The Power of RLVR: Training a Leading SQL Reasoning Model on Databricks
A simple recipe for enterprise reasoning
Update: You can read more about our results in our new tech report available here on arXiv.
Update (Aug 12-2025): Our model trained with RLVR now achieves the top performance on Bird Bench in the overall single-model category when combined with self-consistency! We outperform single-model results both with and without self-consistency (multiple LLM calls allowed). Below we had discussed how we had achieved the best model in single-model single LLM-call category (i.e., no self-consistency). This shows that the power of RLVR training and the use of test-time computation strategies such as self-consistency can be neatly combined. Both best-of-n and RLVR are rolling out to our customers in Agent Bricks.
At Databricks, we use reinforcement learning (RL) to develop reasoning models for problems that our customers face as well as for our products, such as the Databricks Assistant and AI/BI Genie. These tasks include generating code, analyzing data, integrating organizational knowledge, domain-specific evaluation, and information extraction (IE) from documents. Tasks like coding or information extraction often have verifiable rewards -- correctness can be checked directly (e.g., passing tests, matching labels). This allows for reinforcement learning without a learned reward model, known as RLVR (reinforcement learning with verifiable rewards). In other domains, a custom reward model may be required -- which Databricks also supports. In this post, we focus on the RLVR setting.
As an example of the power of RLVR, we applied our training stack to a popular academic benchmark in data science called BIRD. This benchmark studies the task of transforming a natural language query to a SQL code that runs on a database. This is an important problem for Databricks users, enabling non-SQL experts to talk to their data. It is also a challenging task where even the best proprietary LLMs do not work well out of the box. While BIRD neither fully captures the real-world complexity of this task nor the full-breadth of real products like Databricks AI/BI Genie (Figure 1), its popularity allows us to measure the efficacy of RLVR for data science on a well understood benchmark.
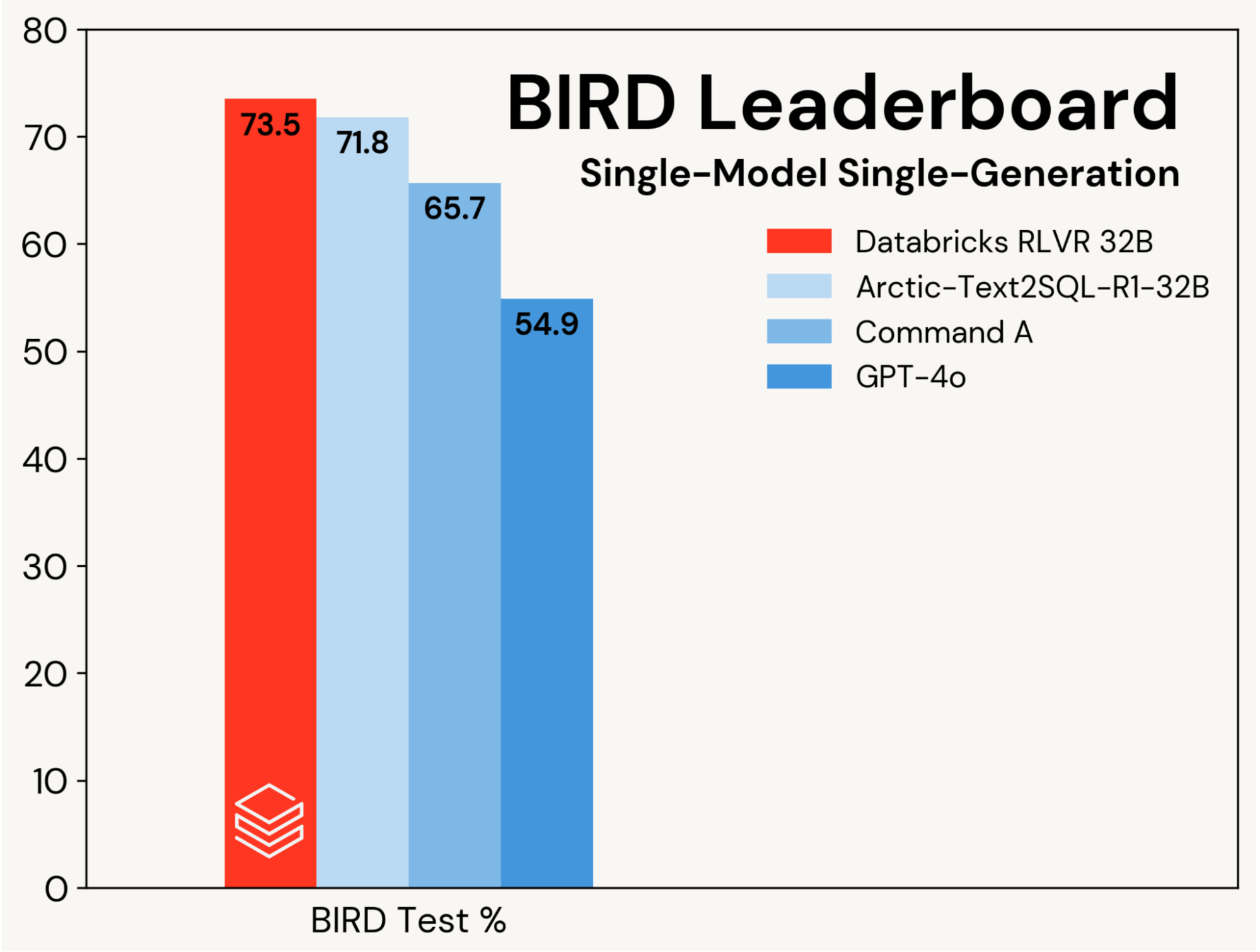
We focus on improving a base SQL coding model using RLVR, isolating these gains from improvements driven by agentic designs. Progress is measured on the single-model, single‑generation track of the BIRD leaderboard (i.e., no self‑consistency), which evaluates on a private test set.
We set a new state-of-the-art test accuracy of 73.5% on this benchmark. We did so using our standard RLVR stack and training only on the BIRD training set. The previous best score on this track was 71.8%[1], achieved by augmenting the BIRD training set with additional data and using a proprietary LLM (GPT-4o). Our score is substantially better than both the original base model and proprietary LLMs (see Figure 2). This result showcases the simplicity and generality of RLVR: we reached this score with off-the-shelf data and the standard RL components we’re rolling out in Agent Bricks, and we did so on our first submission to BIRD. RLVR is a powerful baseline that AI developers should consider whenever enough training data is available.
We constructed our submission based on the BIRD dev set. We found that Qwen 2.5 32B Coder Instruct was the best starting point. We fine-tuned this model using both Databricks TAO – an offline RL method, and our RLVR stack. This approach alongside careful prompt and model selection was sufficient to get us to the top of the BIRD Benchmark. This result is a public demonstration of the same techniques we’re using to improve popular Databricks products like AI/BI Genie and Assistant and to help our customers build agents using Agent Bricks.
Our results highlight the power of RLVR and the efficacy of our training stack. Databricks customers have also reported great results using our stack in their reasoning domains. We think this recipe is powerful, composable, and widely applicable to a range of tasks. If you’d like to preview RLVR on Databricks, contact us here.
1See Table 1 in https://arxiv.org/pdf/2505.20315
Authors: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.