Seguridad de IA agentiva: Nuevos riesgos y controles en el Marco de Seguridad de IA de Databricks (DASF v3.0)
35 nuevos riesgos de IA agentic y 6 controles de mitigación para agentes que acceden a datos, llaman a herramientas y ejecutan acciones
por David Veuve, Omar Khawaja, Arun Pamulapati, Nishith Sinha y Caelin Kaplan
- El Marco de Seguridad de IA de Databricks (DASF) ahora cubre la IA Agentic como su decimotercer componente del sistema, agregando 35 nuevos riesgos técnicos de seguridad y 6 nuevos controles de mitigación para ayudar a las organizaciones a implementar agentes autónomos con confianza.
- Esta extensión aborda los riesgos únicos de la memoria, la planificación y el uso de herramientas de los agentes, incluidas las amenazas introducidas por el Protocolo de Contexto del Modelo (MCP), el estándar emergente para conectar agentes a herramientas empresariales.
- El documento técnico de la Extensión de IA Agentic del DASF y el compendio actualizado ya están disponibles. Descárguelos para evaluar sus arquitecturas de agentes, mapear sus ecosistemas de herramientas e implementar controles de defensa en profundidad diseñados específicamente para la autonomía.
¡Nos complace anunciar el lanzamiento del whitepaper Databricks AI Security Framework (DASF) Agentic AI Extension! Los clientes de Databricks ya están implementando agentes de IA que consultan bases de datos, llaman a APIs externas, ejecutan código y se coordinan con otros agentes. Constantemente escuchamos que los equipos responsables de esas implementaciones se hacen preguntas difíciles: ¿qué sucede cuando la IA puede hacer cosas, no solo decir cosas? Es por eso que hemos ampliado DASF.
Con esta actualización, presentamos nueva orientación para proteger agentes de IA autónomos:
- 35 nuevos riesgos de seguridad de IA agentiva que cubren el razonamiento, la memoria y el uso de herramientas del agente
- 6 nuevos controles de mitigación que incluyen el mínimo privilegio, el sandboxing y la supervisión humana
- Orientación de seguridad para servidores y clientes de herramientas del Protocolo de Contexto de Modelo (MCP)
- Cobertura de riesgos de sistemas multiagente y amenazas de comunicación entre agentes
En conjunto, estas adiciones ayudan a las organizaciones a implementar agentes de IA de forma segura mientras mantienen la gobernanza, la observabilidad y los controles de seguridad de defensa en profundidad.
Esto eleva el marco completo a 97 riesgos y 73 controles. Hemos actualizado el compendio DASF (hoja de Google, Excel) para incluir estos nuevos riesgos y controles, mapeándolos a estándares de la industria para facilitar la operacionalización inmediata. Estas adiciones están catalogadas como DASF v3.0 bajo la columna "DASF Revision".
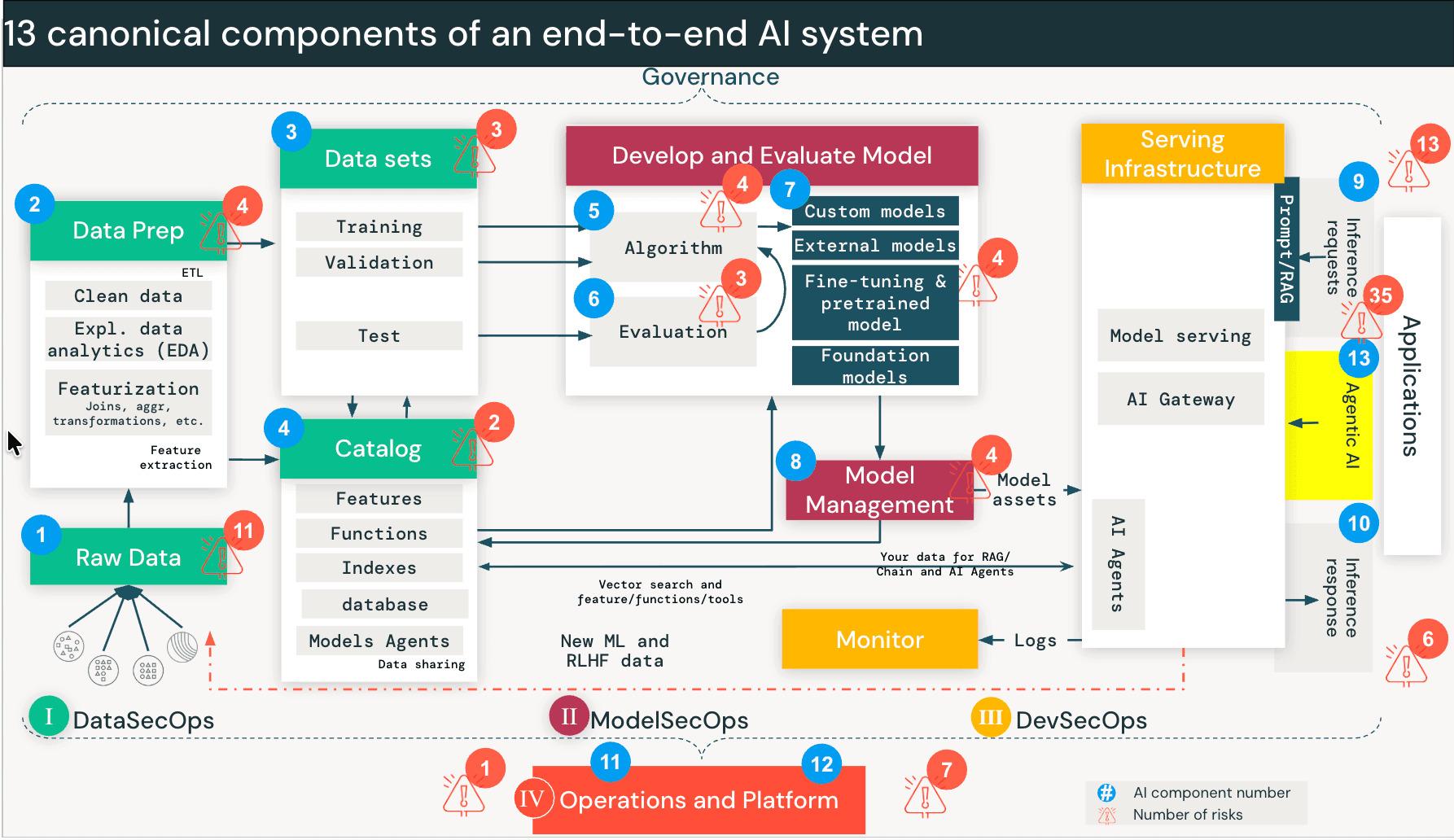
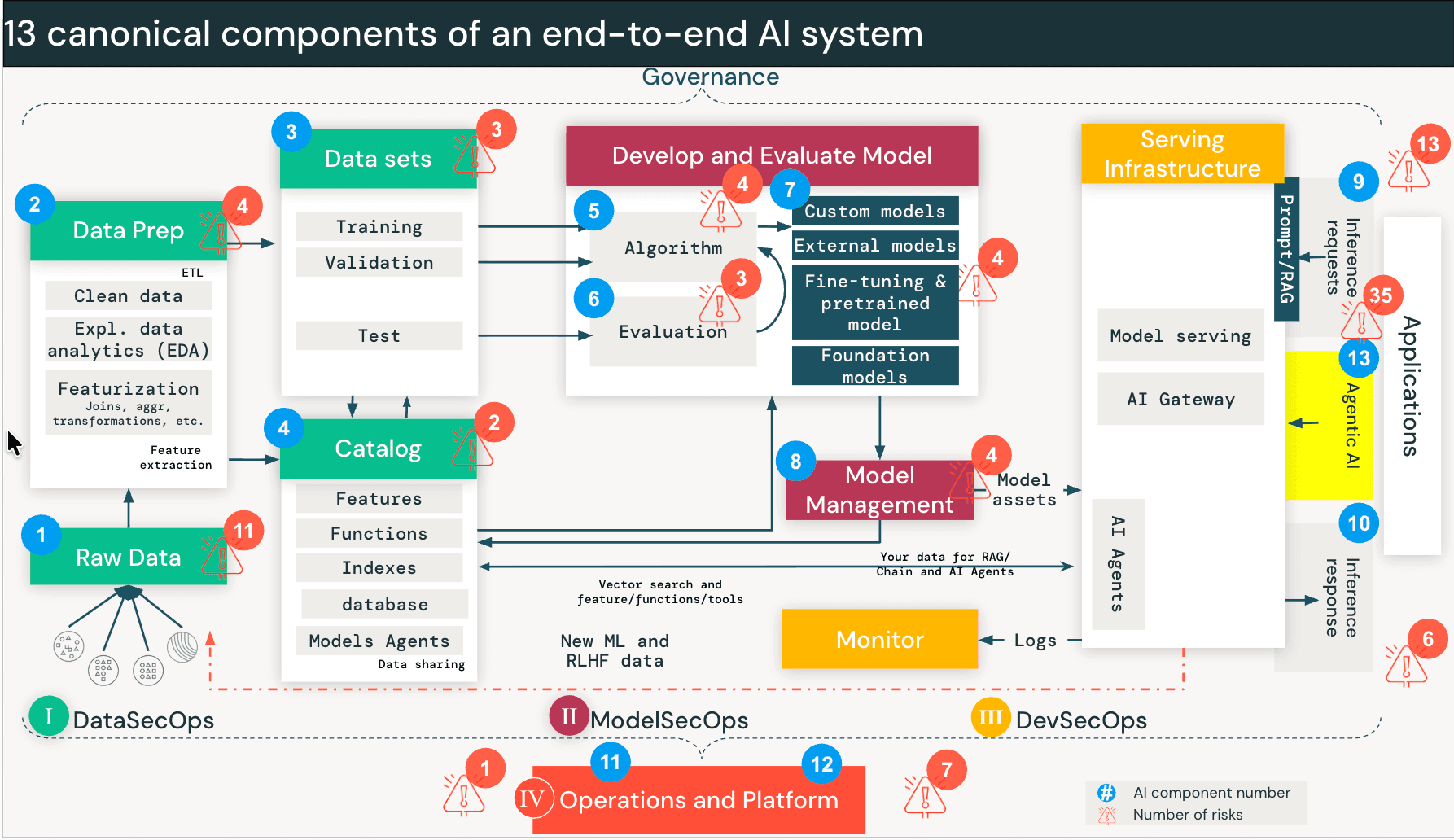{kind=link}
Riesgos de seguridad cuando los agentes de IA pueden tomar acciones
Los sistemas de IA tradicionales como RAG operan principalmente en modo de solo lectura. Pero los agentes de IA pueden tomar acciones como consultar bases de datos, llamar a APIs, ejecutar código e interactuar con herramientas externas.
Los agentes funcionan de manera diferente. Cuando un usuario interactúa con un agente, el modelo inicia un bucle: divide la solicitud en subtareas, elige una herramienta (por ejemplo, "Consultar Base de Datos de Ventas"), la ejecuta, evalúa el resultado y decide si llamar a otra herramienta a continuación. Esto continúa hasta que se completa la tarea. El agente está tomando decisiones en tiempo real sobre a qué datos acceder y qué herramientas invocar, decisiones que antes tomaban los humanos o que estaban codificadas en la lógica de la aplicación.
Eso crea una nueva clase de riesgo que llamamos Descubrimiento y Recorrido. Un agente diseñado para encontrar soluciones recorrerá rutas de datos e interfaces de herramientas que nunca fueron destinadas al usuario solicitante. No está explotando un error. Está haciendo exactamente para lo que fue construido. Pero sin los controles adecuados, el usuario hereda efectivamente los permisos del agente en lugar de los suyos propios.
La Trifecta Letal. Investigaciones recientes de la industria, incluido el artículo de Meta “Agents Rule of Two” y modelos similares como el de Simon Willison “Lethal Trifecta”, resaltan las condiciones bajo las cuales esto se vuelve peligroso. El perfil de riesgo se dispara cuando tres condiciones están presentes simultáneamente:
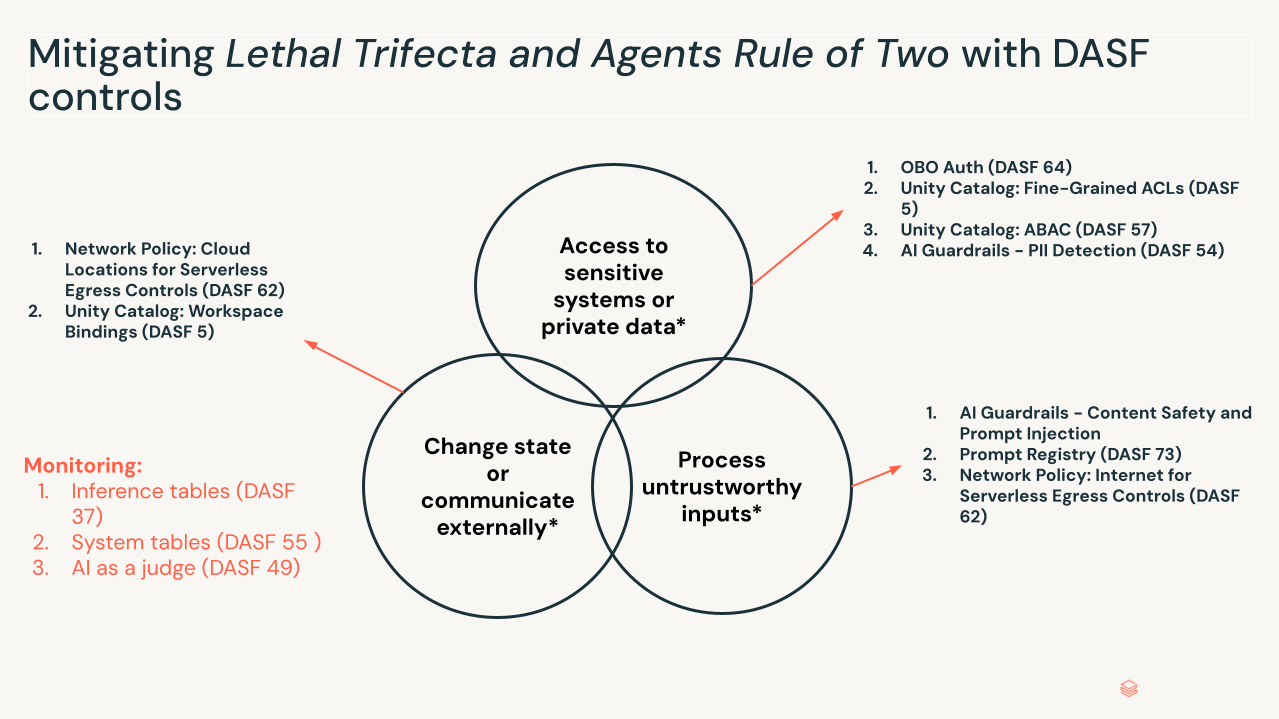
- Acceso a sistemas sensibles o datos privados: El agente puede recuperar datos privados o restringidos.
- Procesar entradas no confiables: El agente procesa datos de fuera del límite de confianza: indicaciones del usuario, sitios web externos, correos electrónicos entrantes.
- Cambiar estado o comunicarse externamente: El agente puede modificar el estado a través de herramientas o conexiones MCP: enviar correos electrónicos, ejecutar SQL, modificar código.
Con las tres presentes, una inyección de indicaciones indirecta incrustada en datos no confiables puede secuestrar el conjunto completo de capacidades del agente, convirtiéndolo en un "delegado confundido" que realiza acciones autorizadas con intenciones maliciosas. Elimine cualquier pata individual limitando los permisos, agregando un punto de control humano, validando la intención antes de la selección de herramientas y rompiendo la cadena de ataque.
Cómo está organizada la extensión
Los 35 nuevos riesgos y 6 controles están organizados en torno a tres subcomponentes que se mapean a cómo funcionan realmente los agentes:
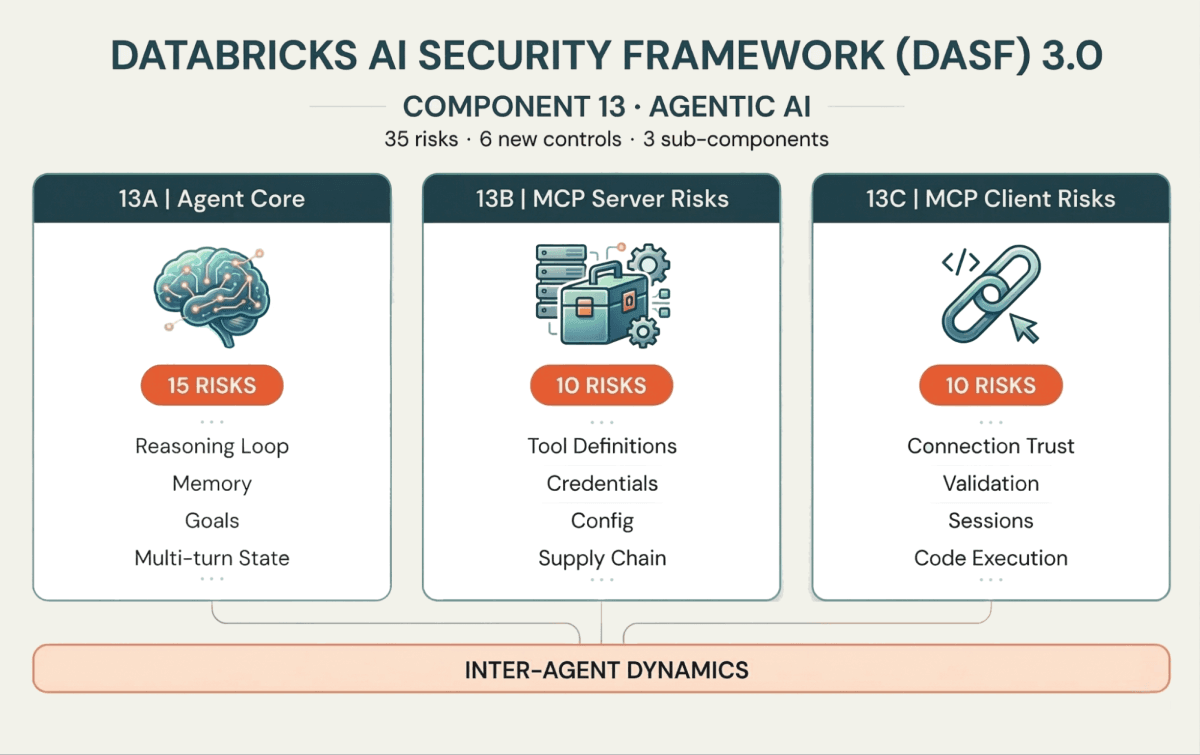
13A: El Núcleo del Agente (cerebro y memoria)
Estos riesgos apuntan al bucle de razonamiento del agente. El Envenenamiento de Memoria (Riesgo 13.1) introduce contexto falso que altera las decisiones actuales o futuras. La Ruptura de Intención y Manipulación de Objetivos (Riesgo 13.6) coacciona al agente para que se desvíe de su objetivo. Y dado que los agentes operan en bucles de múltiples turnos, los Ataques de Alucinación en Cascada (Riesgo 13.5) pueden agravar un error menor a lo largo de las iteraciones hasta convertirlo en una acción destructiva.
13B: Riesgos del Servidor MCP (la interfaz de herramientas)
Los agentes interactúan con sistemas externos a través de herramientas, cada vez más estandarizadas a través del Protocolo de Contexto de Modelo (MCP). En el lado del servidor, los atacantes pueden implementar el Envenenamiento de Herramientas (Riesgo 13.18) —injetando comportamiento malicioso en las definiciones de herramientas— o explotar la Inyección de Indicaciones (Riesgo 13.16) dentro de las descripciones de herramientas para eludir los controles de seguridad.
13C: Riesgos del Cliente MCP (la capa de conexión)
En el lado del cliente, si el agente se conecta a un Servidor Malicioso (Riesgo 13.26) o no valida las respuestas del servidor, corre el riesgo de Ejecución de Código del Lado del Cliente (Riesgo 13.32) o Fuga de Datos (Riesgo 13.30). A medida que aumenta la adopción de MCP, la protección del límite cliente-servidor es tan importante como la protección del razonamiento del agente.
Dinámicas entre agentes
Los agentes se comunicarán cada vez más entre sí. Eso crea riesgos de Envenenamiento de Comunicación de Agentes (Riesgo 13.12) y Agentes Traviesos en Sistemas Multiagente (Riesgo 13.13) —agentes que operan fuera de los límites de monitoreo, un problema que se agrava con la escala.
Controles para proteger agentes de IA y sistemas autónomos
DASF siempre ha tratado sobre defensa en profundidad. Pero cuando un sistema de IA puede tomar acciones, los controles de acceso de solo lectura no son suficientes. Los nuevos controles abordan esto directamente:
- Mínimo privilegio para herramientas (DASF 5, DASF 57, DASF 64): Los agentes necesitan permisos granulares limitados a su tarea inmediata, lo que limita el radio de explosión de la misma manera que RBAC y ABAC limitan el de un humano. Que un agente pueda llamar a la Herramienta de Métricas de RRHH no significa que deba hacerlo al responder una consulta de ventas.
- Supervisión humana en el bucle (DASF 66): Para acciones de alto riesgo, se requiere verificación humana antes de la ejecución de la herramienta. El diseño del control tiene en cuenta la fatiga de aprobación: si abrumas al revisor humano, has creado una nueva vulnerabilidad, no has resuelto una.
- Sandboxing y aislamiento (DASF 34, DASF 62): El código generado por el agente se ejecuta en entornos efímeros y aislados. Si un agente decide escribir y ejecutar un script, esa ejecución no debería tener acceso al sistema en general ni a las conexiones salientes a destinos desconocidos.
- Puerta de enlace y barreras de IA (DASF 54): Los agentes necesitan protecciones contra escenarios en los que un agente está siendo manipulado para mostrar datos que no debería. Las interacciones de los agentes a través de la puerta de enlace y las barreras, como el monitoreo, el filtrado de seguridad y la detección de PII, deben aplicarse. Estas barreras se pueden aplicar tanto a la entrada como a la salida de un agente (o a ambas). También es igualmente importante monitorear lo que realmente devuelve el agente.
- Observabilidad del pensamiento (DASF 65): El registro estándar te dice lo que sucedió. El rastreo agentivo captura el por qué: los pasos de planificación, el razonamiento de selección de herramientas, la cadena de pensamiento que condujo a una acción. Sin esto, no puedes auditar las decisiones de un agente ni detectar cuándo su razonamiento ha sido comprometido.
Para los clientes de Databricks, el compendio mapea estos controles a las capacidades de la plataforma, incluyendo la gobernanza de Unity Catalog para el acceso a datos de agentes, el Agent Bricks Framework, las salvaguardas de AI Gateway y la configuración de seguridad de AI Search.
Construido con la comunidad
Esta extensión refleja los aportes de revisores y colaboradores de Databricks y la comunidad de seguridad, incluyendo equipos de Atlassian, Experian y ComplyLeft. También nos basamos en gran medida en el trabajo de MITRE ATLAS, OWASP, NIST y la Cloud Security Alliance; el compendio actualizado mapea los 97 riesgos y 73 controles a estos estándares de la industria.
Comienza
Descarga el documento técnico DASF Agentic AI Extension para el tratamiento completo de los 35 nuevos riesgos de IA de agentes y 6 nuevos controles, y obtén el compendio actualizado (Google Sheet, Excel) que ahora mapea los riesgos y controles de agentes junto con el DASF original. Utiliza estos recursos para:
- Evalúa tus arquitecturas de agentes actuales contra el modelo de riesgo de IA de agentes.
- Mapea tus ecosistemas de herramientas — incluyendo servidores y clientes MCP — a los vectores de amenaza identificados.
- Implementa los controles recomendados para asegurar que tus agentes operen dentro de límites seguros y gobernados.
Para un contexto más profundo, lee el documento técnico completo DASF y explora la documentación del Agent Bricks Framework para ver cómo funcionan estos controles en la plataforma.
Ponte en contacto con tu equipo de cuentas de Databricks o envíanos un correo electrónico a dasf@databricks.com con tus comentarios; este marco pertenece tanto a la comunidad como a nosotros.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.