Organización funcional del espacio de trabajo en Databricks
Fundamentos de Administración de Databricks: Blog 1/5
por Anindita Mahapatra y Greg Wood
Introducción
Este blog es la primera parte de nuestra serie Admin Essentials, donde nos centraremos en temas importantes para quienes administran y mantienen entornos de Databricks. ¡Esté atento a blogs adicionales sobre gobernanza de datos, operaciones y automatización, gestión de usuarios y accesibilidad, y seguimiento y gestión de costos en el futuro cercano!
En 2020, Databricks comenzó a lanzar versiones preliminares privadas de varias características de la plataforma conocidas colectivamente como Enterprise 2.0 (o E2); estas características proporcionaron la siguiente iteración de la plataforma Lakehouse, creando la escalabilidad y seguridad para igualar la potencia y velocidad ya disponibles en Databricks. Cuando Enterprise 2.0 se hizo disponible públicamente, una de las adiciones más esperadas fue la capacidad de crear múltiples espacios de trabajo desde una sola cuenta. Esta característica abrió nuevas posibilidades para la colaboración, la alineación organizacional y la simplificación. Sin embargo, como hemos descubierto desde entonces, también ha planteado una serie de preguntas. Basándonos en nuestra experiencia con clientes empresariales de todos los tamaños, formas y sectores, este blog presentará respuestas y mejores prácticas a las preguntas más comunes sobre la gestión de espacios de trabajo dentro de Databricks; a nivel fundamental, esto se reduce a una pregunta simple: ¿cuándo se debe crear un nuevo espacio de trabajo? Específicamente, destacaremos las estrategias clave para organizar sus espacios de trabajo y las mejores prácticas de cada una.
Conceptos básicos de organización de espacios de trabajo
Aunque cada proveedor de la nube (AWS, Azure y GCP) tiene una arquitectura subyacente diferente, la organización de los espacios de trabajo de Databricks entre nubes es similar. La construcción lógica de nivel superior es una cuenta maestra E2 (AWS) o un objeto de suscripción (Azure Databricks/GCP). En AWS, aprovisionamos una sola cuenta E2 por organización que proporciona un panel unificado de visibilidad y control para todos los espacios de trabajo. De esta manera, su actividad administrativa está centralizada, con la capacidad de habilitar SSO, Registros de auditoría y Unity Catalog. Azure tiene relativamente menos restricciones en la creación de objetos de suscripción de nivel superior; sin embargo, todavía recomendamos que el número de suscripciones de nivel superior utilizadas para crear espacios de trabajo de Databricks se controle tanto como sea posible. Nos referiremos a la construcción de nivel superior como una cuenta en este blog, ya sea una cuenta E2 de AWS o una suscripción de GCP/Azure.
Dentro de una cuenta de nivel superior, se pueden crear múltiples espacios de trabajo. El máximo recomendado de espacios de trabajo por cuenta está entre 20 y 50 en Azure, con un límite estricto en AWS. Este límite surge de la sobrecarga administrativa que proviene de un número creciente de espacios de trabajo: la gestión de la colaboración, el acceso y la seguridad en cientos de espacios de trabajo puede convertirse en una tarea extremadamente difícil, incluso con procesos de automatización excepcionales. A continuación, presentamos un modelo de objetos de alto nivel de una cuenta de Databricks.
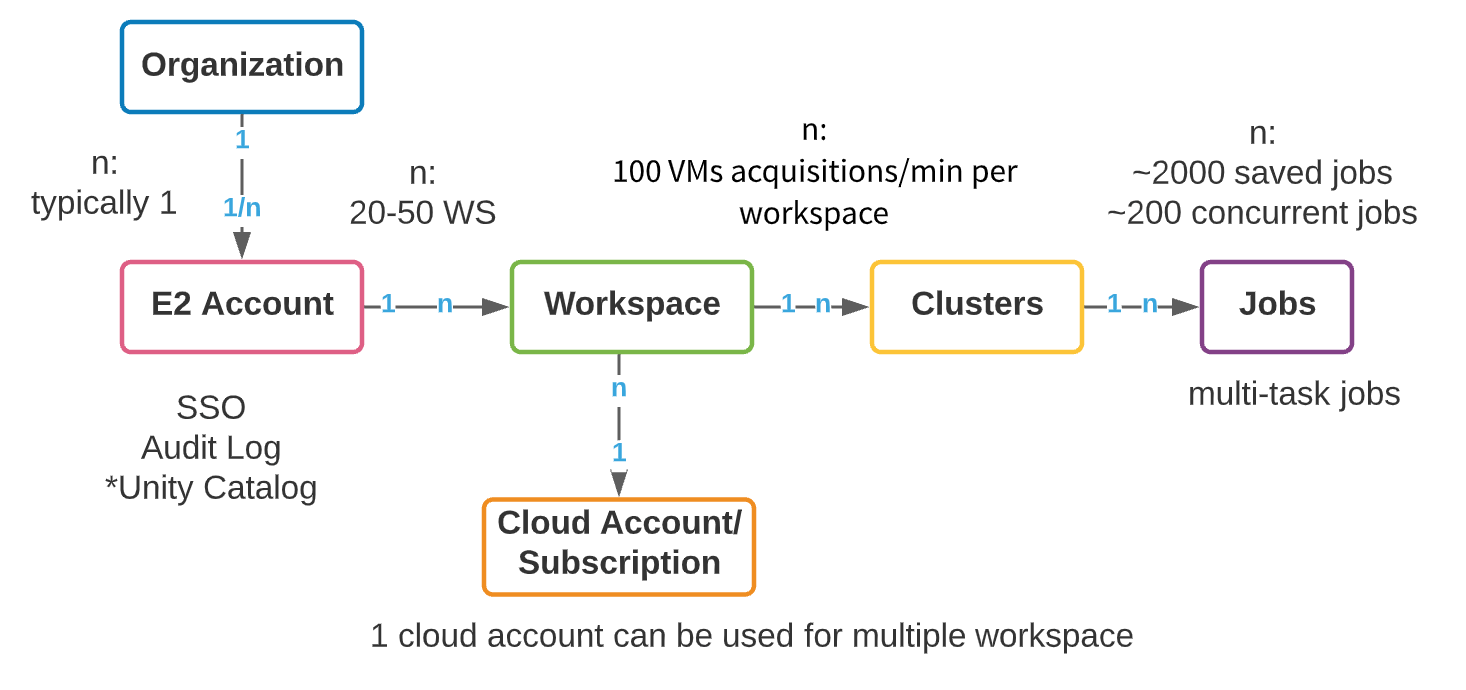
Las empresas necesitan crear recursos en su cuenta de la nube para admitir requisitos de multi-tenencia. La creación de cuentas y espacios de trabajo separados para cada nuevo caso de uso tiene algunas ventajas claras: facilidad de seguimiento de costos, aislamiento de datos y usuarios, y un radio de explosión menor en caso de incidentes de seguridad. Sin embargo, la proliferación de cuentas trae consigo un conjunto separado de complejidades: la gobernanza, la gestión de metadatos y la sobrecarga de colaboración crecen junto con el número de cuentas. La clave, por supuesto, es el equilibrio. A continuación, repasaremos algunas consideraciones generales para la organización de espacios de trabajo empresariales; luego, repasaremos dos estrategias comunes de aislamiento de espacios de trabajo que vemos entre nuestros clientes: basadas en LOB (Línea de Negocio) y basadas en productos. Cada una tiene fortalezas, debilidades y complejidades que discutiremos antes de dar las mejores prácticas.
Consideraciones generales de organización de espacios de trabajo
Al diseñar su estrategia de espacios de trabajo, lo primero que vemos que los clientes suelen hacer son las elecciones organizativas de macro nivel; sin embargo, ¡hay muchas decisiones de nivel inferior que son igual de importantes! Hemos recopilado las más pertinentes a continuación.
Un enfoque simple de tres espacios de trabajo
Aunque dedicamos la mayor parte de este blog a hablar sobre cómo dividir sus espacios de trabajo para obtener la máxima efectividad, ¡hay toda una clase de clientes de Databricks para quienes un solo espacio de trabajo unificado por entorno es más que suficiente! De hecho, esto se ha vuelto cada vez más práctico con el auge de características como Repos, Unity Catalog, páginas de inicio basadas en roles, etc. En tales casos, todavía recomendamos la separación de espacios de trabajo de Desarrollo, Staging y Producción para fines de validación y QA. Esto crea un entorno ideal para pequeñas empresas o equipos que valoran la agilidad sobre la complejidad.
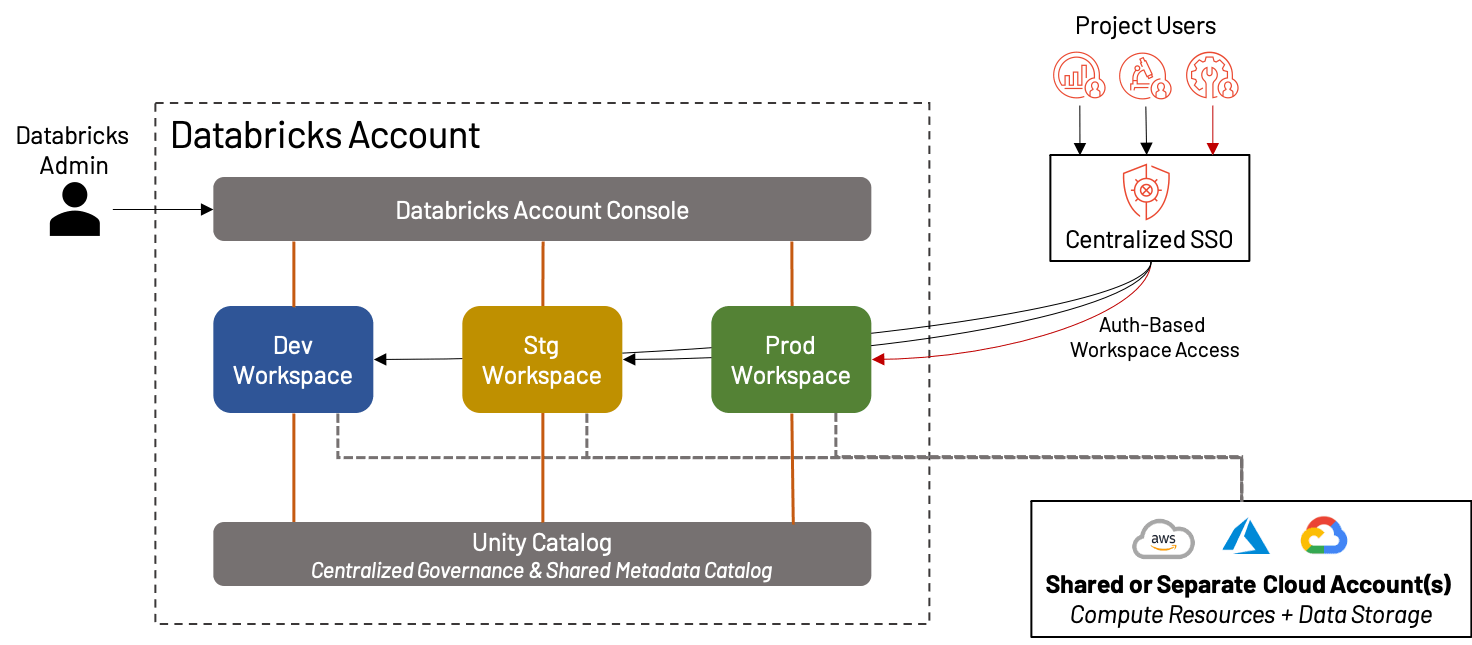
Los beneficios y desventajas de crear un solo conjunto de espacios de trabajo son:
+ No hay preocupación por saturar el espacio de trabajo internamente, mezclar activos o diluir el costo/uso en múltiples proyectos/equipos; todo está en el mismo entorno
+ La simplicidad de la organización significa una menor sobrecarga administrativa
- Para organizaciones más grandes, un solo espacio de trabajo de desarrollo/staging/producción no es viable debido a los límites de la plataforma, la saturación, la incapacidad de aislar datos y las preocupaciones de gobernanza
Si un solo conjunto de espacios de trabajo parece ser el enfoque correcto para usted, las siguientes mejores prácticas le ayudarán a mantener su Lakehouse funcionando sin problemas:
- Defina un proceso estandarizado para mover código entre los diversos entornos; dado que solo hay un conjunto de entornos, esto puede ser más simple que con otros enfoques. Aproveche características como Repos y Secrets y herramientas externas que fomenten buenos procesos de CI/CD para asegurarse de que sus transiciones ocurran de manera automática y fluida.
- Establezca y revise regularmente los grupos del Proveedor de Identidad que se mapean a los activos de Databricks; dado que estos grupos son el principal impulsor de la autorización de usuarios en esta estrategia, es crucial que sean precisos y que se mapeen a los datos y recursos de cómputo subyacentes apropiados. Por ejemplo, la mayoría de los usuarios probablemente no necesitan acceso al espacio de trabajo de producción; solo un pequeño grupo de ingenieros o administradores pueden tener los permisos.
- Mantén un ojo en tu uso y conoce los Límites de Recursos de Databricks; si el uso de tu espacio de trabajo o el número de usuarios comienza a crecer, es posible que necesites considerar la adopción de una estrategia de organización de espacios de trabajo más elaborada para evitar los límites por espacio de trabajo. Aprovecha el etiquetado de recursos siempre que sea posible para rastrear los costos y las métricas de uso.
Aprovechando los espacios de trabajo sandbox
En cualquiera de las estrategias mencionadas en este artículo, un entorno sandbox es una buena práctica para permitir a los usuarios incubar y desarrollar trabajos menos formales, pero aún potencialmente valiosos. Críticamente, estos entornos sandbox necesitan equilibrar la libertad de explorar datos reales con la protección contra el impacto no intencional (o intencional) en las cargas de trabajo de producción. Una práctica recomendada común para tales espacios de trabajo es alojarlos en una cuenta de nube completamente separada; esto limita en gran medida el radio de explosión de los usuarios en el espacio de trabajo. Al mismo tiempo, la configuración de barreras de seguridad simples (como las Políticas de Clúster, limitando el acceso a datos a conjuntos de datos de "juego" o limpios, y cerrando la conectividad saliente siempre que sea posible) significa que los usuarios pueden tener una libertad relativa para hacer (casi) lo que quieran sin necesidad de supervisión constante del administrador. Finalmente, la comunicación interna es igual de importante; si los usuarios construyen sin saber una aplicación increíble en el Sandbox que atrae a miles de usuarios, o esperan soporte a nivel de producción para su trabajo en este entorno, esos ahorros administrativos se evaporarán rápidamente.
Las mejores prácticas para los espacios de trabajo sandbox incluyen:
- Utiliza una cuenta de nube separada que no contenga datos sensibles o de producción.
- Configura barreras de seguridad simples para que los usuarios tengan libertad relativa sobre el entorno sin necesidad de supervisión del administrador.
- Comunica claramente que el entorno sandbox es "autoservicio".
Aislamiento de datos y sensibilidad
Los datos sensibles están cobrando cada vez más importancia entre nuestros clientes en todos los verticales; los datos que antes se limitaban a proveedores de atención médica o procesadores de tarjetas de crédito ahora se están convirtiendo en fuente para comprender el análisis de pacientes o el sentimiento del cliente, analizar mercados emergentes, posicionar nuevos productos y casi cualquier otra cosa que puedas imaginar. Esta riqueza de datos conlleva un alto riesgo potencial, con amenazas cada vez mayores de filtraciones de datos; por esta razón, mantener los datos sensibles segregados y protegidos es importante sin importar la estrategia organizacional que elijas. Databricks proporciona varios medios para proteger datos sensibles (como ACLs y compartición segura), y combinado con las herramientas del proveedor de la nube, puede hacer que el Lakehouse que construyas tenga el menor riesgo posible. Algunas de las mejores prácticas en torno al Aislamiento y Sensibilidad de Datos incluyen:
- Comprende tus necesidades únicas de seguridad de datos; este es el punto más importante. Cada negocio tiene datos diferentes, y tus datos impulsarán tu gobernanza.
- Aplica políticas y controles tanto a nivel de almacenamiento como a nivel de metastore. Las políticas de S3 y las ACL de ADLS siempre deben aplicarse utilizando el principio de menor acceso. Aprovecha Unity Catalog para aplicar una capa adicional de control sobre el acceso a los datos.
- Separa tus datos sensibles de los datos no sensibles, tanto lógica como físicamente; muchos clientes utilizan cuentas de nube completamente separadas (y espacios de trabajo Databricks) para datos sensibles y no sensibles.
DR y copia de seguridad regional
La Recuperación ante Desastres (DR) es un tema amplio que es importante si usas AWS, Azure o GCP; no cubriremos todo en este blog, sino que nos centraremos en cómo la DR y las consideraciones regionales influyen en el diseño del espacio de trabajo. En este contexto, DR implica la creación y el mantenimiento de un espacio de trabajo en una región separada del espacio de trabajo de Producción estándar.
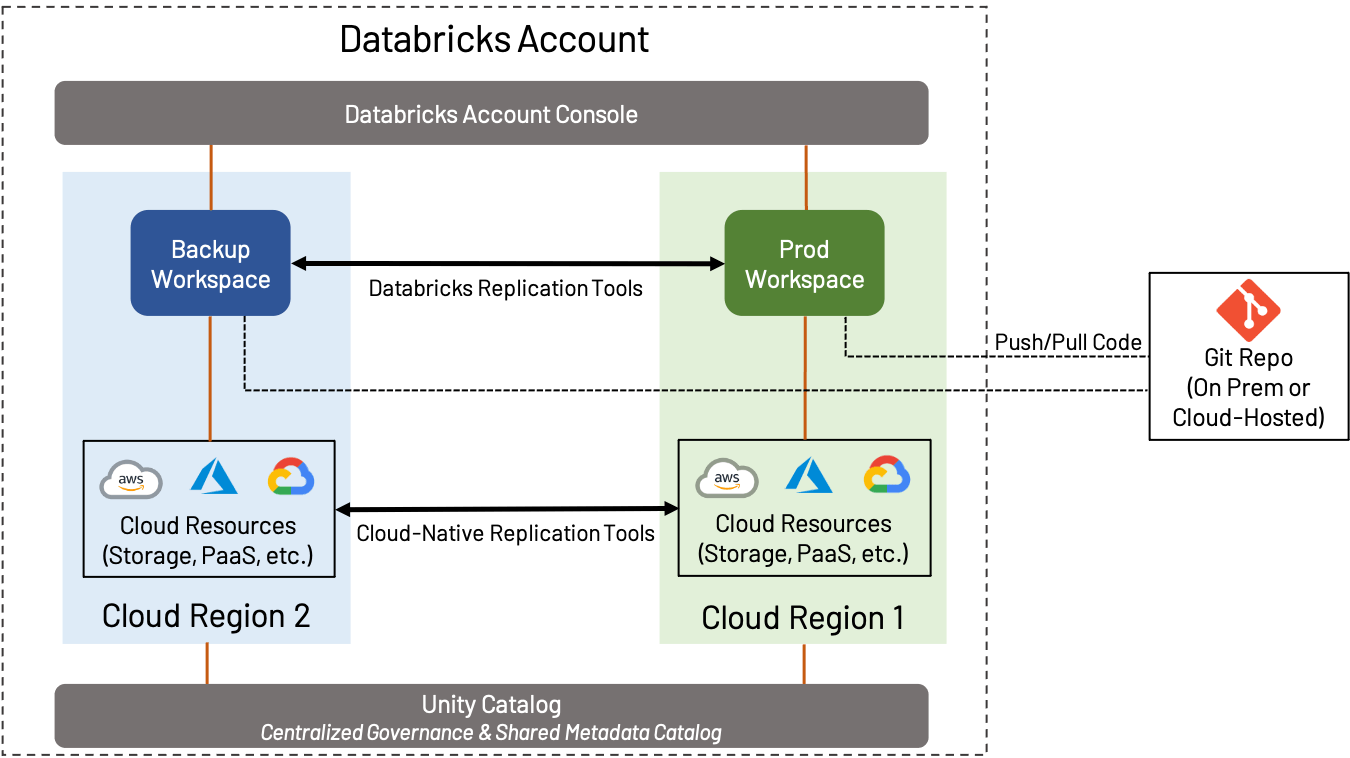
La estrategia de DR puede variar ampliamente dependiendo de las necesidades del negocio. Por ejemplo, algunos clientes prefieren mantener una configuración activa-activa, donde todos los activos de un espacio de trabajo se replican constantemente a un espacio de trabajo secundario; esto proporciona la máxima redundancia, pero también implica complejidad y costo (transferir constantemente datos entre regiones y realizar replicación y deduplicación de objetos es un proceso complicado). Por otro lado, algunos clientes prefieren hacer lo mínimo necesario para garantizar la continuidad del negocio; un espacio de trabajo secundario puede contener muy poco hasta que ocurra un failover, o puede ser respaldado solo ocasionalmente. Determinar el nivel correcto de failover es crucial.
Independientemente del nivel de DR que elijas implementar, recomendamos lo siguiente:
- Almacena el código en un repositorio de Git de tu elección, ya sea on-premise o en la nube, y utiliza funciones como Repos para sincronizarlo con Databricks siempre que sea posible.
- Siempre que sea posible, utiliza Delta Lake junto con Deep Clone para replicar datos; esto proporciona una forma fácil y de código abierto para hacer copias de seguridad de datos de manera eficiente.
- Utiliza las herramientas nativas de la nube proporcionadas por tu proveedor de nube para realizar copias de seguridad de elementos como datos no almacenados en Delta Lake, bases de datos externas, configuraciones, etc.
- Utiliza herramientas como Terraform para hacer copias de seguridad de objetos como notebooks, trabajos, secretos, clústeres y otros objetos del espacio de trabajo.
Recuerda: Databricks es responsable de mantener la infraestructura regional del espacio de trabajo en el Plano de Control, pero tú eres responsable de los activos específicos de tu espacio de trabajo, así como de la infraestructura de la nube de la que dependen tus trabajos de producción.
Aislamiento por línea de negocio (LOB)
Ahora nos adentramos en la organización real de los espacios de trabajo en un contexto empresarial. El aislamiento de proyectos basado en LOB surge de la forma tradicional de ver los recursos de TI centrada en la empresa; también conlleva muchas fortalezas (y debilidades) tradicionales de la alineación centrada en LOB. Como tal, para muchas grandes empresas, este enfoque de gestión de espacios de trabajo les resultará natural.
En una estrategia de espacio de trabajo basada en LOB, cada unidad funcional de un negocio recibirá un conjunto de espacios de trabajo; tradicionalmente, esto incluirá espacios de trabajo de desarrollo, staging y producción, aunque hemos visto clientes con hasta 10 etapas intermedias, cada una potencialmente con su propio espacio de trabajo (¡no recomendado!). El código se escribe y prueba en DEV, luego se promueve (a través de la automatización CI/CD) a STG, y finalmente aterriza en PRD, donde se ejecuta como un trabajo programado hasta ser descontinuado. El tipo de entorno y la LOB independiente son las razones principales para iniciar un nuevo espacio de trabajo en este modelo; hacerlo para cada caso de uso o producto de datos puede ser excesivo.
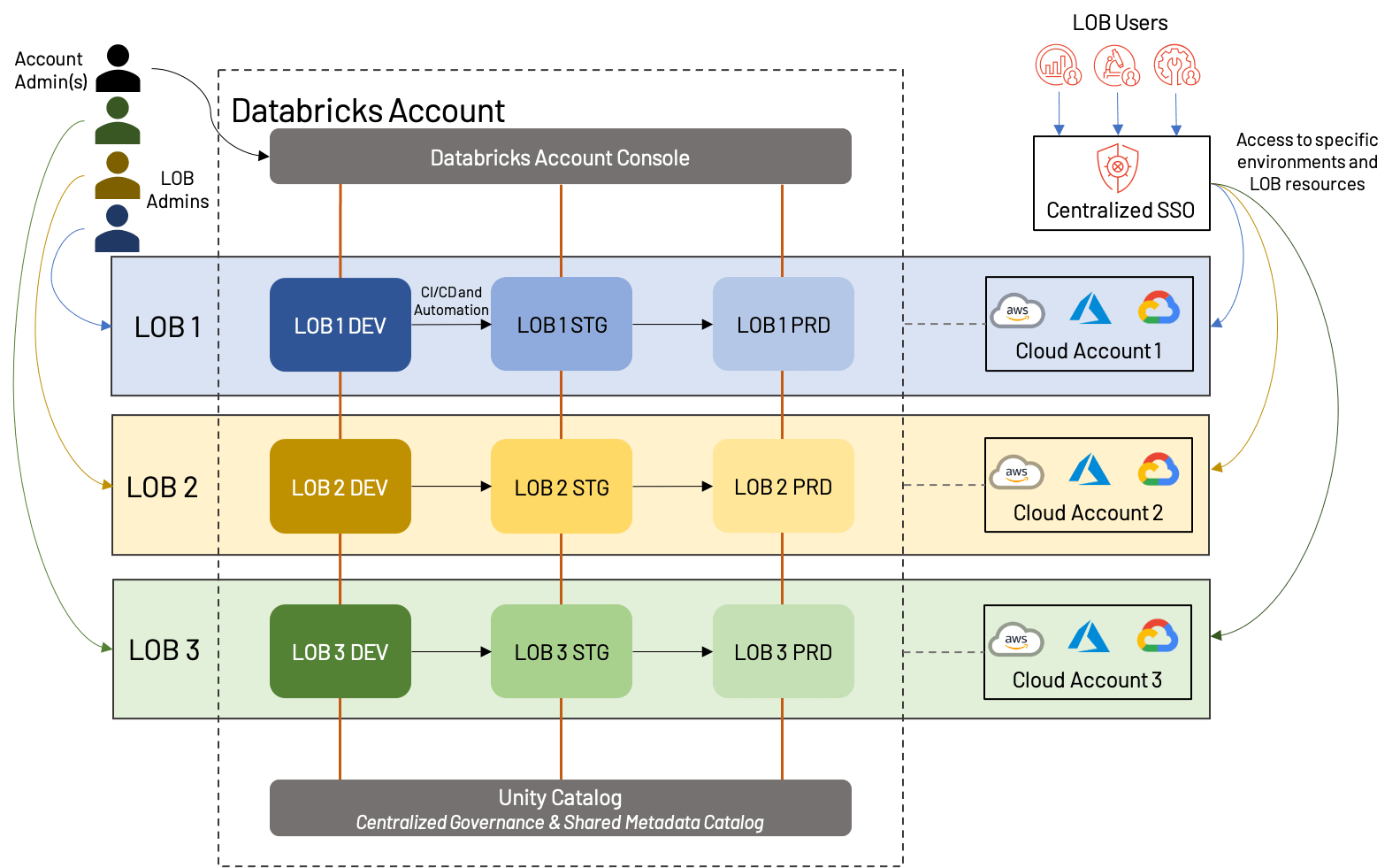
El diagrama anterior muestra una forma potencial en que se puede estructurar un espacio de trabajo basado en LOB; en este caso, cada LOB tiene una cuenta de nube separada con un espacio de trabajo en cada entorno (dev/stg/prd) y también tiene un administrador dedicado. Es importante destacar que todos estos espacios de trabajo caen bajo la misma cuenta de Databricks y aprovechan el mismo Unity Catalog. Algunas variaciones incluirían compartir cuentas de nube (y potencialmente recursos subyacentes como VPCs y servicios en la nube), usar una cuenta de nube separada de dev/stg/prd, o crear metastores externos separados para cada LOB. Todos estos son enfoques razonables que dependen en gran medida de las necesidades del negocio.
En general, hay una serie de beneficios, así como algunos inconvenientes en el enfoque LOB:
+Los activos de cada LOB se pueden aislar, tanto desde la perspectiva de la nube como desde la perspectiva del espacio de trabajo; esto facilita la generación de informes y el análisis de costos, además de un espacio de trabajo menos saturado.
+La clara división de usuarios y roles mejora la gobernanza general del Lakehouse y reduce el riesgo general.
+La automatización de la promoción entre entornos crea un proceso eficiente y de baja sobrecarga.
-Se requiere una planificación inicial para garantizar que los procesos entre LOB estén estandarizados y que la cuenta general de Databricks no alcance los límites de la plataforma.
-La automatización y los procesos administrativos requieren especialistas para su configuración y mantenimiento.
Como mejores prácticas, recomendamos lo siguiente a quienes construyen Lakehouses basados en LOB:
- Emplee un modelo de acceso de mínimo privilegio utilizando control de acceso detallado para usuarios y entornos; en general, muy pocos usuarios deben tener acceso a producción, y las interacciones con este entorno deben ser automatizadas y altamente controladas. Capture estos usuarios y grupos en su proveedor de identidad y sincronícelos con el Lakehouse.
- Comprenda y planifique los límites tanto del proveedor de nube como de la plataforma Databricks; estos incluyen, por ejemplo, el número de espacios de trabajo, la limitación de la tasa de API en ADLS, la limitación de transmisiones de Kinesis, etc.
- Utilice un metastore/catálogo estandarizado con controles de acceso sólidos siempre que sea posible; esto permite la reutilización de activos sin comprometer el aislamiento. Unity Catalog permite controles detallados sobre tablas y activos del espacio de trabajo, que incluyen objetos como experimentos de MLflow.
- Aproveche el uso compartido de datos siempre que sea posible para compartir datos de forma segura entre LOB sin necesidad de duplicar esfuerzos.
Aislamiento de productos de datos
¿Qué hacemos cuando los LOB necesitan colaborar de forma interfuncional, o cuando un simple modelo de desarrollo/staging/producción no se ajusta a los casos de uso de nuestro LOB? Podemos deshacernos de parte de la formalidad de una estructura estricta de Lakehouse basada en LOB y adoptar un enfoque ligeramente más moderno; llamamos a esto aislamiento de espacio de trabajo por Producto de Datos. El concepto es que, en lugar de aislar estrictamente por LOB, aislamos por proyectos de nivel superior, dando a cada uno un entorno de producción. También mezclamos entornos de desarrollo compartidos para evitar la proliferación de espacios de trabajo y simplificar la reutilización de activos.
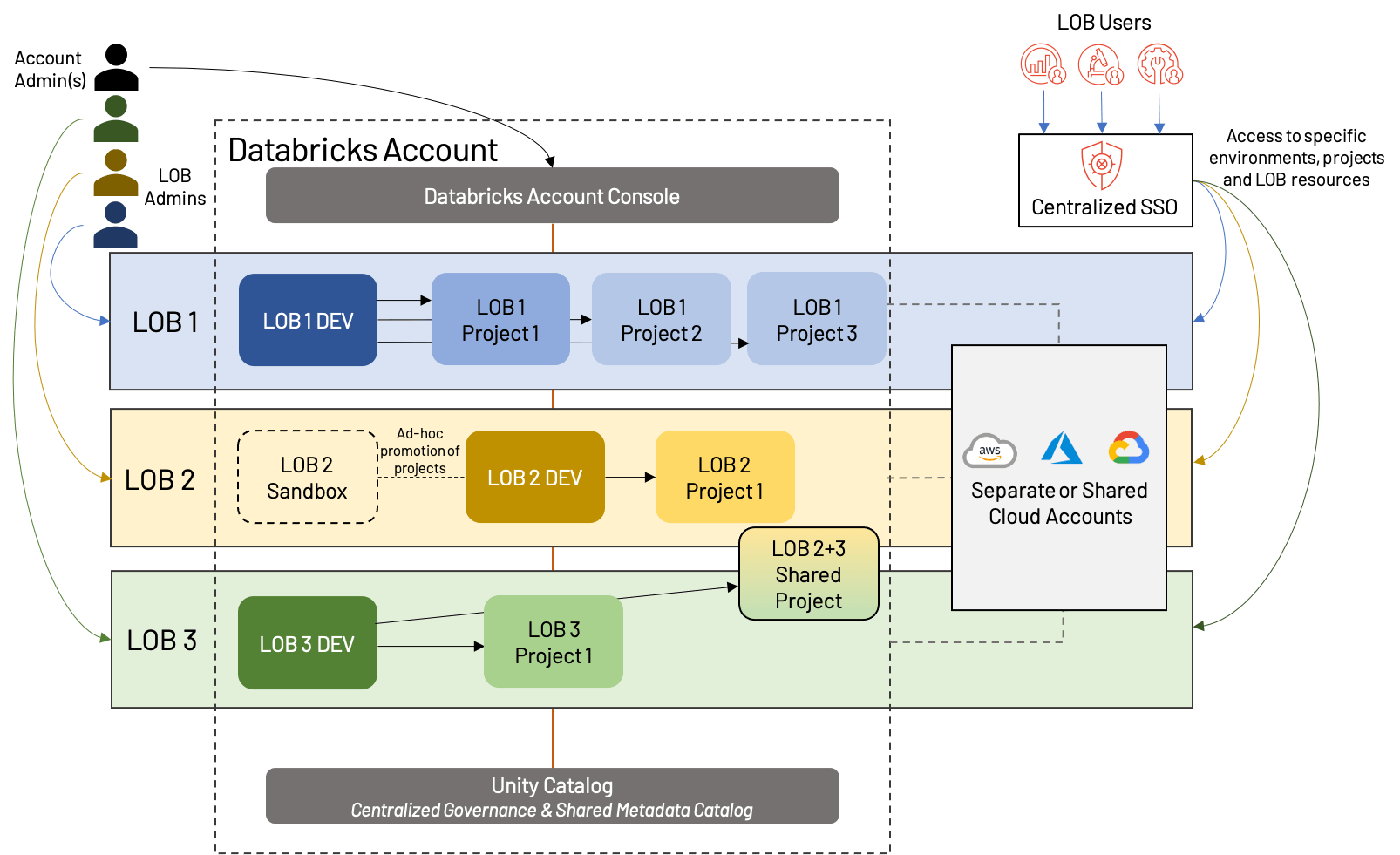
A primera vista, esto parece similar al aislamiento basado en LOB de arriba, pero hay algunas distinciones importantes:
- Un espacio de trabajo de desarrollo compartido, con espacios de trabajo separados para cada proyecto de nivel superior (lo que significa que cada LOB puede tener un número diferente de espacios de trabajo en general)
- La presencia de espacios de trabajo de sandbox, que son específicos de un LOB y ofrecen más libertad y menos automatización que los espacios de trabajo de desarrollo tradicionales
- Compartir recursos y/o espacios de trabajo; esto también es posible en arquitecturas basadas en LOB, pero a menudo se complica por una separación más rígida
Este enfoque comparte muchas de las mismas fortalezas y debilidades que el aislamiento basado en LOB, pero ofrece más flexibilidad y enfatiza el valor de los proyectos en el Lakehouse moderno. Cada vez más, vemos que esto se convierte en el "estándar de oro" de la organización de espacios de trabajo, lo que corresponde con el movimiento de la tecnología de ser principalmente un impulsor de costos a un generador de valor. Como siempre, las necesidades comerciales pueden impulsar desviaciones leves de esta arquitectura de ejemplo, como desarrollo/staging/producción dedicados para proyectos particularmente grandes, proyectos inter-LOB, más o menos segregación de recursos en la nube, etc. Independientemente de la estructura exacta, sugerimos las siguientes mejores prácticas:
- Comparta datos y recursos siempre que sea posible; aunque la segregación de infraestructura y espacios de trabajo es útil para la gobernanza y el seguimiento, la proliferación de recursos se convierte rápidamente en una carga. Un análisis cuidadoso de antemano ayudará a identificar áreas de reutilización.
- Incluso cuando no se comparte extensamente entre proyectos, utilice un metastore compartido como Unity Catalog y bases de código compartidas (a través de, por ejemplo, Repos) siempre que sea posible.
- Utilice Terraform (o herramientas similares) para automatizar el proceso de creación, gestión y eliminación de espacios de trabajo e infraestructura en la nube.
- Proporcione flexibilidad a los usuarios a través de entornos de sandbox, pero asegúrese de que tengan barreras de protección adecuadas para limitar los tamaños de clúster, el acceso a datos, etc.
Resumen
Para aprovechar al máximo todos los beneficios del Lakehouse y respaldar el crecimiento y la gestionabilidad futuros, se debe tener cuidado al planificar la disposición del espacio de trabajo. Otros artefactos asociados que deben considerarse durante este diseño incluyen un registro de modelos centralizado, base de código y catálogo para facilitar la colaboración sin comprometer la seguridad. Para resumir algunas de las mejores prácticas destacadas en este artículo, nuestras conclusiones clave se enumeran a continuación:
Mejor Práctica #1: Minimice el número de cuentas de nivel superior (tanto en el proveedor de nube como en el nivel de Databricks) siempre que sea posible, y cree un espacio de trabajo solo cuando la separación sea necesaria por motivos de cumplimiento, aislamiento o restricciones geográficas. En caso de duda, ¡mantenlo simple!
Mejor Práctica #2: Decida una estrategia de aislamiento que le proporcione flexibilidad a largo plazo sin una complejidad indebida. Sea realista acerca de sus necesidades e implemente pautas estrictas antes de comenzar a incorporar cargas de trabajo a su Lakehouse; en otras palabras, ¡mida dos veces, corte una vez!
Mejor Práctica #3: Automatice sus procesos en la nube. Esto abarca todos los aspectos de su infraestructura (muchos de los cuales se cubrirán en blogs posteriores), incluido SSO/SCIM, Infraestructura como Código con una herramienta como Terraform, canalizaciones de CI/CD y Repos, copias de seguridad en la nube y monitoreo (utilizando herramientas nativas de la nube y de terceros).
Mejor Práctica #4: Considere establecer un equipo de COE para la gobernanza central de una estrategia empresarial, donde los aspectos repetibles de una canalización de datos y aprendizaje automático se plantillan y automatizan para que diferentes equipos de datos puedan usar capacidades de autoservicio con suficientes barreras de protección. El equipo de COE es a menudo un centro ligero pero crítico para los equipos de datos y debe verse a sí mismo como un facilitador, manteniendo documentación, SOP, guías y preguntas frecuentes para educar a otros usuarios.
Mejor Práctica #5: El Lakehouse proporciona un nivel de gobernanza que el Data Lake no tiene; ¡aprovéchelo! Evalúe sus necesidades de cumplimiento y gobernanza como uno de los primeros pasos para establecer su Lakehouse, y aproveche las funciones que Databricks proporciona para asegurarse de que el riesgo se minimice. Esto incluye la entrega de registros de auditoría, HIPAA y PCI (cuando corresponda), controles de exfiltración adecuados, uso de ACL y controles de usuario, y revisión regular de todo lo anterior.
Proporcionaremos más blogs de mejores prácticas de administración en el futuro cercano, sobre temas que van desde la Gobernanza de Datos hasta la Gestión de Usuarios. Mientras tanto, comuníquese con su equipo de cuentas de Databricks si tiene preguntas sobre la gestión de espacios de trabajo, ¡o si desea obtener más información sobre las mejores prácticas en la Plataforma Databricks Lakehouse!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.