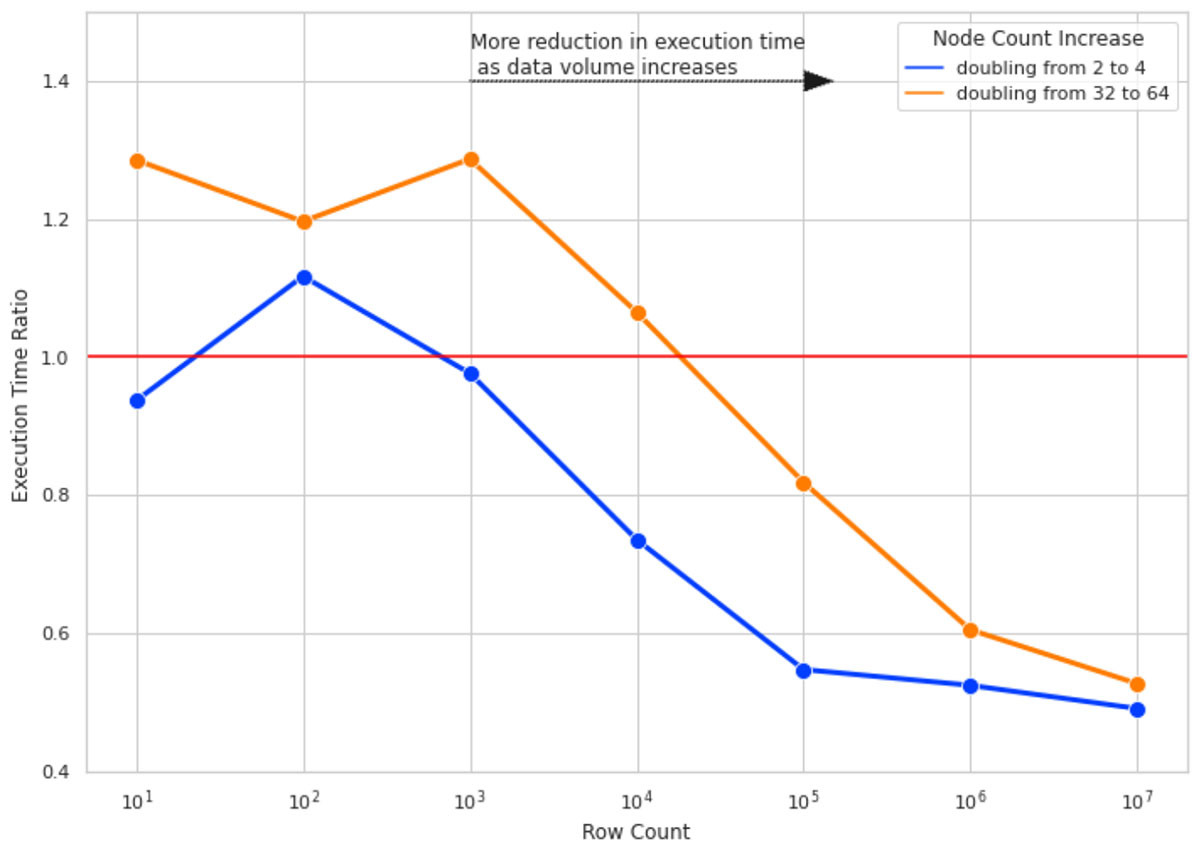
Ejecutamos los cálculos SHAP para 10 columnas de datos y para recuentos de filas de 10, 100, 1000 y así sucesivamente hasta 10 millones. Para cada recuento de filas, medimos el tiempo de ejecución del cálculo SHAP 4 veces para tamaños de clúster de 2, 4, 32 y 64. La relación de tiempo de ejecución es la relación entre el tiempo de ejecución del cálculo de valores SHAP en los tamaños de clúster más grandes (4 y 64) y la ejecución del mismo cálculo en un tamaño de clúster con la mitad del número de nodos (2 y 32, respectivamente).
La figura 4 ilustra el resultado de este experimento. Estos son los puntos clave:
-
- Para recuentos de filas pequeños, duplicar el tamaño del clúster no mejora el tiempo de ejecución y, en algunos casos, lo empeora debido a la sobrecarga que añade la gestión de tareas de Spark (de ahí que la relación de tiempo de ejecución sea > 1).
- A medida que aumentamos el número de filas, duplicar el tamaño del clúster se vuelve más eficaz. Para 10 millones de filas de datos, duplicar el tamaño del clúster casi reduce a la mitad el tiempo de ejecución.
- Para todos los recuentos de filas, duplicar el tamaño del clúster de 2 a 4 es más efectivo que duplicarlo de 32 a 64 (observa la diferencia entre las líneas azules y naranjas). A medida que aumenta el tamaño de tu clúster, también aumenta la sobrecarga que supone añadir más nodos. Esto se debe a que el tamaño de las particiones es demasiado pequeño y supone una mayor sobrecarga crear una tarea independiente para procesar la pequeña cantidad de datos que utilizar un tamaño de datos/partición más óptimo.
Posibles problemas
Reparticionamiento
Como se mencionó anteriormente, Spark implementa el paralelismo a través de la noción de particiones; los datos se dividen en fragmentos de filas y, por defecto, cada partición es procesada por un solo núcleo. Cuando Apache Spark lee inicialmente los datos, puede que no cree necesariamente particiones que sean óptimas para el cómputo que quieres ejecutar en tu clúster. En particular, para calcular los valores SHAP, podemos obtener un mejor rendimiento reparticionando nuestro conjunto de datos.
Es importante encontrar un equilibrio entre crear particiones lo suficientemente pequeñas y no tan pequeñas que la sobrecarga de crearlas supere los beneficios de paralelizar los cálculos.
Para nuestra prueba de rendimiento, decidimos utilizar todos los núcleos del clúster con el siguiente código:
Para volúmenes de datos aún mayores, es posible que desee establecer el número de particiones en 2 o 3 veces el número de núcleos. La clave es experimentar y encontrar la mejor estrategia de particionamiento para tus datos.
Uso de display()
Si estás trabajando en un Databricks Notebook, es posible que quieras evitar el uso de la función display() al evaluar los tiempos de ejecución. Es posible que el uso de display() no te muestre necesariamente cuánto tiempo tarda una transformación completa; tiene un límite de filas implícito que se inyecta en la consulta y, dependiendo de la operación que quieras medir (p. ej., escribir en un archivo), hay una sobrecarga adicional en la recopilación de los resultados de vuelta en el driver. Nuestros tiempos de ejecución se midieron utilizando el método write de Spark con el formato “noop”.
Conclusión
En esta entrada de blog, presentamos una solución para acelerar los cálculos de SHAP mediante su paralelización con PySpark y UDF de Pandas. Luego evaluamos el rendimiento de la solución en volúmenes de datos crecientes, diferentes tipos de máquinas y configuraciones cambiantes. Estos son los puntos clave:
-
-
- El cálculo de SHAP de nodo único crece linealmente con el número de filas y columnas.
- La paralelización de los cálculos SHAP con PySpark mejora el rendimiento al ejecutar los cálculos en todas las CPU de tu clúster.
- Aumentar el tamaño del clúster es más efectivo cuando se tienen mayores volúmenes de datos. Para datos pequeños, este método no es eficaz.
-
Trabajo futuro
Escalado vertical: el propósito de esta publicación de blog era mostrar cómo el escalado horizontal con grandes conjuntos de datos puede mejorar el rendimiento del cálculo de los valores SHAP. Partimos de la premisa de que cada nodo de nuestro clúster tenía 4 núcleos y 30.5 GB. En el futuro, sería interesante probar el rendimiento del escalado tanto vertical como horizontal; por ejemplo, comparar el rendimiento entre un clúster de 4 nodos (4 núcleos, 30.5 GB cada uno) y un clúster de 2 nodos (8 núcleos, 61 GB cada uno).
Serializar/Deserializar: como se mencionó, una de las razones principales para usar UDF de Pandas en lugar de UDF de Python es que las UDF de Pandas usan Apache Arrow para mejorar la serialización/deserialización de datos entre la JVM y el proceso de Python. Podría haber algunas optimizaciones potenciales al convertir las particiones de datos de Spark en lotes de registros de Arrow; experimentar con el tamaño del lote de Arrow podría generar mayores ganancias de rendimiento.
Comparación con implementaciones distribuidas de SHAP: sería interesante comparar los resultados de nuestra solución con implementaciones distribuidas de SHAP, como Shparkley. Al realizar un estudio comparativo de este tipo, sería importante asegurarse de que los resultados de ambas soluciones sean comparables en primer lugar.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.