TAO: Usando cómputo en tiempo de prueba para entrenar LLMs eficientes sin datos etiquetados
Los modelos de lenguaje grandes son difíciles de adaptar a nuevas tareas empresariales. El prompting es propenso a errores y logra ganancias limitadas en calidad, mientras que el fine-tuning requiere grandes cantidades de datos etiquetados por humanos que no están disponibles para la mayoría de las tareas empresariales. Hoy, presentamos un nuevo método de ajuste de modelos que solo requiere datos de uso no etiquetados, permitiendo a las empresas mejorar la calidad y el costo de la IA utilizando solo los datos que ya tienen. Nuestro método, Test-time Adaptive Optimization (TAO), aprovecha la computación en tiempo de prueba (popularizada por o1 y R1) y el aprendizaje por refuerzo (RL) para enseñar a un modelo a realizar una tarea mejor basándose únicamente en ejemplos de entrada anteriores, lo que significa que escala con un presupuesto de computación de ajuste ajustable, no con el esfuerzo de etiquetado humano. Crucialmente, aunque TAO utiliza computación en tiempo de prueba, la usa como parte del proceso para entrenar un modelo; ese modelo luego ejecuta la tarea directamente con bajos costos de inferencia (es decir, no requiere computación adicional en tiempo de inferencia). Sorprendentemente, incluso sin datos etiquetados, TAO puede lograr una mejor calidad del modelo que el fine-tuning tradicional, y puede acercar modelos de código abierto económicos como Llama a la calidad de modelos propietarios costosos como GPT-4o y o3-mini.
TAO es parte del programa de nuestro equipo de investigación sobre Inteligencia de Datos — el problema de hacer que la IA sobresalga en dominios específicos utilizando los datos que las empresas ya tienen. Con TAO, logramos tres resultados emocionantes:
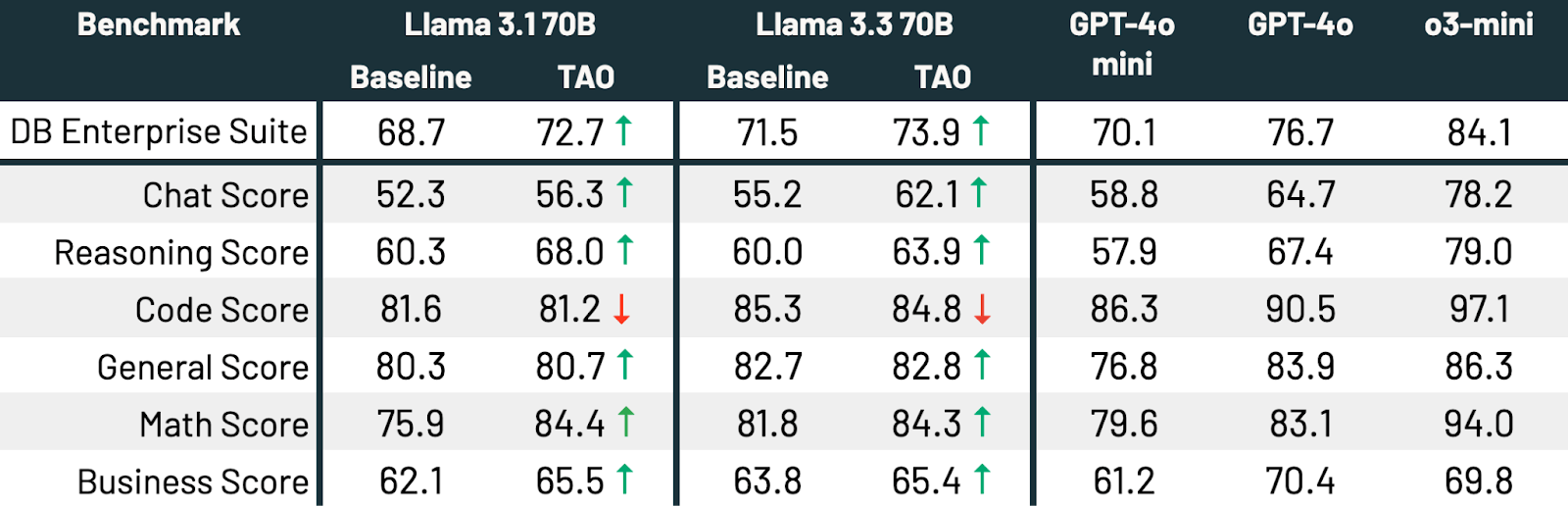
- En tareas empresariales especializadas como la respuesta a preguntas sobre documentos y la generación de SQL, TAO supera al fine-tuning tradicional en miles de ejemplos etiquetados. Acerca modelos eficientes de código abierto como Llama 8B y 70B a una calidad similar a la de modelos costosos como GPT-4o y o3-mini1 sin necesidad de etiquetas.
- También podemos usar TAO multitarefa para mejorar un LLM ampliamente en muchas tareas. Sin usar etiquetas, TAO mejora el rendimiento de Llama 3.3 70B en un 2.4% en un benchmark empresarial amplio.
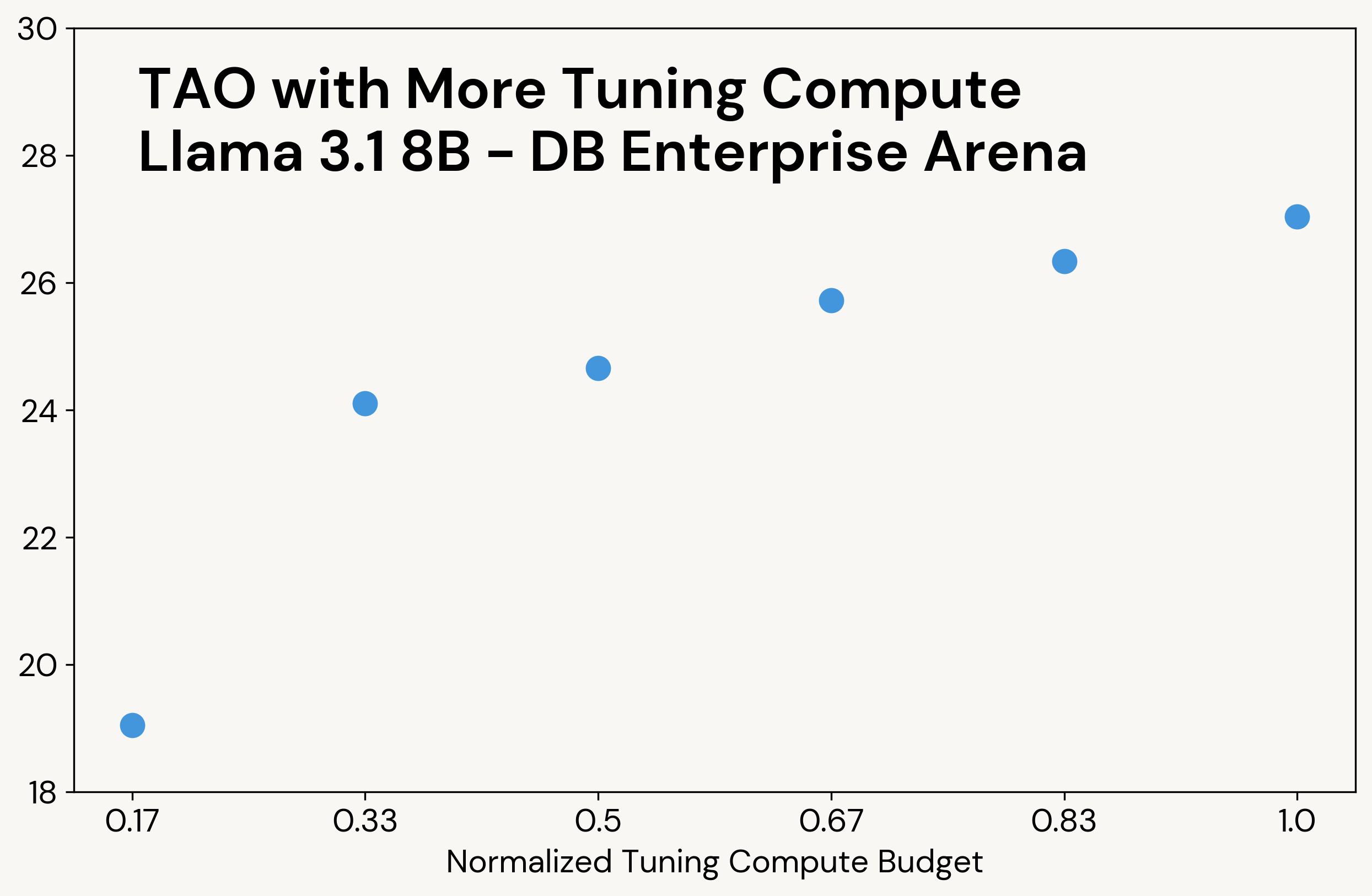
- Aumentar el presupuesto de computación de TAO en tiempo de ajuste produce una mejor calidad del modelo con los mismos datos, mientras que los costos de inferencia del modelo ajustado se mantienen iguales.
La Figura 1 muestra cómo TAO mejora los modelos Llama en tres tareas empresariales: FinanceBench, DB Enterprise Arena y BIRD-SQL (utilizando el dialecto Databricks SQL)². A pesar de tener solo acceso a las entradas de LLM, TAO supera al fine-tuning tradicional (FT) con miles de ejemplos etiquetados y acerca Llama al mismo rango que los modelos propietarios costosos.
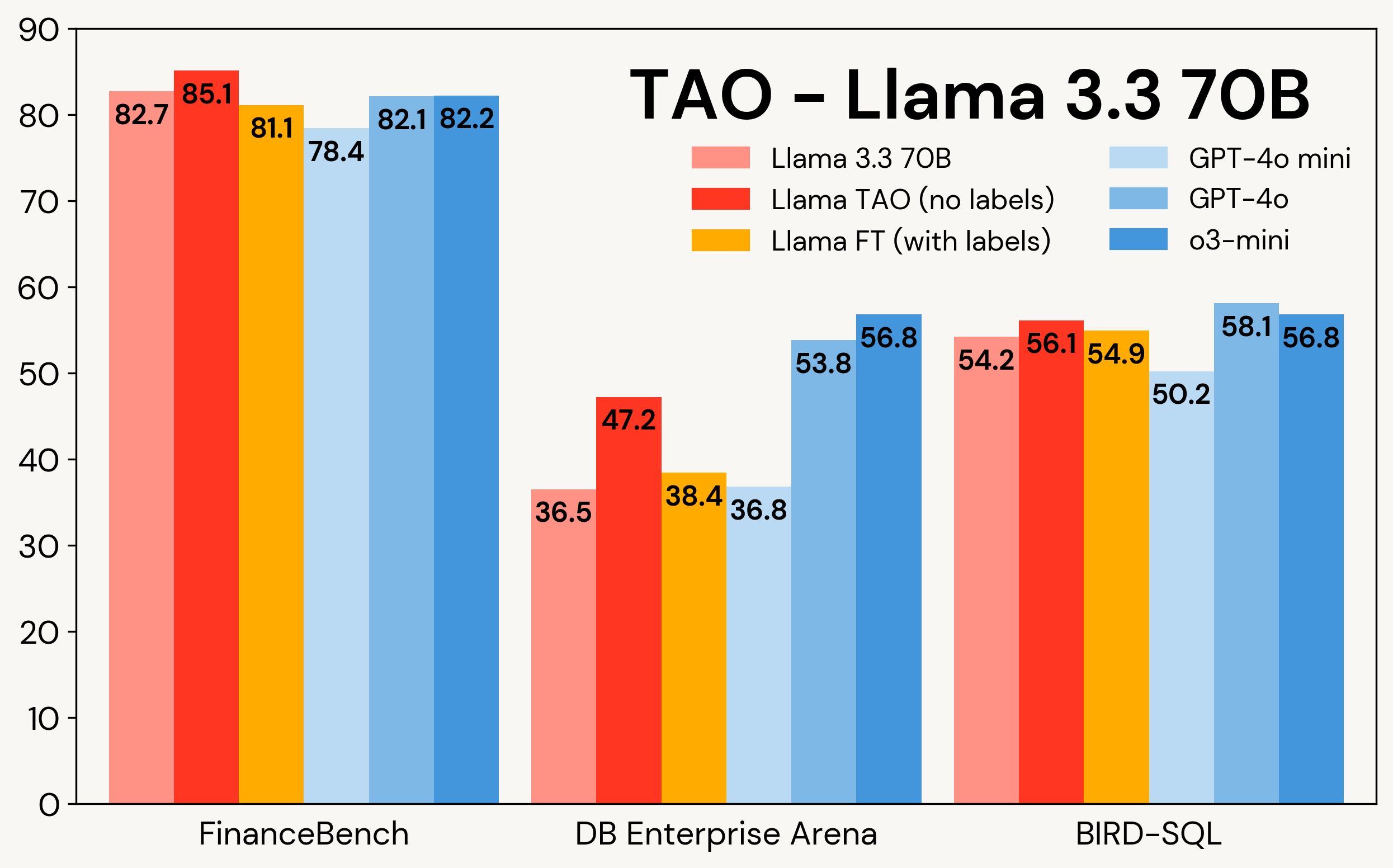
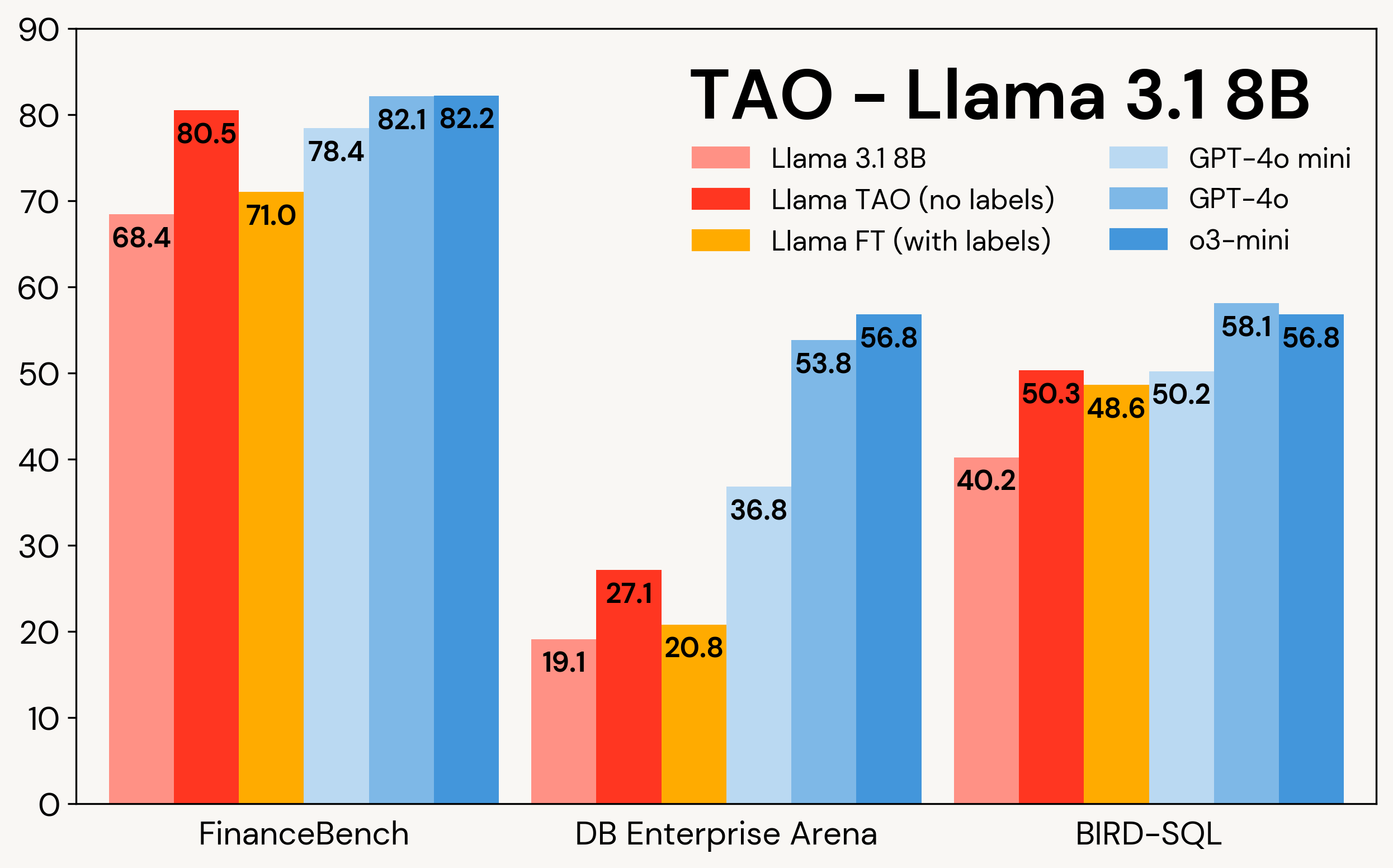
Figura 1: TAO en Llama 3.1 8B y Llama 3.3 70B en tres benchmarks empresariales. TAO conduce a mejoras sustanciales en calidad, superando al fine-tuning y desafiando a los LLMs propietarios costosos.
TAO ya está disponible en vista previa para clientes de Databricks que deseen ajustar Llama, y potenciará varios productos próximos. Complete este formulario para expresar su interés en probarlo en sus tareas como parte de la vista previa privada. En esta publicación, describimos más sobre cómo funciona TAO y nuestros resultados con él.
¿Cómo Funciona TAO? Usando Computación en Tiempo de Prueba y Aprendizaje por Refuerzo para Ajustar Modelos
En lugar de requerir datos de salida anotados por humanos, la idea clave en TAO es usar la computación en tiempo de prueba para que un modelo explore respuestas plausibles para una tarea, y luego usar aprendizaje por refuerzo para actualizar un LLM basándose en la evaluación de estas respuestas. Este pipeline se puede escalar usando computación en tiempo de prueba, en lugar de esfuerzo humano costoso, para aumentar la calidad. Además, se puede personalizar fácilmente utilizando información específica de la tarea (por ejemplo, reglas personalizadas). Sorprendentemente, aplicar esta escala con modelos de código abierto de alta calidad conduce a mejores resultados que las etiquetas humanas en muchos casos.
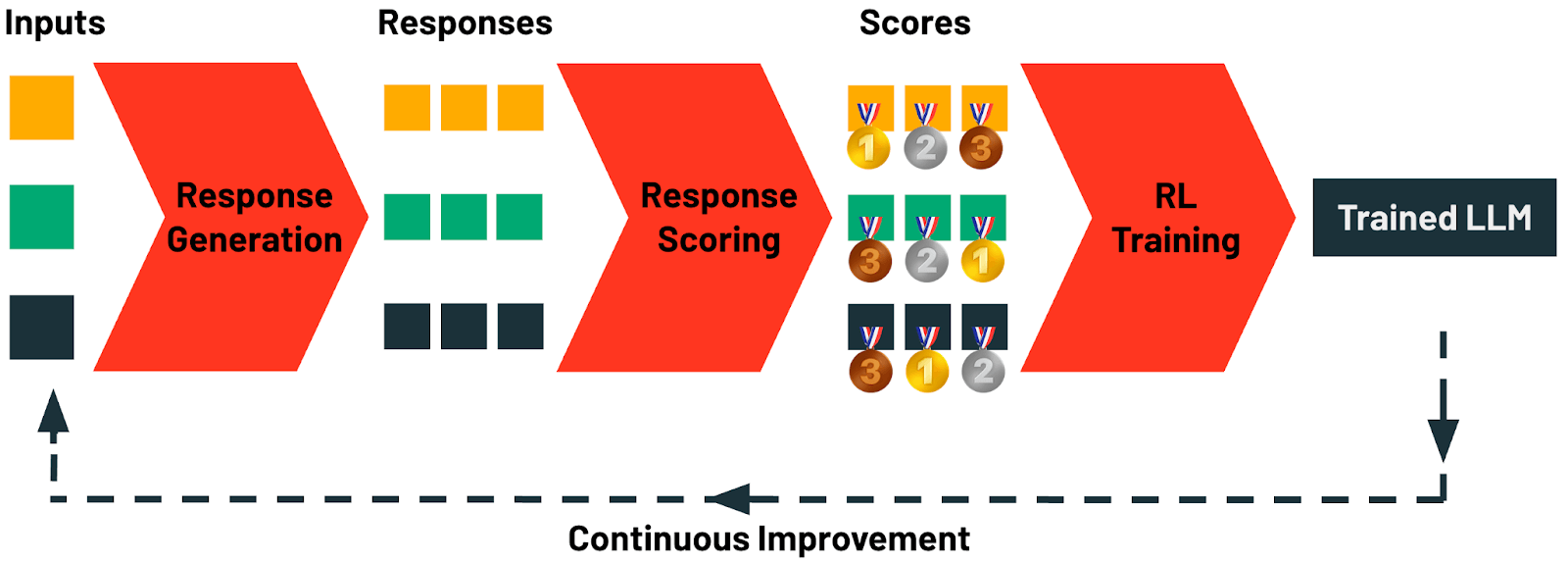
Específicamente, TAO comprende cuatro etapas:
- Generación de Respuestas: Esta etapa comienza con la recopilación de ejemplos de prompts o consultas de entrada para una tarea. En Databricks, estos prompts se pueden recopilar automáticamente de cualquier aplicación de IA utilizando nuestra Puerta de Enlace de IA. Cada prompt se utiliza luego para generar un conjunto diverso de respuestas candidatas. Se puede aplicar un rico espectro de estrategias de generación aquí, que van desde el prompting simple de cadena de pensamiento hasta técnicas sofisticadas de razonamiento y prompting estructurado.
- Puntuación de Respuestas: En esta etapa, las respuestas generadas se evalúan sistemáticamente. Las metodologías de puntuación incluyen una variedad de estrategias, como modelado de recompensas, puntuación basada en preferencias o verificación específica de la tarea utilizando jueces LLM o reglas personalizadas. Esta etapa asegura que cada respuesta generada se evalúe cuantitativamente en cuanto a calidad y alineación con los criterios.
- Entrenamiento de Aprendizaje por Refuerzo (RL): En la etapa final, se aplica un enfoque basado en RL para actualizar el LLM, guiando al modelo a producir salidas estrechamente alineadas con las respuestas de alta puntuación identificadas en el paso anterior. A través de este proceso de aprendizaje adaptativo, el modelo refina sus predicciones para mejorar la calidad.
- Mejora Continua: Los únicos datos que TAO necesita son ejemplos de entradas de LLM. Los usuarios crean naturalmente estos datos interactuando con un LLM. Tan pronto como su LLM se implementa, comienza a generar datos de entrenamiento para la próxima ronda de TAO. En Databricks, su LLM puede mejorar cuanto más lo use, gracias a TAO.
Crucialmente, aunque TAO utiliza computación en tiempo de prueba, la usa para entrenar un modelo que luego ejecuta una tarea directamente con bajos costos de inferencia. Esto significa que los modelos producidos por TAO tienen el mismo costo y velocidad de inferencia que el modelo original, significativamente menos que los modelos de tiempo de prueba como o1, o3 y R1. Como muestran nuestros resultados, los modelos eficientes de código abierto entrenados con TAO pueden desafiar a los modelos propietarios líderes en calidad.
TAO proporciona un nuevo y potente método en el conjunto de herramientas para ajustar modelos de IA. A diferencia de la ingeniería de prompts, que es lenta y propensa a errores, y del fine-tuning, que requiere producir etiquetas humanas costosas y de alta calidad, TAO permite a los ingenieros de IA lograr grandes resultados simplemente proporcionando ejemplos de entrada representativos de su tarea.
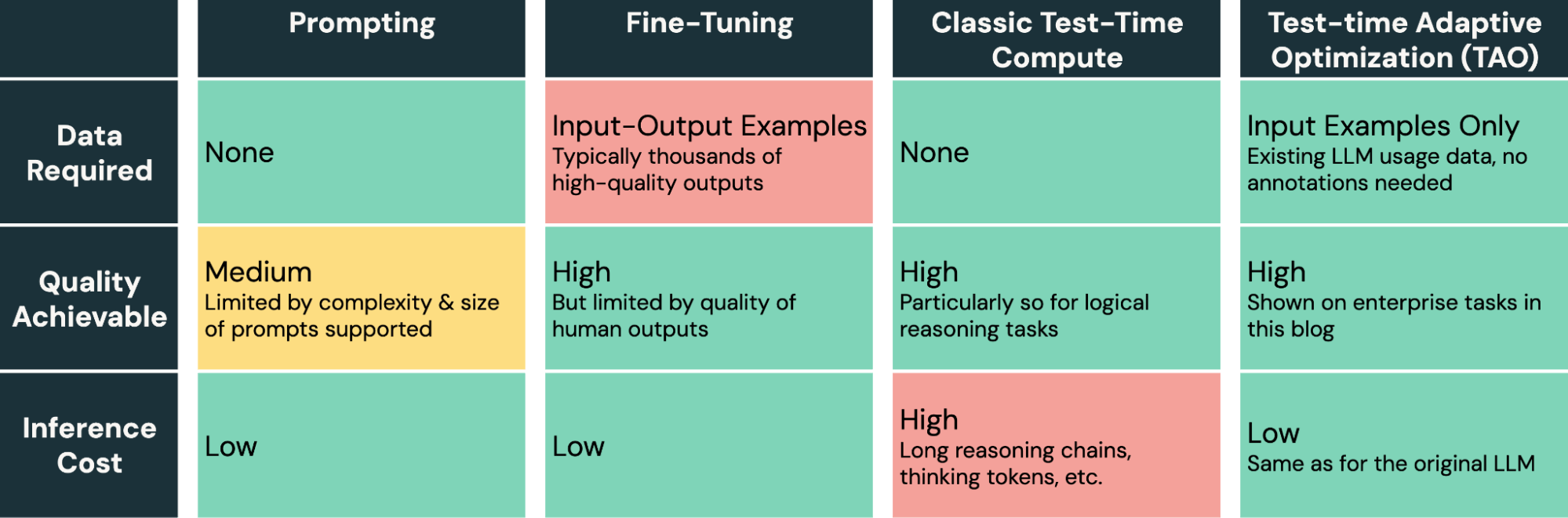
TAO es un método altamente flexible que se puede personalizar si es necesario, pero nuestra implementación predeterminada en Databricks funciona bien lista para usar en diversas tareas empresariales. En el núcleo de nuestra implementación se encuentran nuevas técnicas de aprendizaje por refuerzo y modelado de recompensas que nuestro equipo desarrolló y que permiten a TAO aprender mediante la exploración y luego ajustar el modelo subyacente utilizando RL. Por ejemplo, uno de los ingredientes que potencian TAO es un modelo de recompensa personalizado que entrenamos para tareas empresariales, DBRM, que puede producir señales de puntuación precisas en una amplia gama de tareas.
Mejorando el Rendimiento de Tareas con TAO
En esta sección, profundizamos en cómo utilizamos TAO para ajustar LLMs en tareas empresariales especializadas. Seleccionamos tres benchmarks representativos, incluyendo benchmarks populares de código abierto y otros internos que desarrollamos como parte de nuestro Conjunto de Benchmarks de Inteligencia de Dominio (DIBS).

Para cada tarea, evaluamos varios enfoques:
- Usar un modelo Llama de código abierto (Llama 3.1-8B o Llama 3.3-70B) tal cual.
- Fine-tuning en Llama. Para hacer esto, utilizamos o creamos grandes conjuntos de datos realistas de entrada-salida con miles de ejemplos, que es lo que generalmente se requiere para lograr un buen rendimiento con el fine-tuning. Estos incluyeron:
- 7200 preguntas sintéticas sobre documentos de la SEC para FinanceBench.
- 4800 entradas escritas por humanos para DB Enterprise Arena.
- 8137 ejemplos del conjunto de entrenamiento de BIRD-SQL, modificados para coincidir con el dialecto Databricks SQL.
- TAO en Llama, utilizando solo los ejemplos de entrada de nuestros conjuntos de datos de fine-tuning, pero no las salidas, y utilizando nuestro modelo de recompensa enfocado en empresas DBRM. DBRM en sí mismo no está entrenado en estos benchmarks.
- LLMs propietarios de alta calidad – GPT 4o-mini, GPT 4o y o3-mini.
Como se muestra en la Tabla 3, en los tres benchmarks y en ambos modelos Llama, TAO mejora significativamente el rendimiento base de Llama, incluso más allá del ajuste fino.

Al igual que la computación clásica en tiempo de inferencia, TAO produce resultados de mayor calidad cuando se le da acceso a más recursos de cómputo (ver Figura 3 para un ejemplo). Sin embargo, a diferencia de la computación en tiempo de inferencia, este cómputo adicional solo se utiliza durante la fase de ajuste; el LLM final tiene el mismo costo de inferencia que el LLM original. Por ejemplo, o3-mini produce entre 5 y 10 veces más tokens de salida que los otros modelos en nuestras tareas, lo que resulta en un costo de inferencia proporcionalmente mayor, mientras que TAO tiene el mismo costo de inferencia que el modelo Llama original.
Mejorando la Inteligencia Multitarea con TAO
Hasta ahora, hemos utilizado TAO para mejorar LLMs en tareas individuales y específicas, como la generación de SQL. Sin embargo, a medida que los agentes se vuelven más complejos, las empresas necesitan cada vez más LLMs que puedan realizar más de una tarea. En esta sección, mostramos cómo TAO puede mejorar ampliamente el rendimiento del modelo en una variedad de tareas empresariales.
En este experimento, recopilamos 175.000 prompts que reflejan un conjunto diverso de tareas empresariales, incluyendo codificación, matemáticas, respuesta a preguntas, comprensión de documentos y chat. Luego ejecutamos TAO en Llama 3.1 70B y Llama 3.3 70B. Finalmente, probamos un conjunto de tareas relevantes para empresas, que incluye benchmarks populares de LLM (por ejemplo, Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) y benchmarks internos en múltiples áreas relevantes para las empresas.
TAO mejora significativamente el rendimiento de ambos modelos[t][u]. Llama 3.3 70B y Llama 3.1 70B mejoran en 2.4 y 4.0 puntos porcentuales, respectivamente. TAO acerca significativamente Llama 3.3 70B a GPT-4o en tareas empresariales[v][w]. Todo esto se logra sin costo de etiquetado humano, solo con datos representativos de uso de LLM y nuestra implementación de producción de TAO. La calidad mejora en todos los subpuntajes, excepto en codificaci�ón, donde el rendimiento es estático.
Usando TAO en la Práctica
TAO es un potente método de ajuste que funciona sorprendentemente bien en muchas tareas al aprovechar la computación en tiempo de inferencia. Para usarlo con éxito en tus propias tareas, necesitarás:
- Suficientes entradas de ejemplo para tu tarea (varios miles), recopiladas de una aplicación de IA implementada (por ejemplo, preguntas enviadas a un agente) o generadas sintéticamente.
- Un método de puntuación suficientemente preciso: para los clientes de Databricks, una herramienta potente aquí es nuestro modelo de recompensa personalizado, DBRM, que potencia nuestra implementación de TAO, pero puedes aumentar DBRM con reglas de puntuación personalizadas o verificadores si son aplicables a tu tarea.
Una buena práctica que habilitará TAO y otros métodos de mejora de modelos es crear un ciclo de datos para tus aplicaciones de IA. Tan pronto como implementes una aplicación de IA, puedes recopilar entradas, salidas del modelo y otros eventos a través de servicios como Databricks Inference Tables. Luego puedes usar solo las entradas para ejecutar TAO. Cuantas más personas usen tu aplicación, más datos tendrás para ajustarla, y, gracias a TAO, mejor será tu LLM.
Conclusión y Primeros Pasos en Databricks
En este blog, presentamos Test-time Adaptive Optimization (TAO), una nueva técnica de ajuste de modelos que logra resultados de alta calidad sin necesidad de datos etiquetados. Desarrollamos TAO para abordar un desafío clave que vimos que enfrentaban los clientes empresariales: carecían de los datos etiquetados necesarios para el ajuste fino estándar. TAO utiliza la computación en tiempo de inferencia y el aprendizaje por refuerzo para mejorar modelos utilizando datos que las empresas ya tienen, como ejemplos de entrada, lo que facilita la mejora de la calidad de cualquier aplicación de IA implementada y la reducción de costos mediante el uso de modelos más pequeños. TAO es un método altamente flexible que demuestra el poder de la computación en tiempo de inferencia para el desarrollo especializado de IA, y creemos que brindará a los desarrolladores una herramienta nueva, potente y simple para usar junto con el prompting y el ajuste fino.
Los clientes de Databricks ya están utilizando TAO en Llama en vista previa privada. Completa este formulario para expresar tu interés en probarlo en tus tareas como parte de la vista previa privada. TAO también se está incorporando en muchas de nuestras próximas actualizaciones y lanzamientos de productos de IA. ¡Mantente atento!
¹ Autores: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² Usamos o3-mini-medium en todo este blog.
³ Este es el benchmark BIRD-SQL modificado para el dialecto y los productos SQL de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.