El poder de RLVR: Entrenamiento de un modelo líder de razonamiento SQL en Databricks
Una receta simple para el razonamiento empresarial
Actualización: Puede leer más sobre nuestros resultados en nuestro nuevo informe técnico disponible aquí en arXiv.
Actualización (12 de agosto de 2025): Nuestro modelo entrenado con RLVR ahora logra el máximo rendimiento en Bird Bench en la categoría general de modelo único cuando se combina con autoconsistencia. Superamos los resultados de modelo único tanto con como sin autoconsistencia (se permiten múltiples llamadas a LLM). A continuación, discutimos cómo habíamos logrado el mejor modelo en la categoría de modelo único con una sola llamada a LLM (es decir, sin autoconsistencia). Esto demuestra que el poder del entrenamiento RLVR y el uso de estrategias de cómputo en tiempo de prueba, como la autoconsistencia, se pueden combinar de manera eficiente. Tanto best-of-n como RLVR se están implementando para nuestros clientes en Agent Bricks.
En Databricks, utilizamos aprendizaje por refuerzo (RL) para desarrollar modelos de razonamiento para los problemas que enfrentan nuestros clientes, así como para nuestros productos, como el Databricks Assistant y el AI/BI Genie. Estas tareas incluyen la generación de código, el análisis de datos, la integración de conocimiento organizacional, la evaluación específica del dominio y la extracción de información (IE) de documentos. Tareas como la codificación o la extracción de información a menudo tienen recompensas verificables: la corrección se puede verificar directamente (por ejemplo, pasando pruebas, coincidiendo con etiquetas). Esto permite el aprendizaje por refuerzo sin un modelo de recompensa aprendido, conocido como RLVR (aprendizaje por refuerzo con recompensas verificables). En otros dominios, puede ser necesario un modelo de recompensa personalizado, que Databricks también admite. En esta publicación, nos centramos en el entorno RLVR.
Como ejemplo del poder de RLVR, aplicamos nuestra pila de entrenamiento a un benchmark académico popular en ciencia de datos llamado BIRD. Este benchmark estudia la tarea de transformar una consulta en lenguaje natural a un código SQL que se ejecuta en una base de datos. Este es un problema importante para los usuarios de Databricks, ya que permite a los expertos no SQL hablar con sus datos. También es una tarea desafiante donde incluso los mejores LLM propietarios no funcionan bien de inmediato. Si bien BIRD no captura completamente la complejidad del mundo real de esta tarea ni la amplitud completa de productos como Databricks AI/BI Genie (Figura 1), su popularidad nos permite medir la eficacia de RLVR para la ciencia de datos en un benchmark bien entendido.
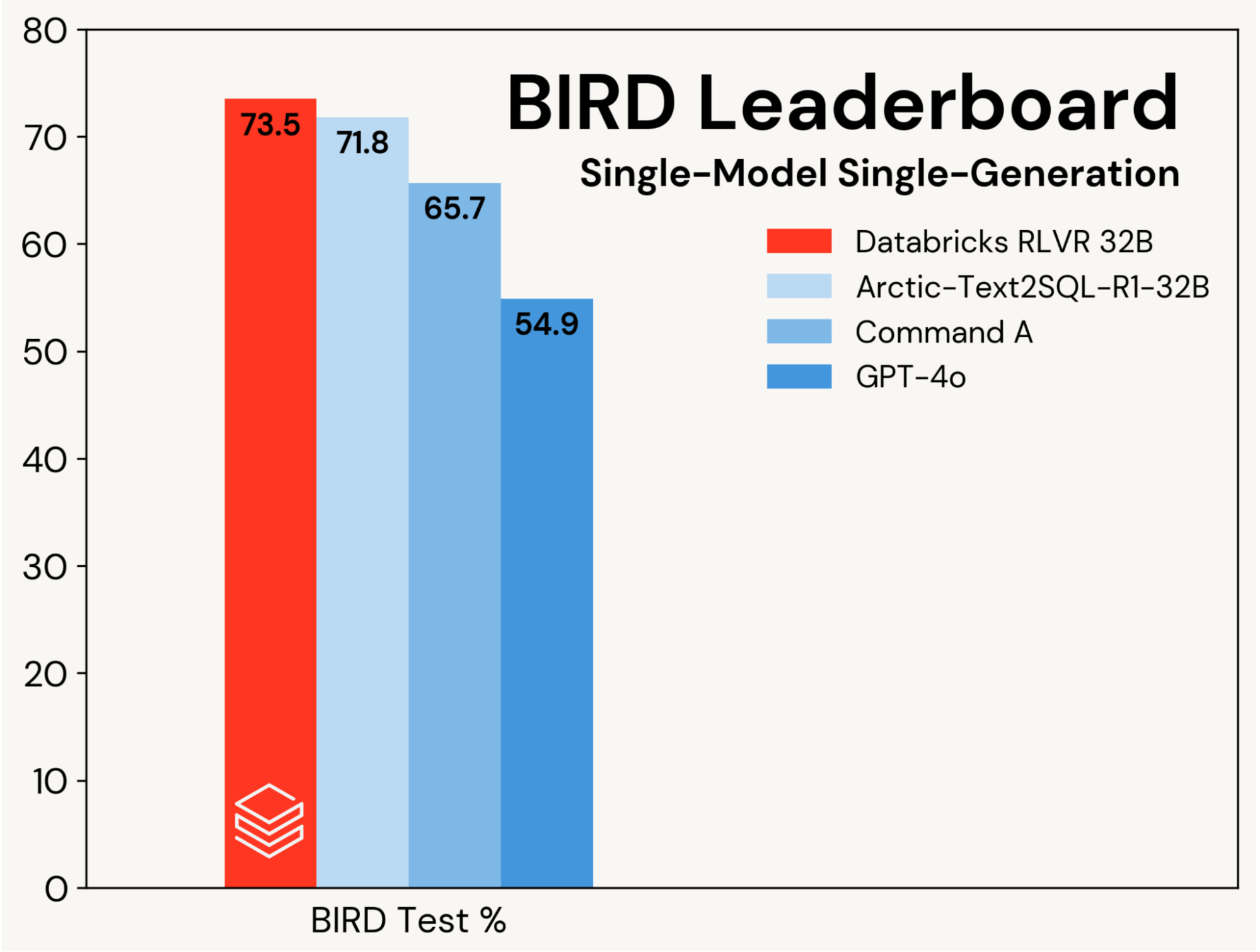
Nos centramos en mejorar un modelo base de codificación SQL utilizando RLVR, aislando estas ganancias de las mejoras impulsadas por diseños de agentes. El progreso se mide en la pista de generación única de modelo único del leaderboard de BIRD (es decir, sin autoconsistencia), que evalúa en un conjunto de prueba privado.
Establecimos una nueva precisión de prueba de vanguardia del 73.5% en este benchmark. Lo hicimos utilizando nuestra pila RLVR estándar y entrenando solo en el conjunto de entrenamiento de BIRD. La mejor puntuación anterior en esta pista fue del 71.8%[1], lograda al aumentar el conjunto de entrenamiento de BIRD con datos adicionales y utilizando un LLM propietario (GPT-4o). Nuestra puntuación es sustancialmente mejor que la del modelo base original y los LLM propietarios (ver Figura 2). Este resultado muestra la simplicidad y generalidad de RLVR: alcanzamos esta puntuación con datos listos para usar y los componentes RL estándar que estamos implementando en Agent Bricks, y lo hicimos en nuestra primera presentación a BIRD. RLVR es una línea base potente que los desarrolladores de IA deberían considerar siempre que haya suficientes datos de entrenamiento disponibles.
Construimos nuestra presentación basándonos en el conjunto de desarrollo de BIRD. Descubrimos que Qwen 2.5 32B Coder Instruct era el mejor punto de partida. Ajustamos este modelo utilizando tanto Databricks TAO – un método de RL offline, como nuestra pila RLVR. Este enfoque, junto con una cuidadosa selección de prompts y modelos, fue suficiente para llevarnos a la cima del Benchmark BIRD. Este resultado es una demostración pública de las mismas técnicas que estamos utilizando para mejorar productos populares de Databricks como AI/BI Genie y Assistant y para ayudar a nuestros clientes a crear agentes utilizando Agent Bricks.
Nuestros resultados resaltan el poder de RLVR y la eficacia de nuestra pila de entrenamiento. Los clientes de Databricks también han reportado grandes resultados utilizando nuestra pila en sus dominios de razonamiento. Creemos que esta receta es potente, componible y ampliamente aplicable a una variedad de tareas. Si desea obtener una vista previa de RLVR en Databricks, contáctenos aquí.
1Ver Tabla 1 en https://arxiv.org/pdf/2505.20315
Autores: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.