Building State-of-the-Art Enterprise Agents 90x Cheaper with Automated Prompt Optimization
Databricks Agent Bricks is a platform for building, evaluating, and deploying production-grade AI agents for enterprise workflows. Our goal is to help customers achieve the optimal quality–cost balance on the Pareto frontier for their domain-specific tasks, and to continuously improve their agents that reason on their own data. To support this, we develop enterprise-centric benchmarks and run empirical evaluations on agents that measure accuracy and serving efficiency, reflecting real tradeoffs enterprises face in production.
Within our broader agent optimization toolkit, this post focuses on automated prompt optimization, a technique that leverages iterative, structured search guided by feedback signals from evaluation to automatically improve prompts. We demonstrate how we can:
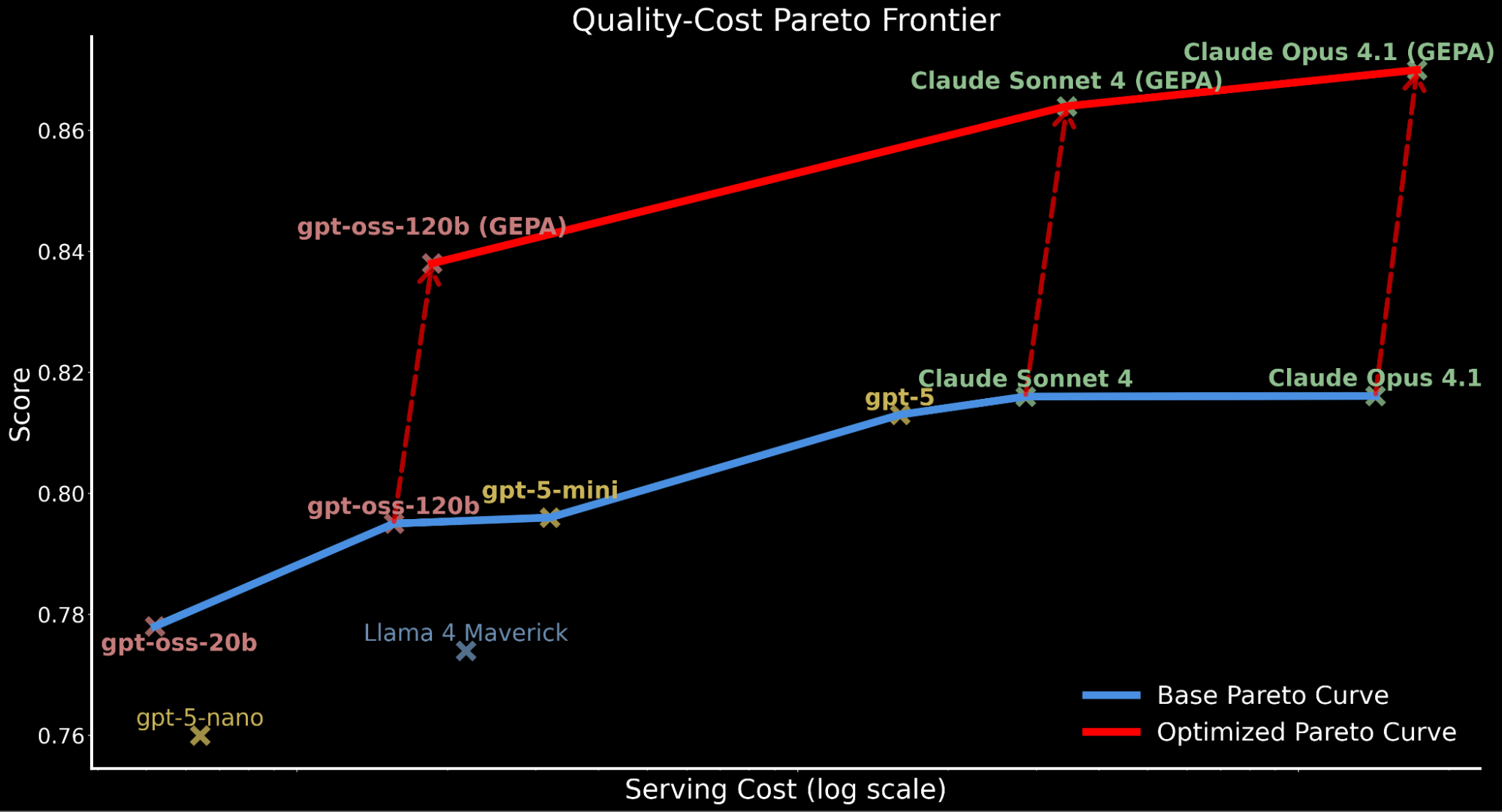
- Enable open-source models to surpass frontier-model quality for enterprise tasks: leveraging GEPA, a newly-released prompt optimization technique coming out of research from Databricks and UC Berkeley, we present how gpt-oss-120b surpasses state-of-the-art proprietary models Claude Sonnet 4 and Claude Opus 4.1 by ~3% while being roughly 20x and 90x cheaper to serve, respectively (see Pareto frontier plot below).
- Lift proprietary frontier models even higher: we apply the same approach to leading proprietary models, raising Claude Opus 4.1 and Claude Sonnet 4 baseline performance by 6-7% and achieving new state-of-the-art performance.
- Offer a superior quality-cost tradeoff compared to SFT: automated prompt optimization delivers performance on par with, or better than, supervised fine-tuning (SFT), while reducing serving costs by 20%. We also show that prompt optimization and SFT can work together to lift the performance further.
In the sections that follow, we’ll cover
- how we evaluate AI agent performance on information extraction as a core use case and why it matters for enterprise workflows;
- an overview of how prompt optimization works, the kinds of benefits it can unlock, especially in scenarios where finetuning is not practical, and performance gains on our evaluation pipeline;
- to put these gains in context, we will measure the impact of prompt optimization, and analyze the economics behind these techniques;
- performance comparison with supervised finetuning (SFT), highlighting the superior quality-cost tradeoff by prompt optimization;
- takeaways and next steps, particularly how you can get started applying these techniques directly with Databricks Agent Bricks to build the best-in-class AI agents optimized for real-world enterprise deployment.
Evaluation of the latest LLMs on IE Bench
Information Extraction (IE) is a core Agent Bricks feature, converting unstructured sources such as PDFs or scanned documents into structured records. Despite rapid progress in generative AI capabilities, IE remains difficult at enterprise scale:
- Documents are lengthy and filled with domain-specific jargon
- Schemas are complex, hierarchical, and contain ambiguities
- Labels are often noisy and inconsistent
- Operational tolerance for error in extraction is low
- Requirement of high reliability and cost efficiency for large inference workloads
As a result, we observe that performance can vary widely by domain and task complexity, so building the right compound AI systems for IE across diverse use cases requires a thorough evaluation of varying AI agent capabilities.
To explore this, we developed IE Bench, a comprehensive evaluation suite spanning multiple real-world enterprise domains like finance, legal, commerce, and healthcare. The benchmark reflects complex real-world challenges, including documents exceeding 100 pages, spanning extraction entities with over 70 fields, and hierarchical schemas with multiple nested levels. We report evaluations on the benchmark’s held-out test set to provide a reliable measure of real-world performance.
We benchmarked the latest generation of open-source models served via the Databricks Foundation Models API, including the newly released gpt-oss series, as well as leading proprietary models from multiple providers, including the latest GPT-5 family.1
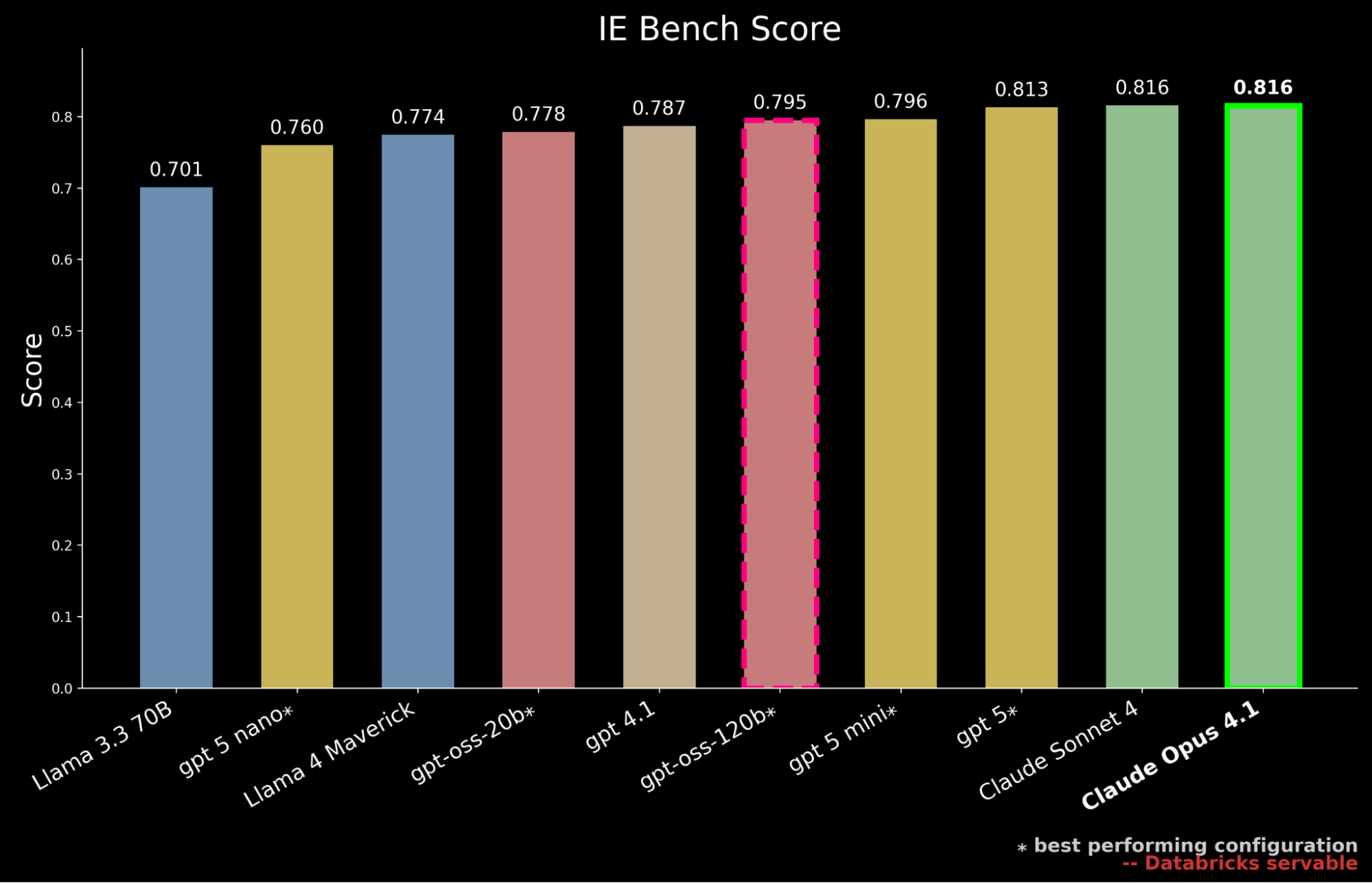
Our results show that gpt-oss-120b is the highest performing open-source model on IE Bench, surpassing previously open-source state-of-the-art performance from Llama 4 Maverick by ~3% while approaching the performance level of gpt-5-mini, marking a meaningful step forward for open-source models. However, it still falls behind proprietary frontier model performance, trailing gpt-5, Claude Sonnet 4, and Claude Opus 4.1—which achieves the highest score on the benchmark.
Yet in enterprise settings, performance must also be weighed against serving cost. We further contextualize our previous findings by highlighting that gpt-oss-120b matches the performance of gpt-5-mini while only incurring roughly 50% of the serving cost. 2 Proprietary frontier models are largely more expensive with gpt-5 at ~10x the serving cost of gpt-oss-120b, Claude Sonnet 4 at ~20x and Claude Opus 4.1 at ~90x.
To illustrate the quality-cost tradeoff across models, we plot the Pareto frontier below, depicting the baseline performance for all models prior to any improvements..
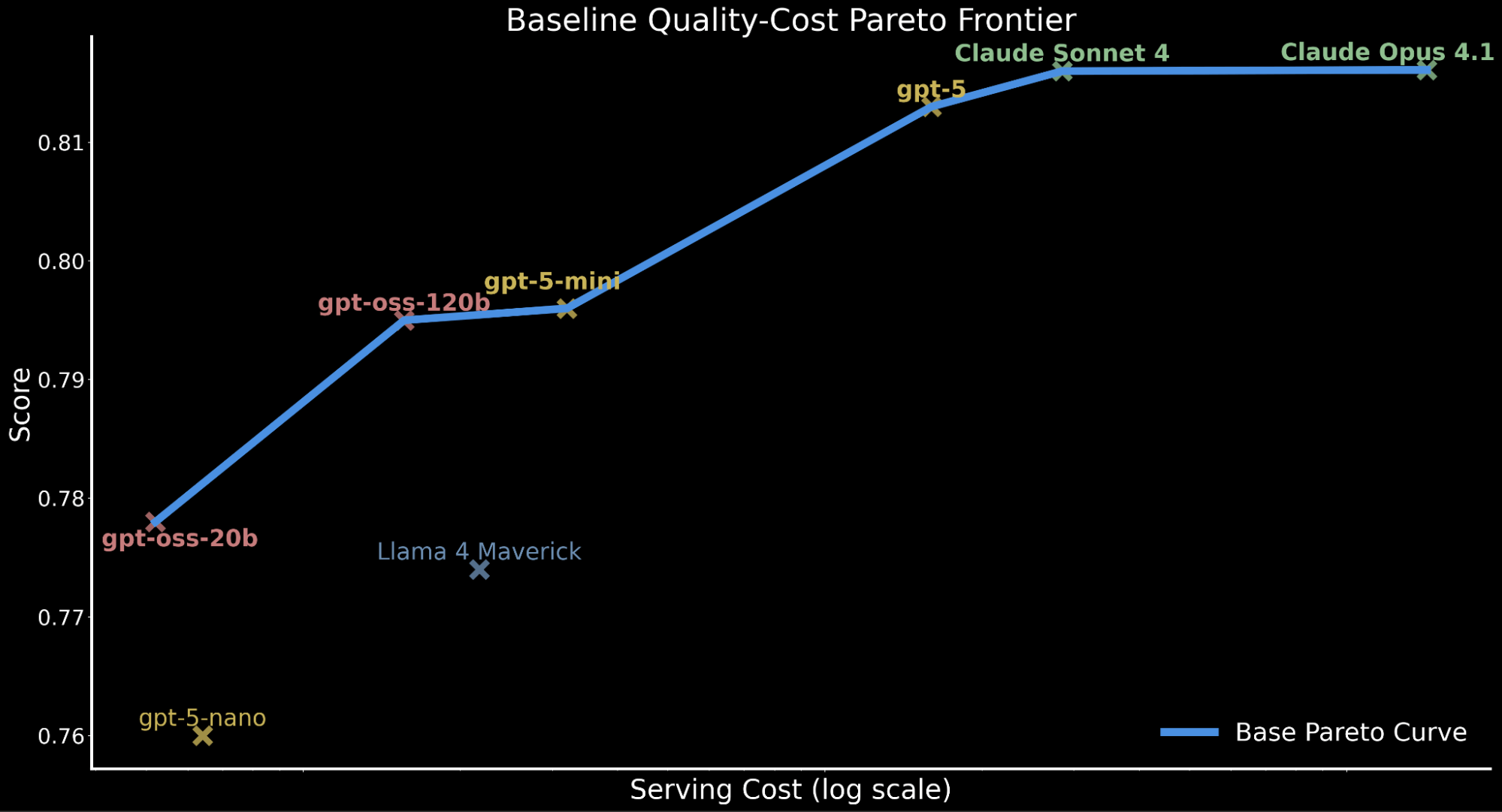
This quality-cost tradeoff has major implications for enterprise workloads requiring large-scale inference that must consider compute budget and serving throughput while maintaining performant accuracy.
This motivates our exploration: Can we push gpt-oss-120b to frontier-level quality while preserving its cost efficiency? If so, this would deliver leading performance on the cost-quality Pareto frontier while being servable for enterprise adoption at Databricks.
Optimizing open-source models to outperform frontier model performance
We explore automatic prompt optimization as a systematic method for raising model performance. Manual prompt engineering can deliver gains, but it typically depends on domain expertise and trial-and-error experimentation. This complexity grows further in compound AI systems integrating multiple LLM calls and external tools that must be optimized together, making manual prompt tuning impractical to scale or maintain across production pipelines.
Prompt optimization offers a different approach, leveraging structured search guided by feedback signals to automatically improve prompts. Such optimizers are pipeline-agnostic and are able to jointly optimize multiple interdependent prompts in multi-stage pipelines, making these techniques robust and adaptable across compound AI systems and diverse tasks.
To test this, we apply automated prompt optimization algorithms, specifically MIPROv2, SIMBA, and GEPA, a new prompt optimizer coming out of research from Databricks and UC Berkeley that combines language-based reflection with evolutionary search to improve AI systems. We apply these algorithms to evaluate how optimized prompting can close the gap between the best-performing open-source model, gpt-oss-120b, and state-of-the-art closed-source frontier models.
We consider the following configurations of automated prompt optimizers in our exploration
Each prompt optimization technique relies on an optimizer model to refine different aspects of the prompt for a target student model. Depending on the algorithm, the optimizer model can generate few-shot examples from bootstrapped traces to apply in-context learning and/or propose and improve the task instructions through search algorithms that perform iterative reflection using feedback to mutate and select better prompts across optimization trials. These insights are distilled into improved prompts for the student model to use during inference time at serving. While the same LLM can be used for both roles, we also experiment with using a “stronger-performing model” as the optimizer model to explore if higher-quality guidance can further boost the student model performance.
Building on our earlier findings of gpt-oss-120b as the leading open-source model on IE Bench, we consider it our student model baseline to explore further improvements.
When optimizing gpt-oss-120b, we consider two configurations:
- gpt-oss-120b (optimizer) → gpt-oss-120b (student)
- Claude Sonnet 4 (optimizer) → gpt-oss-120b (student)
Since Claude Sonnet 4 achieves leading performance on IE Bench over gpt-oss-120b, and is relatively cheaper compared to Claude Opus 4.1 with similar performance, we explore the hypothesis of whether applying a stronger optimizer model can produce better performance for gpt-oss-120b.
We evaluate each configuration across the optimization techniques and compare with the respective gpt-oss-120b baseline:
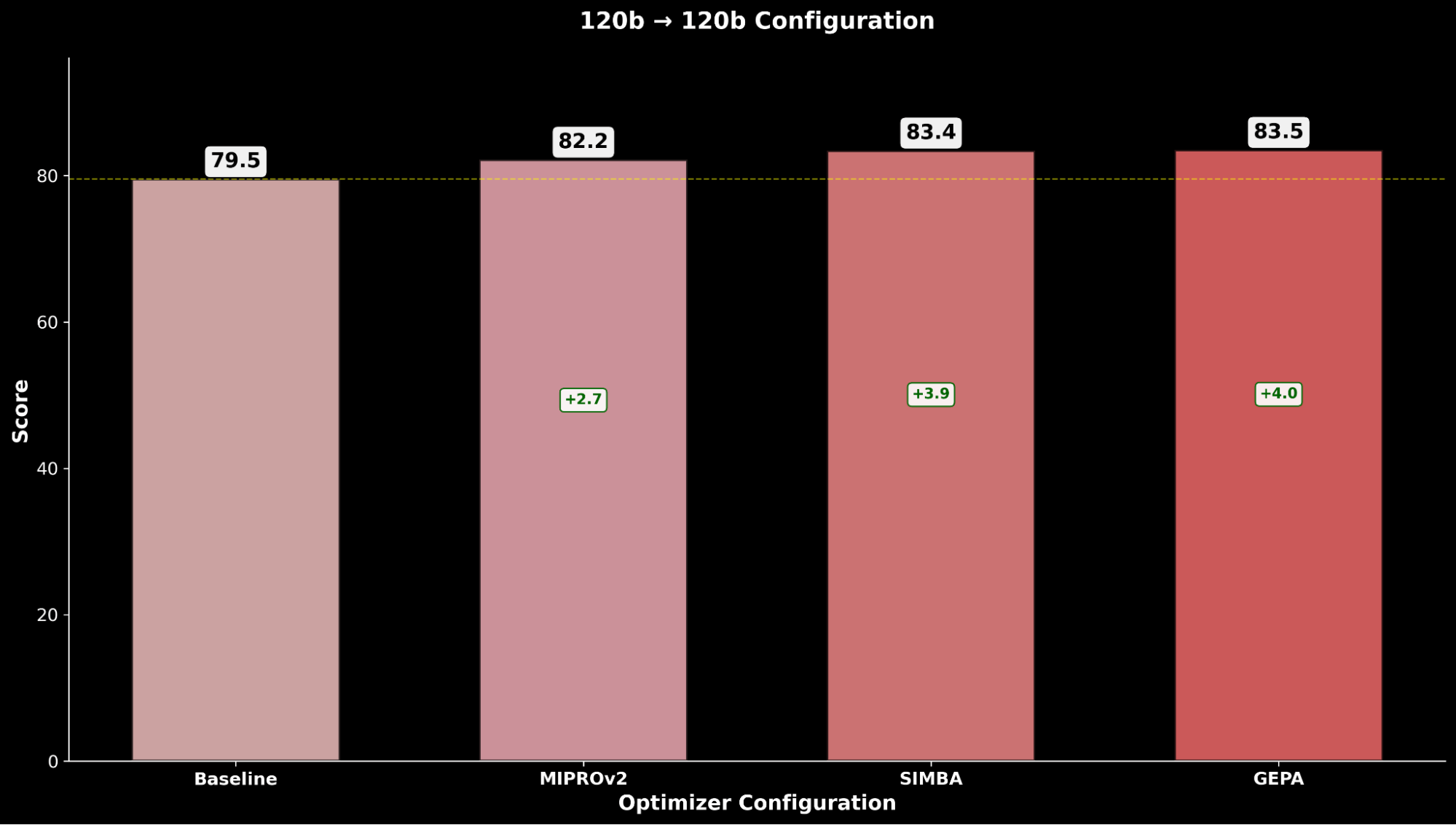
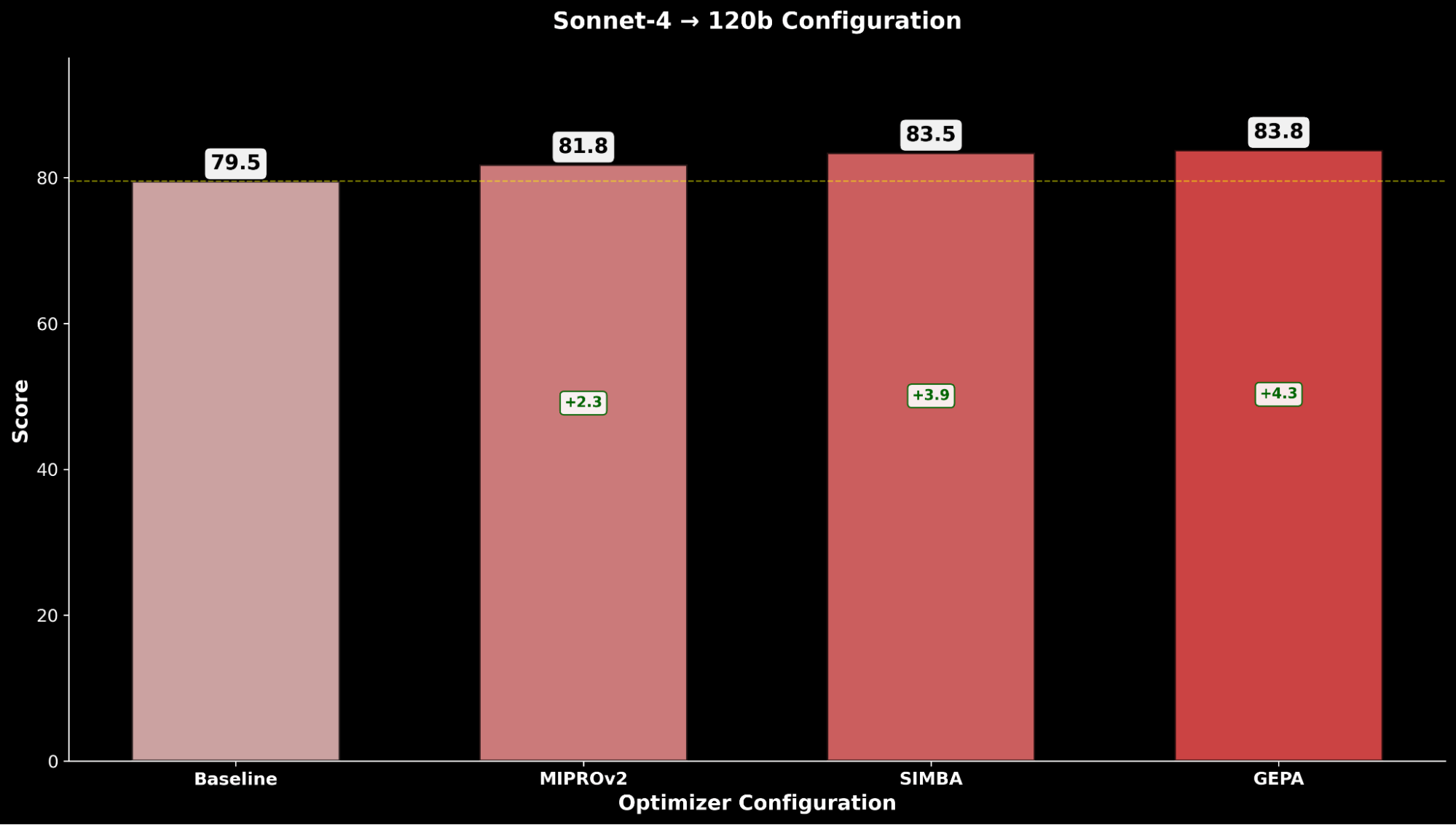
Across IE Bench, we find that optimizing gpt-oss-120b with Claude Sonnet 4 as the optimizer model achieves the most improvement over baseline performance of gpt-oss-120b, with a significant +4.3 point improvement over the baseline and a +0.3 point improvement over optimizing gpt-oss-120b with itself as the optimizer model, highlighting lift through the use of a stronger optimizer model.
We compare the best-performing GEPA-optimized gpt-oss-120b configuration against the frontier Claude models:
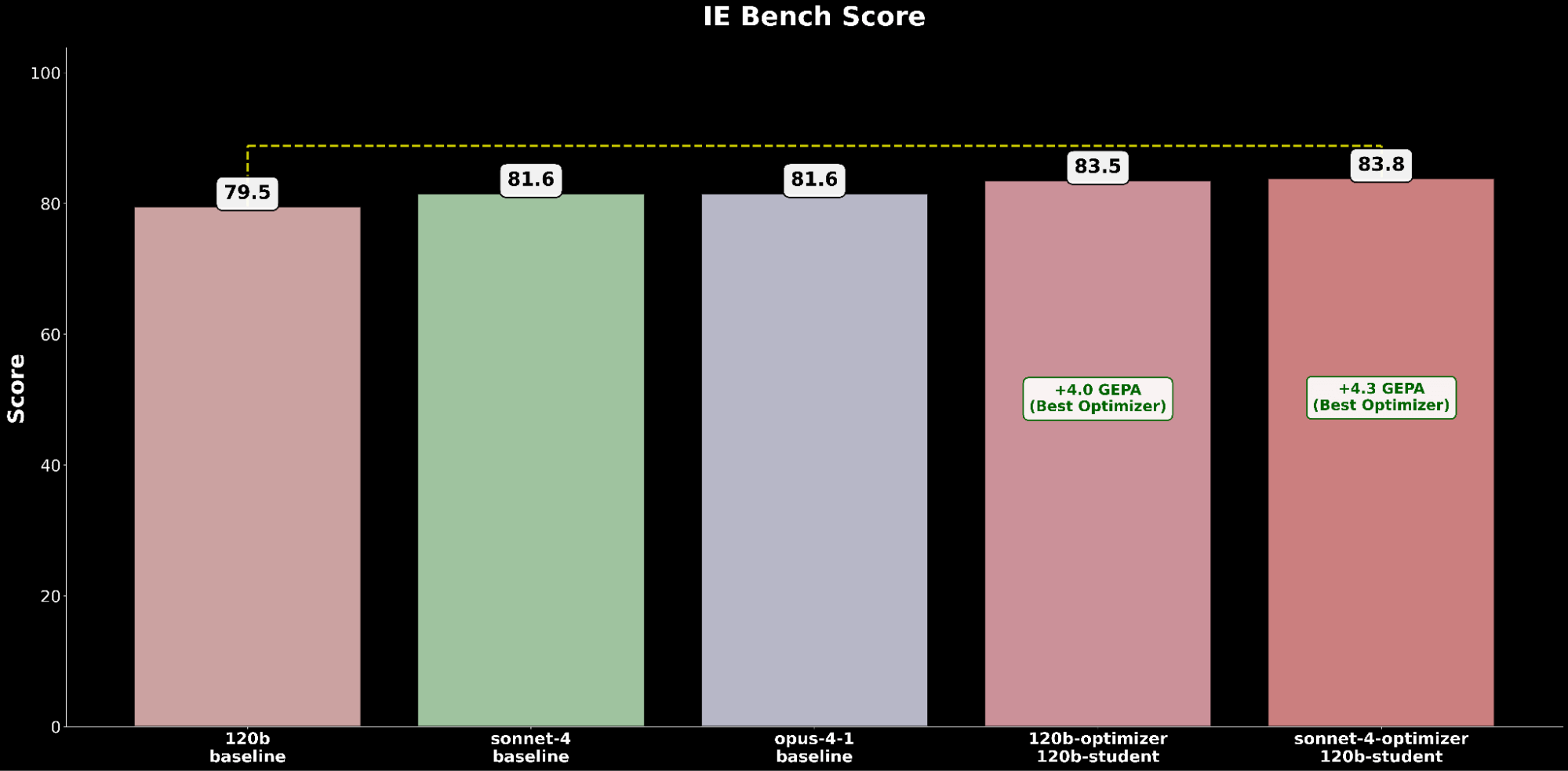
The optimized gpt-oss-120b configuration outperforms the state-of-the-art baseline performance of Claude Opus 4.1 by a +2.2 absolute gain, highlighting the benefits of automated prompt optimization in raising an open-source model to outperform leading proprietary models on IE capabilities.
Optimize frontier models to further raise performance ceiling
As we see the significance of automated prompt optimization, we explore whether applying the same principle to the leading frontier models Claude Sonnet 4 and Claude Opus 4.1 can further push the achievable performance frontier for IE Bench.
When optimizing each proprietary model, we consider the following configurations:
- Claude Sonnet 4 (optimizer) → Claude Sonnet 4 (student)
- Claude Opus 4.1 (optimizer) → Claude Opus 4.1 (student)
We choose to consider the default optimizer model configurations as these models already define the performance frontier.
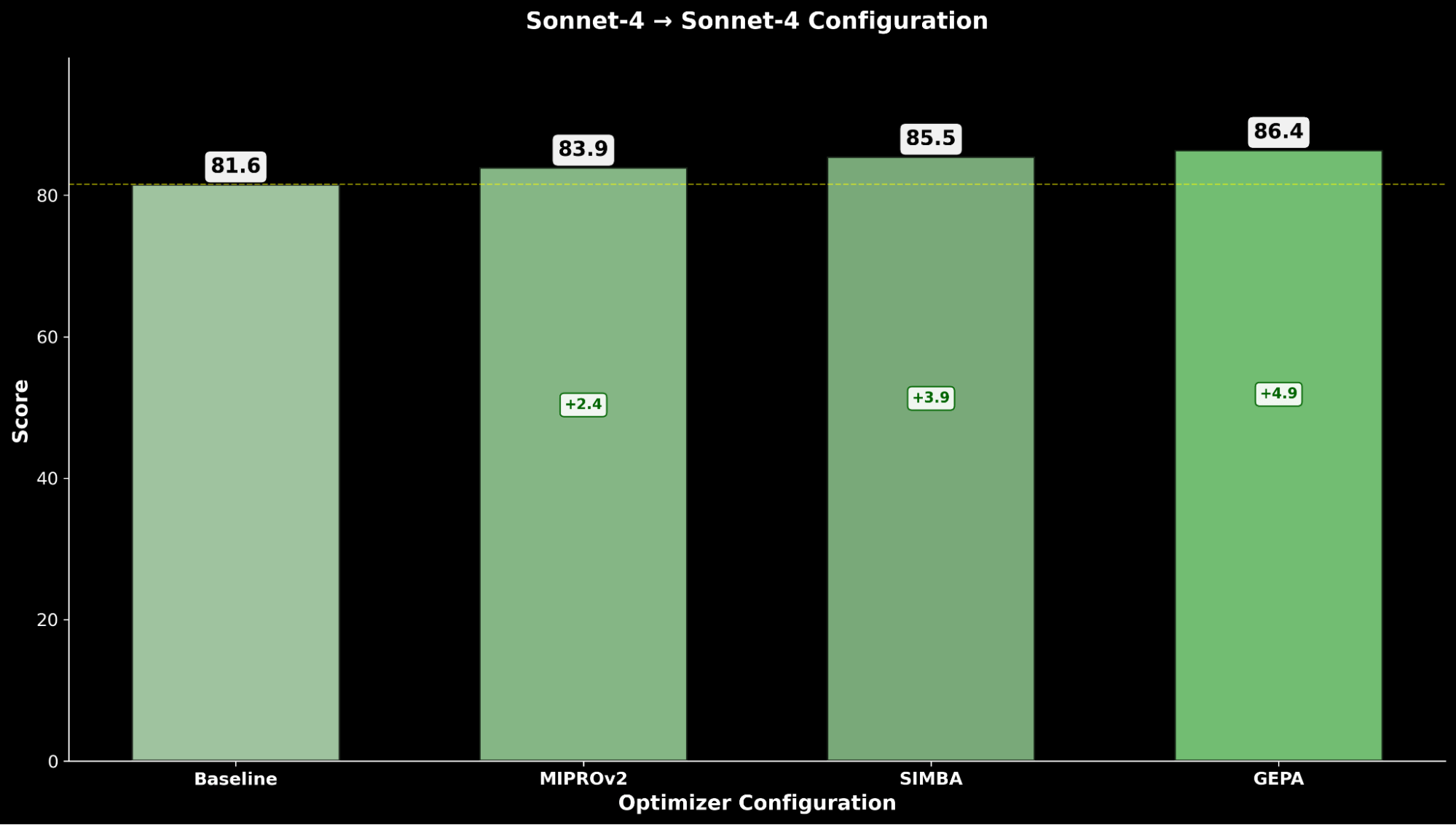
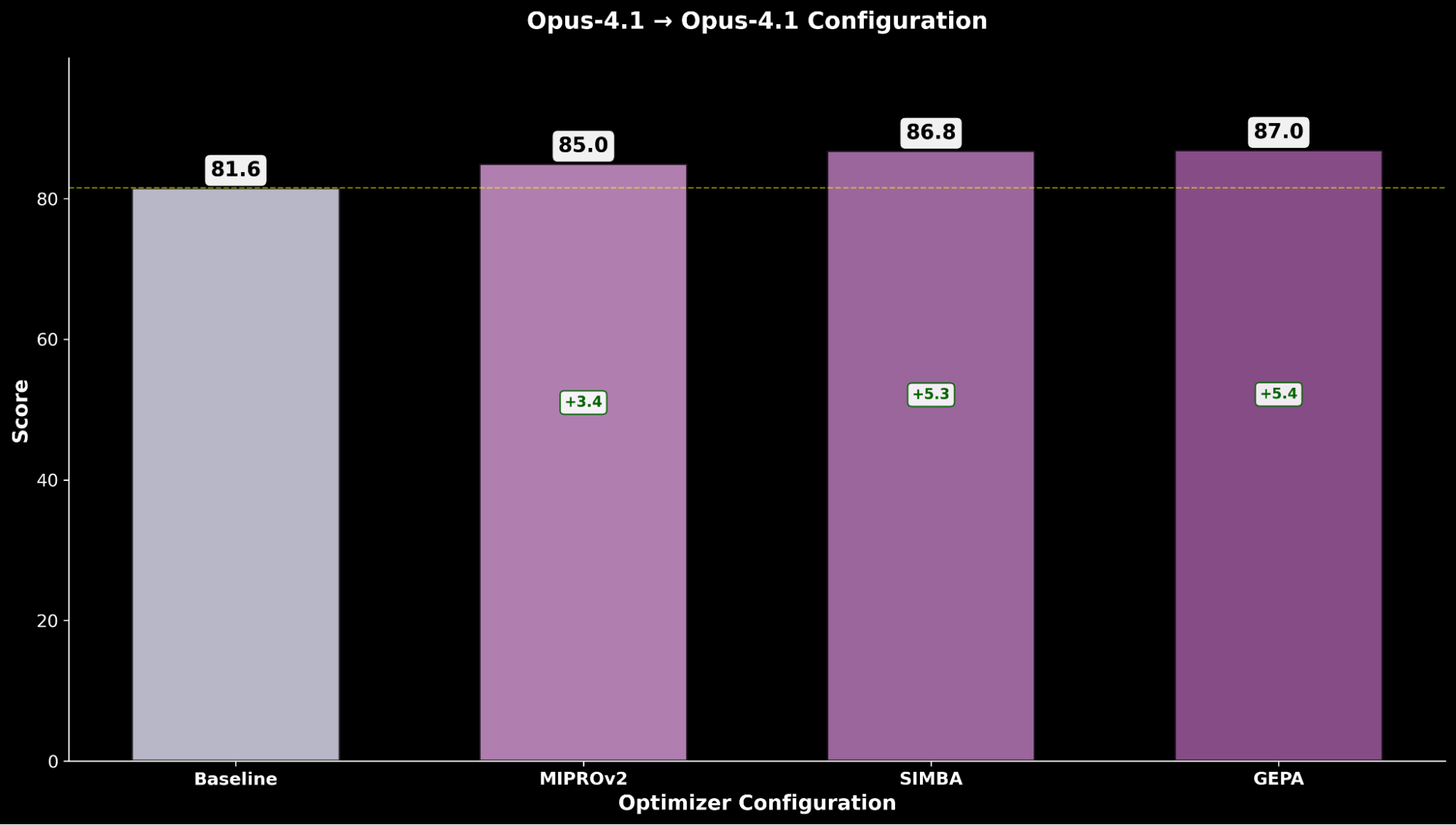
Optimizing Claude Sonnet 4 achieves a +4.8 improvement over the baseline performance, while optimized Claude Opus 4.1 achieves the overall best performance, with a significant +6.4 point improvement over the previous state-of-the-art performance.
Aggregating experiment results, we observe a consistent trend of automated prompt optimization delivering substantial performance gains across all models’ baseline performance.
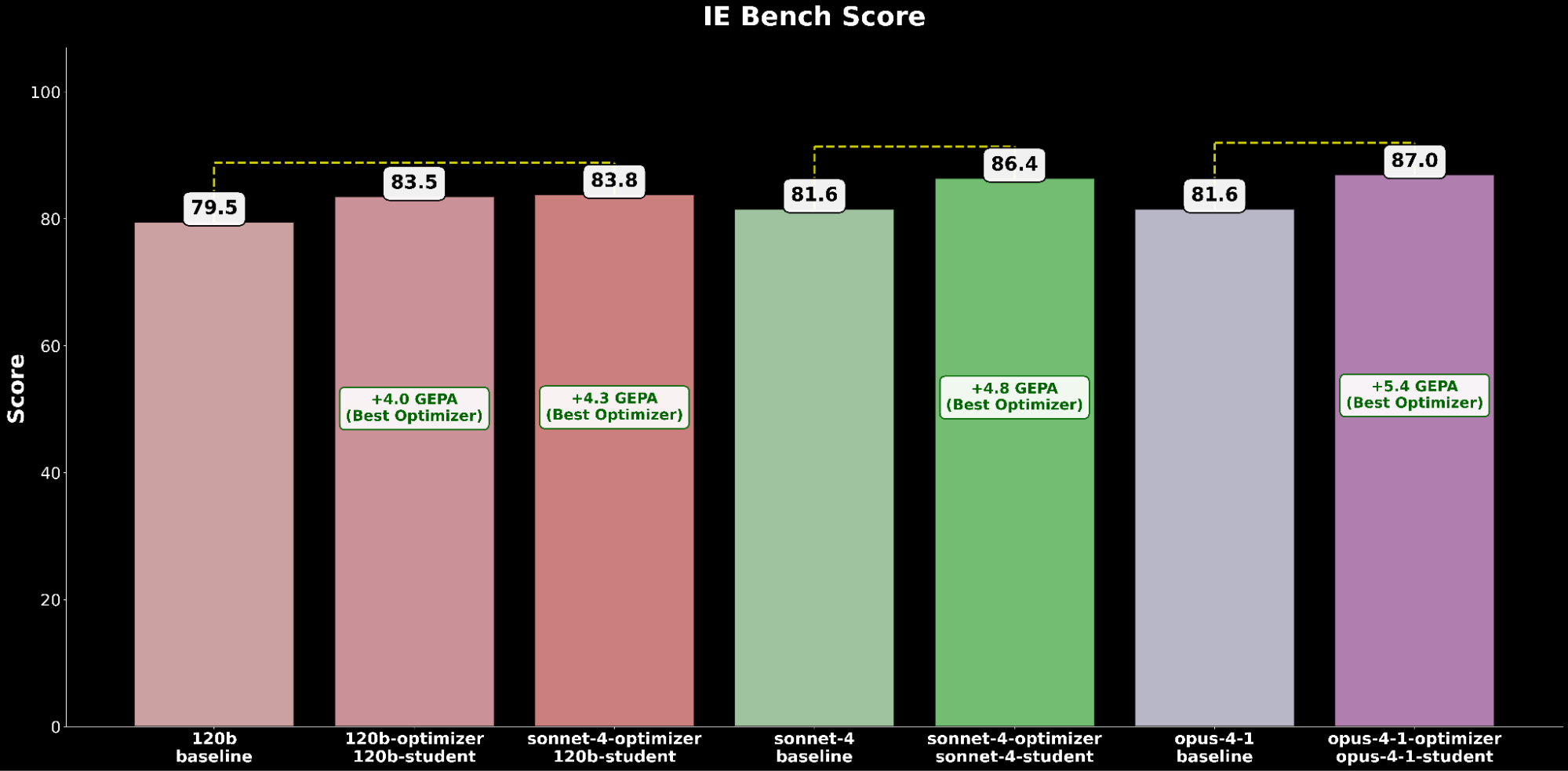
Across both open-source and closed-source model evaluations, we consistently find that GEPA is the highest-performing optimizer, followed by SIMBA and then MIPRO, unlocking significant quality gains using automated prompt optimization.
However, when considering cost, we observe that GEPA has relatively higher runtime overhead (as the optimization exploration can take on the order of O(3x) more LLM calls (~2-3 hrs) than MIPRO and SIMBA (~1 hr))3 during this empirical analysis of IE Bench. We hence factor in cost efficiency and update our quality-cost Pareto frontier including the optimized model performances.
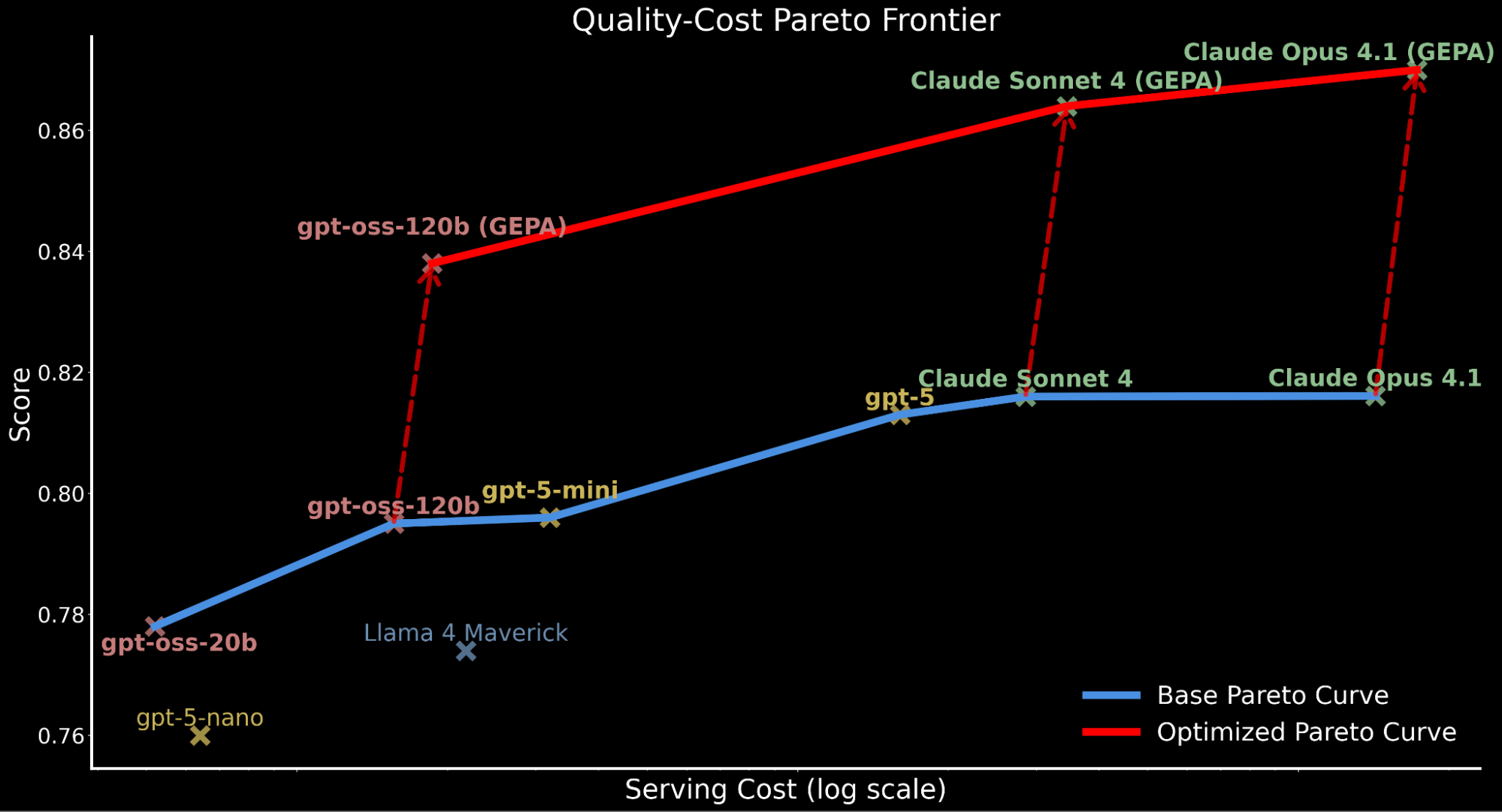
We highlight how applying automated prompt optimization shifts the entire Pareto curve upwards, establishing new state-of-the-art efficiency:
- GEPA-optimized gpt-oss-120b surpasses baseline performance of Claude Sonnet 4 and Claude Opus 4.1 while being 22x and 90x cheaper.
- For customers who prioritize quality over cost, GEPA-optimized Claude Opus 4.1 leads to new state-of-the-art performance, highlighting powerful gains for frontier models that cannot be finetuned.
- We attribute the accounted total serving cost increase for GEPA-optimized models to the longer, more detailed prompts compared to the baseline prompt produced through optimization
By applying automated prompt optimizations to agents, we showcase a solution that delivers on Agent Bricks’ core principles of high performance and cost efficiency.
Comparison with SFT
Supervised Fine-Tuning (SFT) is often considered the default method for improving model performance, but how does it compare to automated prompt optimization
To answer this, we conducted an experiment on a subset of IE Bench, choosing gpt 4.1 to evaluate SFT and automated prompt optimization performance (We exclude gpt-oss and gpt-5 from these comparisons as the models were not released at the time of evaluation).
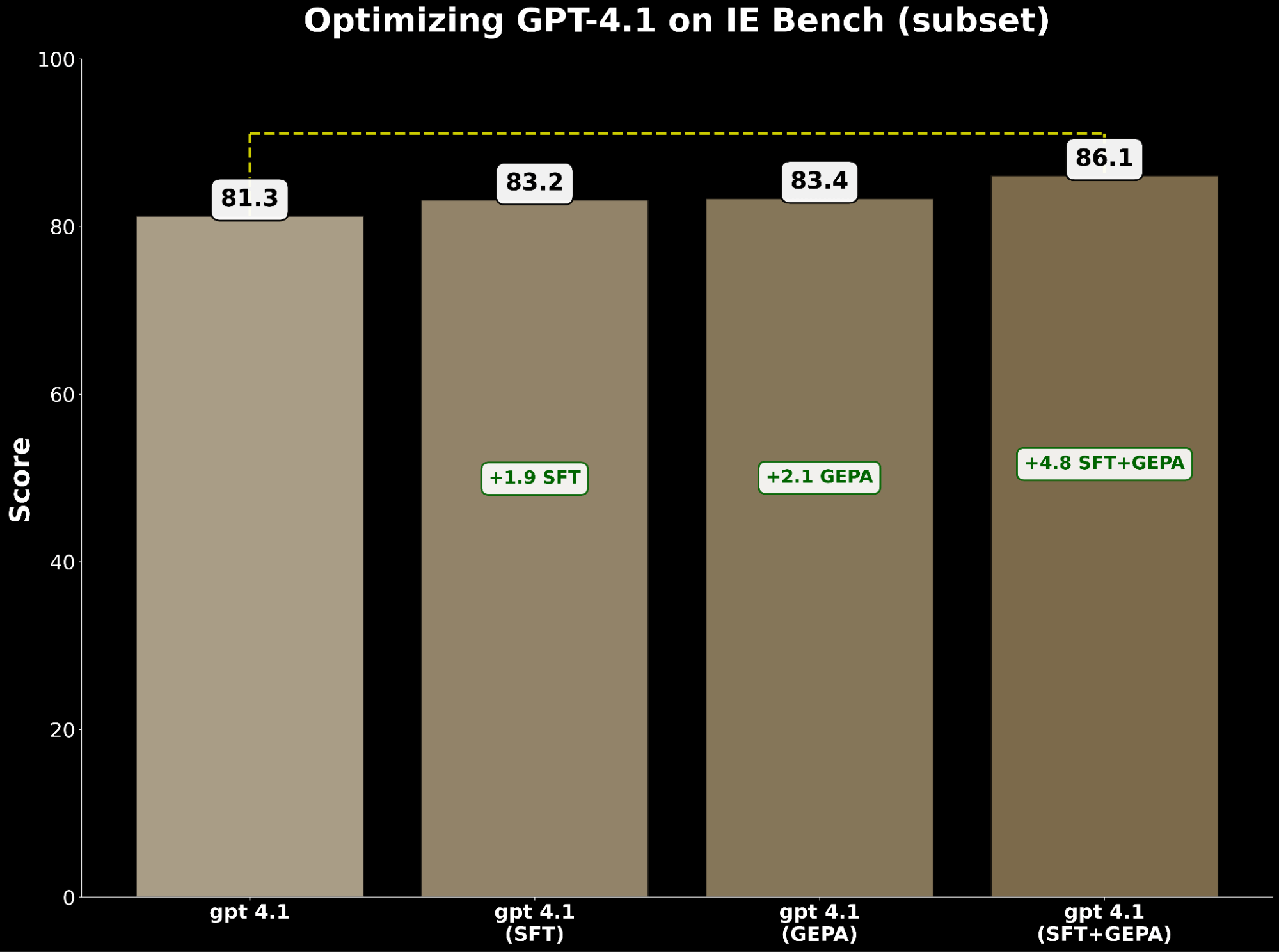
Both SFT and prompt optimization independently improve gpt-4.1. Specifically:
- SFT gpt-4.1 gained +1.9 points over baseline.
- GEPA-optimized gpt-4.1 gained +2.1 points, slightly exceeding SFT.
This demonstrates that prompt optimization can match—and even surpass—the improvements of supervised fine-tuning.
Inspired by BetterTogether, a technique that considers alternating prompt optimization and model weight finetuning to improve LLM performance, we apply GEPA on top of SFT and achieve a +4.8 point gain over the baseline—highlighting the strong potential of compounding these techniques together.
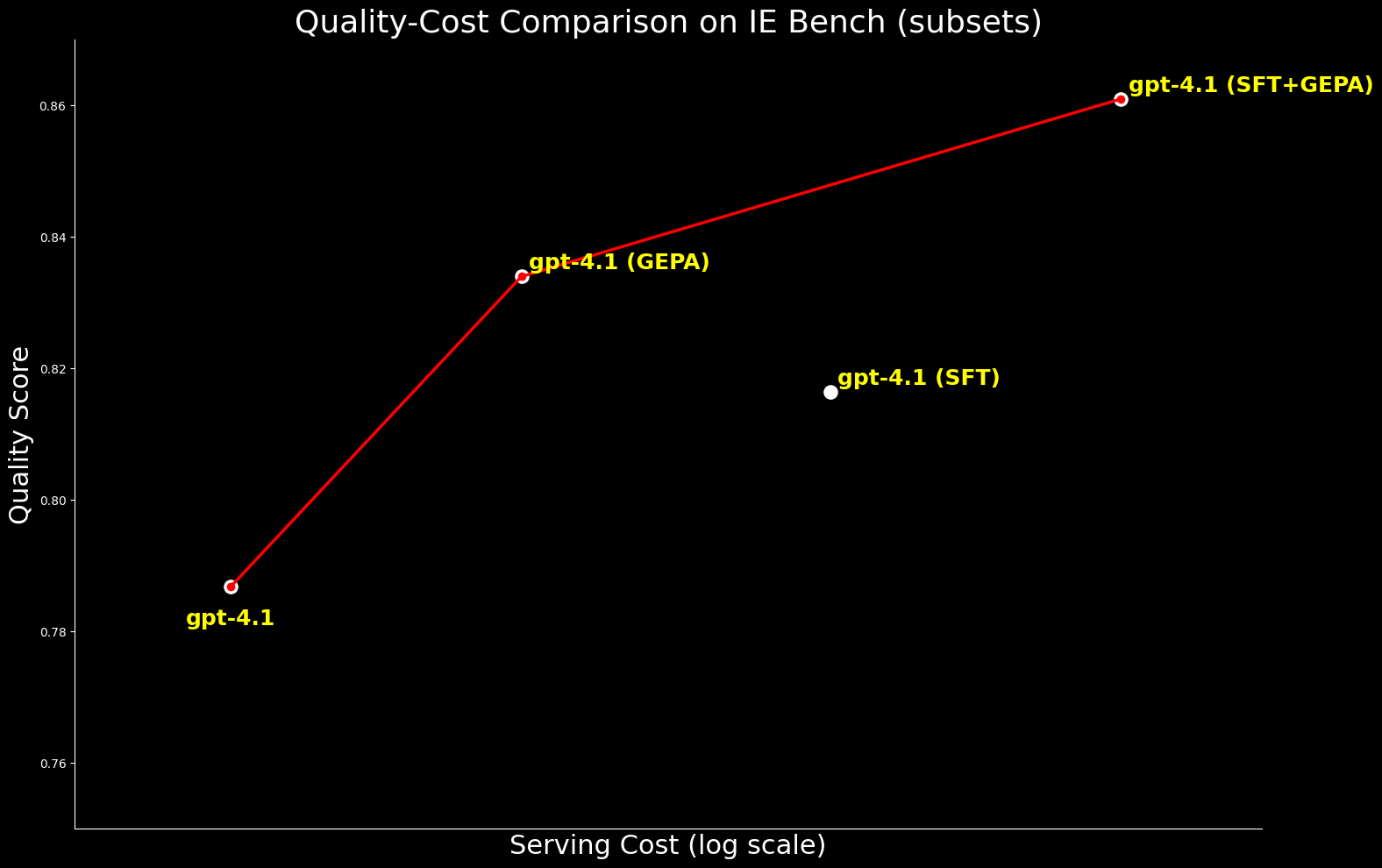
From a cost perspective, GEPA-optimized gpt-4.1 is ~20% cheaper to serve than SFT-optimized gpt-4.1, while delivering better quality. This highlights that GEPA offers a premium quality-cost balance over SFT. Additionally, we can maximize absolute quality by combining GEPA with SFT which performs 2.7% over SFT alone but comes at a ~22% higher serving cost.4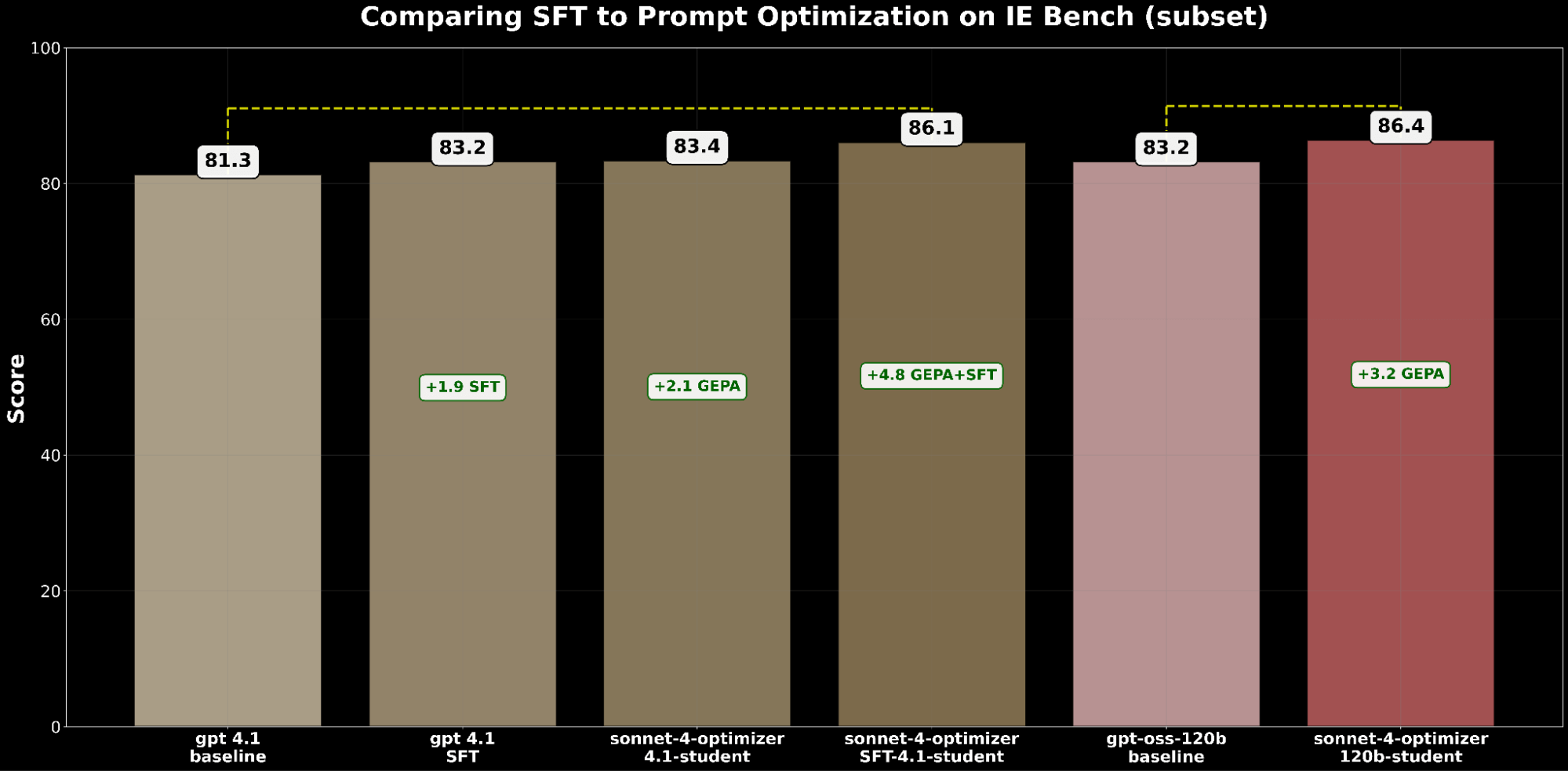
We extended the comparison to gpt-oss-120b to examine the quality–cost frontier. While SFT+GEPA-optimized gpt-4.1 comes close—within 0.3% of the performance of GEPA-optimized gpt-oss-120b—the latter delivers the same quality at 15× lower serving cost, making it far more practical and attractive for large-scale deployment.

Together, these comparisons highlight the strong performance gains enabled by GEPA optimization — whether used alone or in combination with SFT. They also highlight the exceptional quality-cost efficiency of gpt-oss-120b when optimized with GEPA.
Lifetime Cost
To evaluate optimization in real-world terms, we consider the lifetime cost to customers. The goal of optimization is not only to improve accuracy but also to produce an efficient agent that can serve requests in production. This makes it essential to look at both the cost of optimization and the cost of serving large volumes of requests.
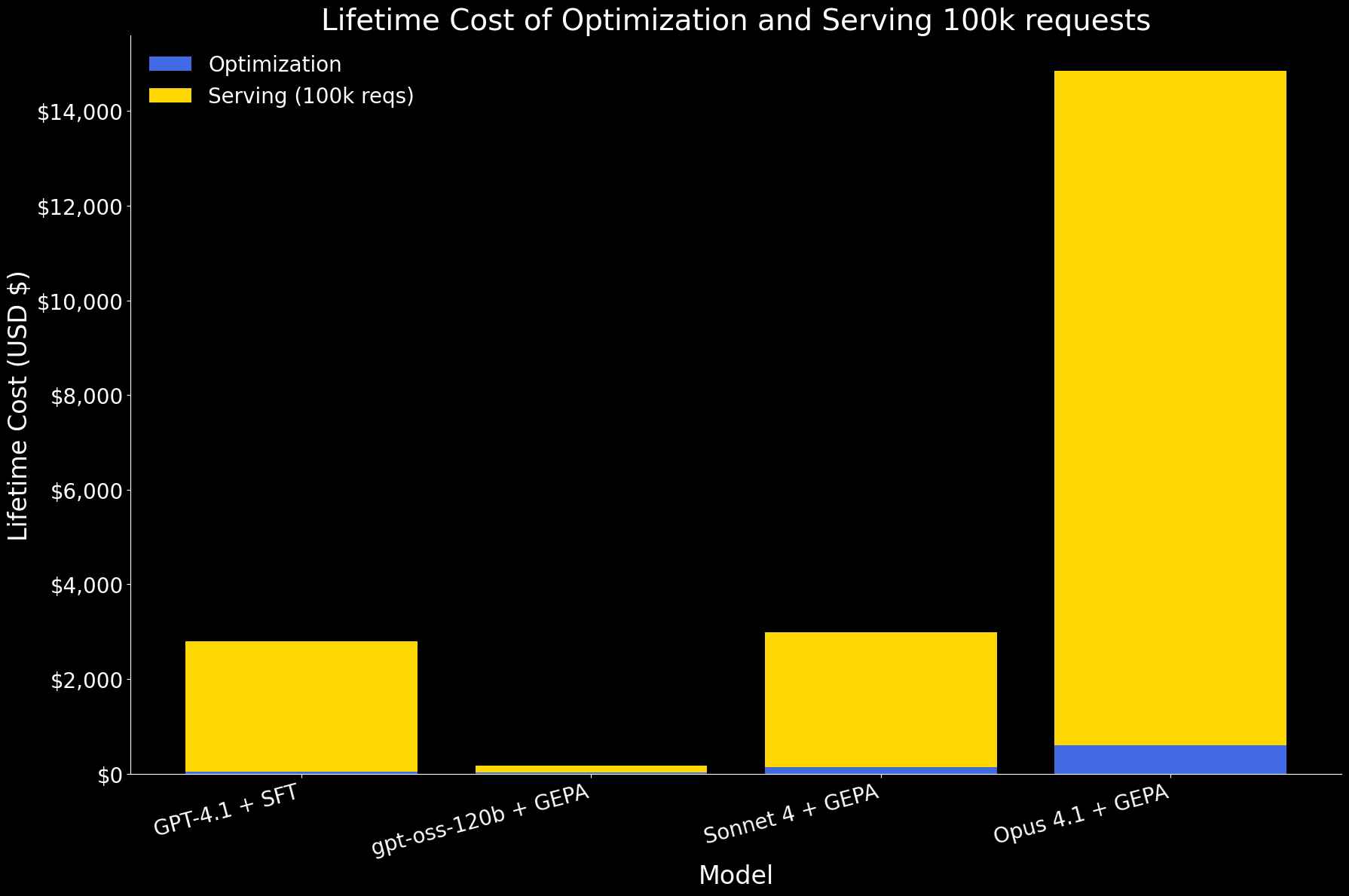
In the first plot below, we show the lifetime cost of optimizing an agent and serving 100k requests, broken down into optimization and serving components. At this scale, serving dominates the overall cost. Among the models:
- gpt-oss-120b with GEPA is by far the most efficient, with costs an order of magnitude lower for both optimization and serving.
- GPT 4.1 with SFT and Sonnet 4 with GEPA have similar lifetime cost.
- Opus 4.1 with GEPA is the most expensive, primarily due to its high serving price.
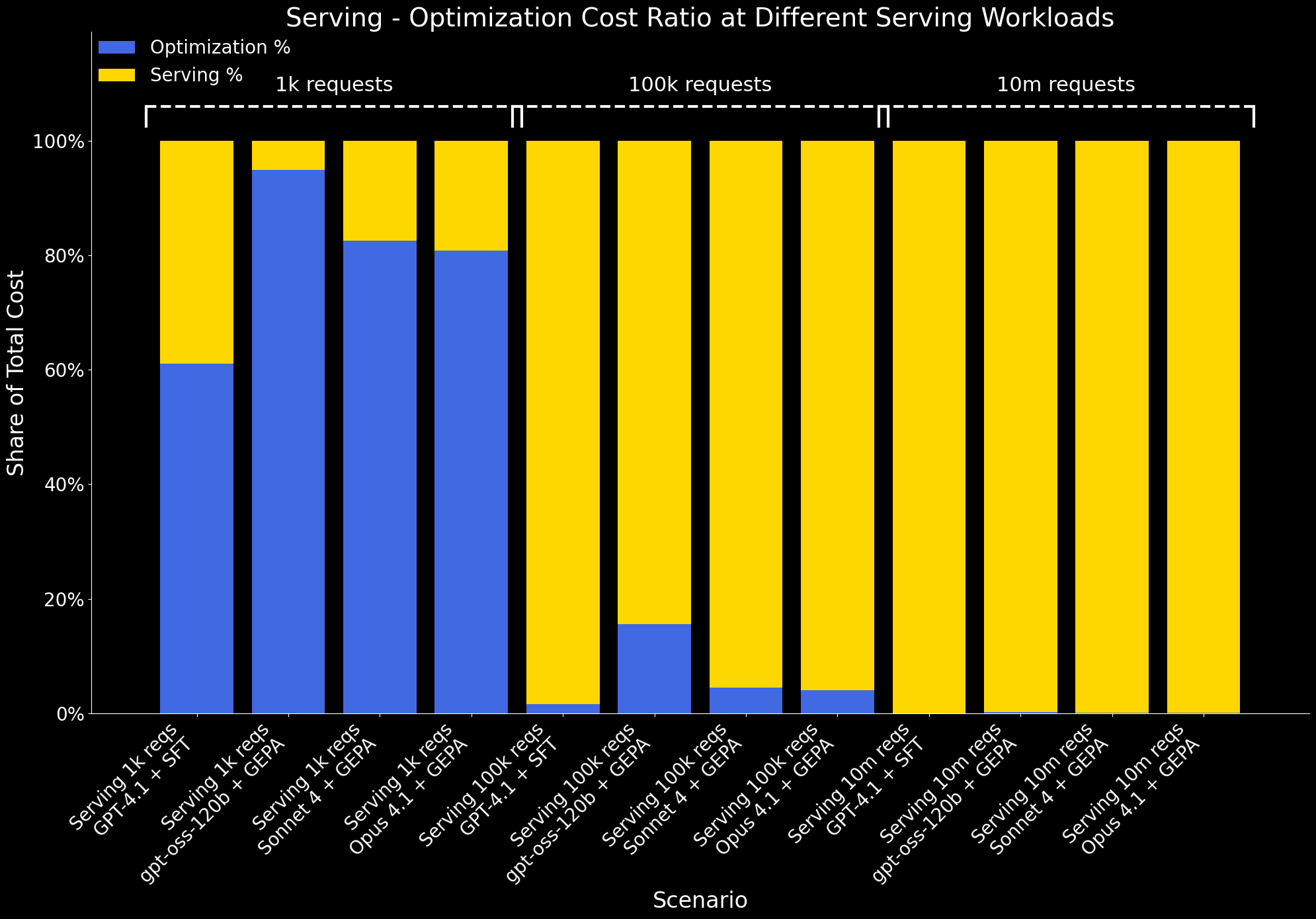
We also examine how the ratio of optimization to serving cost changes at different workload scales:
- At 1k serving workloads, serving costs are minimal, so optimization accounts for a large share of the total cost.
- By 100k requests, serving costs grow significantly, and the optimization overhead is amortized. At this scale, the benefit of optimization – better performance at lower serving cost – clearly outweighs its one-time cost.
- At 10M requests, optimization costs become negligible compared to serving costs and are no longer visible on the chart.
Summary
In this blog post, we demonstrated that automated prompt optimization is a powerful lever for advancing LLM performance on enterprise AI tasks:
- We developed IE Bench, a comprehensive evaluation suite spanning real-world domains and capturing complex information extraction challenges.
- By applying GEPA automated prompt optimization, we raise the performance of the leading open-source model gpt-oss-120b to surpass the performance of state-of-the-art proprietary model Claude Opus 4.1 by ~3% while being 90x cheaper to serve.
- The same technique applies to frontier proprietary models, boosting Claude Sonnet 4 and Claude Opus 4.1 by 6-7%.
- In comparison to Supervised Fine-Tuning (SFT), GEPA optimization provides a superior quality-cost tradeoff for enterprise use. It delivers performance on par with or surpassing SFT while reducing serving costs by 20%.
- Lifetime cost analysis shows that when serving at scale (e.g., 100k requests), the one-time optimization overhead is quickly amortized, and the benefits far outweigh the cost. Notably, GEPA on gpt-oss-120b delivers an order-of-magnitude lower lifetime cost compared to other frontier models, making it a highly attractive choice for enterprise AI agents.
Taken together, our results show that prompt optimization shifts the quality–cost Pareto frontier for enterprise AI systems, raising both performance and efficiency.
The automated prompt optimization, along with previously published TAO, RLVR, and ALHF, is now available in Agent Bricks. The core principle of Agent Bricks is to help enterprises build agents that accurately reason on your data, and achieve state-of-the-art quality and cost-efficiency on domain-specific tasks. By unifying evaluation, automated optimization, and governed deployment, Agent Bricks enables your agents to adapt to your data and tasks, learn from feedback, and continuously improve on your enterprise domain-specific tasks. We encourage customers to try Information Extraction and other Agent Bricks capabilities to optimize agents for your own enterprise use cases.
1 For both gpt-oss and gpt-5 model series, we follow the best practices from OpenAI’s Harmony format that inserts the target JSON schema in the developer message to generate structured output.
We also ablate over the different reasoning efforts for the gpt-oss series (low, medium, high) and gpt-5 series (minimal, low, medium, high), and report the best performance of each model across all reasoning efforts.
2 For serving cost estimates, we use published pricing from the model providers’ platforms (OpenAI and Anthropic for proprietary models) and from Artificial Analysis for open-source models. Costs are calculated by applying these prices to the input and output token distributions observed in IE Bench, giving us the total cost of serving for each model.
3 The actual runtime of the automated prompt optimization is hard to estimate, as it depends on many factors. Here are are giving a rough estimation based on our empirical experience.
4 We estimate the serving cost of SFT gpt-4.1 using OpenAI’s published fine-tuned model pricing. For GEPA-optimized models, we calculate serving cost based on the measured input and output token usage of the optimized prompts.
Authors: Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng, Simon Favreau-Lessard
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.