Modelado visual de datos con erwin Data Modeler de Quest en la Plataforma Databricks Lakehouse
Modelado de Datos usando erwin en Databricks
por Vani Mishra, Abhishek Dey, Leo Mao, Soham Bhatt y Pradeep Anandapu
Esta es una publicación colaborativa entre Databricks y Quest Software. Agradecemos a Vani Mishra, Directora de Gestión de Productos en Quest Software, por sus contribuciones.
Modelado de datos usando erwin Data Modeler
A medida que los clientes modernizan su infraestructura de datos a Databricks, están consolidando varios data marts y EDW en una arquitectura unificada de lakehouse escalable que admite ETL, BI e IA. Por lo general, uno de los primeros pasos de este proceso comienza con un inventario de los modelos de datos existentes de los sistemas heredados y su racionalización y conversión en las zonas Bronze, Silver y Gold de la arquitectura Databricks Lakehouse. Una herramienta de modelado de datos robusta que pueda visualizar, diseñar, implementar y estandarizar los activos de datos del lakehouse simplifica enormemente el diseño y la migración del lakehouse, además de acelerar los aspectos de gobernanza de datos.
Nos complace anunciar nuestra asociación e integración de erwin Data Modeler de Quest con la Plataforma Databricks Lakehouse para satisfacer estas necesidades. Los modeladores de datos ahora pueden modelar y visualizar estructuras de datos del lakehouse con erwin Data Modeler para crear modelos de datos lógicos y físicos que aceleren la migración a Databricks. Los modeladores y arquitectos de datos pueden reingenierizar o reconstruir rápidamente bases de datos y sus tablas y vistas subyacentes en Databricks. ¡Ahora puede acceder fácilmente a erwin Data Modeler desde Databricks Partner Connect!
Aquí hay algunas de las razones clave por las que las herramientas de modelado de datos como erwin Data Modeler son importantes:
- Mejor comprensión de los datos: Las herramientas de modelado de datos proporcionan una representación visual de estructuras de datos complejas, lo que facilita a las partes interesadas la comprensión de las relaciones entre los diferentes elementos de datos.
- Mayor precisión y coherencia: Las herramientas de modelado de datos pueden ayudar a garantizar que las bases de datos se diseñen teniendo en cuenta la precisión y la coherencia, lo que reduce el riesgo de errores e inconsistencias en los datos.
- Facilita la colaboración: Con las herramientas de modelado de datos, varias partes interesadas pueden colaborar en el diseño de una base de datos, asegurando que todos estén en la misma página y que el esquema resultante satisfaga las necesidades de todas las partes interesadas.
- Mejor rendimiento de la base de datos: Las bases de datos diseñadas correctamente pueden mejorar el rendimiento de las aplicaciones que dependen de ellas, lo que lleva a un procesamiento de datos más rápido y eficiente.
- Mantenimiento más fácil: Con una base de datos bien diseñada, las tareas de mantenimiento como agregar nuevos elementos de datos o modificar los existentes se vuelven más fáciles y menos propensas a errores.
- Gobernanza de datos mejorada, inteligencia de datos y gestión de metadatos.
En esta publicación, demostraremos tres escenarios sobre cómo se puede usar erwin Data Modeler con Databricks:
- El primer escenario es donde un equipo quiere crear un Diagrama de Relación de Entidad (ERD) nuevo basado en la documentación del equipo de negocio. El objetivo es crear un diagrama ER para el modelo lógico para que una unidad de negocio comprenda y aplique las relaciones, definiciones y reglas de negocio tal como se aplican en el sistema. Basado en este modelo lógico, también crearemos un modelo físico para Databricks.
- En el segundo escenario, la unidad de negocio está creando un modelo de datos visual mediante la ingeniería inversa de su entorno Databricks actual, para comprender las definiciones de negocio, las relaciones y las perspectivas de gobernanza, a fin de colaborar con el equipo de informes y gobernanza.
- En el tercer escenario, el equipo de arquitectos de plataforma está consolidando sus diversos Enterprise Data Warehouse (EDW) y data marts como Oracle, SQL Server, Teradata, MongoDB, etc., en la plataforma Databricks Lakehouse y creando un modelo maestro consolidado.
Una vez completada la creación del ERD, le mostraremos cómo generar un archivo DDL/SQL para el equipo de diseño físico de Databricks.
Escenario n.º 1: Crear un nuevo modelo de datos lógico y físico para implementar en Databricks
El primer paso será seleccionar un modelo Lógico/Físico como se muestra aquí:
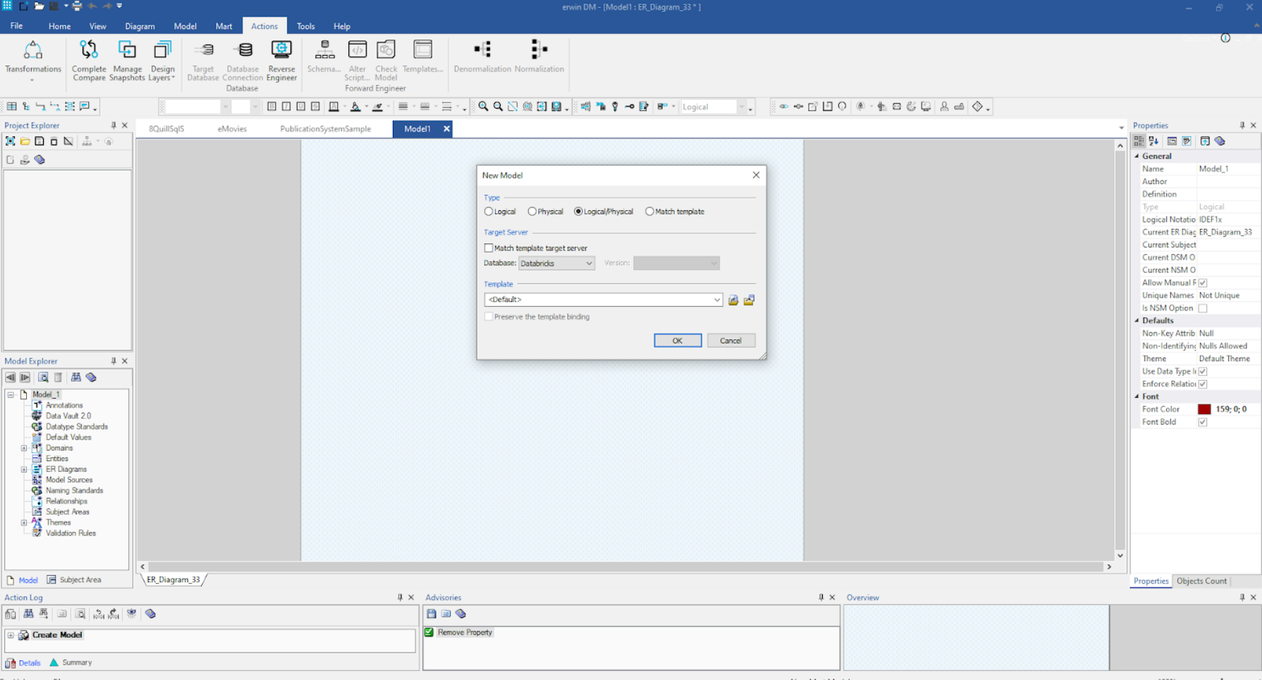
Una vez seleccionado, puede comenzar a construir sus entidades, atributos, relaciones, definiciones y otros detalles en este modelo.
La siguiente captura de pantalla muestra un ejemplo de un modelo avanzado:
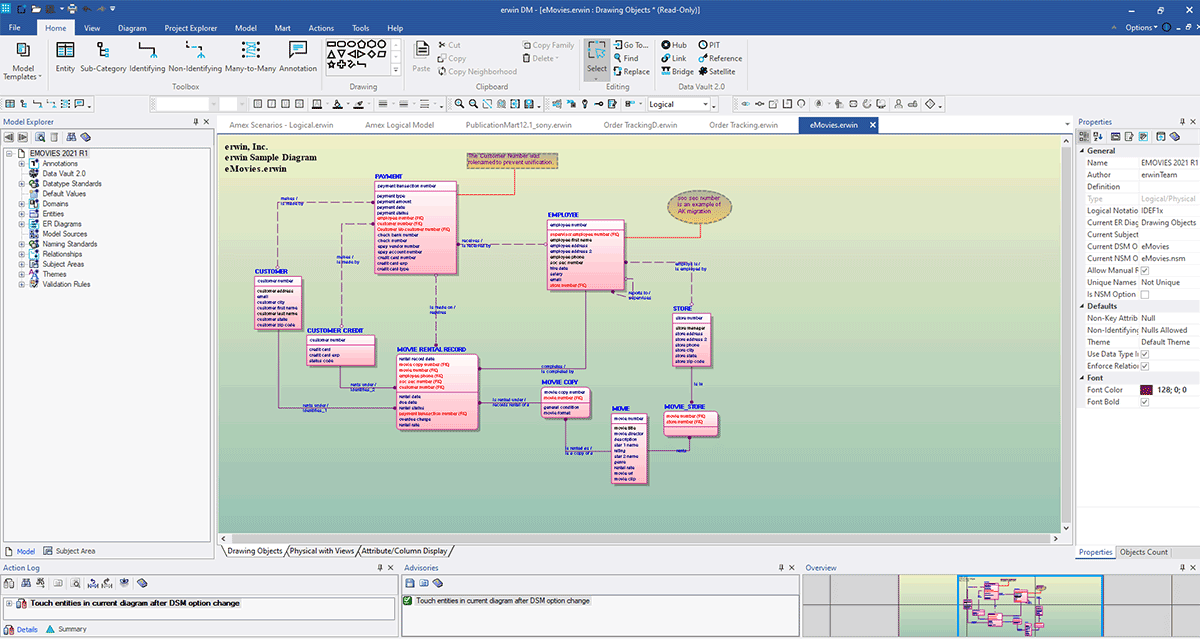
Aquí puede construir su modelo y documentar los detalles según sea necesario. Para obtener más información sobre cómo usar erwin Data Modeler, consulte su documentación de ayuda en línea.
Escenario n.º 2: Ingeniería inversa de un modelo de datos desde la plataforma Databricks Lakehouse
La ingeniería inversa de un modelo de datos consiste en crear un modelo de datos a partir de una base de datos o script existente. La herramienta de modelado crea una representación gráfica de los objetos de base de datos seleccionados y las relaciones entre ellos. Esta representación gráfica puede ser un modelo lógico o físico.
Nos conectaremos a Databricks desde erwin Data Modeler a través de Partner Connect:
Opciones de conexión:
| Parámetro | Descripción | Información adicional |
|---|---|---|
| Tipo de conexión | Especifica el tipo de conexión que desea utilizar. Seleccione Usar origen de datos ODBC para conectarse utilizando el origen de datos ODBC que ha definido. Seleccione Usar conexión JDBC para conectarse utilizando JDBC. | |
| Origen de datos ODBC | Especifica el origen de datos al que desea conectarse. La lista desplegable muestra los orígenes de datos que están definidos en su equipo. | Esta opción solo está disponible cuando el Tipo de conexión está configurado como Usar origen de datos ODBC. |
| Invocar administrador ODBC. | Especifica si desea iniciar el software del Administrador ODBC y mostrar el cuadro de diálogo Seleccionar origen de datos. A continuación, puede seleccionar un origen de datos definido previamente o crear un origen de datos. | Esta opción solo está disponible cuando el Tipo de conexión está configurado como Usar origen de datos ODBC. |
| Cadena de conexión | Especifica la cadena de conexión basada en su instancia de JDBC en el siguiente formato: jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | Esta opción solo está disponible cuando el Tipo de conexión está configurado como Usar conexión JDBC. Por ejemplo: jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
La siguiente captura de pantalla muestra la conectividad JDBC a través de erwin DataModeler al Databricks SQL Warehouse.
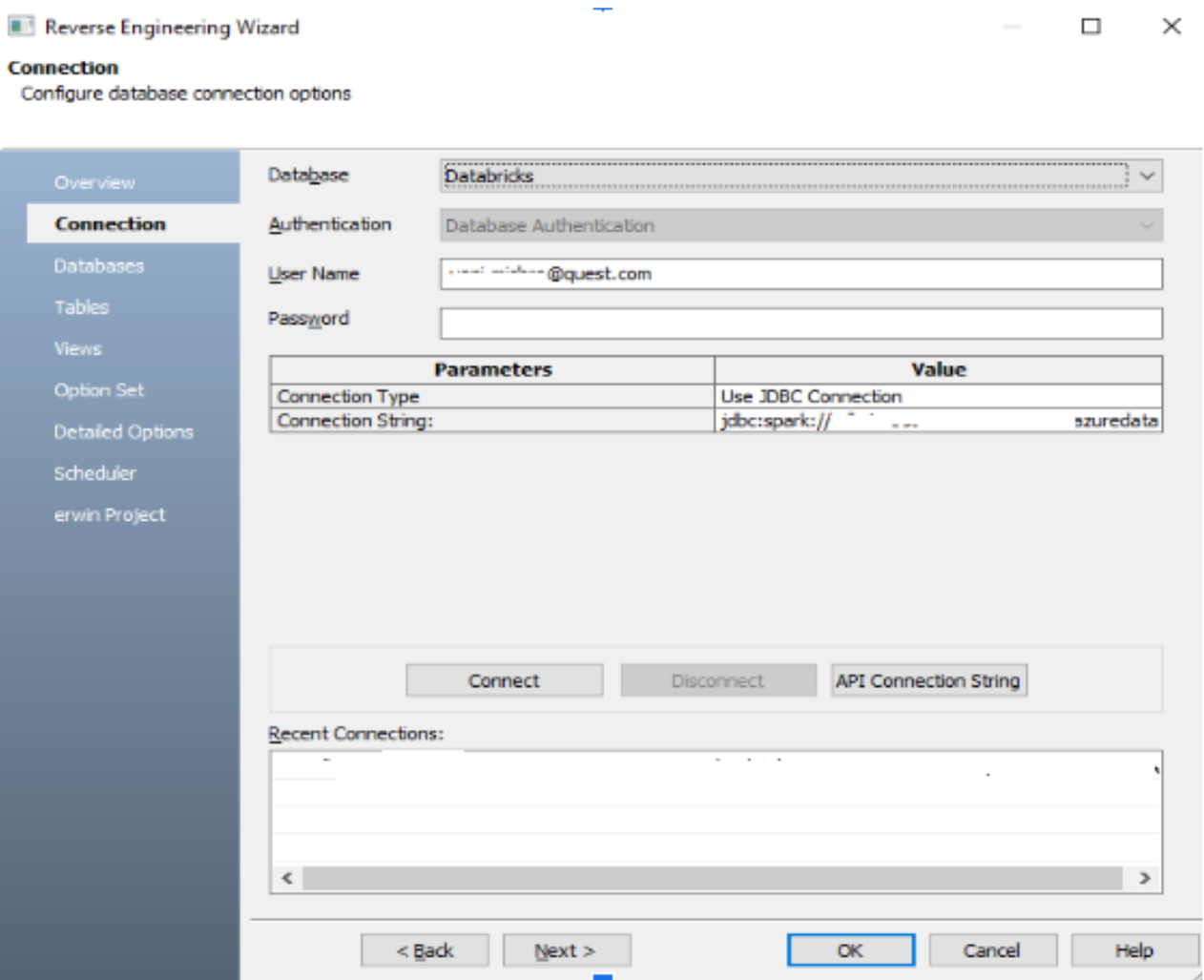
Nos permite ver todas las bases de datos disponibles y seleccionar en qué base de datos queremos construir nuestro modelo ERD, como se muestra a continuación.
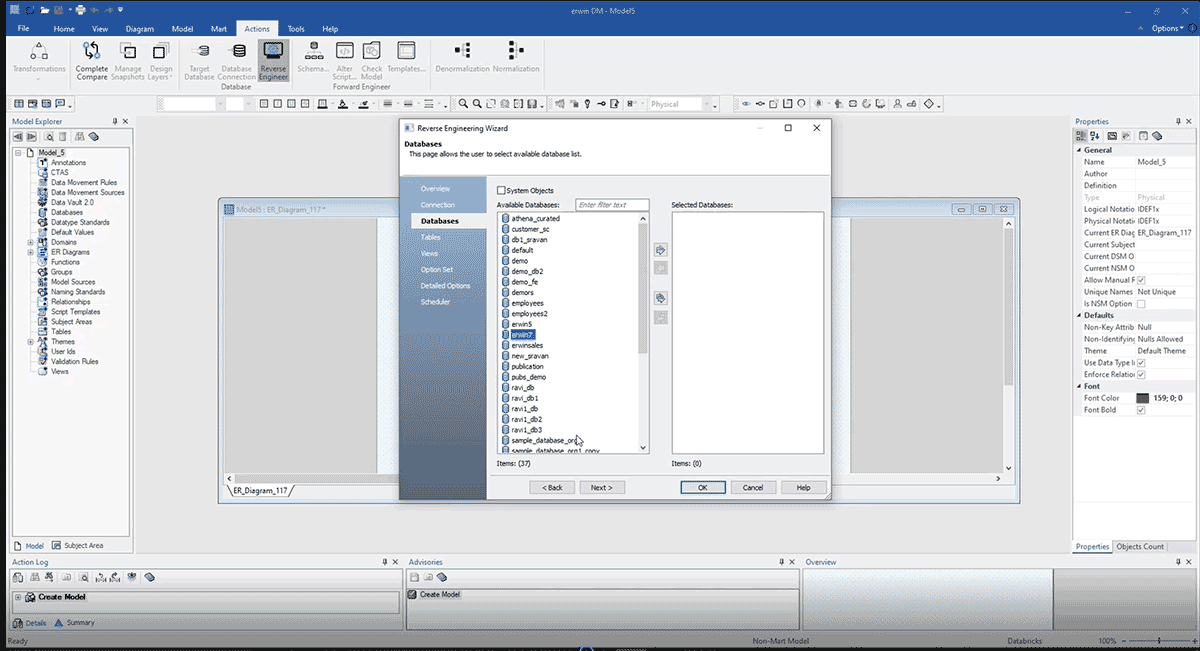
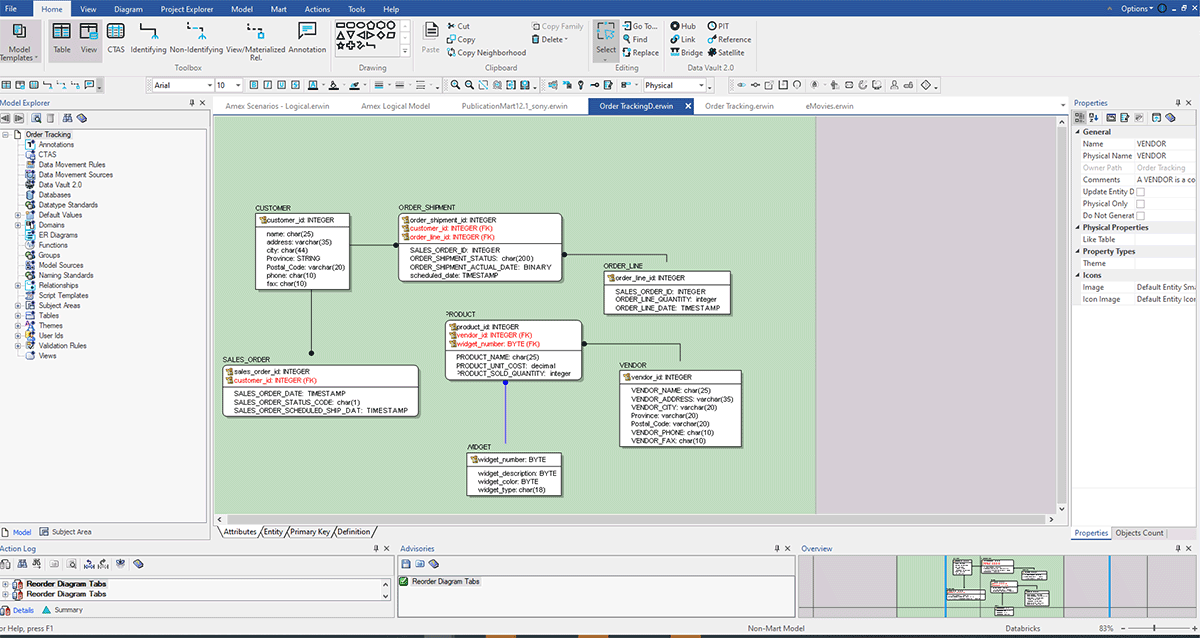
La captura de pantalla anterior muestra un ERD creado después de la ingeniería inversa desde Databricks con el método anterior. Aquí hay algunos beneficios de la ingeniería inversa de un modelo de datos:
- Mejor comprensión de los sistemas existentes: Al realizar ingeniería inversa de un sistema existente, puede comprender mejor cómo funciona y cómo interactúan sus diversos componentes. Le ayuda a identificar cualquier problema potencial o área de mejora.
- Ahorro de costos: La ingeniería inversa puede ayudarlo a identificar ineficiencias en un sistema existente, lo que genera ahorros de costos al optimizar procesos o identificar áreas de recursos desperdiciados.
- Ahorro de tiempo: La ingeniería inversa puede ahorrar tiempo al permitirle reutilizar código o estructuras de datos existentes en lugar de comenzar desde cero.
- Mejor documentación: La ingeniería inversa puede ayudarlo a crear documentación precisa y actualizada para un sistema existente, lo que puede ser útil para el mantenimiento y el desarrollo futuro.
- Migración más sencilla: La ingeniería inversa puede ayudarte a comprender las estructuras y relaciones de datos en un sistema existente, facilitando la migración de datos a un nuevo sistema o base de datos.
En general, la ingeniería inversa es valiosa y un paso fundamental para el modelado de datos. La ingeniería inversa permite una comprensión más profunda de un sistema existente y sus componentes, acceso controlado al proceso de diseño empresarial, total transparencia a través del ciclo de vida del modelado, mejoras en la eficiencia, ahorro de tiempo y costos, y mejor documentación, lo que conduce a mejores objetivos de gobernanza.
Escenario n.º 3: Migrar modelos de datos existentes a Databricks.
Los escenarios anteriores asumen que estás trabajando con una única fuente de datos, pero la mayoría de las empresas tienen diferentes data marts y EDW para respaldar sus necesidades de informes. Imagina que tu empresa se ajusta a esta descripción y ahora está creando un Databricks Lakehouse para consolidar sus plataformas de datos en la nube en una plataforma unificada para BI e IA. En esa situación, será fácil utilizar erwin Data Modeler para convertir tus modelos de datos existentes de un EDW heredado a un modelo de datos de Databricks. En el ejemplo a continuación, un modelo de datos creado para un EDW como SQL Server, Oracle o Teradata ahora se puede implementar en Databricks alterando la base de datos de destino a Databricks.
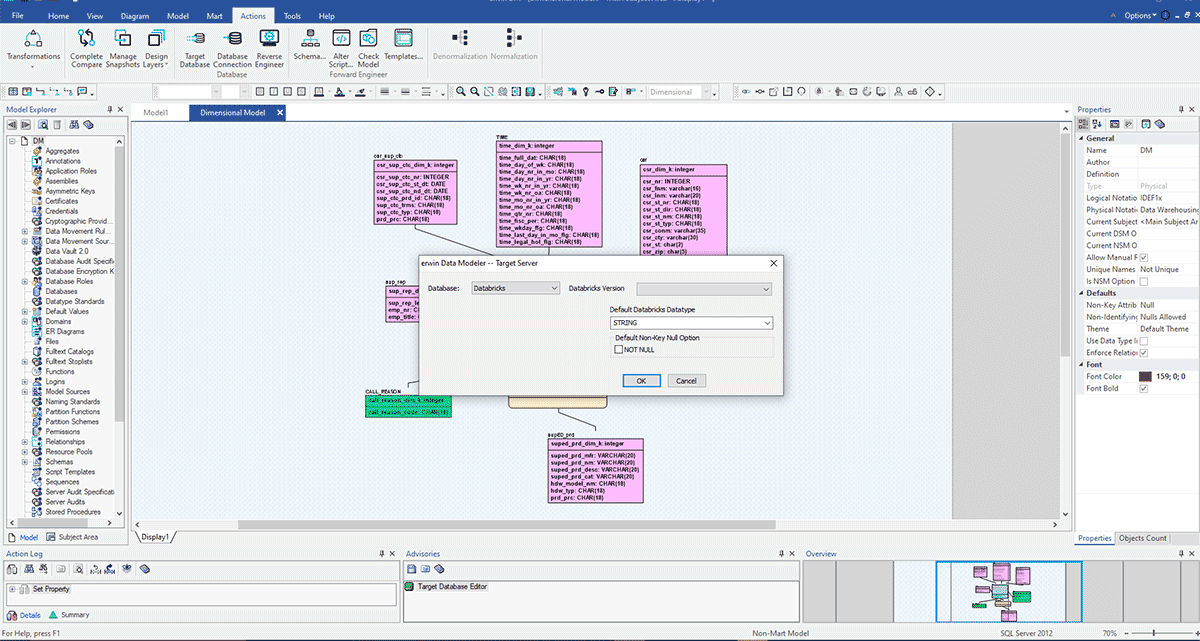
Como puedes ver en el área del círculo marcado, este modelo está creado para SQL Server. Ahora convertiremos este modelo y migraremos su implementación a Databricks cambiando el servidor de destino. Este tipo de conversión sencilla de tus modelos de datos ayuda a las organizaciones a migrar de forma rápida y segura modelos de datos de bases de datos heredadas o locales a la nube y a gobernar esos conjuntos de datos durante su ciclo de vida.
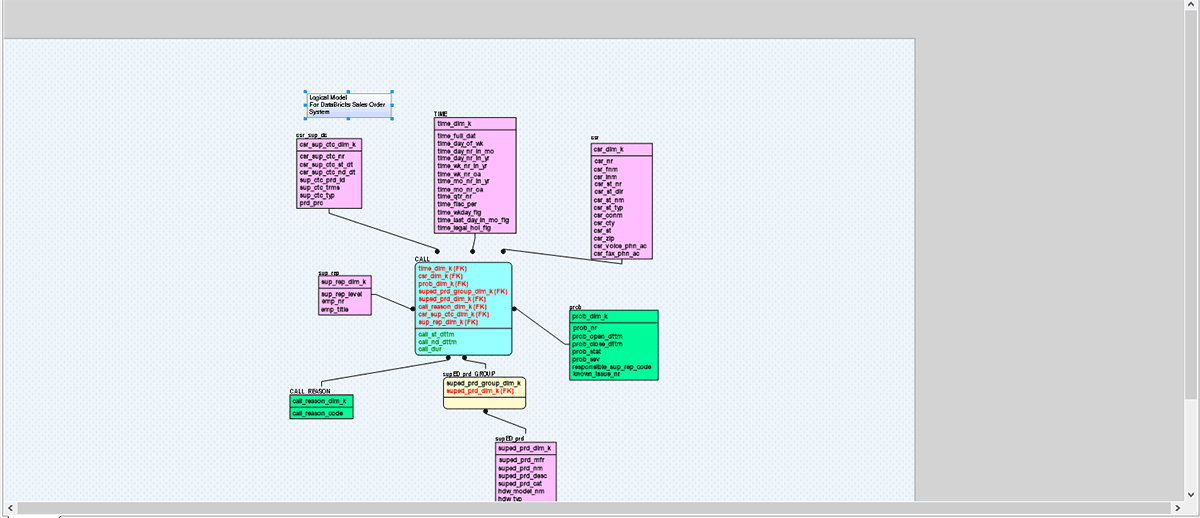
En la imagen anterior, intentamos convertir un modelo de datos heredado basado en SQL Server a Databricks con unos pocos pasos sencillos. Este tipo de ruta de migración sencilla permite y ayuda a las organizaciones a migrar de forma rápida y segura sus datos y activos a Databricks, fomenta la colaboración remota y mejora la seguridad.
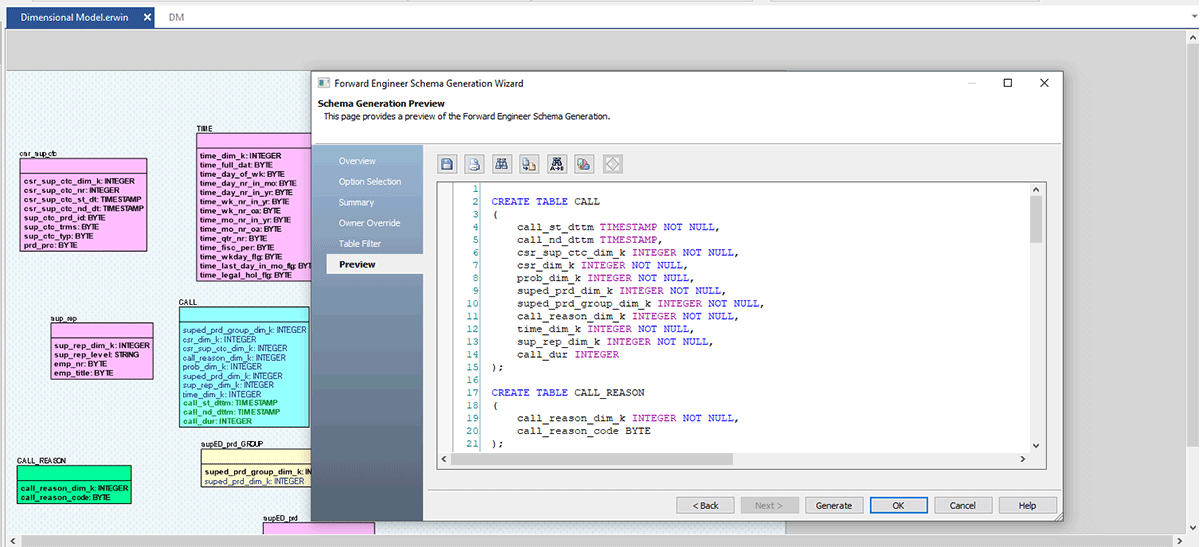
Ahora pasemos a nuestra parte final; una vez que el Modelo ER esté listo y aprobado por el equipo de arquitectura de datos, puedes generar rápidamente un archivo .sql desde erwin DM o conectarte a Databricks e ingeniar directamente este modelo en Databricks.
Sigue las capturas de pantalla a continuación, que explican el proceso paso a paso para crear un archivo DDL o un modelo de base de datos para Databricks.
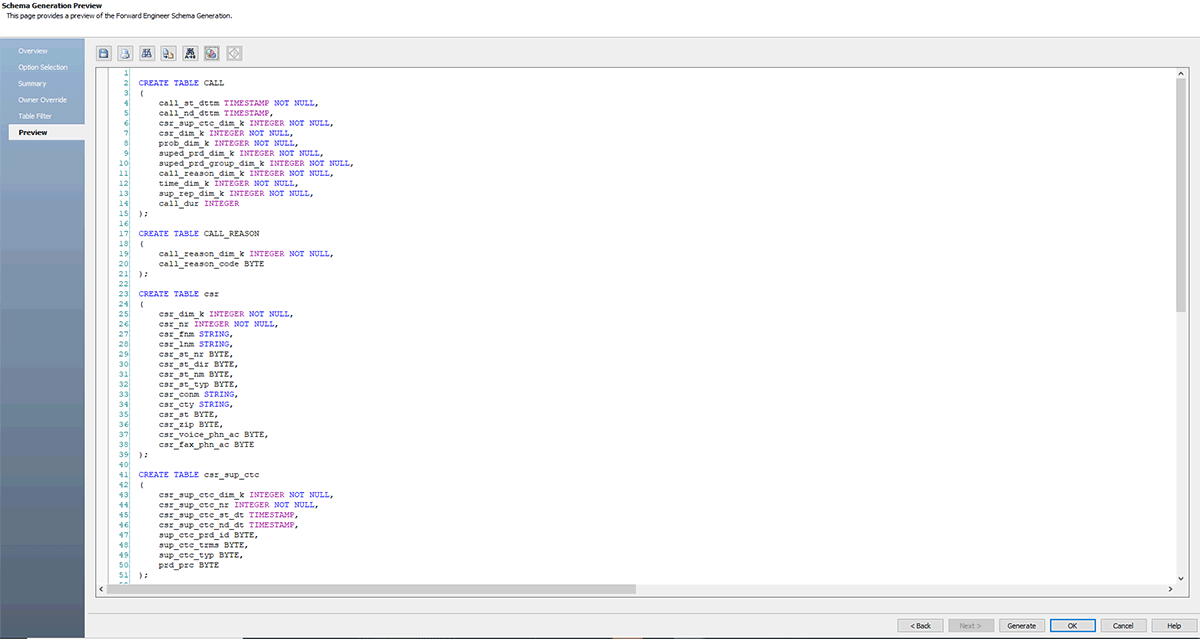
erwin Data Modeler Mart también es compatible con GitHub. Esta compatibilidad permite a tu equipo de DevOps controlar tus scripts en los repositorios de control de origen de tu elección. Ahora, con la compatibilidad con Git, puedes colaborar fácilmente con los desarrolladores y seguir flujos de trabajo de control de versiones.
Conclusión
En este blog, demostramos lo fácil que es crear, realizar ingeniería inversa o ingeniería directa de modelos de datos utilizando erwin Data Modeler y crear modelos de datos visuales para migrar tus definiciones de tabla a Databricks y realizar ingeniería inversa de modelos de datos para la gobernanza de datos y la creación de capas semánticas.
Este tipo de práctica de modelado de datos es el elemento clave para agregar valor a tu:
- Práctica de gobernanza de datos
- Reducción de costos y obtención de un valor más rápido para tus datos y metadatos
- Comprensión y mejora de los resultados empresariales y sus metadatos asociados
- Reducción de complejidades y riesgos
- Mejora de la colaboración entre el equipo de TI y los partes interesadas del negocio
- Mejor documentación
- Finalmente, un camino fácil para migrar de bases de datos heredadas a la plataforma Databricks
Comienza a usar erwin desde Databricks Partner Connect.
Prueba Databricks gratis durante 14 días.
Prueba erwin Data modeler
** erwin DM 12.5 viene con soporte para Unity Catalog de Databricks, donde podrás visualizar tus claves primarias y foráneas.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.