Acelerando la Inferencia de LLM con Caché de Prompts para Modelos de Código Abierto en Databricks
Inferencia de LLM OSS más rápida y segura con caché de prompts.
por Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas y Chenyang Yu
- La caché de prompts reutiliza prefijos de prompts repetidos para que los LLM se ejecuten más rápido. Reduce la latencia y aumenta el rendimiento automáticamente.
- Databricks ahora admite la caché de prompts para modelos de código abierto en cargas de trabajo por lotes, pago por token y aprovisionadas. No se requiere configuración.
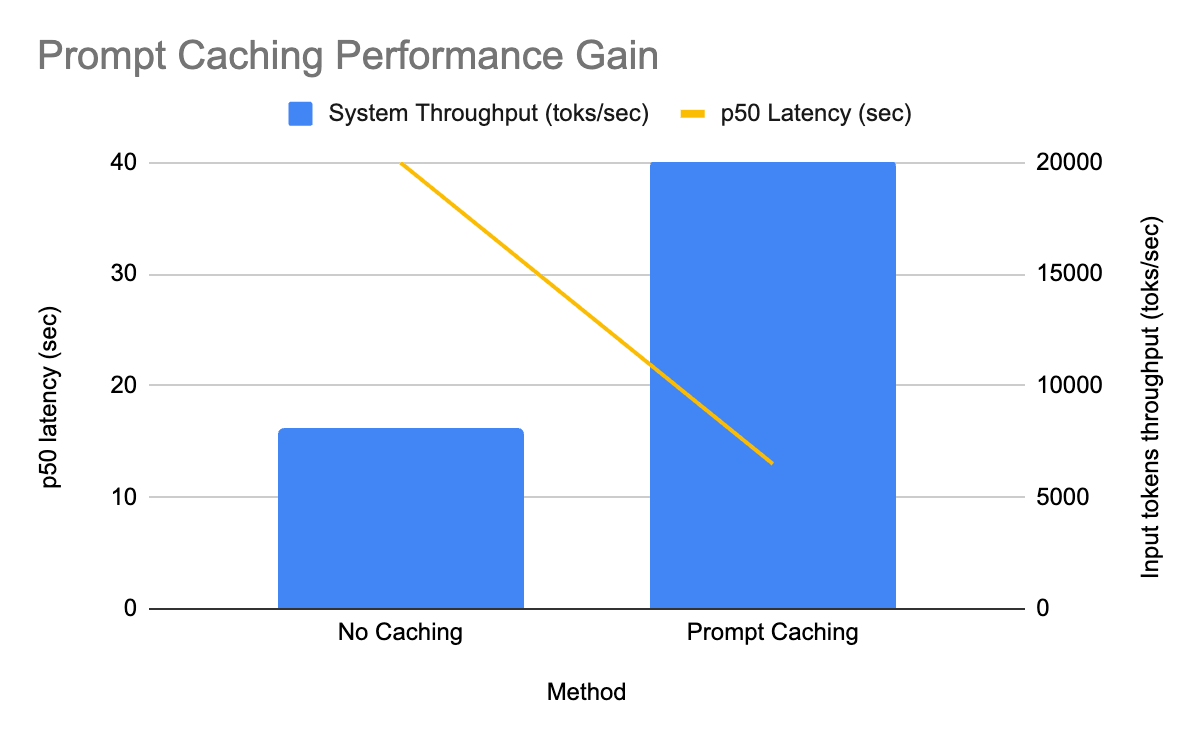
- En producción en GPT-OSS, la caché de prompts aumentó el rendimiento 2.5 veces y redujo la latencia P50 3 veces.
¿Por qué es importante la caché de prompts?
La inferencia de modelos de lenguaje grandes (LLM) a menudo implica prompts repetidos; piense en el mismo prompt de sistema o instrucción que aparece en miles de solicitudes. Reprocesar ese prefijo idéntico para cada llamada desperdicia ciclos de cómputo, infla la latencia y aumenta los costos.
La caché de prompts elimina esta redundancia, proporcionando:
- Menor latencia: se puede omitir la etapa de prellenado cuando se produce un acierto en la caché.
- Mayor rendimiento: se procesan más tokens por unidad de modelo.
La caché de prompts puede ser una técnica poderosa para mejorar la calidad de un modelo en dominios específicos sin comprometer el rendimiento de tokens del modelo. Las consultas pueden compartir un prompt de sistema grande específico del dominio, con el costo de cómputo de ese prompt compartido amortizado en todas esas consultas. Modelos de vanguardia, como Claude, usan prompts de sistema que tienen muchos miles de tokens de longitud internamente. Además, en nuestra investigación publicada recientemente demostramos que la optimización automatizada de prompts permite que los modelos de código abierto superen la calidad de los modelos de vanguardia para tareas empresariales.
Disponibilidad de características
Databricks ya proporciona caché de prompts integrada para modelos propietarios (GPT, Gemini, Claude). Ahora hemos extendido esta capacidad a los modelos de pesos abiertos que potencian nuestras APIs de Modelos Fundacionales (FMAPIs) para inferencia por lotes, pago por token y cargas de trabajo de rendimiento aprovisionado. También se aplica a todos los servicios de nivel superior potenciados por un modelo fundacional, por ejemplo, Agent Bricks, Genie, AI Functions.
La caché de prompts ahora es compatible con los siguientes modelos OSS alojados en Databricks:
- GPT‑OSS 20B y 120B
- Gemma 3 12B
- Llama 3.1 8B ajustado (a través de servicio PEFT)
- Llama 3.1 8B y 3.3 70B
Continuaremos implementando esta característica en nuestros otros modelos. La seguridad es una preocupación de primera clase en Databricks. Las cachés de prompts están aisladas, solo residen en memoria volátil y nunca se persisten. Es importante destacar que la caché es implícita: los clientes no necesitan configurar nada, nuestro sistema está diseñado para ejecutar automáticamente la caché de prompts y la reutilización para mejorar el rendimiento.
Impacto en el mundo real: inferencia por lotes en GPT OSS
Implementamos la caché de prompts primero en nuestros modelos GPT‑OSS y de inmediato vimos mejoras medibles en uno de los pipelines de inferencia por lotes de producción a gran escala:
- El rendimiento de tokens de entrada por réplica aumentó 2.5 veces
- La latencia P50 se redujo 3 veces
- Todo esto con una relación de aciertos de caché relativamente baja del 30%
Conclusión
Al reutilizar automáticamente las cachés KV para prompts idénticos, Databricks te permite ejecutar LLMs de código abierto de manera más rápida, rentable y segura, todo sin requerir configuración adicional. Ya sea que estés sirviendo chat en tiempo real, procesando grandes colecciones de documentos por lotes o construyendo agentes de IA, la caché de prompts puede convertir un buen pipeline de inferencia en uno excelente. Pruébalo en tu próxima implementación de modelo OSS y observa cómo aumentan las métricas de rendimiento.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.