Presentamos el ecosistema de almacenamiento de Databricks: gobernanza del patrimonio de datos empresariales, esté donde esté.
Impulsado por el proyecto de código abierto OpenSharing, nuestro nuevo ecosistema de socios de almacenamiento lleva Databricks Data Intelligence Platform directamente a su infraestructura híbrida y on-premises, sin copiar un solo byte.
por Rupal Jain y Denis Dubeau
- El desafío: Las organizaciones necesitan mantener grandes volúmenes de datos on-premises, en nubes privadas y en entornos edge para cumplir con estrictos requisitos regulatorios y de soberanía de datos, mantener una baja latencia en el edge o gestionar la inmensa gravedad de los datos, todo ello mientras llevan la gobernanza y la AI moderna de la nube a esos entornos.
- Qué es: El Databricks Storage Ecosystem conecta de forma nativa las plataformas de almacenamiento híbridas y on-premises con Databricks mediante el protocolo OpenSharing. Esto permite a las organizaciones establecer una gobernanza de datos centralizada y escalar GenAI en toda su infraestructura híbrida.
- El resultado: Mediante una arquitectura zero-copy, las empresas pueden ejecutar Databricks Serverless Compute, Genie y LLMs directamente en sus conjuntos de datos on-premises sin copiar un solo archivo. Esto convierte instantáneamente los datos aislados en activos activos y listos para la AI para casos de uso avanzados, como el entrenamiento de modelos con datos de ingeniería clasificados o el análisis de telemetría de red in situ.
Los datos que no se pueden mover
Durante años, la estrategia de datos empresariales era simple: mover todo a la nube. Migrar los lagos de datos y los almacenes de datos a la nube, y luego la gobernanza vendría sola. Era una historia perfecta... hasta que dejó de serlo.
Hoy en día, algunas de las empresas más sofisticadas del mundo nos lo están diciendo claramente: no pueden —y no van a— mover todos sus datos a la nube. Los principales fabricantes de semiconductores están entrenando modelos con conjuntos de datos clasificados de ingeniería que nunca deben salir de sus instalaciones. Las firmas de trading globales cuentan con volúmenes masivos de datos históricos de ticks, donde los costos de salida de la nube hacen que la migración sea imposible. Los bancos de primer nivel han adoptado estrategias de "Híbrido para siempre", modernizando el almacenamiento on-premises mientras mantienen una estricta soberanía de datos. Las principales empresas farmacéuticas realizan millones de experimentos diarios de medicamentos con entornos de datos on-premises a escala de petabytes, sujetos a estrictos controles regulatorios.
Estos no son casos aislados. Representan un cambio estructural en la forma en que las empresas piensan sobre los datos: de "Migrar todo" a "Gobernar todo".
Los factores determinantes son reales y se acumulan:
- Soberanía de datos y regulación: Los servicios financieros, la atención médica y las organizaciones gubernamentales operan bajo mandatos (GDPR, HIPAA, NIS2, reglas de residencia de datos específicas del sector) que exigen que los datos permanezcan dentro de jurisdicciones específicas o entornos aislados (air-gapped). La migración a la nube no es opcional; está legalmente prohibida para ciertos conjuntos de datos.
- Gravedad de los datos y costos: A escala de petabytes y exabytes, la viabilidad económica de la migración a la nube se desmorona por completo. Las tarifas de salida, los costos de almacenamiento y el enorme volumen de datos hacen que el modelo de "moverlo una vez" sea financieramente insostenible. Algunos de los minoristas más grandes del mundo están repatriando activamente las cargas de trabajo de analítica de la nube a la infraestructura on-premises precisamente por esta razón.
- Latencia y cargas de trabajo en el extremo (edge): Las cargas de trabajo de comercio minorista, manufactura y telecomunicaciones requieren un acceso de baja latencia a los datos on-premises y en el extremo. Los proveedores de telecomunicaciones recopilan diariamente enormes volúmenes de telemetría de red on-premises para impulsar operaciones de red basadas en IA que no pueden tolerar los tiempos de ida y vuelta a la nube.
- IA en datos oscuros (dark data): Los vastos almacenes de datos de respaldo, archivos no estructurados y conjuntos de datos secundarios —que representan cientos de exabytes en toda la empresa— contienen un inmenso valor para la IA que nunca se ha aprovechado porque la gobernanza no llegaba a ellos.
La señal es inequívoca. Hemos recibido solicitudes de cientos de clientes que piden explícitamente conectividad de almacenamiento híbrido y on-premises con Unity Catalog. El mercado del almacenamiento definido por software (SDS) alcanzará cientos de miles de millones de dólares en 2026, y los socios empresariales que gestionan este patrimonio —que colectivamente tienen más de 2 zettabytes de datos bajo gestión— están construyendo con nosotros.
Presentamos el ecosistema de almacenamiento de Databricks
Hoy nos complace anunciar el ecosistema de almacenamiento definido por software (SDS) de Databricks, una nueva categoría de socios diseñada específicamente para llevar la Databricks Intelligence Platform a los datos empresariales dondequiera que residan: on-premises, en nubes privadas y en entornos en el extremo (edge). Si es una empresa que actualmente ejecuta petabytes de datos en estas plataformas, ya no tendrá que elegir entre su infraestructura de almacenamiento existente fuera de la nube y la IA de Databricks.
Durante demasiado tiempo, las empresas tuvieron que elegir entre la infraestructura de almacenamiento on-premises en la que confían y la IA nativa de la nube que desean desarrollar. Obligar a los clientes a migrar cantidades masivas de datos mediante canalizaciones complejas solo para desbloquear esa inteligencia es un modelo fallido. Al unir a estos socios líderes de la industria, estamos poniendo fin a ese dilema y llevando la inteligencia de Databricks directamente a donde residen los datos de la empresa. Pero este lanzamiento es solo el primer día. Estamos construyendo las bases para garantizar que pronto, cada fragmento de datos híbridos, ya sean estructurados o no estructurados, esté listo de forma instantánea para la IA generativa sin tener que copiar un solo byte. —Stephen Orban, SVP, Alianzas de Productos y Ecosistema, Databricks
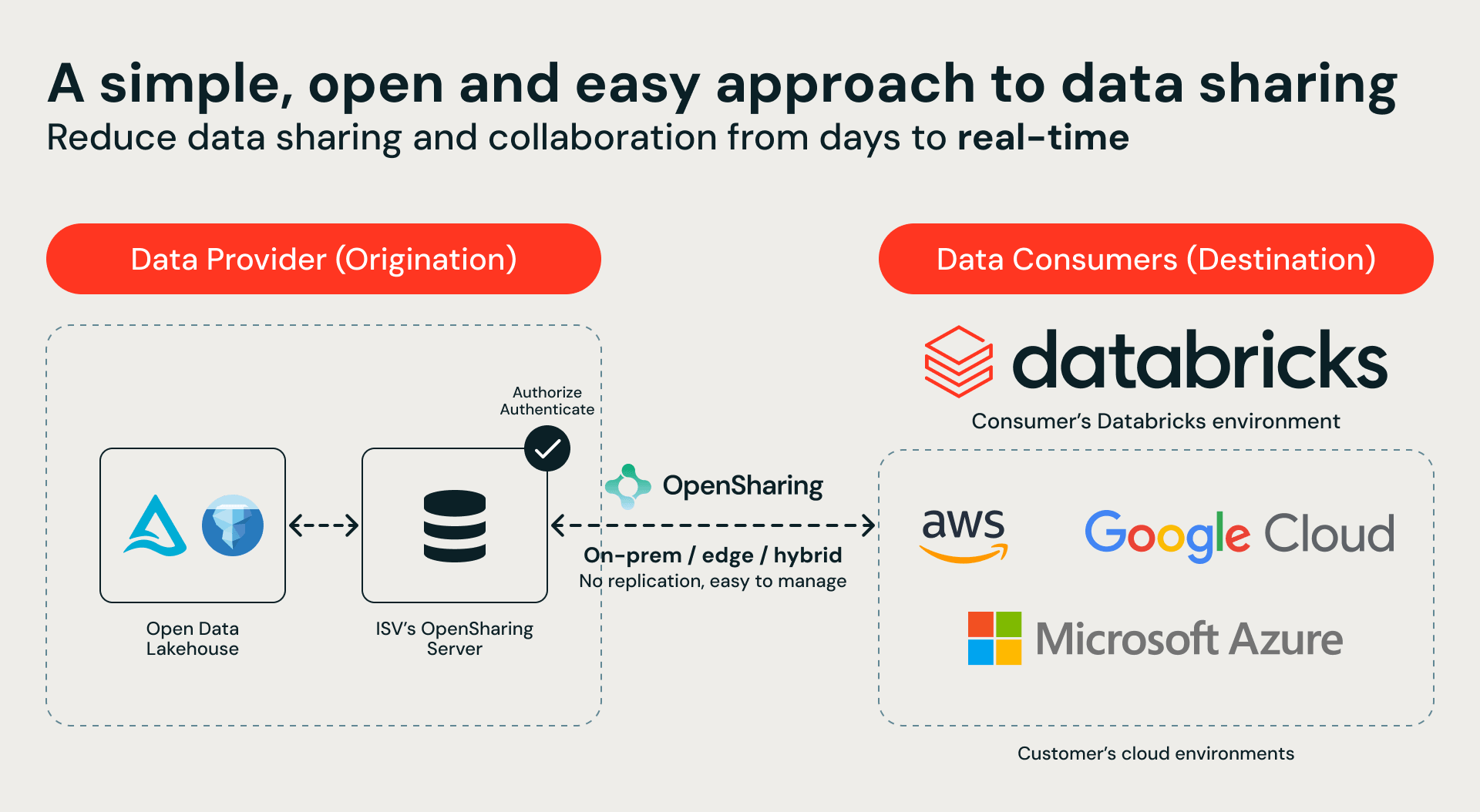
En el corazón de este ecosistema se encuentra OpenSharing, un protocolo de código abierto para el intercambio de datos seguro y gobernado. Nuestros socios de almacenamiento están implementando servidores de OpenSharing para exponer sus entornos de datos directamente a Databricks Serverless Compute. El camino es sencillo: el socio de almacenamiento habilita un punto de conexión (endpoint) de OpenSharing, usted lo conecta a Unity Catalog y obtiene instantáneamente acceso seguro y gobernado a sus datos on-premises en Databricks sin necesidad de migración de datos.
Esta integración proporciona un catálogo único y unificado en todo su entorno híbrido. Ahora, los clientes pueden usar Databricks Serverless Compute, Genie, AgentBricks y el entrenamiento de modelos para consultar y analizar datos que nunca salen de sus instalaciones. ¿El resultado? Cero movimiento de datos, sin duplicación de datos y cero riesgo de cumplimiento.
Esto no es una aspiración a futuro. Los clientes pueden probar estas integraciones hoy mismo. Los socios que desarrollan estas integraciones siguen el Partner Well-Architected Framework, una guía técnica que abarca criterios de arquitectura, seguridad y certificación.
Los clientes desean derribar los silos de datos y unificar todo su patrimonio de datos e IA, incluida la gran cantidad de datos que aún se encuentra on-premises. Gracias a que los socios de almacenamiento on-premises aprovechan el protocolo de código abierto Open Sharing, los clientes ahora pueden unificar, gobernar y analizar sin problemas todo su patrimonio de datos en Databricks Unity Catalog, liberando todo el valor de sus datos en la Databricks Data Intelligence Platform. —Jonathan Keller, VP, Gestión de Productos, Databricks
Nuestros socios de lanzamiento
Nos enorgullece anunciar integraciones con los siguientes proveedores de almacenamiento líderes:

MinIO — Disponibilidad general (demo, blog)
MinIO AIStor es el puente que conecta a la perfección la Databricks Data Intelligence Platform con los datos empresariales que no se pueden mover a la nube. Al implementar de forma nativa el protocolo abierto Open Sharing en la capa de almacenamiento, AIStor elimina la complejidad y permite a los clientes de Databricks consultar de manera eficiente tablas Delta y Apache Iceberg™️ locales en tiempo real bajo la gobernanza completa de Unity Catalog. Extiende Serverless Compute, Genie y Agent Bricks a los datos on-premises, llevando todo el poder de la plataforma de Databricks a los datos más críticos de la empresa.
Las iniciativas de IA y analítica a menudo se ven limitadas por el lugar donde residen los datos, especialmente en entornos con estrictos requisitos de seguridad, soberanía o funcionamiento. Al llevar OpenSharing nativo a AIStor, permitimos que las organizaciones expongan de manera segura los datos donde residen, al tiempo que brindamos a Databricks un acceso sin problemas a través de estándares abiertos. Esto elimina una barrera importante entre los datos empresariales y la IA, lo que permite a las organizaciones activar datos que antes eran inaccesibles para aplicaciones de IA, analítica y agénticas sin comprometer el control. —Ugur Tigli, CTO, MinIO
Everpure (anteriormente Pure Storage) — Vista previa privada (demo, blog)
Everpure y Databricks permiten a las organizaciones utilizar datos on-premises directamente en la nube, eliminando la necesidad de replicación o duplicación de datos. Esto se ofrece a través de un conector de OpenSharing que vincula los datos en el almacenamiento de objetos con los espacios de trabajo principales de Databricks de manera segura y controlada.
Everpure y Databricks permiten a las organizaciones acceder y analizar datos on-premises directamente desde la nube sin necesidad de replicación o duplicación. Mover datos continuamente entre entornos es costoso e insostenible a escala. Los clientes buscan un enfoque más simple que equilibre el costo, el cumplimiento y la soberanía de los datos, al tiempo que reduce la complejidad operativa. —Chadd Kenney, VP de Gestión de Productos, Everpure
Qumulo — Vista previa privada en julio de 2026 (blog)
Qumulo ha integrado OpenSharing con su nuevo NeuralSearch, lo que permite a los clientes compartir de forma segura datos almacenados en Qumulo con Databricks en entornos locales, de nube y de borde, sin replicación, costos adicionales ni complejidad. Con NeuralSearch, los usuarios pueden descubrir conjuntos de datos relevantes, incluido el contenido no estructurado, mediante consultas en lenguaje natural y compartir de forma fluida esas tablas seleccionadas con Databricks a través de OpenSharing.
Las organizaciones ya no pueden permitirse el costo, la complejidad y los retrasos de copiar conjuntos de datos masivos entre entornos solo para dar soporte a la AI y la analítica. Al combinar Qumulo NeuralSearch con Databricks OpenSharing, los clientes pueden descubrir, gobernar y compartir de forma segura tanto datos tabulares como no estructurados en centros de datos locales, ubicaciones de borde y nubes públicas, en tiempo real y sin mover los datos. Juntos, estamos ayudando a las organizaciones a acelerar las iniciativas de AI, unificar la gobernanza y obtener información de valor de forma más rápida a partir de datos distribuidos globalmente, manteniendo al mismo tiempo una única fuente de verdad. —Brandon Whitelaw, SVP y director de producto en Qumulo
VAST Data — Vista previa privada en agosto de 2026
VAST Data está ampliando el VAST AI Operating System con soporte para OpenSharing para ayudar a las empresas a conectar los flujos de trabajo de Databricks con los datos que residen en infraestructuras locales e híbridas, sin necesidad de realizar migraciones o movimientos masivos de datos.
La integración ofrecerá a los clientes más flexibilidad para acceder, procesar y operativizar datos en entornos de nube, centros de datos e infraestructuras de AI emergentes, al tiempo que admite cargas de trabajo modernas de analítica y AI híbrida.
La infraestructura de AI se está volviendo fundamentalmente híbrida. Los clientes desean cada vez más la capacidad de procesar datos donde tenga más sentido desde el punto de vista económico y operativo, manteniendo al mismo tiempo un acceso fluido en todos los entornos. El soporte de OpenSharing amplía la capacidad del VAST AI Operating System para conectar los flujos de trabajo de Databricks con los datos que residen en infraestructuras locales y de nube para aplicaciones modernas de analítica y AI. A diferencia de las plataformas de almacenamiento tradicionales, VAST combina servicios de datos, procesamiento distribuido y orquestación de infraestructura de AI en un sistema operativo unificado para datos de AI a escala. —John Mao, vicepresidente de Alianzas Tecnológicas Globales en VAST Data
Próximos pasos
Integraciones disponibles próximamente
Además de nuestros socios de lanzamiento, el impulso en todo el ecosistema de almacenamiento sigue acelerándose. Hemos obtenido el compromiso de Cohesity, Commvault, HPE, NetApp, Nutanix y Rubrik para desarrollar integraciones nativas antes de finales de año.
En conjunto, estos socios, junto con los socios de lanzamiento, gestionan cientos de exabytes de datos empresariales, que abarcan medios no estructurados de alto rendimiento, archivos de copia de seguridad secundarios, almacenamiento en la nube rentable y entornos de nube privada hiperconvergentes.
Desbloquear los datos no estructurados
El lanzamiento de hoy establece que los datos tabulares estructurados estén totalmente gobernados y accesibles en todo este ecosistema. Pero sabemos que nos espera una gran oportunidad en los datos no estructurados: las imágenes, PDF, vídeos, escaneos médicos, simulaciones de ingeniería y archivos de copia de seguridad que representan la mayoría de los datos empresariales gestionados, y la materia prima para la próxima generación de canalizaciones de RAG y modelos ajustados.
Estamos trabajando activamente para ampliar el protocolo OpenSharing con las API de Volumes, exponiendo archivos no estructurados desde el almacenamiento local directamente a Databricks para cargas de trabajo de GenAI. Con esta novedad, los socios que gestionan grandes volúmenes de datos no estructurados —desde archivos multimedia y de imágenes hasta repositorios de copias de seguridad empresariales— desbloquearán una clase completamente nueva de casos de uso de AI para sus clientes.
Esto es lo que significa gobernarlo todo.
Únete al ecosistema
Si eres un proveedor de almacenamiento interesado en crear una integración con OpenSharing, visita el Partner Well Architected Framework o ponte en contacto con el equipo de Databricks Partner para empezar.
Si eres un cliente empresarial que desea conectar su infraestructura de almacenamiento local a Databricks, ponte en contacto con tu equipo de cuenta para obtener más información.
La era de "Migrar todo" ha terminado. La era de "Gobernar todo" comienza hoy.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.