Introducing Variant: A New Open Standard for Semi-Structured Data in Apache Parquet™, Delta Lake, and Apache Iceberg™
by Gene Pang, David Cashman, Ryan Blue and Aniruth Narayanan
- Variant, the native data type for semi-structured data, is now ratified in the Apache Parquet™ community with support across Delta Lake, Apache Iceberg™, and Apache Spark™
- Shredding, a technique to columnarize commonly occurring fields in Variant data, improves read performance 8x compared to using regular Variant and 30x compared to using string
- Variant shredding is supported in Databricks with DBR 17.2+ (DBSQL 2025.30+), with functions to easily ingest from JSON, CSV, and XML sources
Semi-structured data is everywhere in AI, application logs, and telemetry. This data is useful, but changing schemas makes it challenging to store and query. For years, the standard practice was to store this data as strings. Strings were flexible but had poor query performance, since the engine needed to parse and search through the entire string.
The Variant data type, now ratified in Apache Parquet™, takes a different approach. It stores the data in a compact binary format that is both flexible and performant for querying. This approach isn’t tied to one engine or format - Variant is the open standard for semi-structured data across the lakehouse, with support in Apache Spark™, Delta Lake, and Apache Iceberg™.
In this blog post, we will cover:
- Investing in Variant open standards
- How Variant and shredding work
- Fast performance on semi-structured data
Databricks is leading Variant efforts in open source
Last year, we collaborated with the open source community to introduce Variant to Apache Spark™ and Delta Lake. This new data type offers both flexibility and performance compared to storing semi-structured data as strings (which have poor performance) or structs (which are not flexible).
Variant’s launch quickly drew interest from other major open source projects, including Apache Iceberg™ and Apache Arrow™. To unify the ecosystem, we proposed bringing Variant to all engines and formats by incorporating the type directly into Parquet and moving the Spark implementation to the Parquet-java open source project, contributing over 9,600 lines of code. This allows all open table formats to easily leverage the Variant data type.
Now that Variant has been approved within the Parquet community, the entire lakehouse ecosystem has a standard, open data type for semi-structured data. Variant is already supported in open table formats: Delta has included Variant support for the past year, and last May, Iceberg approved v3, which includes Variant support. Consequently, users leveraging Delta or Iceberg can now benefit from Variant’s flexibility and performance.
The Parquet Variant artifacts include:
- Variant Binary Encoding Specification
- Variant Shredding Specification (a technique to store Variant data more efficiently)
- Parquet Release Version 2.12.0 with the Parquet Java implementation 1.16.0
The Delta and Iceberg Protocols to support Variant are:
We extend our gratitude to all the individuals and organizations involved for their contributions across many open source communities, including Apache Parquet™, Apache Spark™, Apache Iceberg™, Delta Lake, and Apache Arrow™.
How Variant and shredding work
Variant uses a binary encoding format to provide a flexible interface for data storage. Variant also has a shredding scheme, a technique for storing Variant more efficiently to improve performance.
Binary encoding format
The Variant datatype leverages an efficient binary encoding scheme to represent semi-structured data. Instead of storing the data as a plain-text value (like JSON), the Variant data encodes the values and the structure in a binary format that prioritizes efficient navigation.
Navigating a JSON string requires reading and processing the entire JSON object to find the relevant field. With the Variant binary encoding, the structure of the data is encoded using offsets to other locations within the Variant value. With these offsets, navigating through the Variant structure does not require reading or processing the entire value. This offset-based navigation greatly improves the performance of processing semi-structured data.
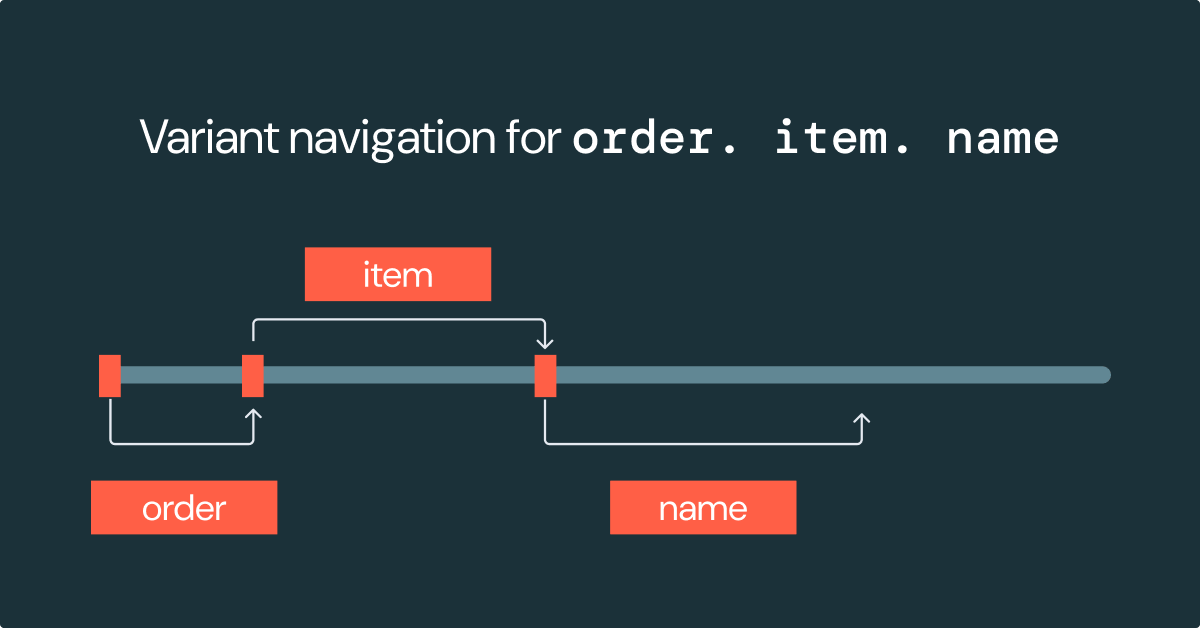
This example demonstrates that navigating to the path order.item.name requires examining only a few portions of the Variant value using the offsets. This reduces the amount of data to process/parse, and leads to faster performance.
Shredding
Shredding automatically extracts common fields from the Variant values. These fields are stored as separate, typed chunks in the same column. Without shredding, the entire Variant value is stored as a single "binary blob" in the file.
There are several performance advantages for shredding Variants:
- Pruned I/O: When fields are stored separately, only the fields required by the query need to be fetched. That means if the query only requires a small fraction of the Variant fields, only a small fraction of the I/O is required.
- Data skipping: When shredded fields are stored as separate Parquet chunks, engines can use all the Parquet optimizations for efficient row group and column page skipping.
- Compression: Since shredded fields are columnar, the data can be compressed more efficiently, thus reducing the storage size.
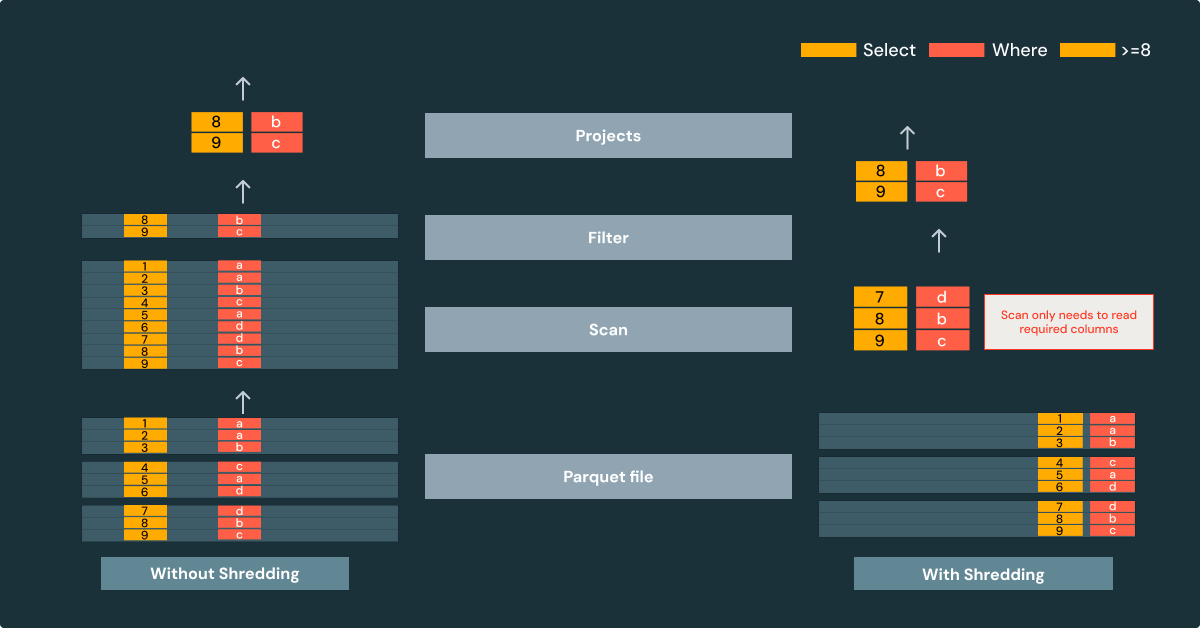
This example demonstrates that with shredding, the scan only needs to read the columns required by the query. The scan uses Parquet column statistics, so irrelevant row-groups can be completely skipped. Reading shredded files improves performance by avoiding unnecessary work.
Fast performance on semi-structured data
The Variant binary format and shredding technique enable significant performance improvements compared to storing semi-structured data as JSON strings. We conducted performance benchmarks using semi-structured data based on TPC-DS to compare Variant and string representations.

Compared to storing JSON as a string, Variant has 8x faster read performance. With shredding, Variant writes are 20% to 50% slower, but reads are 30x faster - demonstrating its performance and efficiency.
Try Variant Today
With native Parquet, Delta, and Iceberg support, the Variant datatype is the open and standardized data type for semi-structured data. By eliminating the need for complex ETL and brittle parsing, Variant empowers users to analyze data fast, easily, and reliably.
Creating a table with a Variant column is easy:
To load Variant data, Databricks supports Variant ingestion functions from JSON, XML, and CSV:
Variant shredding is supported in DBR 17.2+ (DBSQL 2025.30+) with support in Delta and Iceberg tables. This improves query performance without code changes:
Stay tuned for our follow-up post on Variant, where we’ll walk through practical examples and share customer stories.
The focus on performance, simplicity, and value is the foundation of Databricks SQL, where the best data warehouse is a lakehouse. To learn more about Databricks SQL, visit our website, read the documentation, or check out the product tour. Databricks SQL is the high-performance, lower-cost, and serverless data warehouse — try it for free today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.