Modo en tiempo real de Apache Spark para gaming: una mejor manera de realizar la sesionización en tiempo real
Cree pipelines de streaming con estado que realicen un seguimiento de millones de sesiones de dispositivos de juego activos, generando heartbeats en tiempo real con latencia de menos de un segundo en Apache Spark
por Neha Prabhu y Murali Talluri
- Explore cómo el Real-Time Mode de Apache Spark™ permite la sesionización de juegos en tiempo real para millones de sesiones de dispositivos activos
- Aprenda cómo los temporizadores de transformWithState impulsan heartbeats proactivos basados en temporizadores, generando resultados de forma programada, independientemente de los datos entrantes
- Vea cómo Real-Time Mode, combinado con transformWithState, reemplaza las aplicaciones internas personalizadas y los motores de streaming externos, ofreciendo una precisión de menos de un segundo tanto para el procesamiento de entrada como para la salida basada en temporizadores.
En la industria de los videojuegos, cada milisegundo cuenta. Para impulsar la personalización dentro del juego, alimentar los motores de recomendación y tomar decisiones dinámicas de programación de contenido, las plataformas deben procesar los datos de sesión de millones de jugadores en todo el mundo con una latencia de menos de un segundo.
Hoy en día, cumplir con estos requisitos de latencia ultrabaja ya no requiere una arquitectura desarticulada con múltiples motores. En este blog, exploramos una implementación en el mundo real de Apache Spark Real-Time Mode. Al aprovechar el nuevo operador transformWithState para una lógica con estado compleja, demostramos cómo Spark ofrece un rendimiento de milisegundos de extremo a extremo. Descubra cómo su equipo puede acelerar el desarrollo y crear aplicaciones operativas de misión crítica utilizando el conocido ecosistema de Structured Streaming.
Descripción general del caso de uso
Desde el inicio hasta el final del juego: por qué es importante el seguimiento de las sesiones
Para las plataformas de videojuegos, saber qué dispositivos están activos y durante cuánto tiempo no es solo una preocupación de infraestructura: es lo que impulsa el negocio. Los datos de sesión en tiempo real potencian las experiencias personalizadas dentro del juego, alimentan los motores de recomendación, informan las decisiones de programación de contenido y proporcionan señales de estado del dispositivo en millones de consolas y PC. Los equipos de operaciones los utilizan para aplicar controles parentales y detectar patrones de sesión anormales.
Fundamentos de los eventos de sesión
Los eventos de sesión tanto de consolas como de PC fluyen hacia los temas de Kafka. Cada evento contiene un ID de dispositivo y un ID de sesión. El ID de dispositivo identifica la consola o PC; el ID de sesión identifica la sesión de juego. Solo puede haber una sesión activa por dispositivo a la vez.
El pipeline maneja cuatro escenarios:
- Inicio de sesión (GameStart): llega un evento de inicio. El pipeline almacena el ID de sesión y la hora de inicio (start time), emite un evento SessionActive y registra un temporizador de tiempo de procesamiento de 30 segundos. Si ya había otra sesión activa para ese dispositivo, primero finaliza la antigua.
- Latido de sesión (Active): el temporizador se activa cada 30 segundos. El pipeline calcula now - start_time, emite un latido SessionActive con la duración actual y vuelve a registrar el temporizador.
- Fin de sesión (GameEnd): llega un evento de finalización que coincide con la sesión activa. El pipeline emite un SessionEnd con la duración final y limpia el estado.
- Tiempo de espera de sesión (GameSessionTimeout): el temporizador se activa y la duración calculada supera un máximo configurable. En lugar de emitir un latido, el pipeline emite un SessionEnd con un motivo de tiempo de espera y limpia el estado.
Por qué Spark con Real-Time Mode cambia las reglas del juego
Spark Structured Streaming en modo micro-batch puede manejar la creación de sesiones con estado, pero cuando el caso de uso exige una precisión de menos de un segundo tanto para el procesamiento de entrada como para la salida basada en temporizadores, el modo micro-batch se queda corto. En el pasado, esa brecha obligaba a los equipos a administrar motores especializados adicionales o a crear soluciones personalizadas.
Con Apache Flink: se pueden implementar la gestión de estados y los temporizadores, pero adoptar Flink significa adoptar todo un ecosistema paralelo: un clúster independiente, un backend de estado, un modelo de implementación, una pila de monitoreo y una base de código, todo junto con Databricks Platform. El resultado es la fragmentación de la infraestructura, la complejidad operativa y el costo de operar y dotar de personal a un segundo motor de streaming.
Con soluciones personalizadas internas: algunos equipos crean su propio servicio de creación de sesiones; por ejemplo, un sistema de actores basado en Akka donde cada dispositivo obtiene un actor que gestiona el estado de la sesión, los temporizadores y la emisión de latidos. Estos conllevan la misma sobrecarga operativa y de infraestructura que Flink, con un desafío adicional: no se escalan. Distribuir millones de actores con estado entre nodos es algo que debe diseñar usted mismo. Estos sistemas funcionan al principio, pero con el tiempo terminan en modo de mantenimiento: lo suficientemente estables como para ejecutarse, pero difíciles de ampliar.
Hoy en día, Real-Time Mode cierra esta brecha para los clientes, ofreciendo una precisión de menos de un segundo con las mismas API de Spark que los equipos ya utilizan, todo en un único motor unificado.
Real-Time Mode con transformWithState
transformWithState es un operador de próxima generación en Spark Structured Streaming que hace que el procesamiento con estado complejo sea flexible y escalable. Las características clave incluyen la gestión de estado orientada a objetos, tipos de datos compuestos, lógica basada en temporizadores, soporte automático de TTL y evolución del esquema. Combinado con Real-Time Mode, ofrece una precisión de menos de un segundo tanto para el procesamiento de entrada como para la salida basada en temporizadores.
El caso de uso de creación de sesiones de juego exige dos cosas:
- Procesamiento reactivo: manejar los inicios y finales de sesión a medida que llegan.
- Salida proactiva: producir un latido para cada sesión activa según una programación, independientemente de los datos entrantes
transformWithState ofrece ambos en una sola clase StatefulProcessor con dos métodos dedicados.
handleInputRows() reacciona a los eventos entrantes de Kafka, procesando los inicios y finales de sesión, y manteniendo el estado de la sesión a medida que llegan los eventos.
handleExpiredTimer() maneja todo lo que sucede en el medio, activándose para producir salidas proactivas como latidos y tiempos de espera, independientemente de si han llegado nuevos datos.
Cómo funciona: creación de un pipeline de creación de sesiones de juego en tiempo real
Descripción general de la arquitectura del pipeline
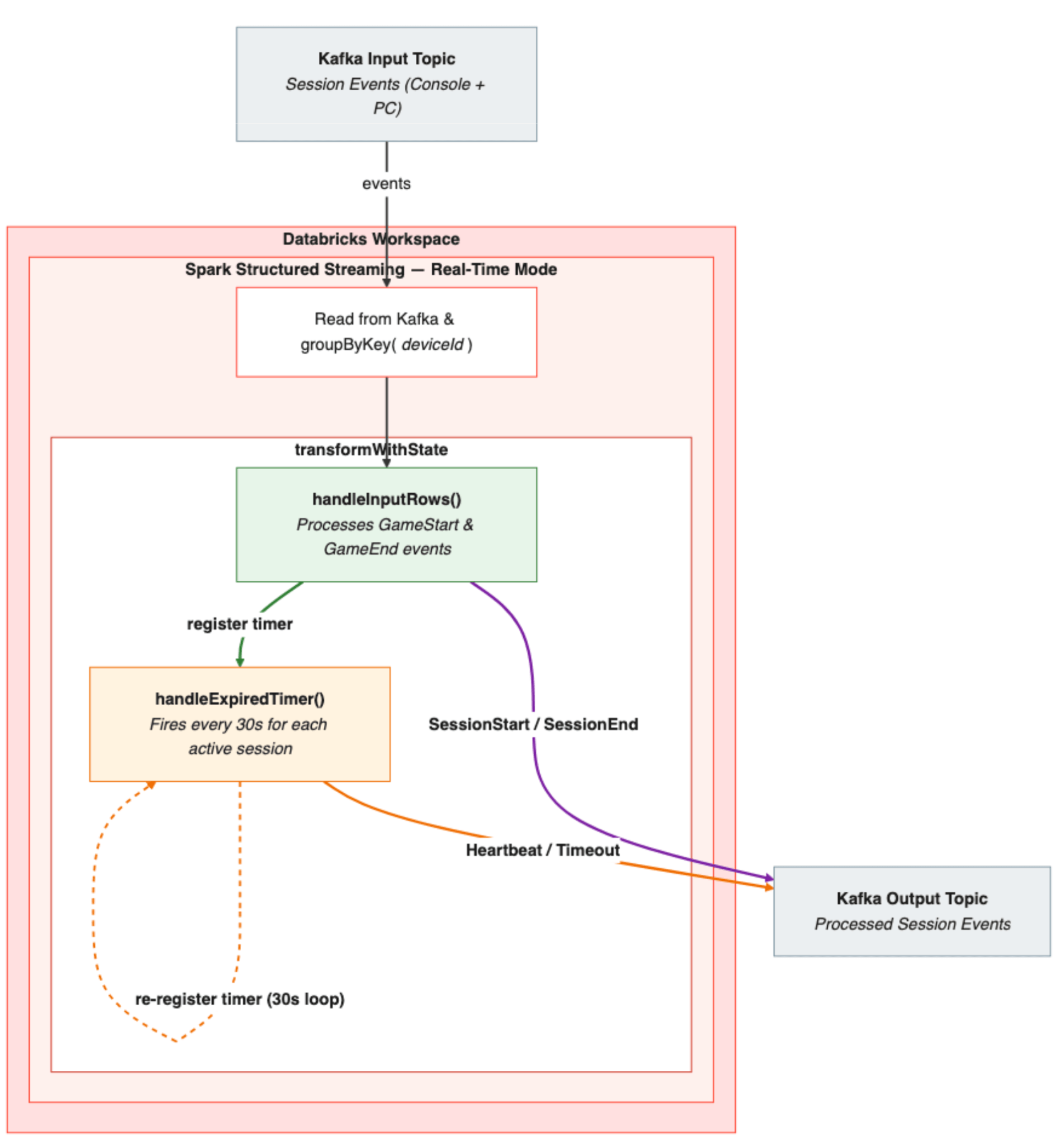
- Ingesta de eventos: los eventos de sesión (inicios y finales) de consolas y PC llegan a los temas de Kafka. Cada evento se analiza y se deriva un deviceId a partir del identificador específico del dispositivo.
- Agrupación con estado: el flujo se agrupa por deviceId, lo que garantiza que todos los eventos de un dispositivo determinado se enruten a la misma instancia de procesador con estado.
- Procesamiento: transformWithState aplica el procesador de creación de sesiones, que utiliza un MapState con clave de ID de sesión para realizar el seguimiento de la sesión activa por dispositivo. Cuando llega un inicio de sesión, handleInputRows() almacena el estado de la sesión, emite un evento SessionActive y registra el primer temporizador de 30 segundos. A partir de ese momento, handleExpiredTimer() toma el control, emitiendo latidos cada 30 segundos y comprobando si hay tiempos de espera. Cuando llega un evento de fin de sesión, handleInputRows() lo retoma, emitiendo un SessionEnd con la duración final, limpiando el estado y deteniendo el bucle del temporizador.
- Salida: los eventos de sesión procesados (inicios, latidos, finales y tiempos de espera) se escriben como JSON en un tema de Kafka de salida, listos para su consumo posterior.
Análisis profundo de la implementación
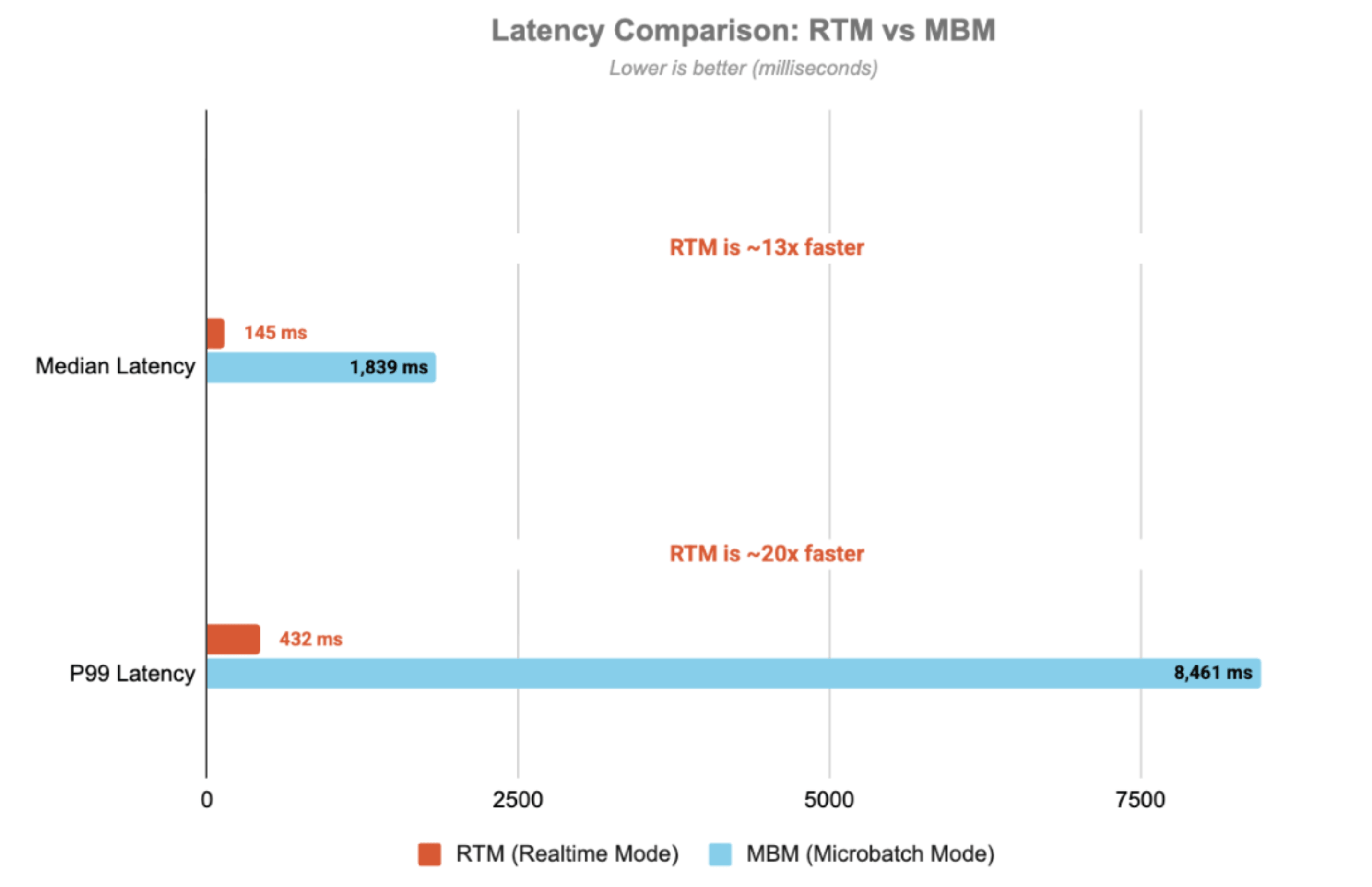
Para obtener un recorrido detallado de la arquitectura, la implementación del código y las consideraciones de producción, consulte este blog complementario, donde analizamos el código de StatefulProcessor, el ciclo de vida del temporizador, los patrones de gestión de estado y el monitoreo con StreamingQueryListener. Los siguientes resultados ilustran las características de rendimiento y latencia del pipeline, destacando las diferencias significativas de latencia entre el modo micro-batch (MBM) y Real-Time Mode (RTM):
Rendimiento
Para validar el pipeline bajo una carga realista, realizamos pruebas con el siguiente rendimiento sostenido:
Métrica (por minuto) | Valor |
Eventos de entrada (inicios + finales de sesión) | ~500K |
Número de sesiones activas | ~4M |
Registros de latidos emitidos | ~8M |
Amplificación de entrada a salida | ~16x |
La gran mayoría de las salidas no se activan por los datos entrantes; se generan por completo mediante handleExpiredTimer(), que emite latidos de forma proactiva según una programación.
Latencia
La latencia se mide de extremo a extremo, desde la marca de tiempo del tema de entrada de Kafka hasta la marca de tiempo del tema de salida. Con Real-Time Mode, el pipeline logra una latencia p99 de 432 ms, 20 veces más rápida que el modo micro-batch.
Conclusión
Los casos de uso como la sesionización de videojuegos requieren pipelines que van más allá del procesamiento de eventos entrantes: emitir heartbeats de forma proactiva de manera programada, realizar el seguimiento de millones de sesiones simultáneas y gestionar el estado de manera eficiente. Este patrón no se limita a los videojuegos. Cualquier carga de trabajo que necesite resultados basados en temporizadores (como heartbeats de IoT, seguimiento de sesiones, alertas en tiempo real o monitoreo de equipos) se puede compilar de la misma manera.
Los temporizadores en transformWithState lo hacen posible. Una única clase StatefulProcessor gestiona todo el ciclo de vida de la sesión: el procesamiento de entrada reactivo y la generación de resultados proactivos basados en temporizadores. En combinación con Real-Time Mode, los registros de entrada se procesan y los temporizadores se activan con una precisión de menos de un segundo; no en el siguiente intervalo de lote, sino ahora mismo. Todo dentro de Databricks, sin necesidad de un segundo motor.
Si ya estás ejecutando pipelines de Structured Streaming en modo micro-batch y estás recurriendo a un segundo motor para lograr una menor latencia, prueba primero Real-Time Mode. Cambiar es tan sencillo como modificar un solo trigger: sin reescrituras ni cambios de plataforma:
Pruébalo tú mismo:
- Notebook complementario con generador de datos: ejecuta el pipeline completo de sesionización de videojuegos y compara la latencia de MBM frente a RTM tú mismo.
- Guía de la API transformWithState: variables de estado, temporizadores, TTL y evolución del esquema
- Referencia de Real-Time Mode: operadores admitidos, modos de ejecución, orígenes, destinos y soporte de idiomas
Real-Time Mode ya está disponible de forma general.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.