Avanzando el Lakehouse con Apache Iceberg v3 en Databricks
Databricks soporta Apache Iceberg v3, ofreciendo a los clientes una capa de datos unificada, de alto rendimiento e interoperable
por Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu y Aniruth Narayanan
• Databricks soporta Apache Iceberg v3, para que los clientes puedan ejecutar cargas de trabajo interoperables y gobernadas en una sola copia de datos
• Con Iceberg v3, los vectores de eliminación, el linaje a nivel de fila y el tipo de dato Variant ahora están disponibles en todas las tablas administradas
• Con estas características, Databricks trae la Plataforma de Inteligencia de Datos a todos los formatos para el mejor rendimiento
Databricks soporta Apache Iceberg v3 en la Plataforma de Inteligencia de Datos, ofreciendo a los clientes una capa de datos unificada y abierta con rendimiento, interoperabilidad y gobernanza de primer nivel.
Con esta versión, los clientes de Databricks que ejecutan cargas de trabajo de Iceberg ahora pueden aprovechar las características de la v3, incluyendo vectores de eliminación, linaje a nivel de fila y el tipo de dato Variant. Estas características permiten a los equipos ejecutar cargas de trabajo modernas de manera eficiente y consistente en todas las plataformas. Estas características también funcionan sin problemas tanto en tablas Delta como en Iceberg, permitiendo la interoperabilidad sin reescribir datos.

Esta versión fortalece el compromiso de Databricks con los estándares abiertos y ayuda a los clientes a construir sobre la base del lakehouse de Delta Lake, Apache Iceberg, Apache Parquet y Apache Spark, todo con gobernanza y flexibilidad completas.
En este blog, exploraremos:
- Una capa de datos unificada con Iceberg v3
- Cargas de trabajo eficientes de Iceberg v3 en Databricks
- Avanzando en los formatos de tabla abiertos
Una capa de datos unificada con Iceberg v3
Delta Lake y Apache Iceberg se han convertido en la base del lakehouse moderno, cada uno con sólidas capacidades para la confiabilidad, la gobernanza y la gestión escalable de datos. Ambos utilizan archivos de metadatos para rastrear archivos de datos Parquet y eliminaciones a nivel de fila. Sin embargo, las diferencias menores entre los formatos en estos archivos de datos y de eliminación a menudo obligaban a las organizaciones a elegir un formato y sus características, generalmente basándose en las plataformas de datos que utilizaban. Esta elección a menudo era irreversible, ya que reescribir petabytes de datos no es práctico.
Iceberg v3 cierra esta brecha. Introduce características que se alinean estrechamente con Delta y el ecosistema abierto más amplio, como Parquet y Spark, lo que permite a los equipos utilizar una sola copia de datos con comportamiento y rendimiento consistentes en todos los formatos.
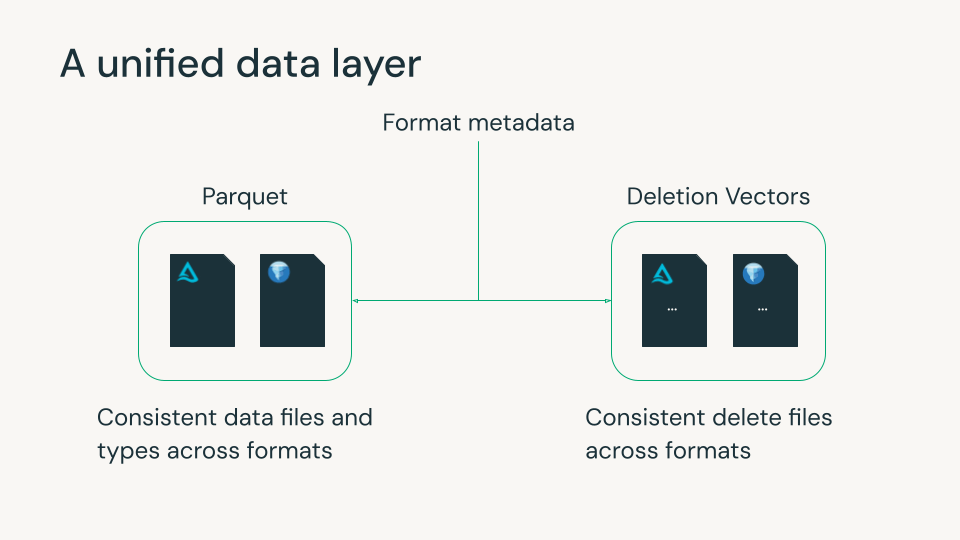
Databricks ha creído durante mucho tiempo que el futuro del lakehouse es la opcionalidad sin fragmentación. Nuestras contribuciones a Iceberg v3 reflejan ese compromiso: ayudando a unificar los comportamientos centrales de las tablas para que los clientes puedan usar los motores y herramientas que prefieren mientras gobiernan todo de manera consistente con Unity Catalog.
Cargas de trabajo eficientes de Iceberg v3 en Databricks
Con Iceberg v3, Databricks trae las características de la Plataforma de Inteligencia de Datos a todas las tablas administradas por Unity Catalog.
Vectores de eliminación para actualizaciones más rápidas
Los vectores de eliminación permiten eliminar o actualizar filas sin reescribir archivos Parquet. En su lugar, las eliminaciones se almacenan como archivos separados y se fusionan durante la lectura. La mayoría de las cargas de trabajo de ingeniería de datos modifican solo unas pocas filas a la vez, lo que la convierte en una característica crítica para escrituras eficientes.

Ahora puede aprovechar el rendimiento de precio de ETL de primer nivel de Databricks para ejecutar cargas de trabajo de Iceberg utilizando vectores de eliminación. En comparación con las sentencias MERGE regulares, los vectores de eliminación pueden acelerar las actualizaciones hasta 10 veces. Los motores de Iceberg pueden leer y escribir en tablas administradas de Iceberg utilizando las API del Catálogo REST de Iceberg de Unity Catalog. Como señala Geodis:
“Ahora que los Vectores de Eliminación han llegado a Iceberg, podemos centralizar nuestro patrimonio de datos de Iceberg en Unity Catalog, mientras aprovechamos el motor de nuestra elección y mantenemos un rendimiento de primer nivel.” —Delio Amato, Arquitecto Jefe y Director de Datos, Geodis
Linaje de fila para concurrencia a nivel de fila
El linaje de fila otorga a cada fila un ID único, lo que facilita el seguimiento de los cambios a lo largo del tiempo. El linaje de fila es necesario para todas las tablas de Iceberg v3.
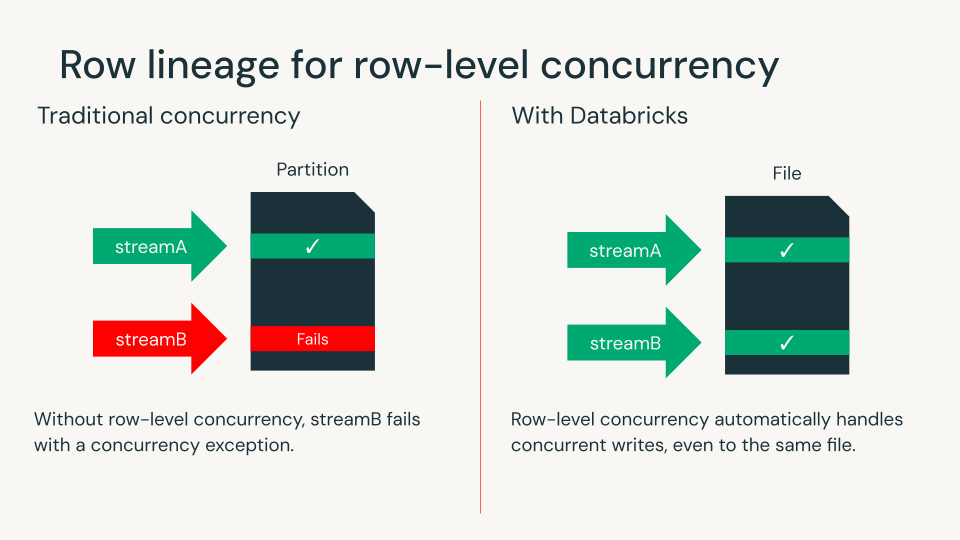
Con los vectores de eliminación y el linaje de fila, los clientes de Databricks ahora pueden usar concurrencia a nivel de fila para detectar conflictos de escritura a nivel de fila. Esto elimina la necesidad de diseñar diseños de datos complejos o coordinar cargas de trabajo para garantizar la concurrencia. Databricks sigue siendo el único motor de lakehouse que aporta esta capacidad a los formatos de tabla abiertos.
Tipo de dato Variant para ingesta flexible
Los datos modernos rara vez encajan perfectamente en filas y columnas. Los registros, eventos y datos de aplicaciones a menudo llegan en formato JSON. El tipo de dato Variant almacena datos semiestructurados directamente, ofreciendo un excelente rendimiento sin la necesidad de esquemas complejos o pipelines frágiles.

Usando el tipo de dato Variant en Databricks, puede cargar datos sin procesar directamente en sus tablas de lakehouse utilizando funciones de ingesta. Estas funciones admiten la carga de datos JSON, CSV y XML. Variant admite shredding, que extrae campos comunes en fragmentos separados para proporcionar un rendimiento similar al columnar. Esto acelera las consultas para pipelines de BI, paneles y alertas de baja latencia.
Variant funciona tanto en Delta como en Iceberg. Los equipos que utilizan diferentes motores pueden consultar la misma tabla, incluidas las columnas Variant, sin duplicación de datos:
“Atrás quedaron los días de los datos escalares simples, particularmente para casos de uso que requieren seguridad y registros de aplicaciones. Unity Catalog e Iceberg v3 desbloquean el poder de los datos semiestructurados a través de Variant. Esto permite la interoperabilidad y la recopilación de registros a escala de petabytes, rentable.” —Russell Leighton, Arquitecto Jefe, Panther
Avanzando en los formatos de tabla abiertos
Iceberg v3 marca un gran paso hacia la unificación de los formatos de tabla abiertos en la capa de datos. La próxima frontera es mejorar cómo los formatos gestionan y sincronizan metadatos a escala. Los esfuerzos de la comunidad, como el árbol de metadatos adaptativo introducido por primera vez en el Iceberg Summit, pueden reducir la sobrecarga de metadatos y acelerar las operaciones de tabla a escala.
A medida que estas ideas maduran, acercan a las comunidades de Delta e Iceberg, con objetivos compartidos en torno a confirmaciones más rápidas, gestión eficiente de metadatos y operaciones escalables de múltiples tablas. Databricks continúa contribuyendo a esta evolución, permitiendo a los clientes obtener el mejor rendimiento e interoperabilidad sin estar limitados por las diferencias a nivel de formato.
Pruebe Iceberg v3 hoy mismo con Databricks
Estas características de Iceberg v3 ya están disponibles en Databricks, brindando a los clientes la implementación más preparada para el futuro del estándar, respaldada por la gobernanza de Unity Catalog. Con Iceberg v3, los clientes de Databricks pueden aprovechar las mejores características tanto en tablas Delta como en Iceberg. Crear una tabla administrada por Unity Catalog con Iceberg v3 es fácil:
Comience con Unity Catalog e Iceberg v3 y únase a nosotros en los próximos eventos de Open Lakehouse + AI para obtener más información sobre nuestro trabajo en el ecosistema abierto.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.