Spark Connect disponible en Apache Spark 3.4
Ejecuta aplicaciones Spark en cualquier lugar
por Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin y Kris Mo
El año pasado, Spark Connect se introdujo en la Data and AI Summit. Como parte de la versión recientemente lanzada de Apache SparkTM 3.4, Spark Connect ya está disponible de forma general. También hemos re-arquitectado recientemente Databricks Connect para basarlo en Spark Connect. Esta entrada de blog explica qué es Spark Connect, cómo funciona y cómo usarlo.
Los usuarios ahora pueden conectar IDEs, Notebooks y aplicaciones de datos modernas directamente a clústeres de Spark
Spark Connect introduce una arquitectura desacoplada de cliente-servidor que permite la conectividad remota a clústeres de Spark desde cualquier aplicación, ejecutándose en cualquier lugar. Esta separación de cliente y servidor permite que las aplicaciones de datos modernas, los IDEs, los Notebooks y los lenguajes de programación accedan a Spark de forma interactiva.
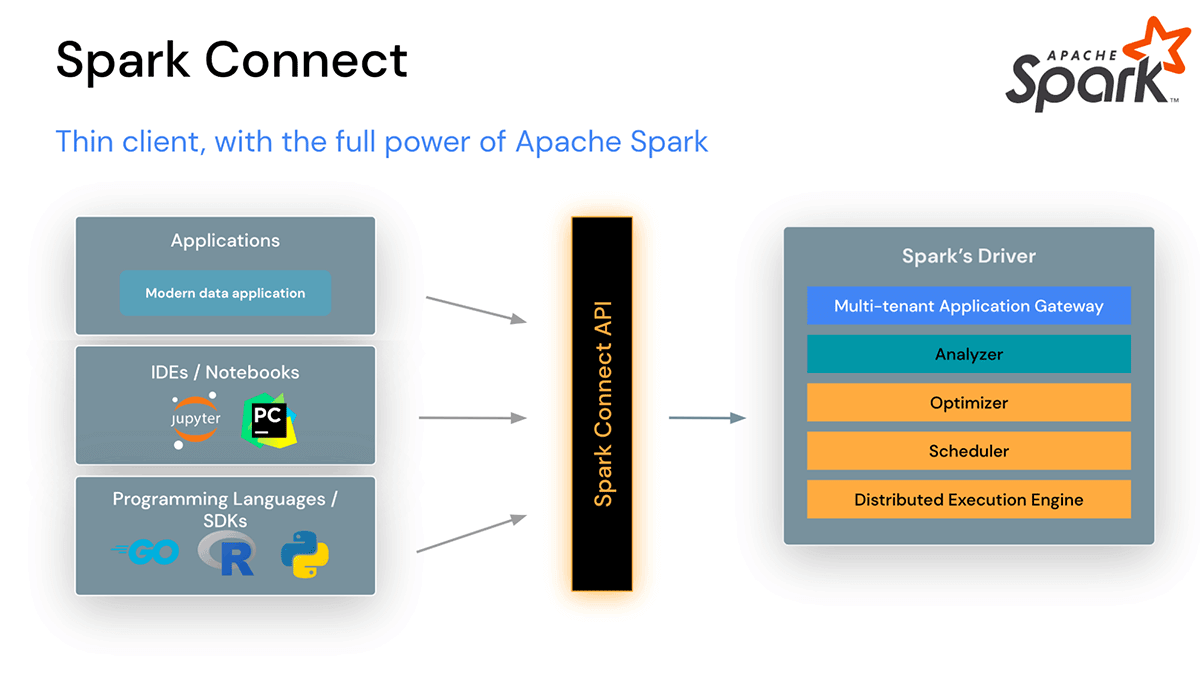
Spark Connect mejora la Estabilidad, Actualizaciones, Depuración y Observabilidad
Con esta nueva arquitectura, Spark Connect también mitiga problemas operativos comunes:
Estabilidad: Las aplicaciones que utilizan mucha memoria ahora solo afectarán a su propio entorno, ya que pueden ejecutarse en sus propios procesos fuera del clúster de Spark. Los usuarios pueden definir sus propias dependencias en el entorno del cliente y no necesitan preocuparse por posibles conflictos de dependencias en el driver de Spark.
Por ejemplo, si tiene una aplicación cliente que recupera un gran conjunto de datos de Spark para análisis o para realizar transformaciones, esa aplicación ya no se ejecutará en el driver de Spark. Esto significa que, si la aplicación utiliza mucha memoria o ciclos de CPU, no competirá por recursos con otras aplicaciones en el driver de Spark, lo que podría hacer que esas otras aplicaciones se ralenticen o fallen, porque ahora se ejecuta en su propio entorno separado y dedicado.
Actualizabilidad: En el pasado, era extremadamente complicado actualizar Spark, porque todas las aplicaciones del mismo clúster de Spark debían actualizarse junto con el clúster al mismo tiempo. Con Spark Connect, las aplicaciones se pueden actualizar independientemente del servidor, debido a la separación de cliente y servidor. Esto facilita mucho la actualización, ya que las organizaciones no tienen que realizar ningún cambio en sus aplicaciones cliente al actualizar Spark.
Depurabilidad y observabilidad: Spark Connect permite la depuración interactiva paso a paso durante el desarrollo directamente desde su IDE favorito. De manera similar, las aplicaciones se pueden monitorear utilizando las métricas nativas y las bibliotecas de registro del framework de la aplicación.
Por ejemplo, puede depurar interactivamente una aplicación cliente de Spark Connect en Visual Studio Code, inspeccionar objetos y ejecutar comandos de depuración para probar y corregir problemas en su código.
Cómo funciona Spark Connect
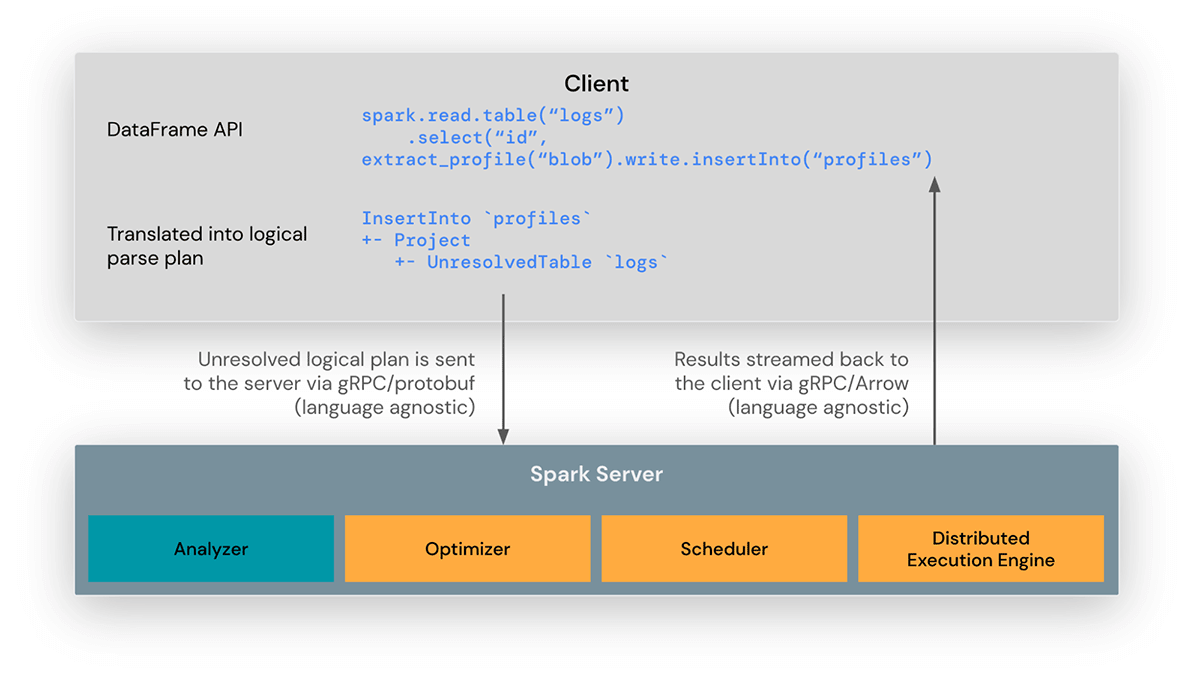
La biblioteca cliente de Spark Connect está diseñada para simplificar el desarrollo de aplicaciones Spark. Es una API ligera que se puede incrustar en todas partes: en servidores de aplicaciones, IDEs, notebooks y lenguajes de programación. La API de Spark Connect se basa en la API de DataFrame de Spark utilizando planes lógicos no resueltos como protocolo agnóstico al lenguaje entre el cliente y el driver de Spark.
El cliente de Spark Connect traduce las operaciones de DataFrame en planes lógicos no resueltos que se codifican mediante protocol buffers. Estos se envían al servidor utilizando el framework gRPC.
El endpoint de Spark Connect incrustado en el driver de Spark recibe y traduce los planes lógicos no resueltos en operadores de plan lógico de Spark. Esto es similar a analizar una consulta SQL, donde los atributos y las relaciones se analizan y se construye un plan de análisis inicial. A partir de ahí, entra en juego el proceso de ejecución estándar de Spark, lo que garantiza que Spark Connect aproveche todas las optimizaciones y mejoras de Spark. Los resultados se transmiten de vuelta al cliente a través de gRPC como lotes de resultados codificados en Apache Arrow.
Cómo usar Spark Connect
A partir de Spark 3.4, Spark Connect está disponible y soporta aplicaciones PySpark y Scala. Recorreremos un ejemplo de conexión a un servidor Apache Spark con Spark Connect desde una aplicación cliente utilizando la biblioteca cliente de Spark Connect.
Al escribir aplicaciones Spark, la única vez que necesita considerar Spark Connect es al crear sesiones de Spark. El resto de su código es exactamente el mismo que antes.
Para usar Spark Connect, simplemente puede establecer una variable de entorno (SPARK_REMOTE) para que su aplicación la recoja, sin realizar ningún cambio en el código, o puede incluir explícitamente Spark Connect en su código al crear sesiones de Spark.
Echemos un vistazo a un ejemplo de notebook de Jupyter. En este notebook, creamos una sesión de Spark Connect a un clúster de Spark local, creamos un DataFrame de PySpark y mostramos los 10 principales artistas de música por número de oyentes.
En este ejemplo, especificamos explícitamente que queremos usar Spark Connect estableciendo la propiedad remota al crear nuestra sesión de Spark (SparkSession.builder.remote...).
Código de notebook Jupyter usando Spark Connect
Puede descargar el conjunto de datos utilizado en el ejemplo desde aquí: Popularidad de artistas de música | Kaggle
Como se ilustra en el siguiente ejemplo, Spark Connect también facilita el cambio entre diferentes clústeres de Spark, por ejemplo, al desarrollar y probar en un clúster de Spark local y luego mover su código a producción en un clúster remoto.
En este ejemplo, establecemos la variable de entorno TEST_ENV para dirigir qué clúster de Spark y ubicación de datos utilizará nuestra aplicación, de modo que no tengamos que realizar ningún cambio en el código para cambiar entre nuestros clústeres de prueba, staging y producción.
Cambiando entre diferentes clústeres de Spark usando una variable de entorno
Para leer más sobre cómo usar Spark Connect, visite las páginas de Descripción general de Spark Connect y Inicio rápido de Spark Connect.
Databricks Connect está construido sobre Spark Connect
A partir de Databricks Runtime 13.0, Databricks Connect ahora está construido sobre Spark Connect de código abierto. Con esta arquitectura “v2”, Databricks Connect se convierte en un cliente ligero que es simple y fácil de usar. Se puede incrustar en todas partes para conectarse a Databricks: en IDEs, Notebooks y cualquier aplicación, lo que permite a clientes y socios crear nuevas experiencias de usuario (interactivas) basadas en su Databricks Lakehouse. Es muy fácil de usar: los usuarios simplemente incrustan la biblioteca Databricks Connect en sus aplicaciones y se conectan a su Databricks Lakehouse.
APIs soportadas en Apache Spark 3.4
PySpark: En Spark 3.4, Spark Connect soporta la mayoría de las APIs de PySpark, incluyendo DataFrame, Functions y Column. Las APIs de PySpark soportadas están etiquetadas como “Supports Spark Connect” en la documentación de referencia de la API, así que puedes verificar si las APIs que estás usando están disponibles antes de migrar código existente a Spark Connect.
Scala: En Spark 3.4, Spark Connect soporta la mayoría de las APIs de Scala, incluyendo Dataset, functions y Column.
El soporte para streaming llegará pronto y esperamos colaborar con la comunidad para ofrecer más APIs para Spark Connect en futuras versiones de Spark.
Spark Connect en Apache Spark 3.4 abre el acceso a Spark desde cualquier aplicación basada en DataFrames/DataSets en PySpark y Scala, y sienta las bases para soportar otros lenguajes de programación en el futuro.
Con un desarrollo simplificado de aplicaciones cliente, una mitigación de la contención de memoria en el driver de Spark, gestión de dependencias separada para aplicaciones cliente, actualizaciones independientes de cliente y servidor, depuración paso a paso en IDE y registro y métricas de cliente ligero, Spark Connect hace que el acceso a Spark sea ubicuo.
Para saber más sobre Spark Connect y empezar, visita las páginas de Spark Connect Overview y Spark Connect Quickstart.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.