Anuncio de Agrupación Líquida Automática
Diseño de datos optimizado para consultas hasta 10 veces más rápidas
por Cindy Jiang, Supun Nakandala, Naga Raju Bhanoori, Eric Liang y Parimarjan Negi
- La agrupación líquida automática, impulsada por Optimización Predictiva, automatiza la selección de claves de agrupación para mejorar continuamente el rendimiento de las consultas y reducir los costos.
- Los procesos de selección robustos y la monitorización continua mantienen las tablas optimizadas.
- El TCO se minimiza evaluando automáticamente si las mejoras de rendimiento compensan los costos.
Nos complace anunciar la Vista Previa Pública de Clústeres Líquidos Automáticos, impulsada por Optimización Predictiva. Esta característica aplica y actualiza automáticamente las columnas de Clústeres Líquidos en tablas administradas de Unity Catalog, mejorando el rendimiento de las consultas y reduciendo los costos.
Los Clústeres Líquidos Automáticos simplifican la administración de datos al eliminar la necesidad de ajustes manuales. Anteriormente, los equipos de datos debían diseñar manualmente la disposición específica de los datos para cada una de sus tablas. Ahora, la Optimización Predictiva aprovecha el poder de Unity Catalog para monitorear y analizar sus datos y patrones de consulta.
Para habilitar los Clústeres Líquidos Automáticos, configure sus tablas no particionadas o de Clústeres Líquidos administradas por UC estableciendo el parámetro CLUSTER BY AUTO.
Una vez habilitada, la Optimización Predictiva analiza cómo se consultan sus tablas y selecciona de forma inteligente las claves de clúster más efectivas según su carga de trabajo. Luego, agrupa la tabla automáticamente, asegurando que los datos estén organizados para un rendimiento óptimo de las consultas. Cualquier motor que lea de la tabla Delta se beneficia de estas mejoras, lo que resulta en consultas significativamente más rápidas. Además, a medida que cambian los patrones de consulta, la Optimización Predictiva ajusta dinámicamente el esquema de clústeres, eliminando por completo la necesidad de ajustes manuales o decisiones de diseño de datos al configurar sus tablas Delta.
Durante la Vista Previa Privada, docenas de clientes probaron los Clústeres Líquidos Automáticos y obtuvieron excelentes resultados. Muchos apreciaron su simplicidad y las mejoras de rendimiento, y algunos ya lo están utilizando para sus tablas de oro y planean expandirlo a todas las tablas Delta.
Los clientes en vista previa como Healthrise han reportado mejoras significativas en el rendimiento de las consultas con Clústeres Líquidos Automáticos:
“Hemos implementado Clústeres Líquidos Automáticos en todas nuestras tablas de oro. Desde entonces, nuestras consultas se ejecutaron hasta 10 veces más rápido. Todas nuestras cargas de trabajo se han vuelto mucho más eficientes sin ningún trabajo manual necesario en el diseño de la disposición de los datos o la ejecución de mantenimiento.” —Li Zou, Ingeniero Principal de Datos, Brian Allee, Director de Servicios de Datos | Tecnología y Analítica, Healthrise
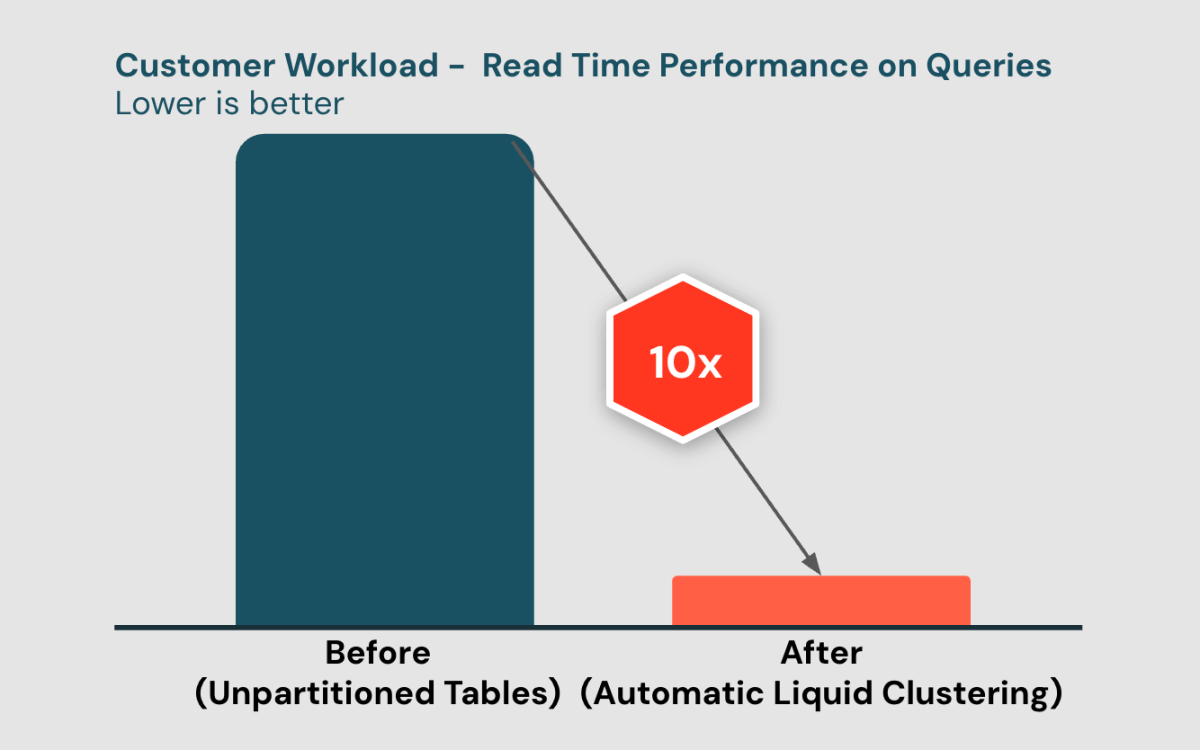
Elegir la mejor disposición de datos es un problema difícil
Aplicar la mejor disposición de datos a sus tablas mejora significativamente el rendimiento de las consultas y la eficiencia de costos. Tradicionalmente, con la partición, los clientes han encontrado difícil diseñar la estrategia de partición correcta para evitar desajustes de datos y conflictos de concurrencia. Para mejorar aún más el rendimiento, los clientes pueden usar ZORDER además de la partición, pero ZORDER es costoso y aún más complicado de administrar.
Clústeres Líquidos simplifica significativamente las decisiones relacionadas con la disposición de datos y proporciona la flexibilidad para redefinir las claves de clúster sin reescrituras de datos. Los clientes solo tienen que elegir las claves de clúster puramente en función de los patrones de acceso a las consultas, sin tener que preocuparse por la cardinalidad, el orden de las claves, el tamaño de los archivos, los posibles desajustes de datos, la concurrencia y los cambios futuros en los patrones de acceso. Hemos trabajado con miles de clientes que se beneficiaron de un mejor rendimiento de las consultas con Clústeres Líquidos, y ahora tenemos más de 3000 clientes activos mensuales que escriben más de 200 PB de datos en tablas con clústeres líquidos por mes.
Sin embargo, incluso con los avances en Clústeres Líquidos, aún debe elegir las columnas para agrupar según cómo consulta su tabla. Los equipos de datos deben averiguar:
- ¿Qué tablas se beneficiarán de los Clústeres Líquidos?
- ¿Cuáles son las mejores columnas de clúster para esta tabla?
- ¿Qué pasa si mis patrones de consulta cambian a medida que evolucionan las necesidades del negocio?
Además, dentro de una organización, los ingenieros de datos a menudo tienen que trabajar con múltiples consumidores descendentes para comprender cómo se consultan las tablas, al mismo tiempo que se mantienen al día con los patrones de acceso cambiantes y los esquemas en evolución. Este desafío se vuelve exponencialmente más complejo a medida que su volumen de datos escala con más necesidades analíticas.
Cómo los Clústeres Líquidos Automáticos evolucionan su Disposición de Datos
Con Clústeres Líquidos Automáticos, Databricks se encarga de todas las decisiones relacionadas con la disposición de datos por usted, desde la creación de tablas hasta la agrupación de sus datos y la evolución de la disposición de sus datos, lo que le permite concentrarse en extraer información de sus datos.
Veamos los Clústeres Líquidos Automáticos en acción con una tabla de ejemplo.
Considere una tabla example_tbl, que se consulta con frecuencia por fecha y ID de cliente. Contiene datos de 5-6 de febrero y IDs de cliente de la A a la F. Sin ninguna configuración de disposición de datos, los datos se almacenan en orden de inserción, lo que resulta en la siguiente disposición:
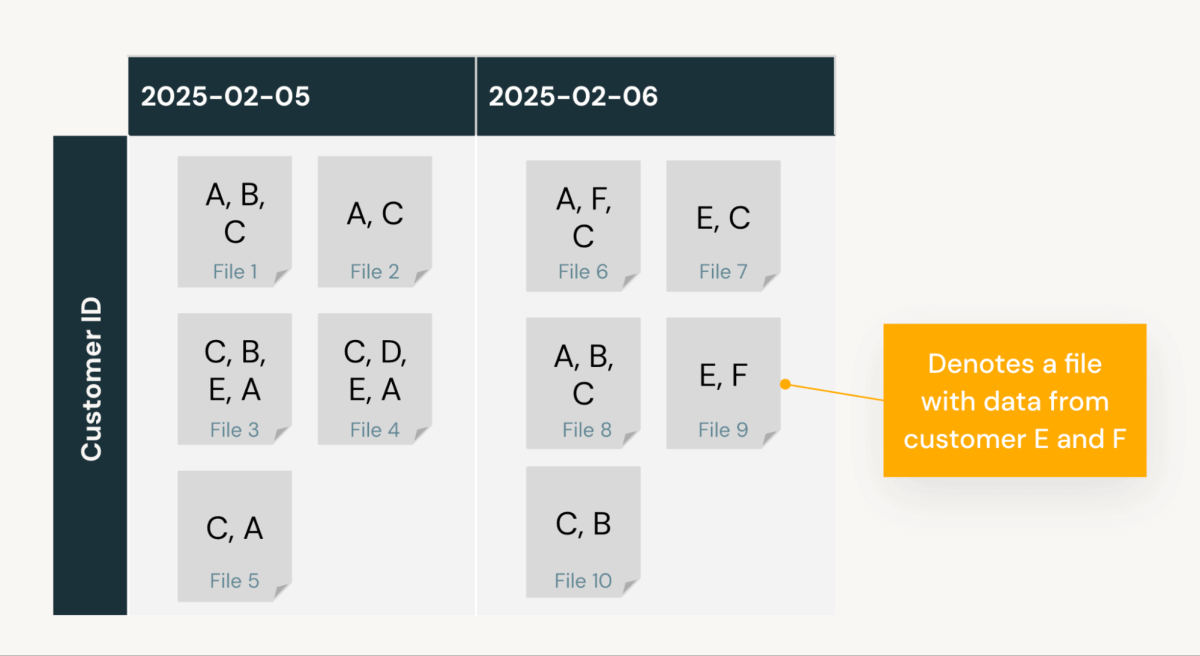
Suponga que el cliente ejecuta SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'. El motor de consulta aprovecha las estadísticas de omisión de datos de Delta (valores min/max, recuentos nulos y registros totales por archivo) para identificar los archivos relevantes a escanear. La eliminación de lecturas de archivos innecesarias es crucial, ya que reduce la cantidad de archivos escaneados durante la ejecución de la consulta, lo que mejora directamente el rendimiento de la consulta y reduce los costos de cómputo. Cuantos menos archivos necesite leer una consulta, más rápida y eficiente será.
En este caso, el motor identifica 5 archivos para el 5 de febrero, ya que la mitad de los archivos tienen un valor min/max para la columna fecha que coincide con esa fecha. Sin embargo, dado que las estadísticas de omisión de datos solo proporcionan valores min/max, estos 5 archivos tienen un customer_id min/max que sugiere que el cliente B está en algún lugar intermedio. Como resultado, la consulta debe escanear los 5 archivos para extraer las entradas del cliente B, lo que genera una tasa de omisión de archivos del 50% (leyendo 5 de 10 archivos).

Como ve, el problema principal es que los datos del cliente B no están colocados en el mismo archivo. Esto significa que extraer todas las entradas para el cliente B también requiere leer una cantidad significativa de entradas para otros clientes.
¿Hay alguna forma de mejorar la omisión de archivos y el rendimiento de las consultas aquí? Los Clústeres Líquidos Automáticos pueden mejorar ambos. Aquí le explicamos cómo:
Detrás de Escena de los Clústeres Líquidos Automáticos: Cómo Funciona
Una vez habilitado, los Clústeres Líquidos Automáticos realizan continuamente los siguientes tres pasos:
- Recopilación de telemetría para determinar si la tabla se beneficiará de introducir o evolucionar las Claves de Clústeres Líquidos.
- Modelado de la carga de trabajo para comprender e identificar las columnas elegibles.
- Aplicación de la selección de columnas y evolución de los esquemas de clústeres basada en el análisis de costo-beneficio.

Paso 1: Análisis de Telemetría
La Optimización Predictiva recopila y analiza estadísticas de escaneo de consultas, como predicados de consulta y filtros JOIN, para determinar si una tabla se beneficiaría de Clústeres Líquidos.
Con nuestro ejemplo, la Optimización Predictiva detecta que las columnas 'fecha' y 'customer_id' se consultan con frecuencia.
Paso 2: Modelado de Carga de Trabajo
La Optimización Predictiva evalúa la carga de trabajo de la consulta e identifica las mejores claves de clúster para maximizar la omisión de datos.
Aprende de los patrones de consulta pasados y estima las ganancias de rendimiento potenciales de diferentes esquemas de clústeres. Al simular consultas pasadas, predice qué tan efectivamente cada opción reduciría la cantidad de datos escaneados.
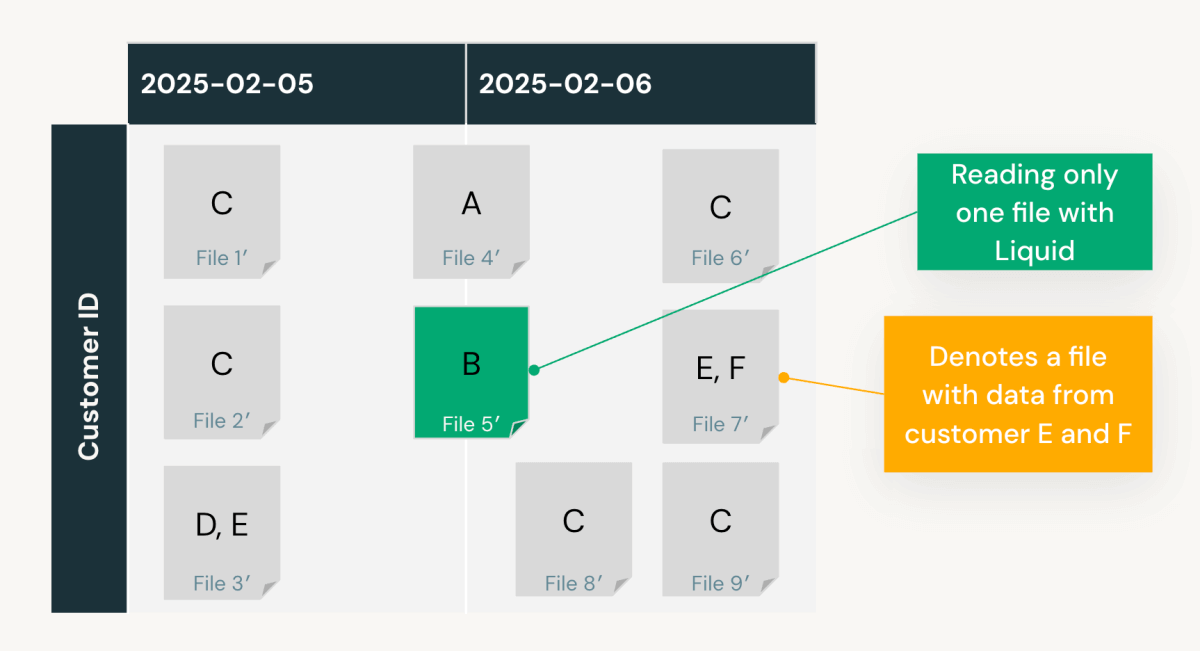
En nuestro ejemplo, al usar escaneos registrados en ‘date’ y ‘customer_id’ y asumiendo consultas consistentes, Predictive Optimization calcula que:
- Agrupar por
‘date’lee 5 archivos con tasas de poda del 50%. - Agrupar por
‘customer_id’, lee ~2 archivos (una estimación) con una tasa de poda del 80%.- Agrupar por
‘date’y‘customer_id’(ver diseño de datos a continuación) lee solo 1 archivo con una tasa de poda del 90%.
- Agrupar por

Paso 3: Optimización de costo-beneficio
La Plataforma Databricks asegura que cualquier cambio en las claves de agrupación proporcione un beneficio claro en el rendimiento, ya que la agrupación puede introducir sobrecarga adicional. Una vez identificados los candidatos para nuevas claves de agrupación, Predictive Optimization evalúa si las ganancias de rendimiento superan los costos. Si los beneficios son significativos, actualiza las claves de agrupación en las tablas administradas por Unity Catalog.
En nuestro ejemplo, agrupar por ‘date’ y ‘customer_id’ resulta en una tasa de poda de datos del 90%. Dado que estas columnas se consultan con frecuencia, la reducción de costos de cómputo y la mejora en el rendimiento de las consultas justifican la sobrecarga de la agrupación.
Los clientes en vista previa han destacado la efectividad en costos de Predictive Optimization, particularmente su baja sobrecarga en comparación con el diseño manual de diseños de datos. Empresas como CFC Underwriting han reportado un menor costo total de propiedad y ganancias significativas en eficiencia.
“Realmente nos encanta el Agrupamiento Líquido Automático de Databricks porque nos da la tranquilidad de que tenemos el diseño de datos más optimizado desde el principio. También nos ahorró mucho tiempo al eliminar la necesidad de que un ingeniero mantenga el diseño de datos. Gracias a esta capacidad, hemos notado que nuestros costos de cómputo han disminuido incluso a medida que hemos escalado nuestro volumen de datos.” —Nikos Balanis, Head of Data Platform, CFC
La capacidad en pocas palabras: Predictive Optimization elige las claves de agrupación líquida en tu nombre, de modo que los ahorros de costos previstos por el salto de datos superen el costo previsto de la agrupación.
Comienza Hoy
Si aún no has habilitado Predictive Optimization, puedes hacerlo seleccionando Habilitado junto a Predictive Optimization en la consola de cuenta, en Configuración > Habilitación de funciones.

¿Nuevo en Databricks? Desde el 11 de noviembre de 2024, Databricks ha habilitado Predictive Optimization por defecto en todas las nuevas cuentas de Databricks, ejecutando optimizaciones para todas tus tablas administradas por Unity Catalog.
Comienza hoy configurando CLUSTER BY AUTO en tus tablas administradas por Unity Catalog. Se requiere Databricks Runtime 15.4+ para CREAR nuevas tablas AUTO o ALTERAR tablas líquidas / no particionadas existentes. En un futuro cercano, el Agrupamiento Líquido Automático estará habilitado por defecto para las tablas administradas por Unity Catalog recién creadas. Mantente atento a más detalles.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.