Construye Agentes Empresariales de Vanguardia 90 veces más baratos con Optimización Automatizada de Prompts
Databricks Agent Bricks es una plataforma para crear, evaluar y desplegar agentes de IA de nivel de producción para flujos de trabajo empresariales. Nuestro objetivo es ayudar a los clientes a lograr el equilibrio óptimo entre calidad y costo en la frontera de Pareto para sus tareas específicas del dominio, y a mejorar continuamente sus agentes que razonan sobre sus propios datos. Para apoyar esto, desarrollamos benchmarks centrados en la empresa y realizamos evaluaciones empíricas en agentes que miden la precisión y la eficiencia de servicio, reflejando las compensaciones reales que las empresas enfrentan en producción.
Dentro de nuestro conjunto de herramientas más amplio para la optimización de agentes, esta publicación se centra en la optimización automatizada de prompts, una técnica que aprovecha la búsqueda estructurada e iterativa guiada por señales de retroalimentación de la evaluación para mejorar automáticamente los prompts. Demostramos cómo podemos:
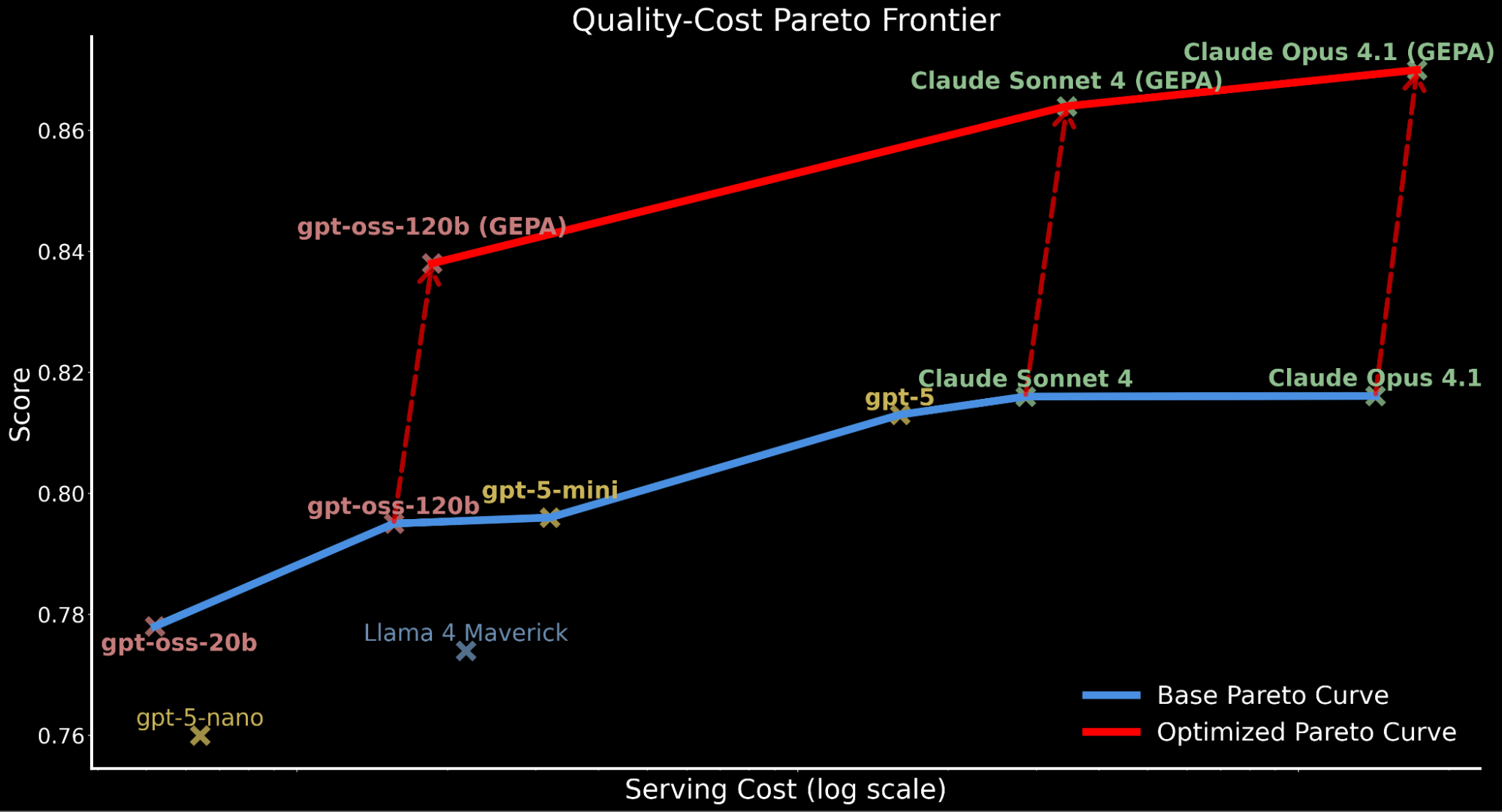
- Permitir que los modelos de código abierto superen la calidad de los modelos de frontera para tareas empresariales: aprovechando GEPA, una técnica de optimización de prompts recientemente lanzada de la investigación de Databricks y UC Berkeley, presentamos cómo gpt-oss-120b supera a los modelos propietarios de vanguardia Claude Sonnet 4 y Claude Opus 4.1 en ~3%, siendo aproximadamente 20 veces y 90 veces más económico de servir, respectivamente (ver gráfico de la frontera de Pareto a continuación).
- Elevar aún más los modelos de frontera propietarios: aplicamos el mismo enfoque a los modelos propietarios líderes, elevando el rendimiento base de Claude Opus 4.1 y Claude Sonnet 4 en un 6-7% y logrando un nuevo rendimiento de vanguardia.
- Ofrecer una compensación superior de calidad-costo en comparación con SFT: la optimización automatizada de prompts ofrece un rendimiento a la par o mejor que el ajuste fino supervisado (SFT), al tiempo que reduce los costos de servicio en un 20%. También mostramos que la optimización de prompts y SFT pueden trabajar juntos para mejorar aún más el rendimiento.
En las siguientes secciones, cubriremos
- cómo evaluamos el rendimiento de los agentes de IA en la extracción de información como un caso de uso principal y por qué es importante para los flujos de trabajo empresariales;
- una descripción general de cómo funciona la optimización de prompts, los tipos de beneficios que puede desbloquear, especialmente en escenarios donde el ajuste fino no es práctico, y las ganancias de rendimiento en nuestro pipeline de evaluación;
- para poner estas ganancias en contexto, mediremos el impacto de la optimización de prompts y analizaremos la economía detrás de estas técnicas;
- comparación de rendimiento con el ajuste fino supervisado (SFT), destacando la compensación superior de calidad-costo de la optimización de prompts;
- conclusiones y próximos pasos, particularmente cómo puede comenzar a aplicar estas técnicas directamente con Databricks Agent Bricks para construir agentes de IA de primera clase optimizados para la implementación empresarial en el mundo real.
Evaluación de los últimos LLM en IE Bench
Extracción de Información (IE) es una característica principal de Agent Bricks, que convierte fuentes no estructuradas como PDFs o documentos escaneados en registros estructurados. A pesar del rápido progreso en las capacidades de IA generativa, la IE sigue siendo difícil a escala empresarial:
- Los documentos son extensos y están llenos de jerga específica del dominio
- Los esquemas son complejos, jerárquicos y contienen ambigüedades
- Las etiquetas a menudo son ruidosas e inconsistentes
- La tolerancia operativa al error en la extracción es baja
- Requisito de alta fiabilidad y eficiencia de costos para cargas de trabajo de inferencia grandes
Como resultado, observamos que el rendimiento puede variar ampliamente según el dominio y la complejidad de la tarea, por lo que la creación de los sistemas de IA compuestos adecuados para IE en diversos casos de uso requiere una evaluación exhaustiva de las capacidades variables de los agentes de IA.
Para explorar esto, desarrollamos IE Bench, un conjunto de evaluación integral que abarca múltiples dominios empresariales del mundo real como finanzas, legal, comercio y atención médica. El benchmark refleja desafíos complejos del mundo real, incluidos documentos de más de 100 páginas, que abarcan entidades de extracción con más de 70 campos, y esquemas jerárquicos con múltiples niveles anidados. Informamos las evaluaciones en el conjunto de prueba retenido del benchmark para proporcionar una medida confiable del rendimiento en el mundo real.
Evaluamos la última generación de modelos de código abierto servidos a través de la API de Databricks Foundation Models, incluida la serie gpt-oss recién lanzada, así como modelos propietarios líderes de múltiples proveedores, incluida la última familia GPT-5.1
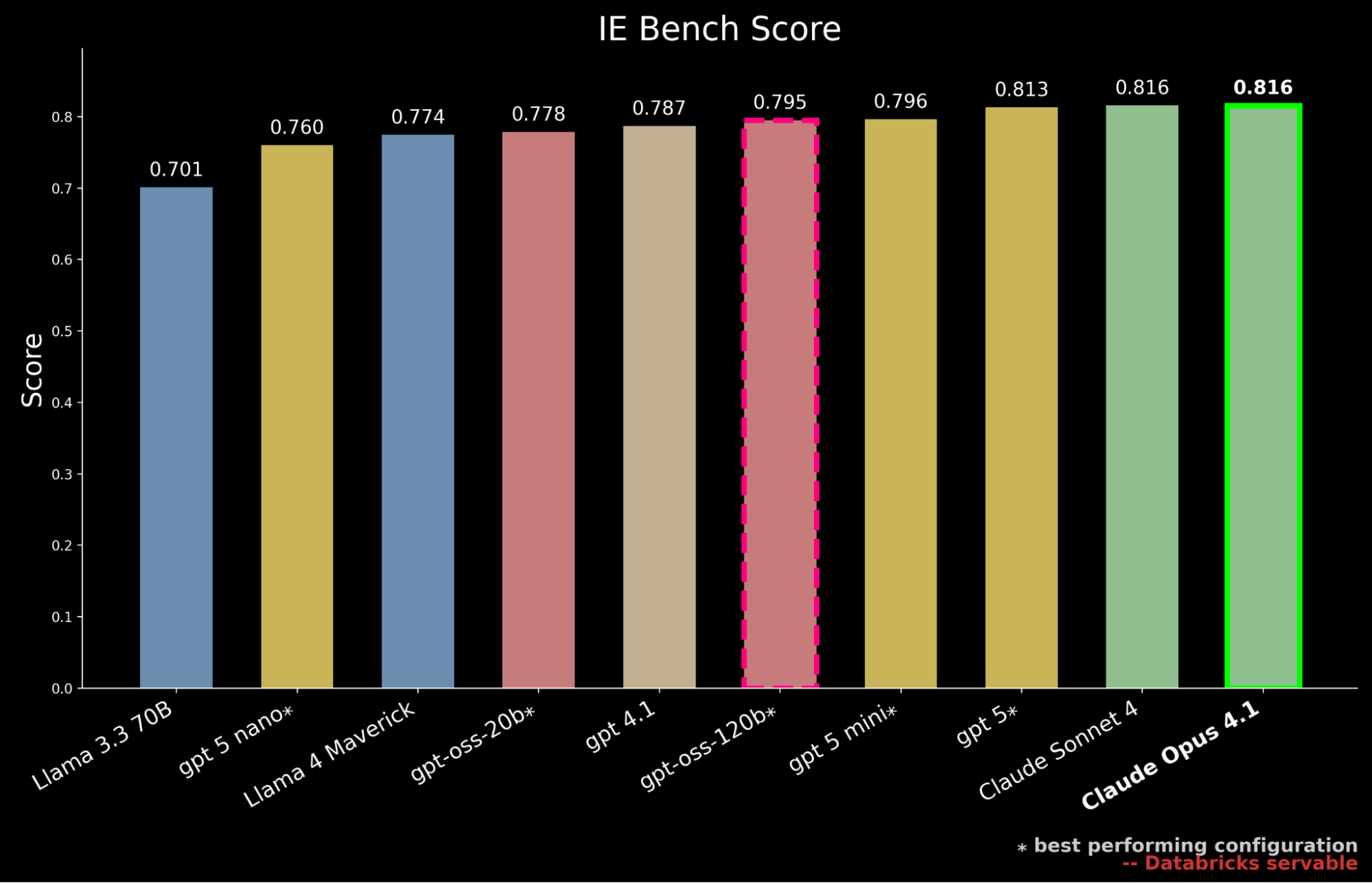
Nuestros resultados muestran que gpt-oss-120b es el modelo de código abierto con el mejor rendimiento en IE Bench, superando el rendimiento de vanguardia previamente de código abierto de Llama 4 Maverick en ~3% y acercándose al nivel de rendimiento de gpt-5-mini, lo que marca un avance significativo para los modelos de código abierto. Sin embargo, todavía está por detrás del rendimiento de los modelos de frontera propietarios, quedando por detrás de gpt-5, Claude Sonnet 4 y Claude Opus 4.1, que logra la puntuación más alta en el benchmark.
Sin embargo, en entornos empresariales, el rendimiento también debe sopesarse frente al costo de servicio. Contextualizamos aún más nuestros hallazgos anteriores al destacar que gpt-oss-120b iguala el rendimiento de gpt-5-mini incurriendo solo en aproximadamente el 50% del costo de servicio. 2 Los modelos de frontera propietarios son en gran medida más caros, con gpt-5 a ~10 veces el costo de servicio de gpt-oss-120b, Claude Sonnet 4 a ~20 veces y Claude Opus 4.1 a ~90 veces.
Para ilustrar la compensación calidad-costo entre los modelos, trazamos la frontera de Pareto a continuación, representando el rendimiento base para todos los modelos antes de cualquier mejora.
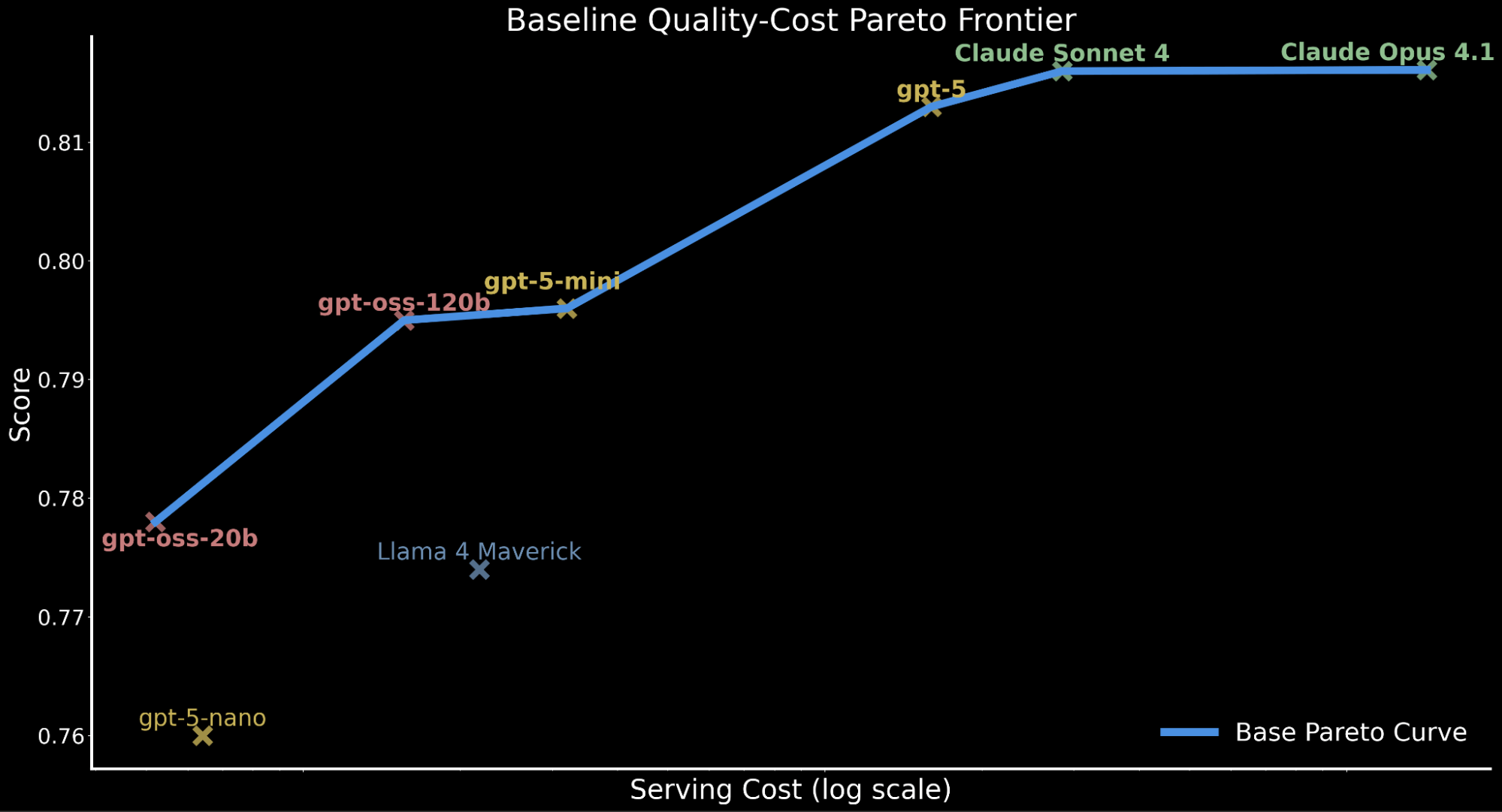
Esta compensación calidad-costo tiene implicaciones importantes para las cargas de trabajo empresariales que requieren inferencia a gran escala y que deben considerar el presupuesto de cómputo y el rendimiento de servicio manteniendo una precisión de alto rendimiento.
Esto motiva nuestra exploración: ¿Podemos llevar gpt-oss-120b a una calidad de frontera preservando su eficiencia de costos? Si es así, esto ofrecería un rendimiento líder en la frontera de Pareto de costo-calidad y sería servible para la adopción empresarial en Databricks.
Optimización de modelos de código abierto para superar el rendimiento de los modelos de frontera
Exploramos la optimización automática de prompts como un método sistemático para mejorar el rendimiento del modelo. La ingeniería manual de prompts puede ofrecer ganancias, pero típicamente depende de la experiencia en el dominio y la experimentación de prueba y error. Esta complejidad aumenta aún más en sistemas de IA compuestos que integran múltiples llamadas a LLM y herramientas externas que deben optimizarse conjuntamente, lo que hace que la optimización manual de prompts sea poco práctica de escalar o mantener en pipelines de producción.
La optimización de prompts ofrece un enfoque diferente, aprovechando la búsqueda estructurada guiada por señales de retroalimentación para mejorar automáticamente los prompts. Dichos optimizadores son independientes del pipeline y pueden optimizar conjuntamente múltiples prompts interdependientes en pipelines de múltiples etapas, lo que hace que estas técnicas sean robustas y adaptables en sistemas de IA compuestos y diversas tareas.
Para probar esto, aplicamos algoritmos de optimización automática de prompts, específicamente MIPROv2, SIMBA y GEPA, un nuevo optimizador de prompts de la investigación de Databricks y UC Berkeley que combina la reflexión basada en lenguaje con la búsqueda evolutiva para mejorar los sistemas de IA. Aplicamos estos algoritmos para evaluar cómo la optimización de prompts puede cerrar la brecha entre el modelo de código abierto con mejor rendimiento, gpt-oss-120b, y los modelos de frontera cerrados de vanguardia.
Consideramos las siguientes configuraciones de optimizadores automáticos de prompts en nuestra exploración
Cada técnica de optimización de prompts se basa en un modelo optimizador para refinar diferentes aspectos del prompt para un modelo estudiante objetivo. Dependiendo del algoritmo, el modelo optimizador puede generar ejemplos few-shot a partir de trazas bootstrapped para aplicar aprendizaje in-context y/o proponer y mejorar las instrucciones de la tarea a través de algoritmos de búsqueda que realizan reflexión iterativa utilizando feedback para mutar y seleccionar mejores prompts a lo largo de los ensayos de optimización. Estos insights se destilan en prompts mejorados para que el modelo estudiante los use durante el tiempo de inferencia en la producción. Si bien se puede usar el mismo LLM para ambos roles, también experimentamos con el uso de un “modelo de mayor rendimiento” como modelo optimizador para explorar si una guía de mayor calidad puede mejorar aún más el rendimiento del modelo estudiante.
Basándonos en nuestros hallazgos anteriores de gpt-oss-120b como el modelo open-source líder en IE Bench, lo consideramos nuestra línea base de modelo estudiante para explorar mejoras adicionales.
Al optimizar gpt-oss-120b, consideramos dos configuraciones:
- gpt-oss-120b (optimizador) → gpt-oss-120b (estudiante)
- Claude Sonnet 4 (optimizador) → gpt-oss-120b (estudiante)
Dado que Claude Sonnet 4 logra un rendimiento líder en IE Bench sobre gpt-oss-120b, y es relativamente más económico en comparación con Claude Opus 4.1 con un rendimiento similar, exploramos la hipótesis de si aplicar un modelo optimizador más potente puede producir un mejor rendimiento para gpt-oss-120b.
Evaluamos cada configuración en las técnicas de optimización y comparamos con la línea base de gpt-oss-120b respectiva:
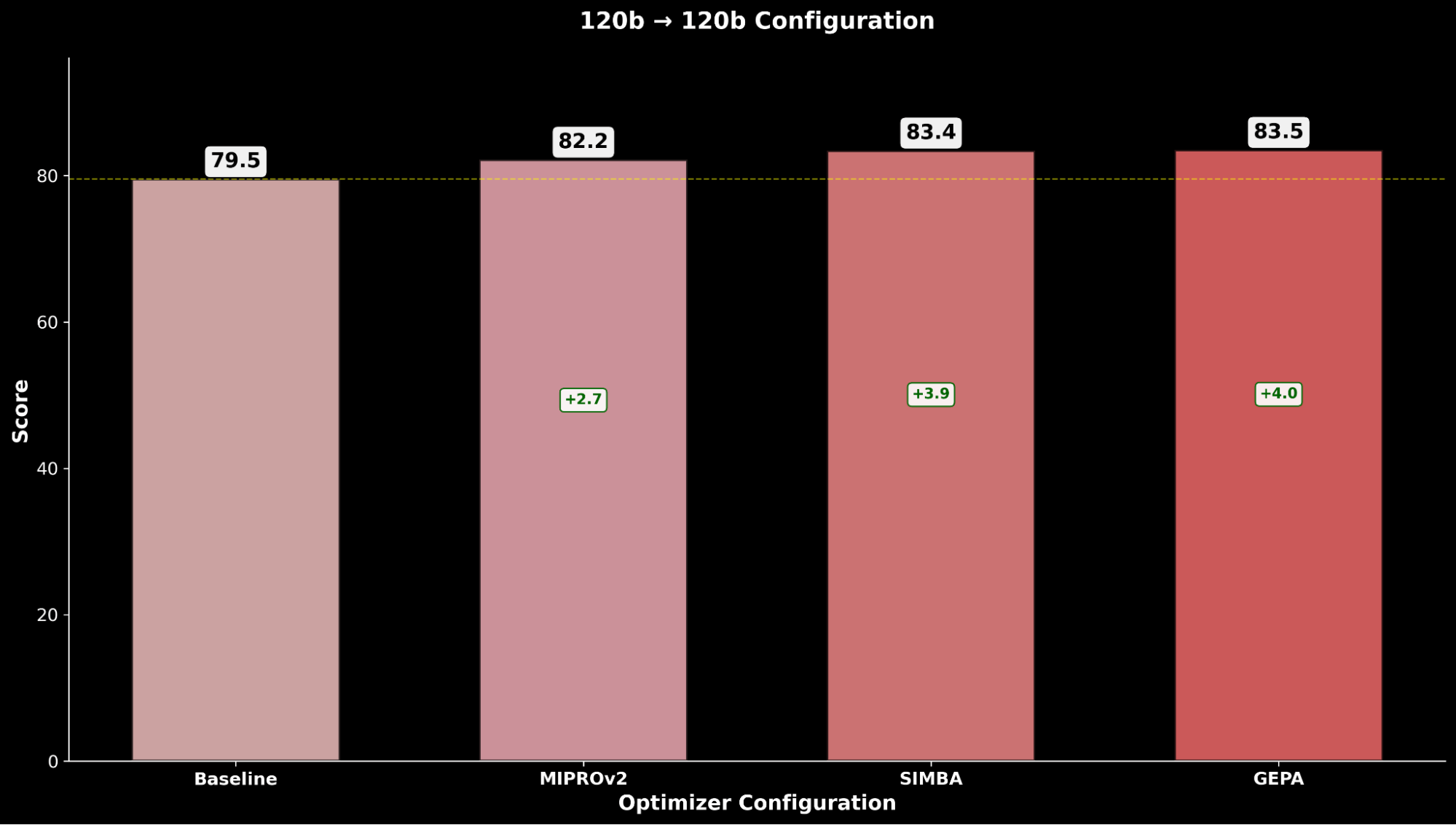
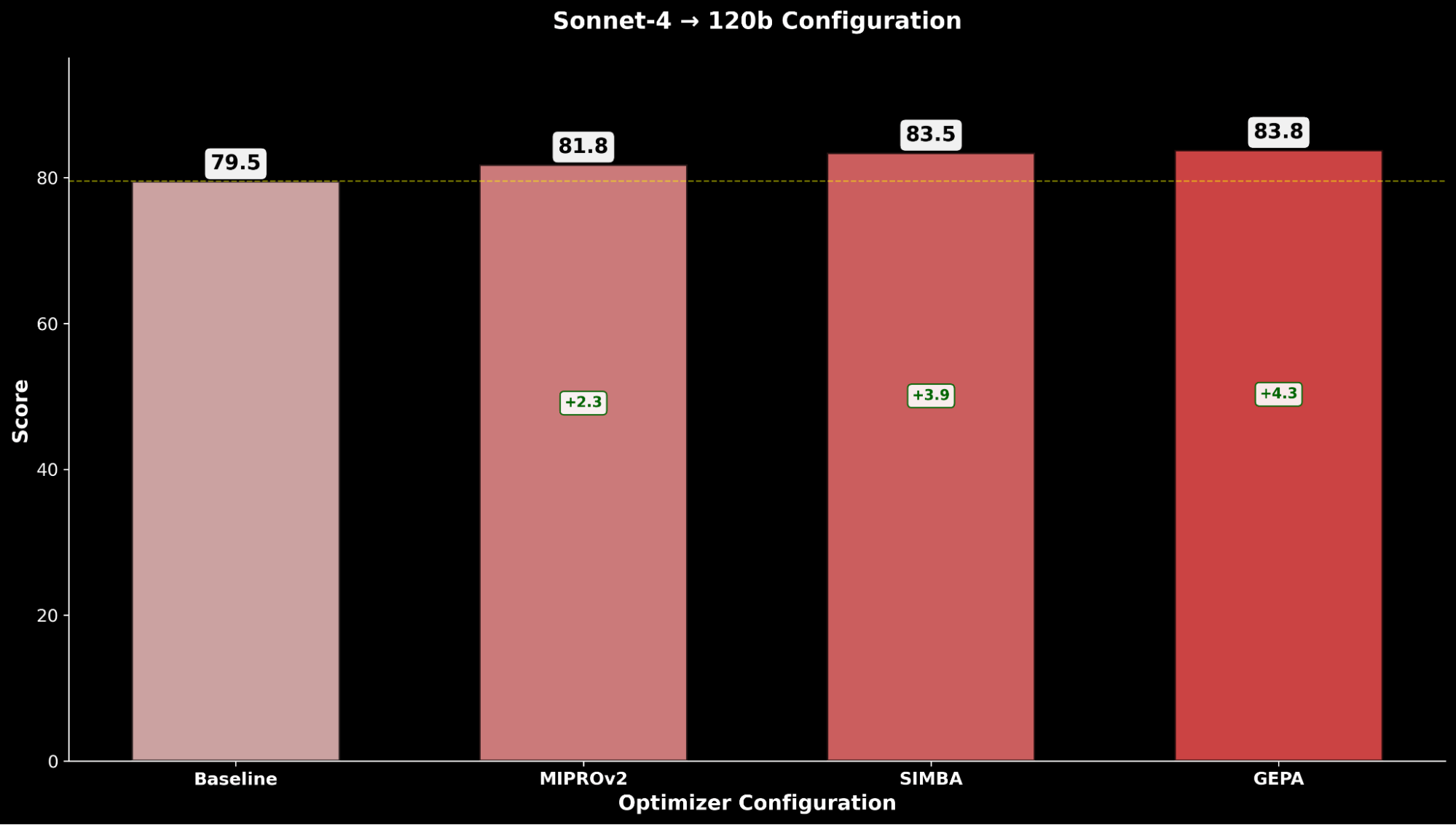
En IE Bench, encontramos que optimizar gpt-oss-120b con Claude Sonnet 4 como modelo optimizador logra la mayor mejora sobre el rendimiento base de gpt-oss-120b, con una mejora significativa de +4.3 puntos sobre la línea base y una mejora de +0.3 puntos sobre la optimización de gpt-oss-120b consigo mismo como modelo optimizador, lo que resalta el impulso a través del uso de un modelo optimizador más potente.
Comparamos la configuración de gpt-oss-120b optimizada por GEPA con el mejor rendimiento contra los modelos Claude de vanguardia:
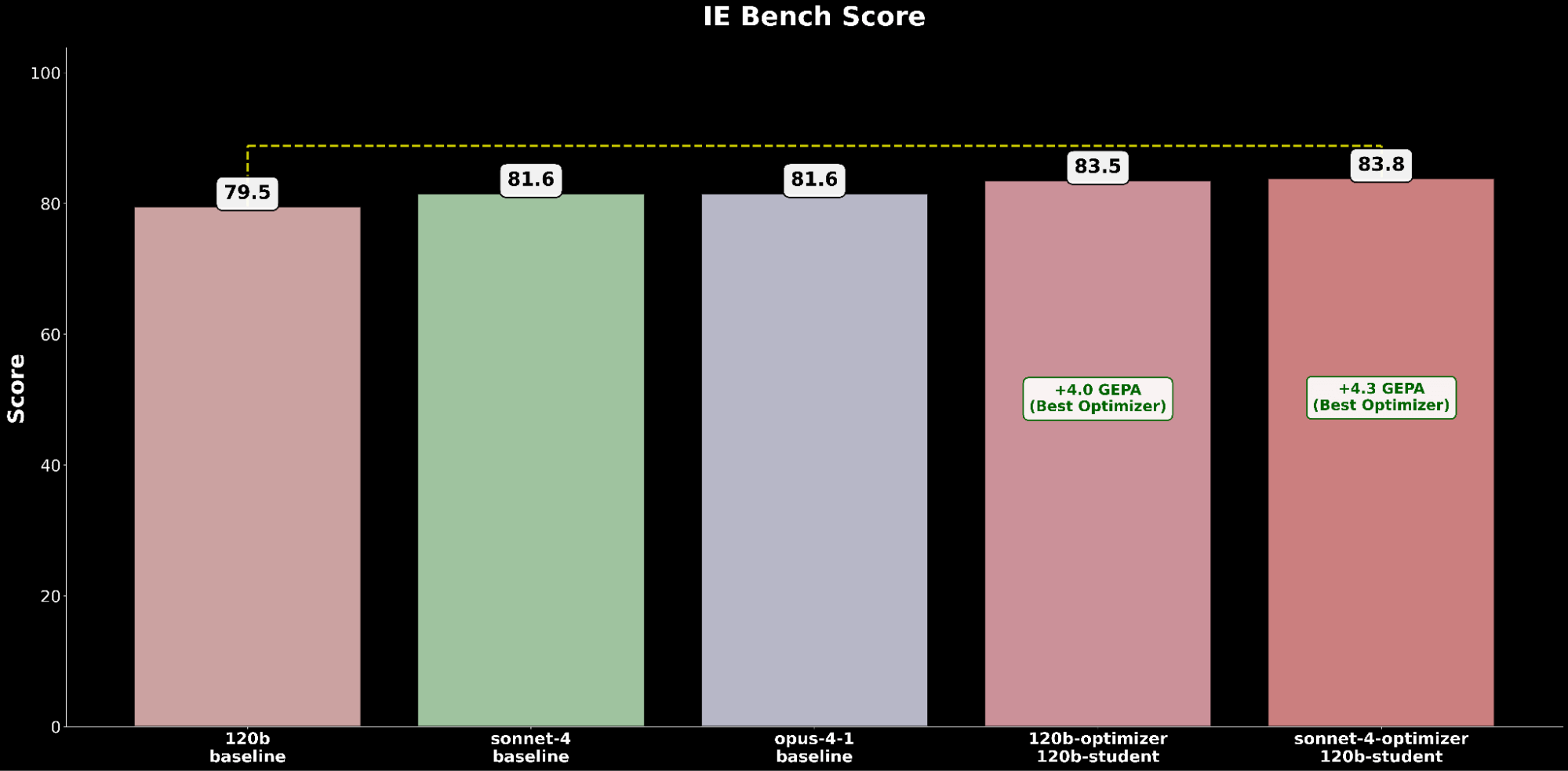
La configuración optimizada de gpt-oss-120b supera el rendimiento base del estado del arte de Claude Opus 4.1 en una ganancia absoluta de +2.2 puntos, lo que resalta los beneficios de la optimización automatizada de prompts para elevar un modelo de código abierto a superar a los modelos propietarios líderes en capacidades de IE.
Optimizar modelos de vanguardia para elevar aún más el techo de rendimiento
Al ver la importancia de la optimización automatizada de prompts, exploramos si aplicar el mismo principio a los modelos de vanguardia líderes Claude Sonnet 4 y Claude Opus 4.1 puede empujar aún más el techo de rendimiento alcanzable para IE Bench.
Al optimizar cada modelo propietario, consideramos las siguientes configuraciones:
- Claude Sonnet 4 (optimizador) → Claude Sonnet 4 (estudiante)
- Claude Opus 4.1 (optimizador) → Claude Opus 4.1 (estudiante)
Elegimos considerar las configuraciones predeterminadas del modelo optimizador, ya que estos modelos ya definen la frontera de rendimiento.
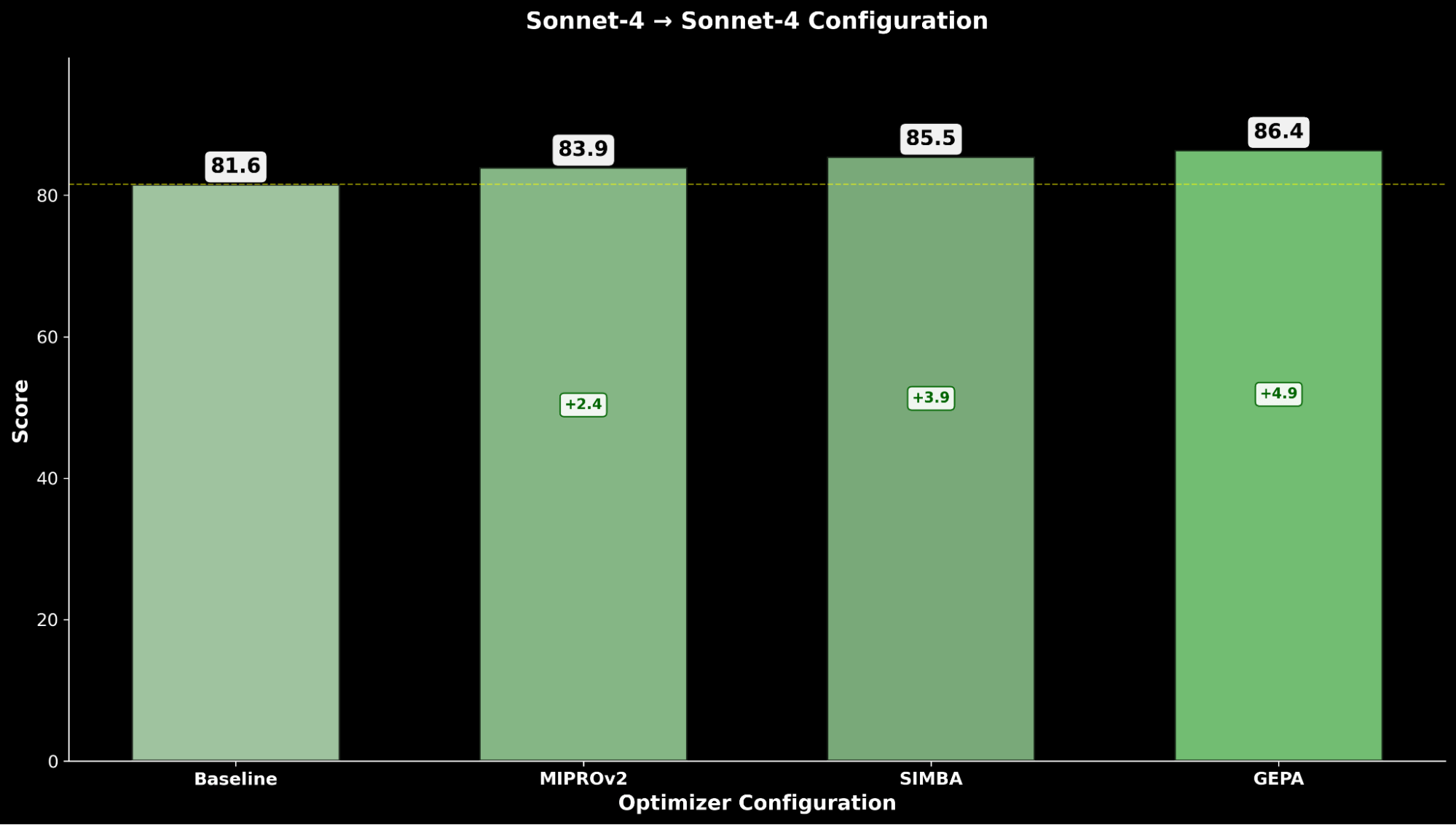
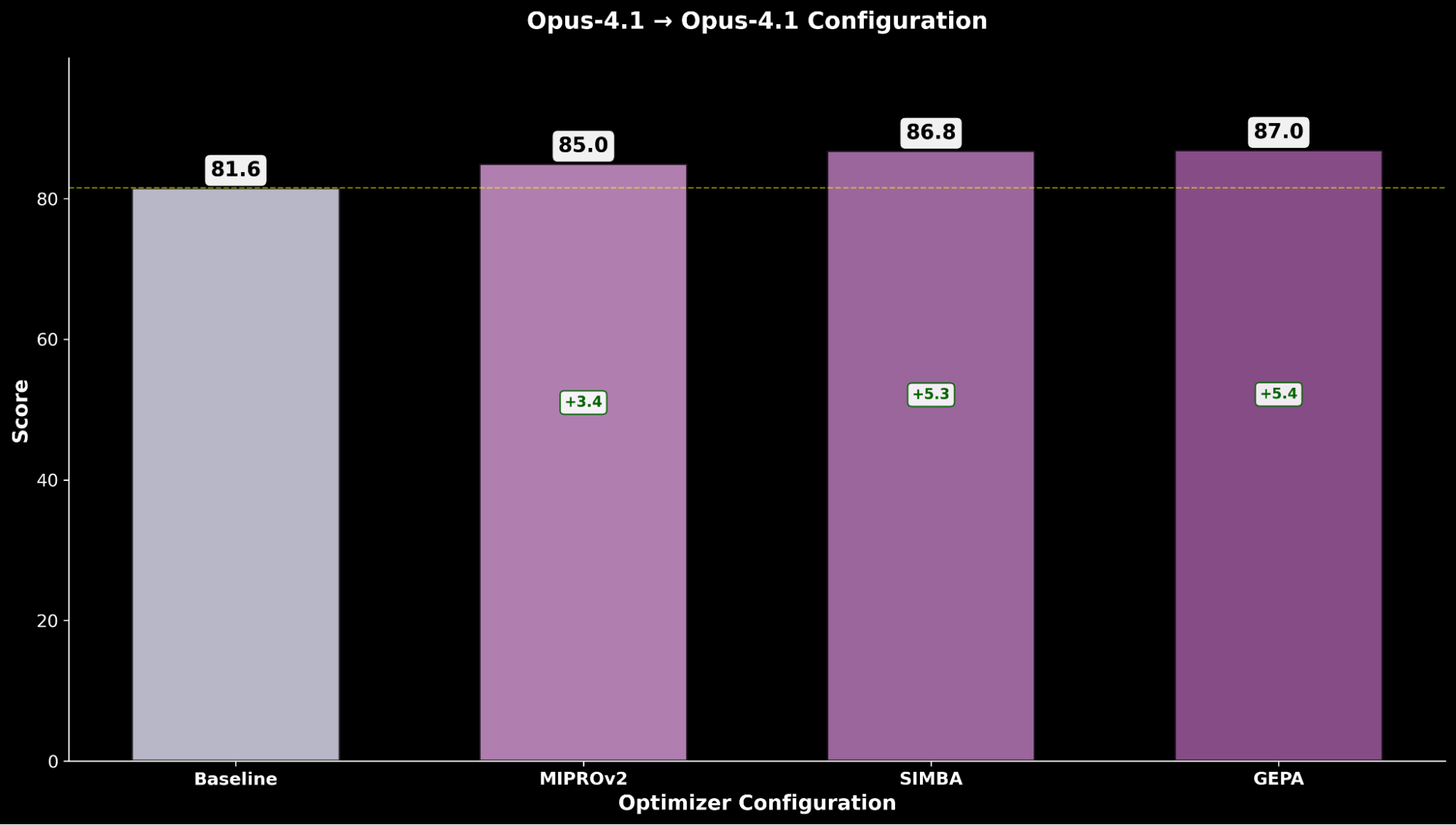
La optimización de Claude Sonnet 4 logra una mejora de +4.8 sobre el rendimiento base, mientras que Claude Opus 4.1 optimizado logra el mejor rendimiento general, con una mejora significativa de +6.4 puntos sobre el rendimiento anterior del estado del arte.
Al agregar los resultados de los experimentos, observamos una tendencia constante de que la optimización automática de prompts ofrece mejoras sustanciales de rendimiento en el rendimiento base de todos los modelos.
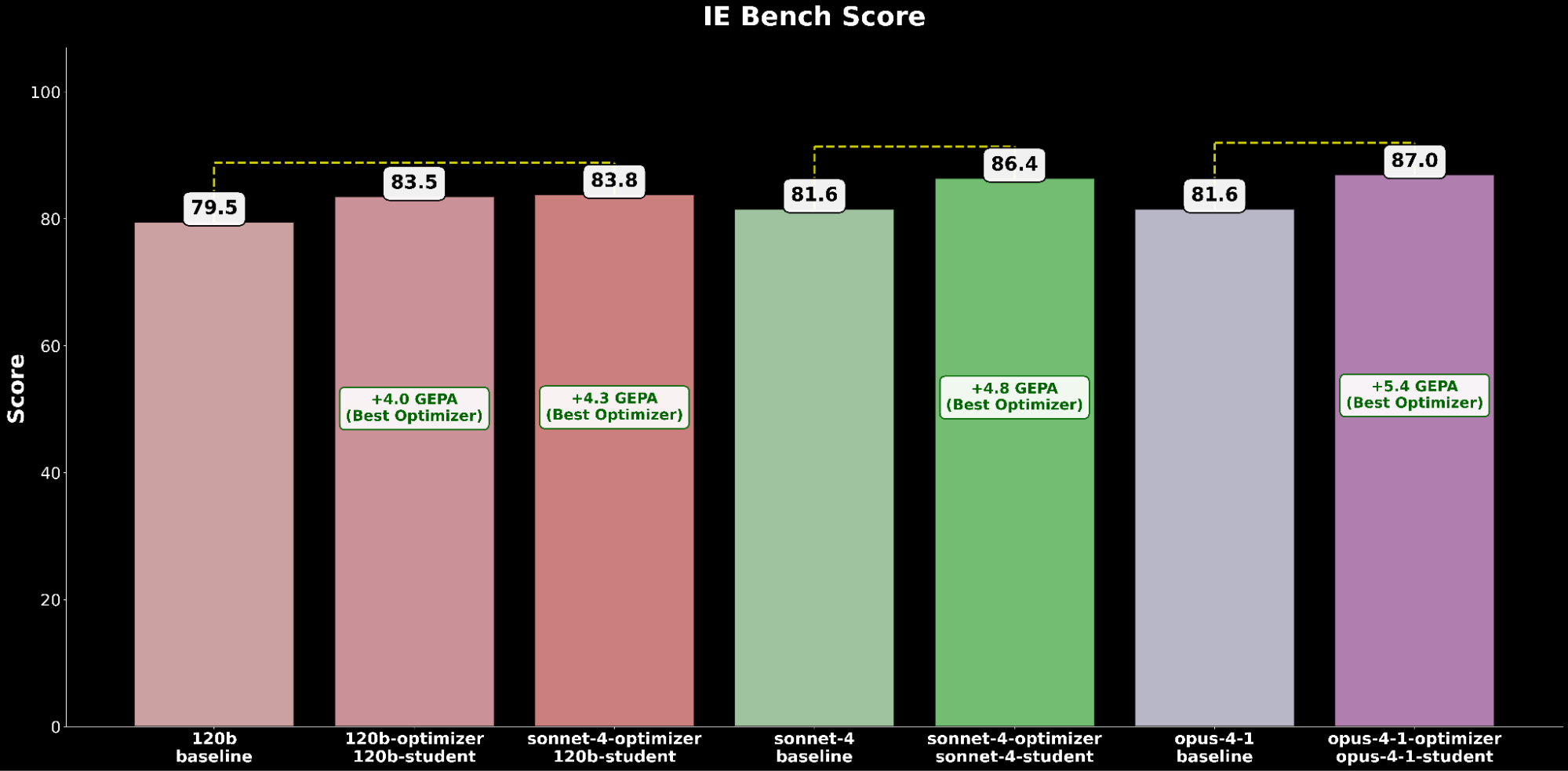
En las evaluaciones de modelos de código abierto y cerrado, encontramos consistentemente que GEPA es el optimizador de mayor rendimiento, seguido por SIMBA y luego MIPRO, lo que desbloquea importantes mejoras de calidad utilizando la optimización automática de prompts.
Sin embargo, al considerar el costo, observamos que GEPA tiene una sobrecarga de tiempo de ejecución relativamente mayor (ya que la exploración de optimización puede requerir del orden de O(3x) más llamadas a LLM (~2-3 horas) que MIPRO y SIMBA (~1 hora))3 durante este análisis empírico de IE Bench. Por lo tanto, tenemos en cuenta la eficiencia de costos y actualizamos nuestra frontera de Pareto de calidad-costo, incluyendo los rendimientos de los modelos optimizados.
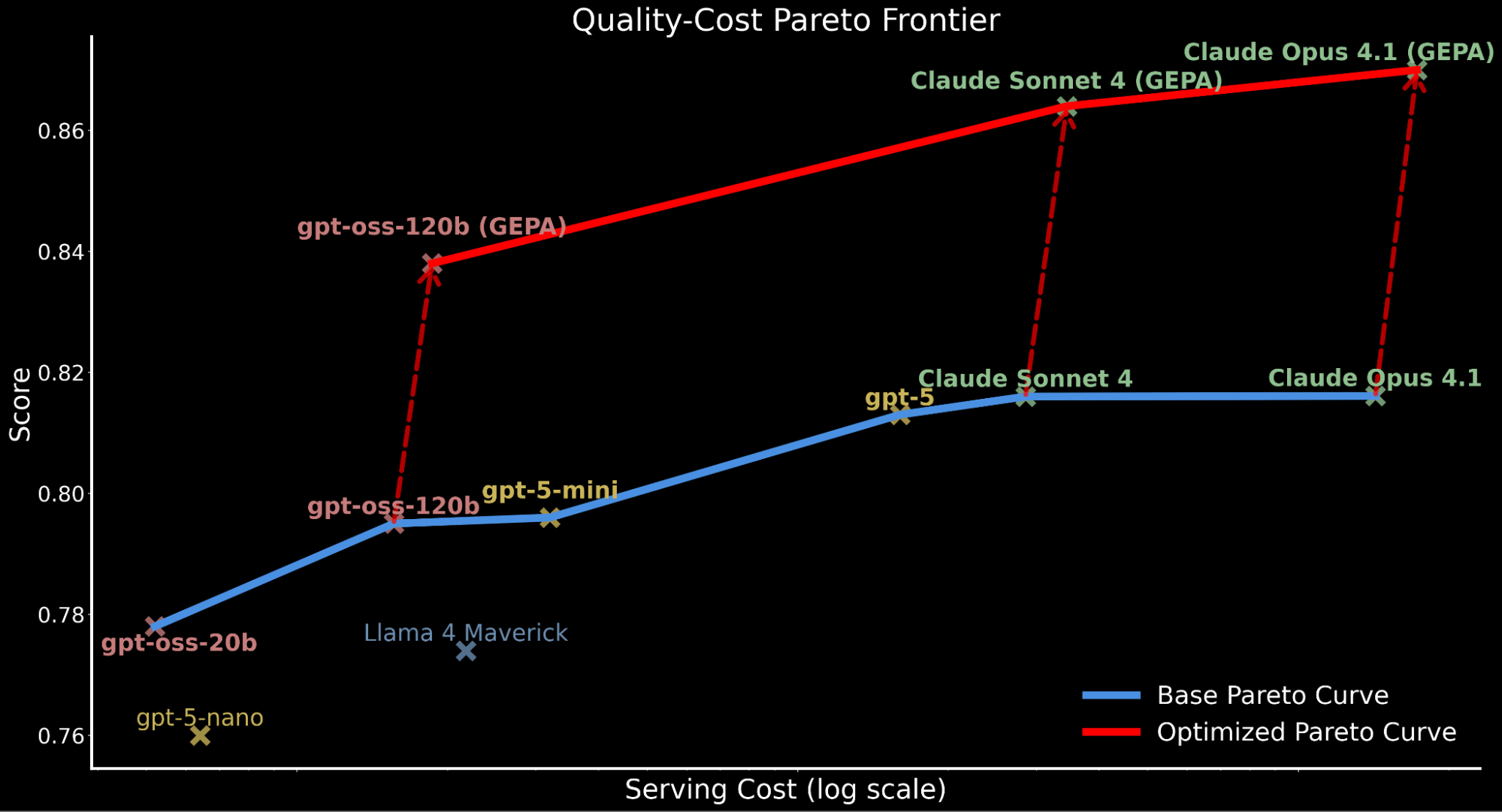
Destacamos cómo la aplicación de la optimización automática de prompts desplaza toda la curva de Pareto hacia arriba, estableciendo una nueva eficiencia de vanguardia:
- gpt-oss-120b optimizado con GEPA supera el rendimiento base de Claude Sonnet 4 y Claude Opus 4.1, siendo 22 veces y 90 veces más barato.
- Para los clientes que priorizan la calidad sobre el costo, Claude Opus 4.1 optimizado con GEPA conduce a un nuevo rendimiento de vanguardia, destacando ganancias significativas para modelos de vanguardia que no se pueden ajustar.
- Atribuimos el aumento del costo total de servicio para los modelos optimizados con GEPA a los prompts más largos y detallados en comparación con el prompt base producido a través de la optimización.
Al aplicar optimizaciones automáticas de prompts a los agentes, mostramos una solución que cumple con los principios fundamentales de Agent Bricks de alto rendimiento y eficiencia de costos.
Comparación con SFT
El ajuste fino supervisado (SFT) a menudo se considera el método predeterminado para mejorar el rendimiento del modelo, pero ¿cómo se compara con la optimización automática de prompts?
Para responder a esto, realizamos un experimento en un subconjunto de IE Bench, eligiendo gpt 4.1 para evaluar el rendimiento de SFT y la optimización automática de prompts (Excluimos gpt-oss y gpt-5 de estas comparaciones ya que los modelos no fueron lanzados en el momento de la evaluación).
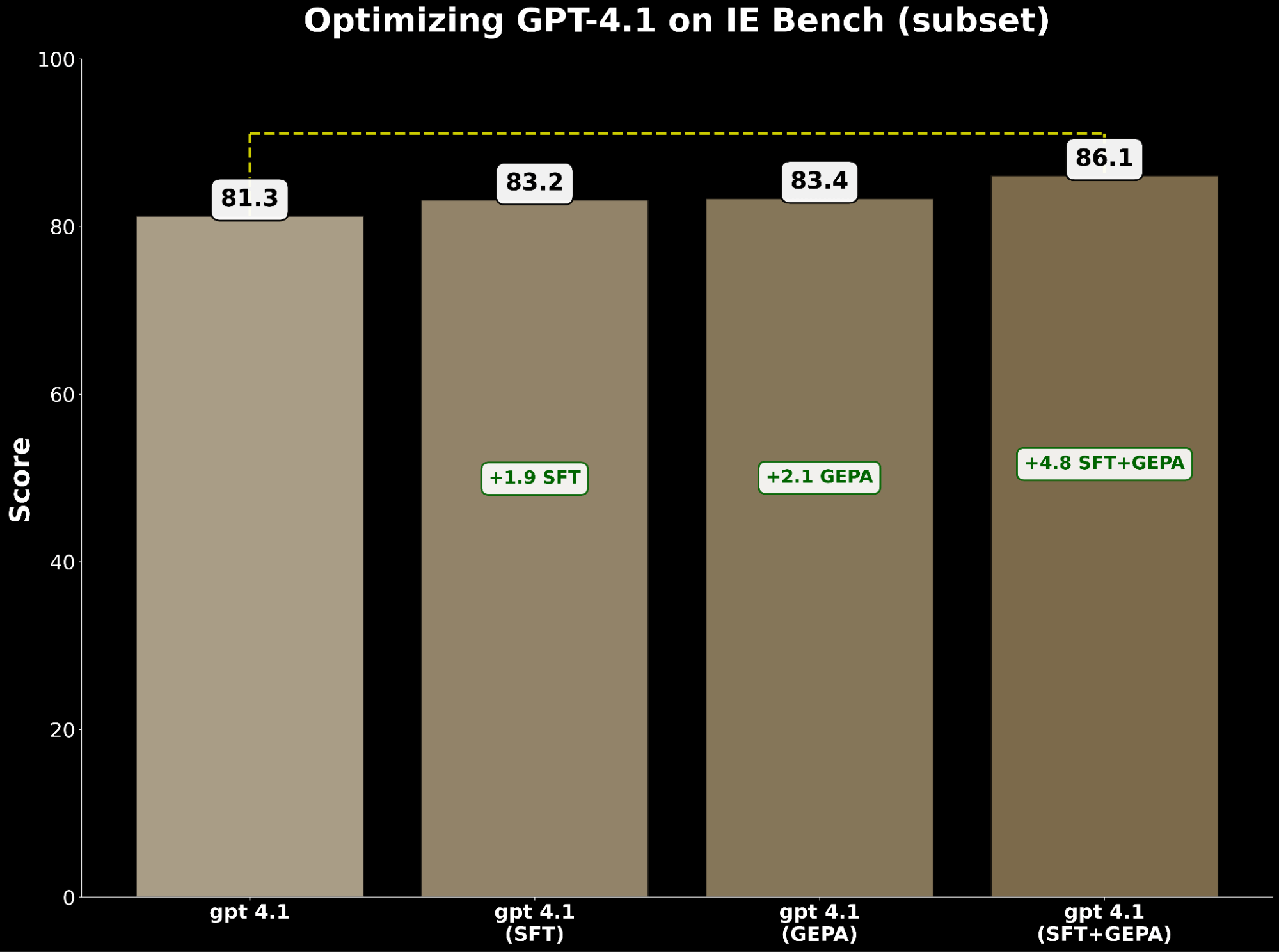
Tanto SFT como la optimización de prompts mejoran gpt-4.1 de forma independiente. Específicamente:
- SFT gpt-4.1 ganó +1.9 puntos sobre la base.
- GEPA optimizado gpt-4.1 ganó +2.1 puntos, superando ligeramente a SFT.
Esto demuestra que la optimización de prompts puede igualar, e incluso superar, las mejoras del ajuste fino supervisado.
Inspirados por BetterTogether, una técnica que considera la optimización alterna de prompts y el ajuste fino de pesos del modelo para mejorar el rendimiento de LLM, aplicamos GEPA sobre SFT y logramos una ganancia de +4.8 puntos sobre la base, lo que resalta el fuerte potencial de combinar estas técnicas.
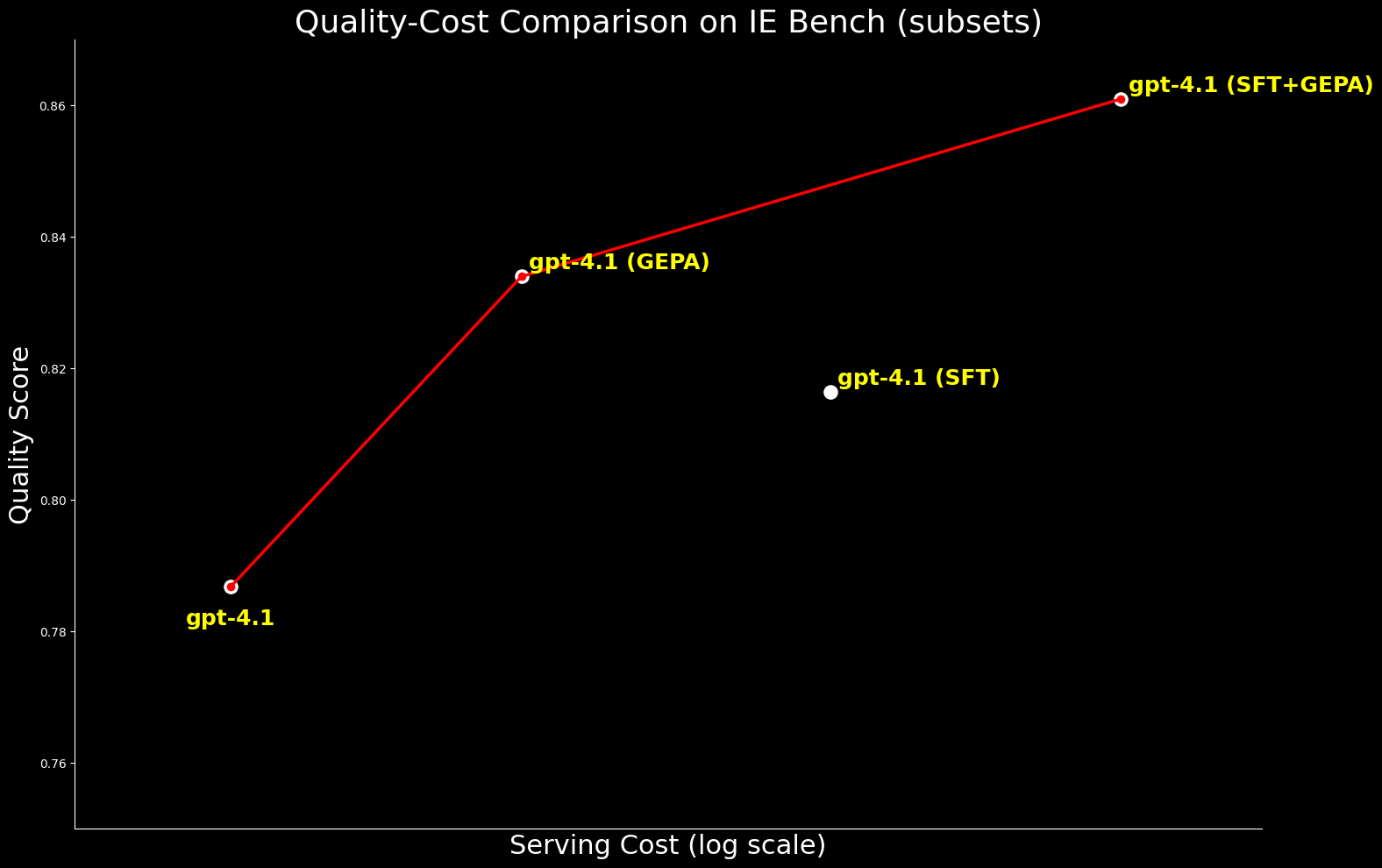
Desde una perspectiva de costos, gpt-4.1 optimizado con GEPA es ~20% más barato de servir que gpt-4.1 optimizado con SFT, al tiempo que ofrece una mejor calidad. Esto resalta que GEPA ofrece un equilibrio premium de calidad-costo sobre SFT. Además, podemos maximizar la calidad absoluta combinando GEPA con SFT, lo que rinde un 2.7% más que SFT solo, pero a un costo de servicio ~22% mayor.4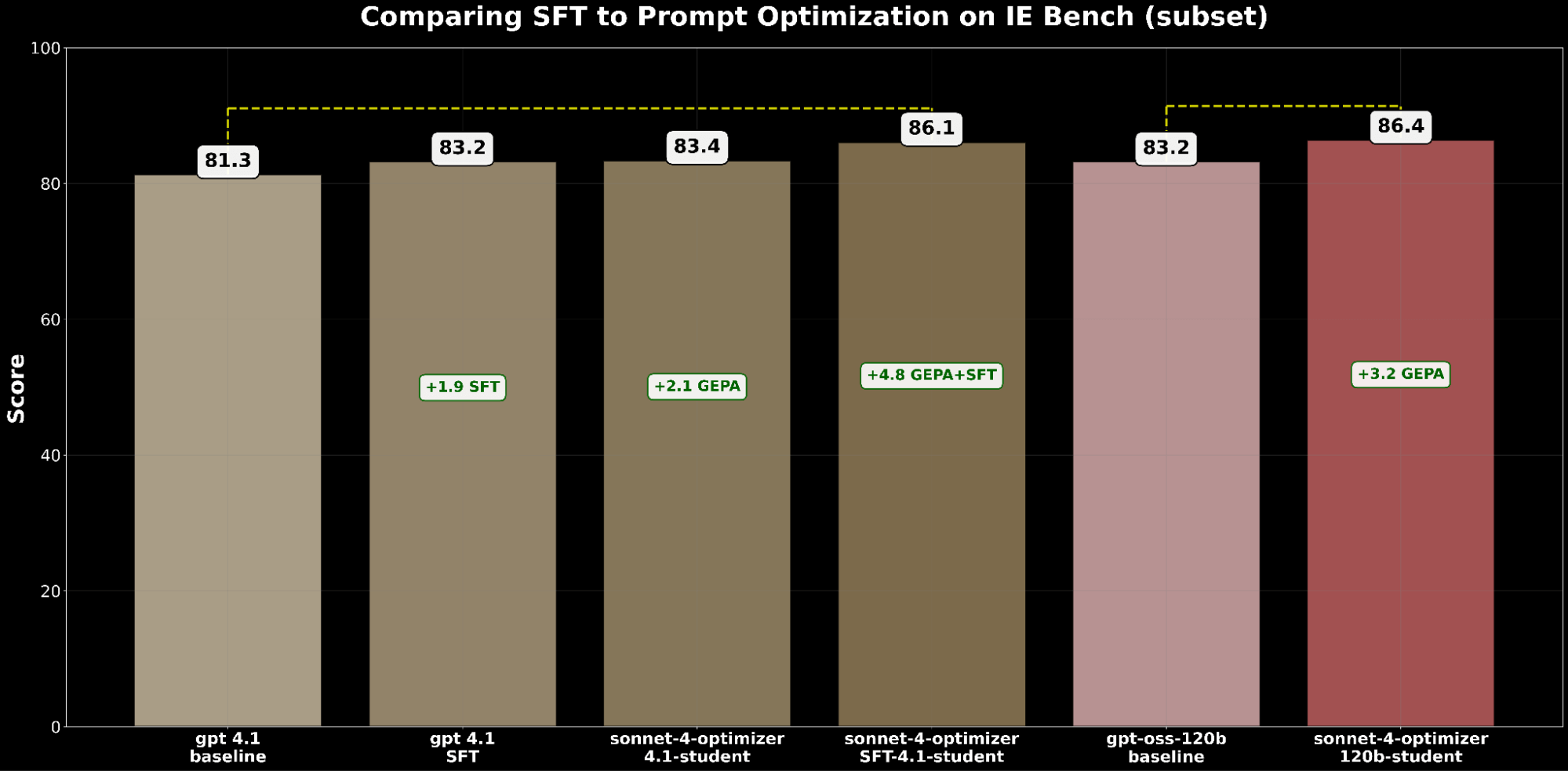
Ampliamos la comparación a gpt-oss-120b para examinar la frontera de calidad-costo. Si bien gpt-4.1 optimizado con SFT+GEPA se acerca —a un 0.3% del rendimiento de gpt-oss-120b optimizado con GEPA—, este último ofrece la misma calidad a un costo de servicio 15 veces menor, lo que lo hace mucho más práctico y atractivo para la implementación a gran escala.

En conjunto, estas comparaciones resaltan las fuertes ganancias de rendimiento habilitadas por la optimización GEPA, ya sea que se use sola o en combinación con SFT. También resaltan la excepcional eficiencia de calidad-costo de gpt-oss-120b cuando se optimiza con GEPA.
Costo de por vida
Para evaluar la optimización en términos del mundo real, consideramos el costo de por vida para los clientes. El objetivo de la optimización no es solo mejorar la precisión, sino también producir un agente eficiente que pueda atender solicitudes en producción. Esto hace que sea esencial observar tanto el costo de optimización como el costo de atender grandes volúmenes de solicitudes.
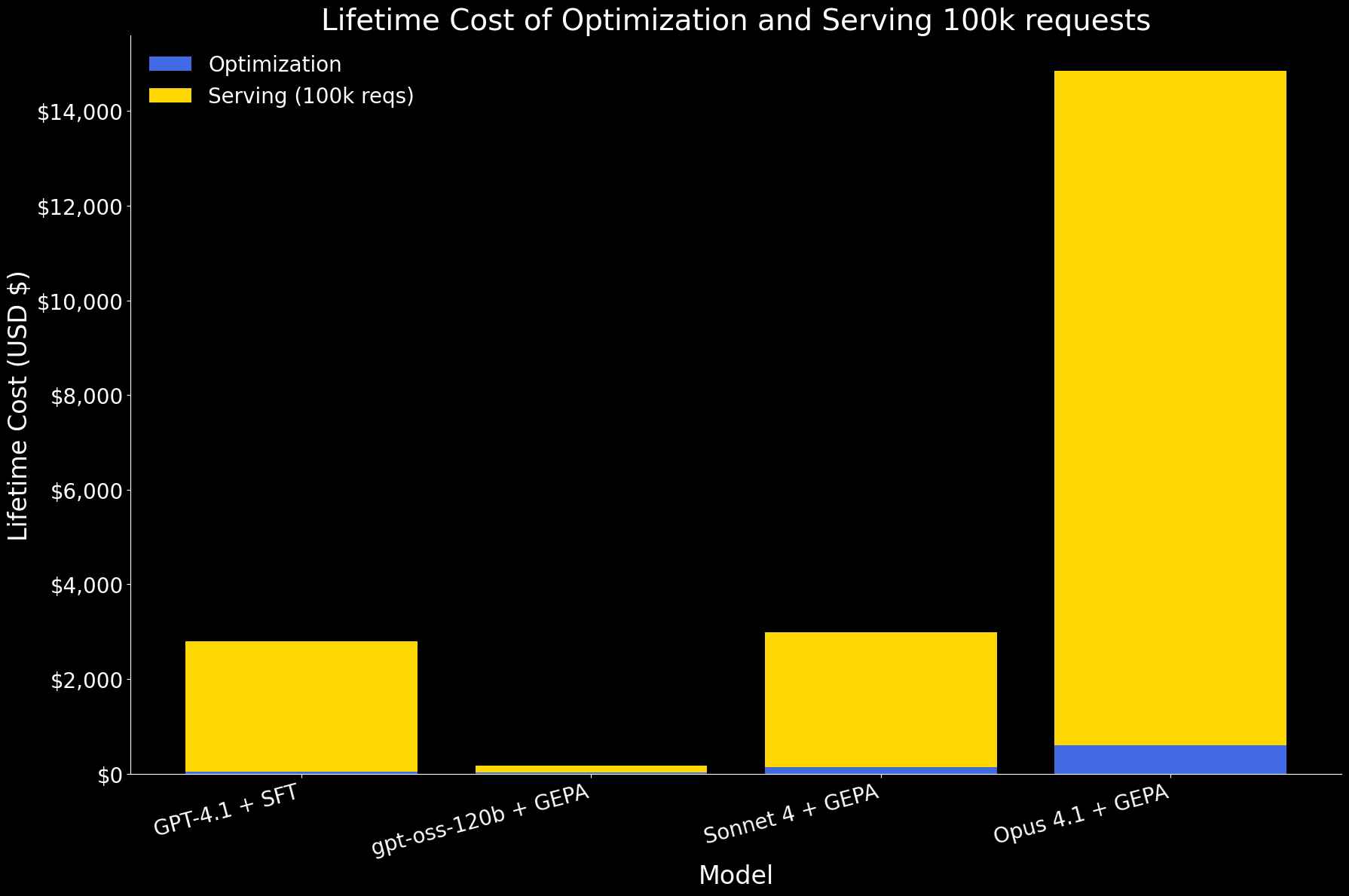
En la primera gráfica a continuación, mostramos el costo de por vida de optimizar un agente y atender 100k solicitudes, desglosado en componentes de optimización y servicio. A esta escala, el servicio domina el costo general. Entre los modelos:
- gpt-oss-120b con GEPA es, con diferencia, el más eficiente, con costos de orden de magnitud inferior tanto para la optimización como para el servicio.
- GPT 4.1 con SFT y Sonnet 4 con GEPA tienen un costo de por vida similar.
- Opus 4.1 con GEPA es el más caro, principalmente debido a su alto precio de servicio.
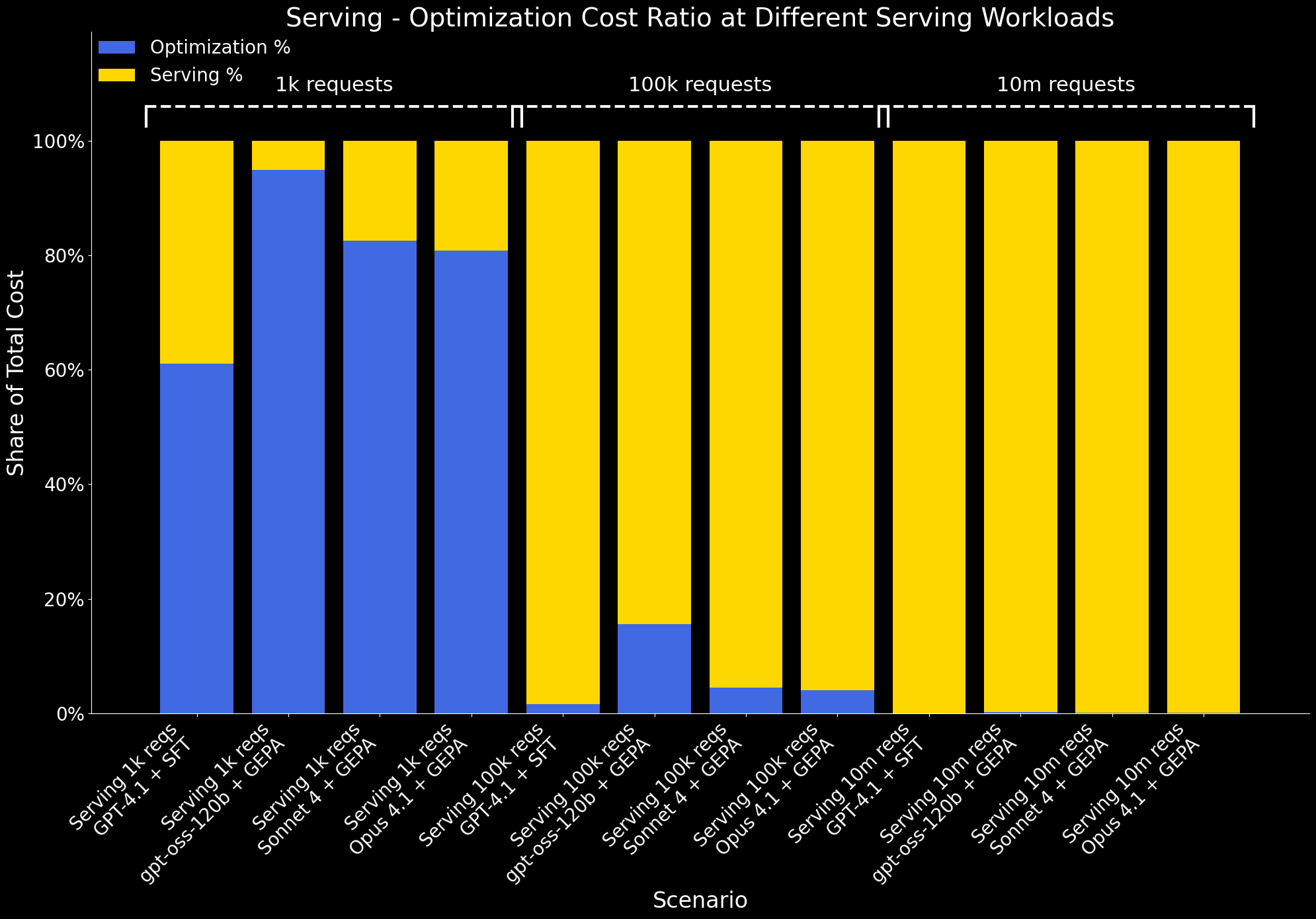
También examinamos cómo cambia la relación entre el costo de optimización y el costo de servicio en diferentes escalas de carga de trabajo:
- En cargas de trabajo de servicio de 1k, los costos de servicio son mínimos, por lo que la optimización representa una gran parte del costo total.
- A las 100k solicitudes, los costos de servicio aumentan significativamente y la sobrecarga de optimización se amortiza. A esta escala, el beneficio de la optimización (mejor rendimiento a menor costo de servicio) supera claramente su costo único.
- A 10M de solicitudes, los costos de optimización se vuelven insignificantes en comparación con los costos de servicio y ya no son visibles en el gráfico.
Resumen
En esta publicación de blog, demostramos que la optimización automática de prompts es una herramienta poderosa para avanzar en el rendimiento de LLM en tareas de IA empresariales:
- Desarrollamos IE Bench, un conjunto de evaluación integral que abarca dominios del mundo real y captura desafíos complejos de extracción de información.
- Al aplicar la optimización automática de prompts GEPA, elevamos el rendimiento del modelo líder de código abierto gpt-oss-120b para superar el rendimiento del modelo propietario de vanguardia Claude Opus 4.1 en ~3%, siendo 90 veces más barato de servir.
- La misma técnica se aplica a modelos propietarios de vanguardia, mejorando Claude Sonnet 4 y Claude Opus 4.1 en un 6-7%.
- En comparación con el Ajuste Fino Supervisado (SFT), la optimización GEPA proporciona una compensación superior de calidad-costo para uso empresarial. Ofrece un rendimiento igual o superior a SFT, al tiempo que reduce los costos de servicio en un 20%.
- El análisis de costo de por vida muestra que al servir a escala (por ejemplo, 100k solicitudes), la sobrecarga de optimización única se amortiza rápidamente y los beneficios superan con creces el costo. En particular, GEPA en gpt-oss-120b ofrece un costo de por vida de orden de magnitud inferior en comparación con otros modelos de vanguardia, lo que lo convierte en una opción muy atractiva para los agentes de IA empresariales.
En conjunto, nuestros resultados muestran que la optimización de prompts desplaza la frontera de Pareto de calidad-costo para los sistemas de IA empresariales, elevando tanto el rendimiento como la eficiencia.
La optimización automatizada de prompts, junto con las previamente publicadas TAO, RLVR y ALHF, ya está disponible en Agent Bricks. El principio fundamental de Agent Bricks es ayudar a las empresas a crear agentes que razonen con precisión sobre sus datos y logren una calidad y eficiencia de costos de vanguardia en tareas específicas del dominio. Al unificar la evaluación, la optimización automatizada y el despliegue gobernado, Agent Bricks permite que sus agentes se adapten a sus datos y tareas, aprendan de la retroalimentación y mejoren continuamente en las tareas específicas de su dominio empresarial. Animamos a los clientes a probar la Extracción de Información y otras capacidades de Agent Bricks para optimizar agentes para sus propios casos de uso empresariales.
1 Para las series de modelos gpt-oss y gpt-5, seguimos las mejores prácticas del formato Harmony de OpenAI que inserta el esquema JSON de destino en el mensaje del desarrollador para generar una salida estructurada.
También ablacionamos los diferentes esfuerzos de razonamiento para la serie gpt-oss (bajo, medio, alto) y la serie gpt-5 (mínimo, bajo, medio, alto), y reportamos el mejor rendimiento de cada modelo en todos los esfuerzos de razonamiento.
2 Para las estimaciones de costos de servicio, utilizamos los precios publicados de las plataformas de los proveedores de modelos (OpenAI y Anthropic para modelos propietarios) y de Artificial Analysis para modelos de código abierto. Los costos se calculan aplicando estos precios a las distribuciones de tokens de entrada y salida observadas en IE Bench, lo que nos da el costo total de servicio para cada modelo.
3 El tiempo de ejecución real de la optimización automatizada de prompts es difícil de estimar, ya que depende de muchos factores. Aquí proporcionamos una estimación aproximada basada en nuestra experiencia empírica.
4 Estimamos el costo de servicio de SFT gpt-4.1 utilizando los precios de modelos fine-tuned publicados por OpenAI. Para los modelos optimizados con GEPA, calculamos el costo de servicio en función del uso de tokens de entrada y salida medido de los prompts optimizados.
Autores: Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng, Simon Favreau-Lessard
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.