Advancing the Lakehouse with Apache Iceberg v3 on Databricks
Databricks supports Apache Iceberg v3, giving customers a unified, high-performance, and interoperable data layer
by Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu and Aniruth Narayanan
• Databricks supports Apache Iceberg v3, so customers can run interoperable, governed workloads on a single copy of data
• With Iceberg v3, deletion vectors, row-level lineage, and the Variant data type are now available on all managed tables
• With these features, Databricks brings the Data Intelligence Platform to all formats for the best performance
Databricks supports Apache Iceberg v3 in the Data Intelligence Platform, giving customers a unified and open data layer with best-in-class performance, interoperability, and governance.
With this release, Databricks customers running Iceberg workloads can now take advantage of v3 features, including deletion vectors, row-level lineage, and the Variant data type. These features allow teams to run modern workloads efficiently and consistently across platforms. These features also work seamlessly across both Delta and Iceberg tables, enabling interoperability without rewriting data.

This release strengthens Databricks’ commitment to open standards and helps customers build on the lakehouse foundation of Delta Lake, Apache Iceberg, Apache Parquet, and Apache Spark, all with full governance and flexibility.
In this blog, we’ll explore:
- A unified data layer with Iceberg v3
- Efficient Iceberg v3 workloads on Databricks
- Advancing open table formats
A unified data layer with Iceberg v3
Delta Lake and Apache Iceberg have become the foundation of the modern lakehouse, each with strong capabilities for reliability, governance, and scalable data management. They both use metadata files to track Parquet data files and row-level deletes. However, minor differences between the formats in these data and delete files often forced organizations to pick a format and its features, usually based on which data platforms they used. This choice was often irreversible, since rewriting petabytes of data is impractical.
Iceberg v3 closes this gap. It introduces features that align closely with Delta and the broader open ecosystem, such as Parquet and Spark, allowing teams to use a single copy of data with consistent behavior and performance across formats.
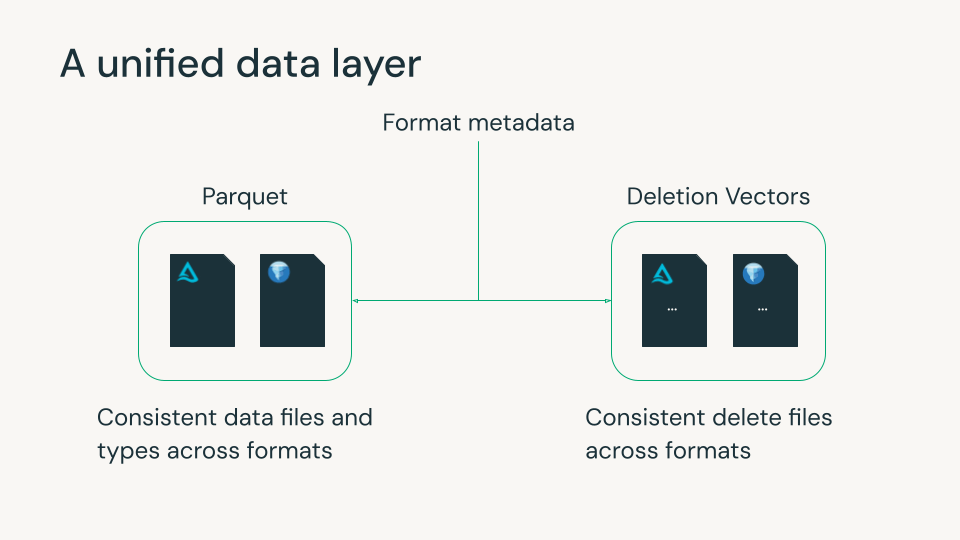
Databricks has long believed that the future of the lakehouse is optionality without fragmentation. Our contributions to Iceberg v3 reflect that commitment: helping unify core table behaviors so customers can use the engines and tools they prefer while governing everything consistently with Unity Catalog.
Efficient Iceberg v3 workloads on Databricks
With Iceberg v3, Databricks brings features of the Data Intelligence Platform to all Unity Catalog managed tables.
Deletion vectors for faster updates
Deletion vectors enable deleting or updating rows without rewriting Parquet files. Instead, deletes are stored as separate files and merged during reads. Most data engineering workloads modify only a few rows at a time, making this a critical feature for efficient writes.

You can now take advantage of Databricks’ best-in-class ETL price-performance to run Iceberg workloads using deletion vectors. Compared to regular MERGE statements, deletion vectors can speed up updates by up to 10x. Iceberg engines can read and write to managed Iceberg tables using Unity Catalog’s Iceberg REST Catalog APIs. As Geodis notes:
“Now that Deletion Vectors have come to Iceberg, we can centralize our Iceberg data estate in Unity Catalog, while leveraging the engine of our choice and maintaining best-in-class performance.” —Delio Amato, Chief Architect & Data Officer, Geodis
Row lineage for row-level concurrency
Row lineage gives each row a unique ID, making it easy to track changes over time. Row lineage is required for all Iceberg v3 tables.
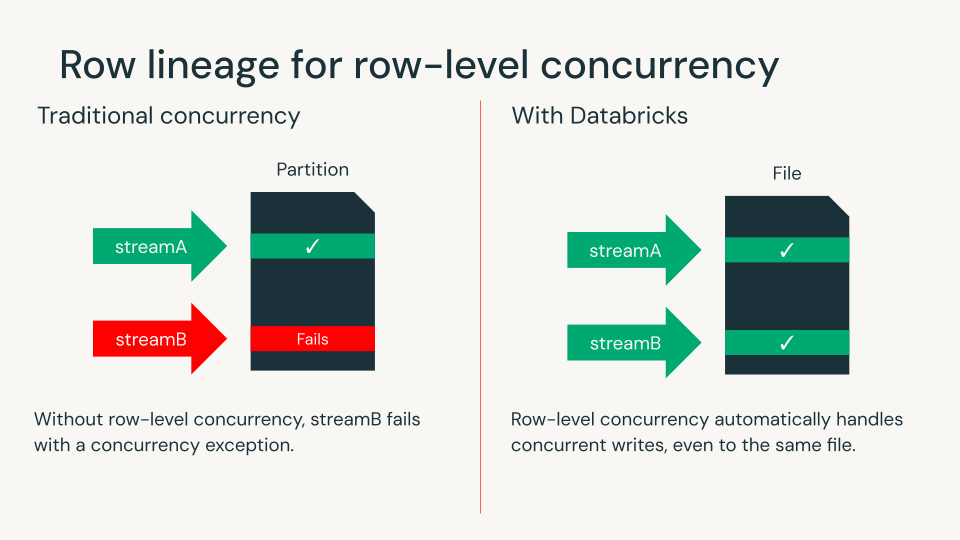
With deletion vectors and row lineage, Databricks customers can now use row-level concurrency to detect write conflicts at the row level. This eliminates the need to design complex data layouts or coordinate workloads to ensure concurrency. Databricks remains the only lakehouse engine that brings this capability to open table formats.
Variant data type for flexible ingestion
Modern data rarely fits neatly into rows and columns. Logs, events, and application data often arrive in JSON format. The Variant data type stores semi-structured data directly, offering excellent performance without the need for complex schemas or brittle pipelines.

Using the Variant data type in Databricks, you can land raw data directly into your lakehouse tables using ingestion functions. These functions support loading JSON, CSV, and XML data. Variant supports shredding, which extracts common fields into separate chunks to provide columnar-like performance. This speeds up queries for low-latency BI, dashboards, and alerting pipelines.
Variant works across both Delta and Iceberg. Teams using different engines can query the same table, including the Variant columns, without data duplication:
“Gone are the days of simple scalar data, particularly for use cases that require security and application logs. Unity Catalog and Iceberg v3 unlock the power of semi-structured data through Variant. This enables interoperability and cost-effective, petabyte-scale log collection.” —Russell Leighton, Chief Architect, Panther
Advancing open table formats
Iceberg v3 marks a major step toward unifying open table formats across the data layer. The next frontier is improving how formats manage and synchronize metadata at scale. Community efforts, such as the adaptive metadata tree first introduced at the Iceberg Summit, can reduce metadata overhead and accelerate table operations at scale.
As these ideas mature, they bring the Delta and Iceberg communities closer together, with shared goals around faster commits, efficient metadata management, and scalable multi-table operations. Databricks continues to contribute to this evolution, enabling customers to get the best performance and interoperability without being constrained by format-level differences.
Try Iceberg v3 Today with Databricks
These Iceberg v3 features are now available on Databricks, providing customers with the most future-ready implementation of the standard, backed by the governance of Unity Catalog. With Iceberg v3, Databricks customers can leverage the best features across Delta and Iceberg tables. Creating a Unity Catalog managed table with Iceberg v3 is easy:
Get started with Unity Catalog and Iceberg v3 and join us at upcoming Open Lakehouse + AI events to learn more about our work across the open ecosystem.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.