Presentamos el modo en tiempo real en Apache Spark™ Structured Streaming
Procesa eventos en milisegundos usando el nuevo disparador en tiempo real de Spark
por Jerry Peng, Siying Dong, Abhay Bothra, Fatih Emekci, Karthikeyan Ramasamy, Navneeth Nair, Indrajit Roy, Matt Jones, Craig Lukasik y Ryan Nienhuis
- Procesamiento de streaming en milisegundos: Spark Structured Streaming introduce el modo en tiempo real para procesar datos en milisegundos, habilitando una nueva clase de aplicaciones de baja latencia.
- No se requieren reescrituras: Los equipos pueden habilitar el modo en tiempo real con un simple cambio de configuración, sin necesidad de replataforma ni revisiones de código.
- Ahora en Vista Previa Pública: Disponible en Databricks con soporte para fuentes y sinks populares; ideal para detección de fraude, personalización en vivo y servicio de características de ML.
Apache Spark™ Structured Streaming ha potenciado durante mucho tiempo pipelines críticos para el negocio a escala, desde ETL en streaming hasta análisis casi en tiempo real y machine learning. Ahora, ampliamos esa capacidad a una clase completamente nueva de cargas de trabajo con el modo en tiempo real, un nuevo tipo de disparador que procesa eventos a medida que llegan, con latencias de decenas de milisegundos.
A diferencia de los disparadores de micro-lotes existentes, que procesan datos según un horario fijo (disparador ProcessingTime) o procesan todos los datos disponibles antes de apagarse (disparador AvailableNow), el modo en tiempo real procesa continuamente los datos y emite resultados tan pronto como están listos. Esto permite casos de uso de latencia ultra baja como detección de fraude, personalización en vivo y servicio de características de machine learning en tiempo real, todo sin cambiar su código existente ni realizar replataformas.
Este nuevo modo se está contribuyendo a Apache Spark de código abierto y ahora está disponible en Vista Previa Pública en Databricks.
En esta publicación, cubriremos:
- Qué es el modo en tiempo real y cómo funciona
- Los tipos de aplicaciones que habilita
- Cómo puede empezar a usarlo hoy
¿Qué es el modo en tiempo real?
El modo en tiempo real ofrece procesamiento continuo de baja latencia en Spark Structured Streaming, con latencias p99 tan bajas como unos pocos milisegundos. Los equipos pueden habilitarlo con un solo cambio de configuración, sin reescrituras ni replataformas, mientras mantienen las mismas API de Structured Streaming que usan hoy.
Cómo funciona el modo en tiempo real
El modo en tiempo real ejecuta trabajos de streaming de larga duración que programan etapas de forma concurrente. Los datos pasan entre tareas en memoria utilizando un shuffle de streaming, que:
- Reduce la sobrecarga de coordinación
- Elimina los retrasos de programación fijos del modo de micro-lotes
- Ofrece un rendimiento consistente de subsegundo
En pruebas internas de Databricks, las latencias p99 oscilaron entre unos pocos milisegundos y ~300 ms, dependiendo de la complejidad de la transformación:
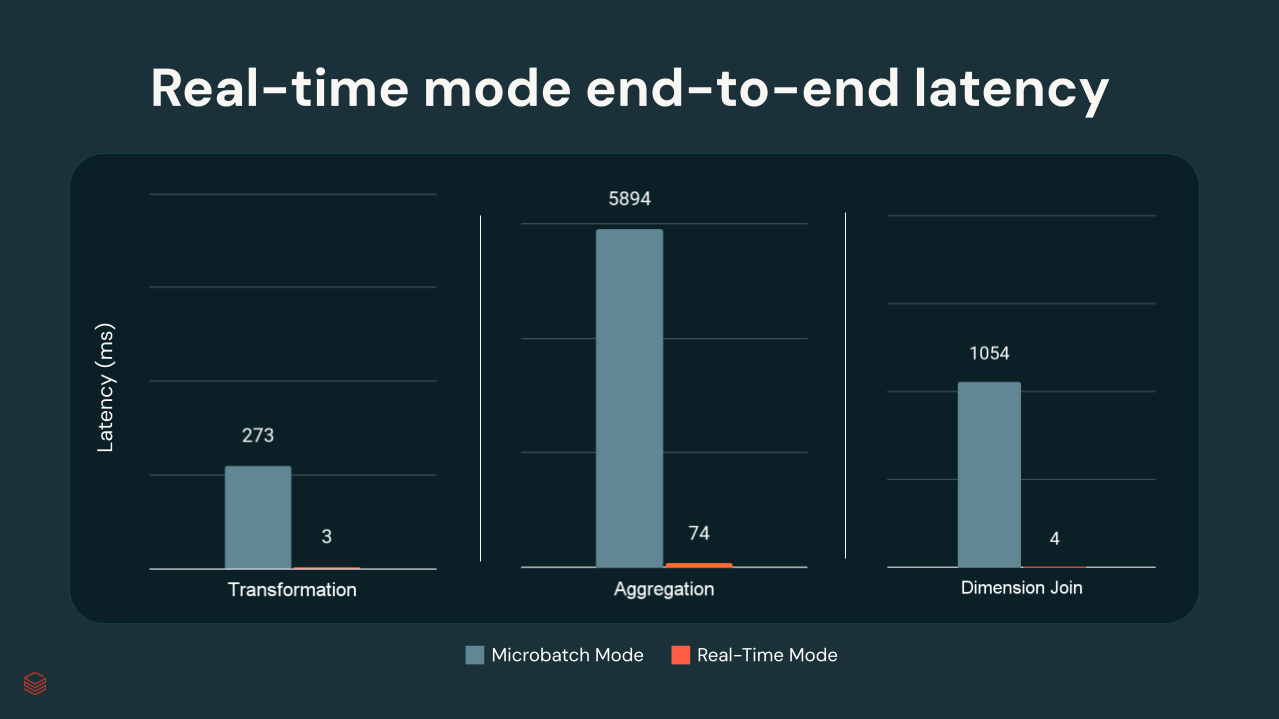
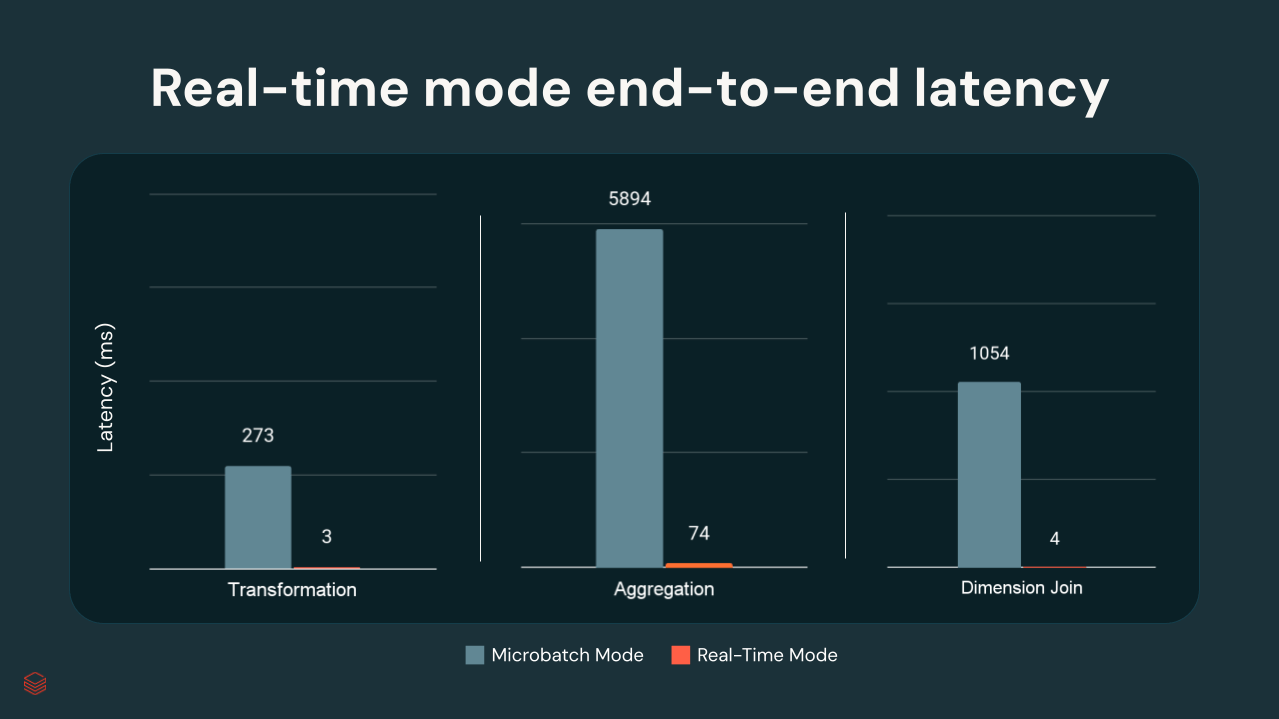{kind=link}
Aplicaciones y Casos de Uso
El modo en tiempo real está diseñado para aplicaciones de streaming que requieren procesamiento de ultra baja latencia y tiempos de respuesta rápidos, a menudo en el camino crítico de las operaciones comerciales.
El modo en tiempo real en Spark Structured Streaming ha entregado resultados notables en nuestras pruebas iniciales. Para un pipeline de autorización de pagos crítico para el negocio, donde realizamos cifrado y otras transformaciones, logramos una latencia de extremo a extremo P99 de solo 15 milisegundos. Somos optimistas sobre la escalabilidad de este procesamiento de baja latencia en nuestros flujos de datos mientras cumplimos consistentemente con estrictos SLAs. —Raja Kanchumarthi, Lead Data Engineer, Network International

Además del caso de uso de autorización de pagos de Network International citado anteriormente, varios adoptantes tempranos ya lo han utilizado para potenciar una amplia gama de cargas de trabajo:
Detección de fraude en servicios financieros: Un banco global procesa transacciones de tarjetas de crédito de Kafka en tiempo real y marca actividades sospechosas, todo dentro de 200 milisegundos, reduciendo el riesgo y el tiempo de respuesta sin replataforma.
Experiencias personalizadas en retail y medios: Un proveedor de streaming OTT actualiza las recomendaciones de contenido inmediatamente después de que un usuario termina de ver un programa. Una plataforma líder de comercio electrónico recalcula las ofertas de productos mientras los clientes navegan, manteniendo un alto nivel de participación con bucles de retroalimentación de subsegundo.
Estado de sesión en vivo e historial de búsqueda: Un importante sitio de viajes rastrea y muestra las búsquedas recientes de cada usuario en tiempo real a través de dispositivos. Cada nueva consulta actualiza la caché de sesión al instante, permitiendo resultados personalizados y autocompletado sin demora.
Servicio de características de ML en tiempo real: Una aplicación de entrega de comida actualiza características como la ubicación del conductor y los tiempos de preparación en milisegundos. Estas actualizaciones fluyen directamente a los modelos de machine learning y a las aplicaciones orientadas al usuario, mejorando la precisión de la ETA y la experiencia del cliente.
Estos son solo algunos ejemplos. El modo en tiempo real puede soportar cualquier carga de trabajo que se beneficie de convertir datos en decisiones en milisegundos, desde alertas de sensores IoT y visibilidad de la cadena de suministro hasta telemetría de juegos en vivo y personalización dentro de la aplicación.
Primeros Pasos con el modo en tiempo real
El modo en tiempo real ya está disponible en Vista Previa Pública en Databricks. Si ya está utilizando Structured Streaming, puede habilitarlo con un solo cambio de configuración y disparador, sin necesidad de reescrituras.
Para probarlo en DBR 16.4 o superior:
- Cree un clúster (recomendamos el Modo Dedicado) en Databricks con acceso a Vista Previa Pública.
Habilite el modo en tiempo real estableciendo la siguiente configuración:
Use el nuevo disparador en su consulta:
Checkpointing
La opción trigger(RealTimeTrigger.apply(...)) habilita el nuevo modo de ejecución en tiempo real, permitiéndole lograr latencias de procesamiento de subsegundo. RealTimeTrigger acepta un argumento que especifica la frecuencia con la que la consulta realiza checkpointing. Por ejemplo, trigger(RealTimeTrigger.apply(“x minutos”)) Por defecto, el intervalo de checkpointing es de 5 minutos, lo que funciona bien para la mayoría de los casos de uso. Reducir este intervalo aumenta la frecuencia de checkpointing, pero puede afectar la latencia. La mayoría de las fuentes y sinks de streaming son compatibles, incluyendo Kafka, Kinesis y forEach para escribir en sistemas externos.
Resumen
El modo en tiempo real es ideal para casos de uso que exigen la menor latencia posible. Para muchas cargas de trabajo analíticas, el modo de micro-lotes estándar puede ser más rentable sin dejar de cumplir los requisitos de latencia. El modo en tiempo real introduce una ligera sobrecarga del sistema, por lo que recomendamos usarlo para pipelines críticos en cuanto a latencia, como los ejemplos anteriores. El soporte para fuentes y sinks adicionales se está expandiendo, y estamos trabajando activamente para ampliar la compatibilidad y reducir aún más la latencia.
Para más detalles, por favor revise la documentación del modo en tiempo real para obtener detalles completos de implementación, fuentes y sinks compatibles, y ejemplos de consultas. Encontrará todo lo que necesita para habilitar el nuevo disparador y configurar sus cargas de trabajo de streaming.
Para una visión más amplia de las novedades en Apache Spark, incluyendo cómo el modo en tiempo real encaja en la evolución del motor, vea la keynote de Spark de Michael Armbrust de DAIS 2025. Cubre los cambios arquitectónicos detrás del próximo capítulo de Spark, con el modo en tiempo real como parte central de la historia.
Para profundizar en la ingeniería detrás del modo en tiempo real, vea nuestra sesión de análisis técnico de nuestros ingenieros, que detalla el diseño e implementación.
Y para ver cómo el modo en tiempo real encaja en la estrategia de streaming más amplia en Databricks, consulte la Guía Completa de Streaming en la Plataforma de Inteligencia de Datos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.