Evaluación de modelos en MLflow
por Mark Zhang
Muchos científicos de datos e ingenieros de ML utilizan hoy en día MLflow para gestionar sus modelos. MLflow es una plataforma de código abierto que permite a los usuarios gobernar todos los aspectos del ciclo de vida de ML, incluyendo, entre otros, la experimentación, la reproducibilidad, el despliegue y el registro de modelos. Un paso crítico durante el desarrollo de modelos de ML es la evaluación de su rendimiento en conjuntos de datos novedosos.
Motivación
¿Por qué evaluamos los modelos?
La evaluación de modelos es una parte integral del ciclo de vida de ML. Permite a los científicos de datos medir, interpretar y explicar el rendimiento de sus modelos. Acelera el marco de tiempo de desarrollo del modelo al proporcionar información sobre cómo y por qué los modelos se comportan como lo hacen. Especialmente a medida que aumenta la complejidad de los modelos de ML, ser capaz de observar y comprender rápidamente el rendimiento de los modelos de ML es esencial en un viaje de desarrollo de ML exitoso.
Estado de la evaluación de modelos en MLflow
Actualmente, muchos usuarios evalúan el rendimiento de su modelo MLflow del sabor de modelo python_function (pyfunc) a través de la API mlflow.evaluate, que admite la evaluación de modelos de clasificación y regresión. Calcula y registra un conjunto de métricas de rendimiento específicas de la tarea integradas, gráficos de rendimiento del modelo y explicaciones del modelo en el servidor de MLflow Tracking.
Para evaluar modelos MLflow frente a métricas personalizadas no incluidas en el conjunto de métricas de evaluación integradas, los usuarios tendrían que definir un plugin de evaluador de modelos personalizado. Esto implicaría crear una clase de evaluador personalizada que implemente la interfaz ModelEvaluator, y luego registrar un punto de entrada de evaluador como parte de un plugin de MLflow. Esta rigidez y complejidad podrían ser prohibitivas para los usuarios.
Según una encuesta interna a clientes, el 75% de los encuestados dicen que usan con frecuencia o siempre métricas especializadas y enfocadas en el negocio, además de las básicas como precisión y pérdida. Los científicos de datos a menudo utilizan estas métricas personalizadas, ya que son más descriptivas de los objetivos comerciales (por ejemplo, tasa de conversión) y contienen heurísticas adicionales que no son capturadas por la predicción del modelo en sí.
En este blog, presentamos una forma fácil y conveniente de evaluar modelos MLflow con métricas personalizadas definidas por el usuario. Con esta funcionalidad, un científico de datos puede incorporar fácilmente esta lógica en la etapa de evaluación del modelo y determinar rápidamente el modelo de mejor rendimiento sin un análisis posterior adicional.
*Nota: En MLflow 2.4, mlflow.evaluate se amplía para admitir modelos de texto LLM, resumen de texto y preguntas y respuestas
Uso
Métricas integradas
MLflow incluye un conjunto de métricas de rendimiento y explicabilidad del modelo comúnmente utilizadas tanto para modelos clasificadores como regresores. Evaluar modelos con estas métricas es sencillo. Todo lo que necesitamos es crear un conjunto de datos de evaluación que contenga los datos de prueba y los objetivos, y realizar una llamada a mlflow.evaluate.
Dependiendo del tipo de modelo, se calculan diferentes métricas. Consulte la sección Comportamiento del evaluador predeterminado en la documentación de la API de mlflow.evaluate para obtener la información más actualizada sobre las métricas integradas.
Ejemplo
A continuación, se muestra un ejemplo sencillo de cómo se evalúa un modelo MLflow clasificador con métricas integradas.
Primero, importe las bibliotecas necesarias
Luego, dividimos el conjunto de datos, ajustamos el modelo y creamos nuestro conjunto de datos de evaluación
Finalmente, iniciamos una ejecución de MLflow y llamamos a mlflow.evaluate
Podemos encontrar las métricas y artefactos registrados en la UI de MLflow:
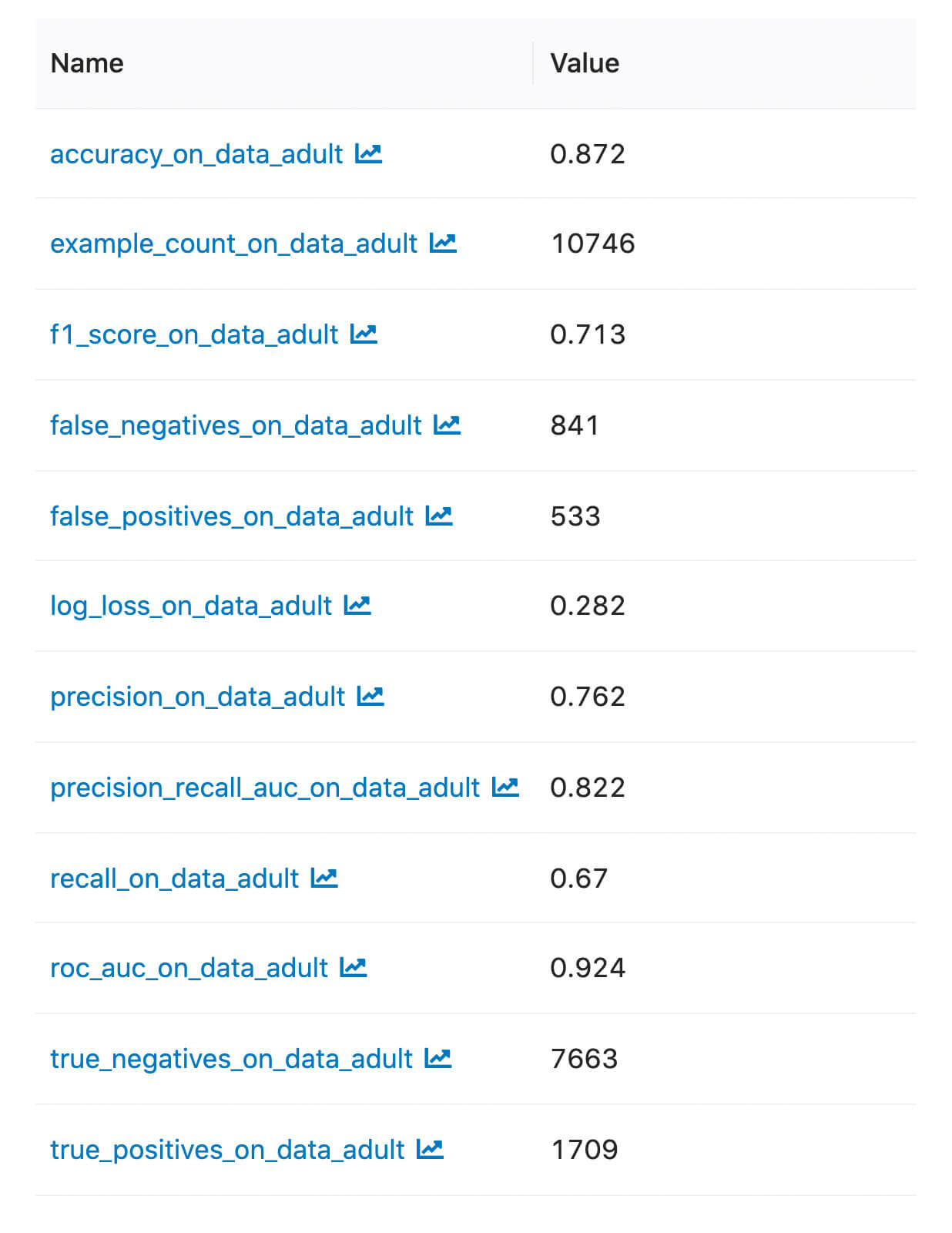
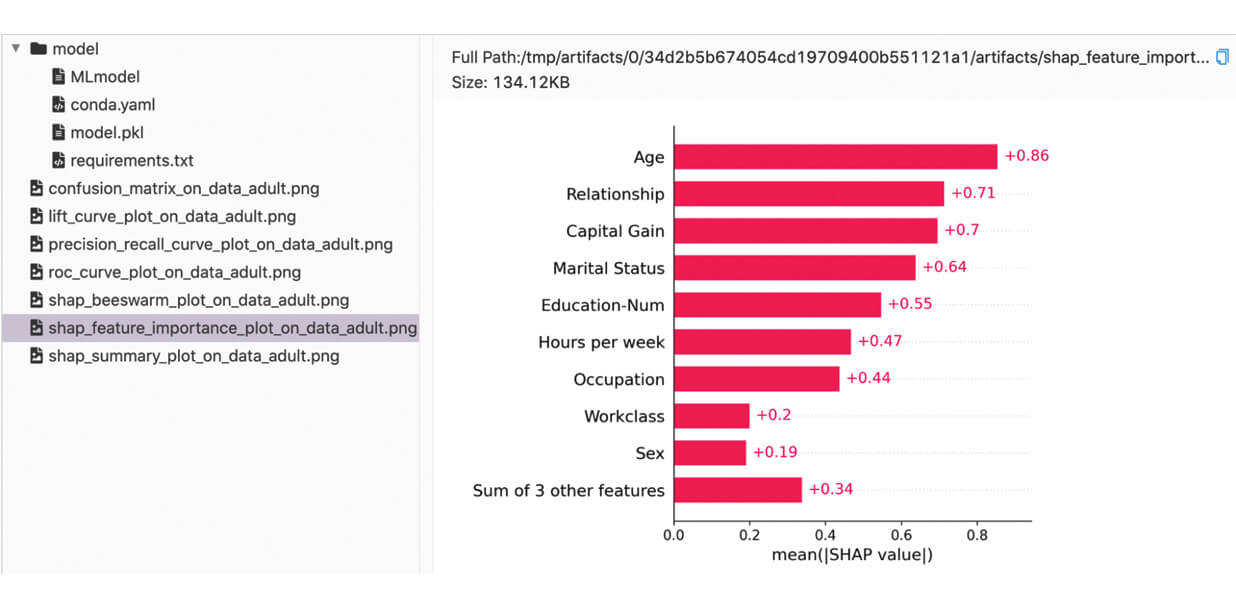
Métricas personalizadas
Para evaluar un modelo frente a métricas personalizadas, simplemente pasamos una lista de funciones de métricas personalizadas a la API mlflow.evaluate.
Requisitos de definición de función
Las funciones de métricas personalizadas deben aceptar dos parámetros obligatorios y uno opcional en el siguiente orden:
eval_df: un DataFrame de Pandas o Spark que contiene una columna deprediccióny una columna deobjetivo.Por ejemplo, si la salida del modelo es un vector de tres números, entonces el DataFrame
eval_dfse vería algo así: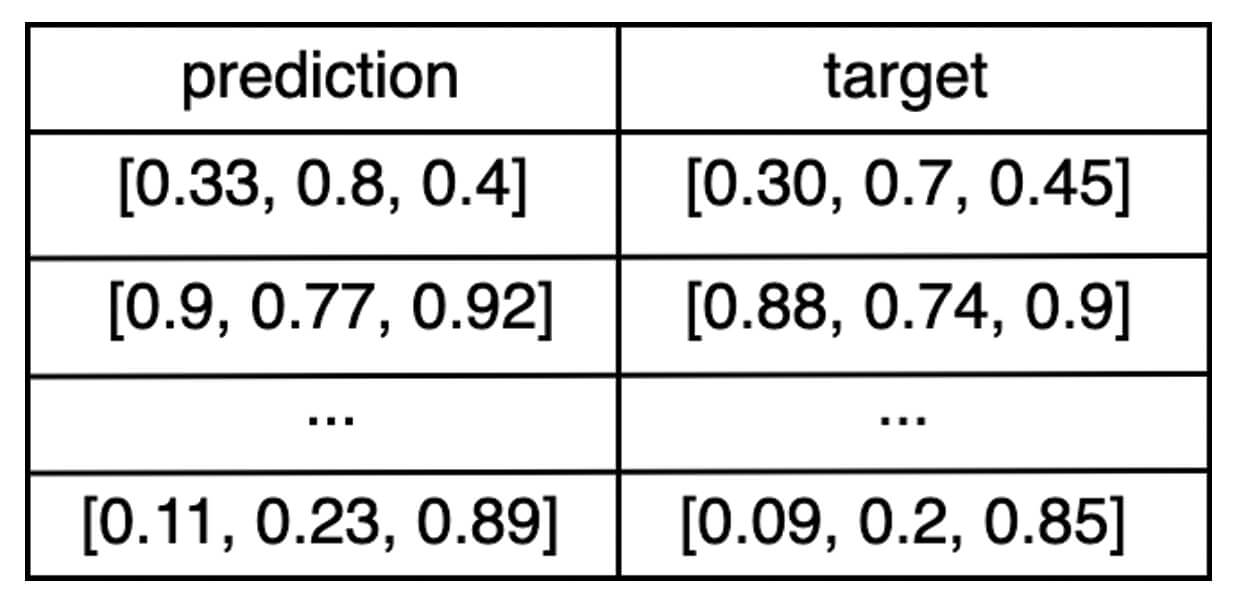
builtin_metrics: un diccionario que contiene las métricas integradasPor ejemplo, para un modelo regresor,
builtin_metricsse vería algo así:- (Opcional)
artifacts_dir: ruta a un directorio temporal que puede ser utilizado por la función de métrica personalizada para almacenar temporalmente los artefactos producidos antes de registrarlos en MLflow.Por ejemplo, esto se verá diferente dependiendo de la configuración específica del entorno. Por ejemplo, en MacOS podría verse algo así:
Si los artefactos de archivo se almacenan en un lugar distinto de
artifacts_dir, asegúrese de que persistan hasta después de la ejecución completa demlflow.evaluate.
Requisitos del valor de retorno
La función debe devolver un diccionario que represente las métricas producidas y opcionalmente puede devolver un segundo diccionario que represente los artefactos producidos. Para ambos diccionarios, la clave de cada entrada representa el nombre de la métrica o artefacto correspondiente.
Si bien cada métrica debe ser un escalar, existen varias formas de definir artefactos:
- La ruta a un archivo de artefacto
- La representación de cadena de un objeto JSON
- Un DataFrame de pandas
- Un array numpy
- Una figura de matplotlib
- Se intentará serializar otros objetos con el protocolo predeterminado
Consulta la documentación de mlflow.evaluate para obtener detalles más profundos sobre la definición.
Ejemplo
Veamos un ejemplo concreto que utiliza métricas personalizadas. Para ello, crearemos un modelo de juguete a partir del conjunto de datos California Housing.
Luego, configuraremos nuestro conjunto de datos y modelo
Aquí viene la parte emocionante: definir nuestra función de métricas personalizadas, ¡y un artefacto personalizado!!
Finalmente, para unir todo esto, iniciaremos una ejecución de MLflow y llamaremos a mlflow.evaluate:
Las métricas y artefactos personalizados registrados se pueden encontrar junto con las métricas y artefactos predeterminados. Las regiones encerradas en rojo muestran las métricas y artefactos personalizados registrados en la página de ejecución.
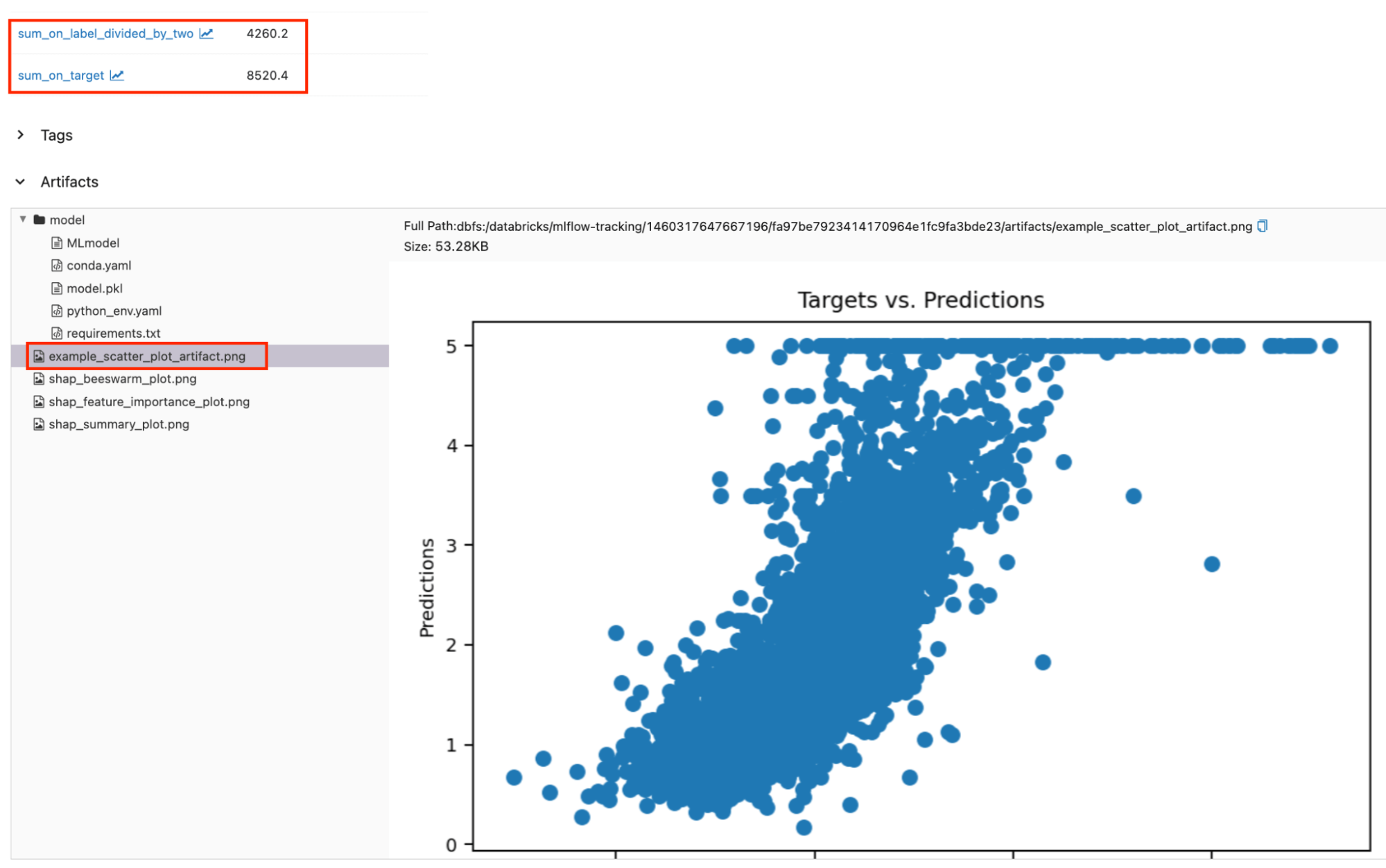
Accediendo a los Resultados de Evaluación Programáticamente
Hasta ahora, hemos explorado los resultados de la evaluación tanto para métricas integradas como personalizadas en la interfaz de usuario de MLflow. Sin embargo, también podemos acceder a ellas programáticamente a través del objeto EvaluationResult devuelto por mlflow.evaluate. Continuemos nuestro ejemplo de métricas personalizadas anterior y veamos cómo podemos acceder a sus resultados de evaluación programáticamente. (Asumiendo que result es nuestra instancia de EvaluationResult a partir de aquí).
Podemos acceder al conjunto de métricas calculadas a través del diccionario result.metrics que contiene tanto el nombre como los valores escalares de las métricas. El contenido de result.metrics debería verse algo así:
De manera similar, el conjunto de artefactos es accesible a través del diccionario result.artifacts. Los valores de cada entrada son un objeto EvaluationArtifact. result.artifacts debería verse algo así:
Cuadernos de Ejemplo
Por Dentro
El siguiente diagrama ilustra cómo funciona todo esto internamente:
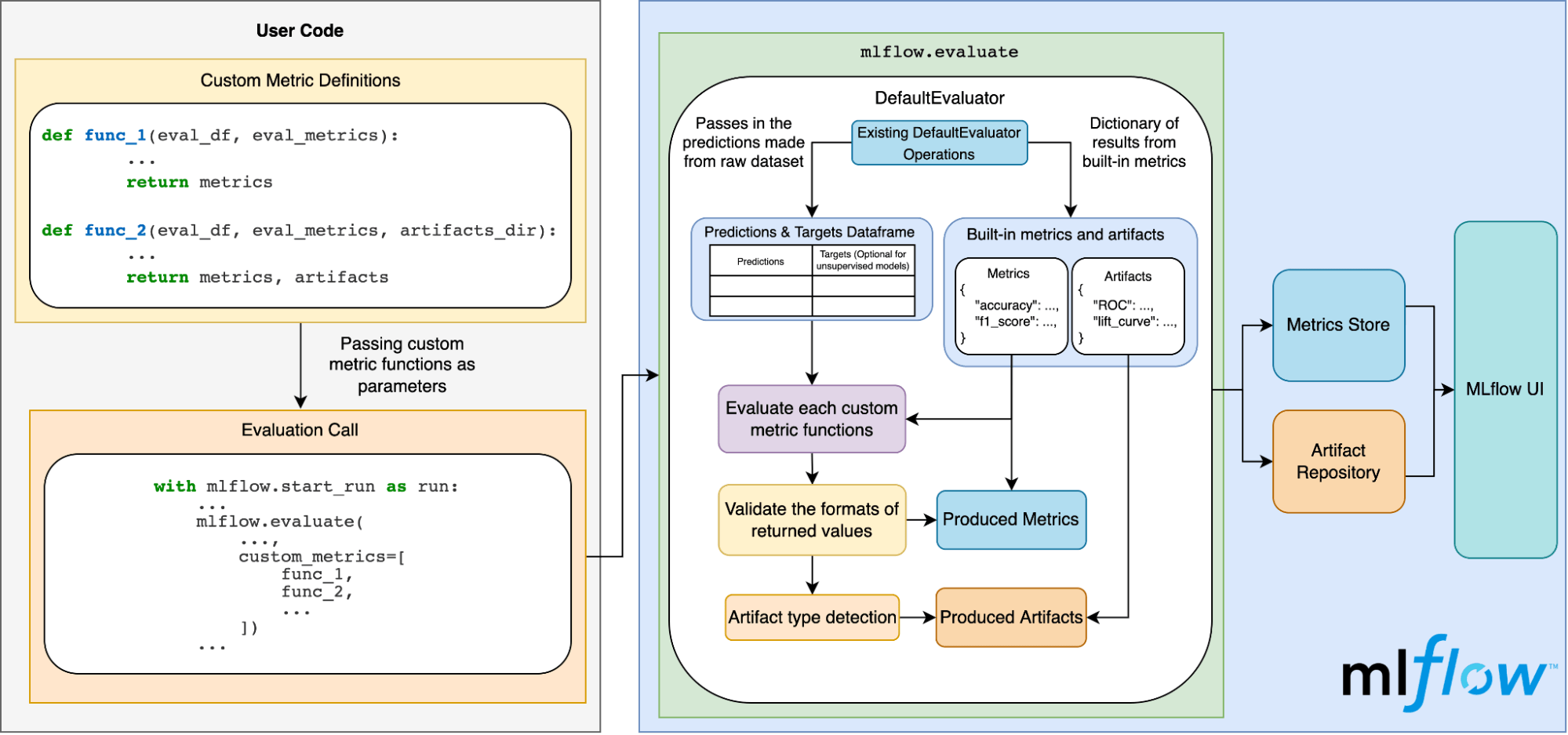
Conclusión
En esta entrada de blog, cubrimos:
- La importancia de la evaluación de modelos y lo que actualmente se admite en MLflow.
- Por qué es importante tener una forma fácil para que los usuarios de MLflow incorporen métricas personalizadas en sus modelos de MLflow.
- Cómo evaluar modelos con métricas predeterminadas.
- Cómo evaluar modelos con métricas personalizadas.
- Cómo MLflow maneja la evaluación de modelos detrás de escena.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.