¡Las columnas de identidad para generar claves sustitutas ya están disponibles en un Lakehouse cerca de ti!
por Franco Patano
¿Qué es una columna de identidad?
Una columna de identidad es una columna en una base de datos que genera automáticamente un número de ID único para cada nueva fila de datos. Este número no está relacionado con el contenido de la fila.
Las columnas de identidad son una forma de claves sustitutas. En los almacenes de datos, es común usar una clave adicional, llamada clave sustituta, para identificar de forma única cada fila y realizar un seguimiento de los cambios en los datos a lo largo del tiempo. Además, se recomienda usar claves sustitutas en lugar de claves naturales. Las claves sustitutas son generadas por el sistema y no dependen de varios campos para identificar la unicidad de la fila.
Por lo tanto, las columnas de identidad se utilizan para crear claves sustitutas, que pueden servir como claves primarias y foráneas en modelos dimensionales para almacenes de datos y data marts. Como se ve a continuación, estas claves son las columnas que conectan diferentes tablas entre sí en un modelo dimensional tradicional como un esquema en estrella.
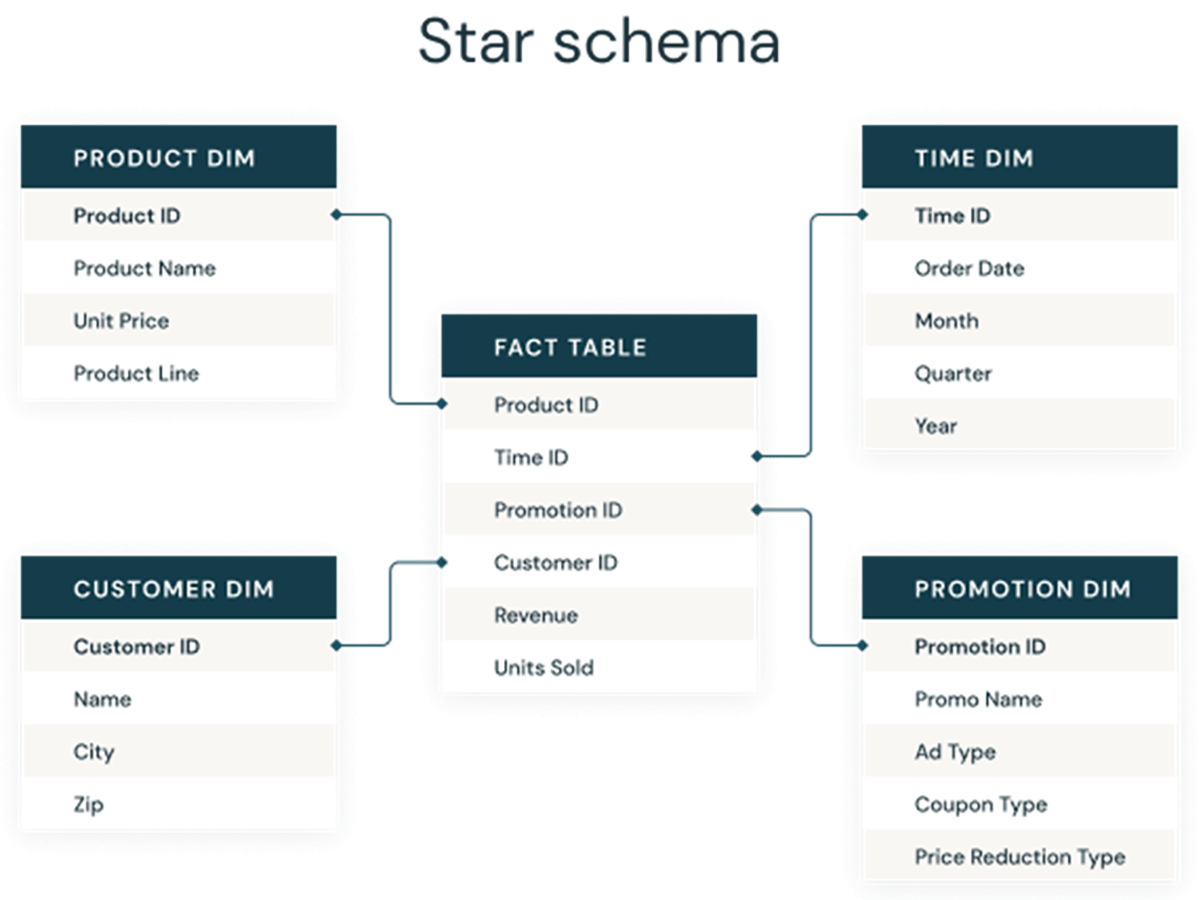
Enfoques tradicionales para generar claves sustitutas en lagos de datos
La mayoría de las tecnologías de big data utilizan el paralelismo, o la capacidad de dividir una tarea en partes más pequeñas que se pueden completar al mismo tiempo, para mejorar el rendimiento. En los primeros días de los lagos de datos, no había una forma fácil de crear secuencias únicas en un grupo de máquinas. Esto llevó a algunos ingenieros de datos a utilizar métodos menos confiables para generar claves sustitutas sin una característica adecuada, como:
monotonically_increasing_id(),row_number(),Rank OVER,ZipWithIndex(),ZipWithUniqueIndex(),- Hash de fila con
hash(),y - Hash de fila con
md5().
Si bien estas funciones pueden hacer el trabajo en ciertas circunstancias, a menudo están plagadas de muchas advertencias y salvedades sobre el llenado disperso de las secuencias, problemas de rendimiento a escala y problemas de transacciones concurrentes.
Las bases de datos han podido generar secuencias desde los primeros días, para generar claves sustitutas que identifiquen de forma única una fila de datos con la ayuda de un gestor de transacciones centralizado. Sin embargo, las implementaciones típicas requieren bloqueos y confirmaciones transaccionales, que pueden ser difíciles de gestionar.
Las columnas de identidad en Delta Lake facilitan la generación de claves sustitutas
Las columnas de identidad resuelven los problemas mencionados anteriormente y proporcionan una solución simple y de alto rendimiento para generar claves sustitutas. Delta Lake es el primer protocolo de lago de datos que habilita las columnas de identidad para la generación de claves sustitutas.
Delta Lake ahora admite la creación de columnas IDENTITY que pueden generar automáticamente números de ID únicos y de incremento automático cuando se cargan nuevas filas. Si bien estos números de ID pueden no ser consecutivos, Delta hace todo lo posible para mantener la brecha lo más pequeña posible. Puede usar esta característica para crear claves sustitutas para sus cargas de trabajo de almacenamiento de datos fácilmente.
Cómo crear una clave sustituta con una columna de identidad usando SQL y Delta Lake
[Recomendado] Generar siempre como identidad
Crear una columna de identidad en SQL es tan simple como crear una tabla de Delta Lake. Al declarar sus columnas, agregue un nombre de columna llamado id, o el que prefiera, con un tipo de datos BIGINT, y luego ingrese GENERATED ALWAYS AS IDENTITY.
Ahora, cada vez que realice una operación en esta tabla donde inserte datos, omita esta columna de la inserción, y Delta Lake generará automáticamente un valor único para la columna IDENTITY por cada fila insertada en la tabla de Delta Lake.
Aquí hay un ejemplo simple de cómo usar columnas de identidad en Delta Lake:
En adelante, la columna de identidad titulada "id" se incrementará automáticamente cada vez que inserte nuevos registros en la tabla. Luego puede insertar nuevos datos de la siguiente manera:
Observe cómo la columna de clave sustituta titulada "id" falta en la parte INSERT de la declaración. Delta Lake completará las claves sustitutas cuando escriba la tabla en el almacenamiento de objetos en la nube (por ejemplo, AWS S3, Azure Data Lake Storage o Google Cloud Storage). Obtenga más información en la documentación.
Generar por DEFAULT
También existe la opción GENERATED BY DEFAULT AS IDENTITY, que permite anular la inserción de identidad, mientras que la opción ALWAYS no se puede anular.
Hay algunas advertencias que debe tener en cuenta al adoptar esta nueva característica. Las columnas de identidad no se pueden agregar a tablas existentes; las tablas deberán recrearse con la nueva columna de identidad agregada. Para hacer esto, simplemente cree un nuevo DDL de tabla con la columna de identidad, e inserte las columnas existentes en la nueva tabla, y se generarán claves sustitutas para la nueva tabla.
Comience hoy mismo con las columnas de identidad en Delta Lake en Databricks SQL
Las columnas de identidad ya están disponibles de forma general (GA) en Databricks Runtime 10.4+ y en Databricks SQL 2022.17+. Con las columnas de identidad, ahora puede habilitar todas sus cargas de trabajo de almacenamiento de datos para que tengan todos los beneficios de una arquitectura Lakehouse, acelerada por Photon. Pruebe las columnas de identidad en Databricks SQL hoy mismo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.