Detrás de cámaras con Lakebase
Ramificando el ciclo de desarrollo (Parte 1)
por Cameron Casher y Kevin Hartman
Durante treinta años, la base de datos operativa y la base de datos analítica han sido dos artefactos, dos planos de gobernanza, dos presupuestos y, por lo general, dos rotaciones de guardia, conectados por un trabajo ETL que alguien escribió a toda prisa y que nadie quiere poseer. Esa división nunca fue una elección de diseño; fue una restricción física. OLTP y OLAP tenían diseños de almacenamiento, perfiles de cómputo y modos de falla genuinamente diferentes, por lo que construimos dos plataformas y las conectamos después de construirlas.
Esa restricción se está disolviendo. Cuando el almacenamiento se comparte, el cómputo es sin servidor y está aislado por carga de trabajo, y la gobernanza reside en la capa del catálogo, "operacional" y "analítico" dejan de ser categorías arquitectónicas y se convierten en patrones de acceso sobre la misma base.
Para probar si eso es realmente cierto en la práctica, tomamos Backstage, el Portal de Desarrolladores Internos de Spotify, notoriamente pesado en estado, lo desconectamos de su base de datos Postgres estándar y lo apuntamos a Lakebase de Databricks. A lo largo de esta serie de tres partes, exploraremos qué sucede con los Ciclos de Despliegue (Parte 1), la Gobernanza (Parte 2) y FinOps (Parte 3) cuando colapsas el muro entre la aplicación operativa y la plataforma de datos.
La Configuración: Apuntando Backstage a Lakebase
Lakebase expone una superficie Postgres sin servidor (aprovechando la arquitectura de Neon internamente) que reside dentro de la Plataforma Databricks. Debido a que habla Postgres con protocolo de cable, Backstage no sabe ni le importa que no esté hablando con RDS.
Conectarlo requirió apuntar app-config.yaml a Lakebase y cambiar la búsqueda en memoria predeterminada de Backstage por PgSearchEngine. Un obstáculo inmediato: Lakebase rechaza los Tokens de Acceso Personal de Databricks clásicos, esperando un OAuth JWT en su lugar. La CLI proporciona databricks postgres generate-database-credential, que genera un JWT con ámbito y de corta duración para un punto final específico, el enfoque previsto para aplicaciones y CI. Para este POC, envolvimos ese comando en un script de cron ligero que reescribía el DATABRICKS_TOKEN en nuestro archivo .env cada 50 minutos para manejar la expiración del token.
Con la autenticación resuelta, las migraciones de Knex se ejecutaron limpiamente y el portal estaba en línea.
Branching Cambia el Ciclo de Desarrollo de Bases de Datos
Lo más subestimado de una Postgres tradicional no es su conjunto de características; es el tempo que impone a los equipos que la poseen.
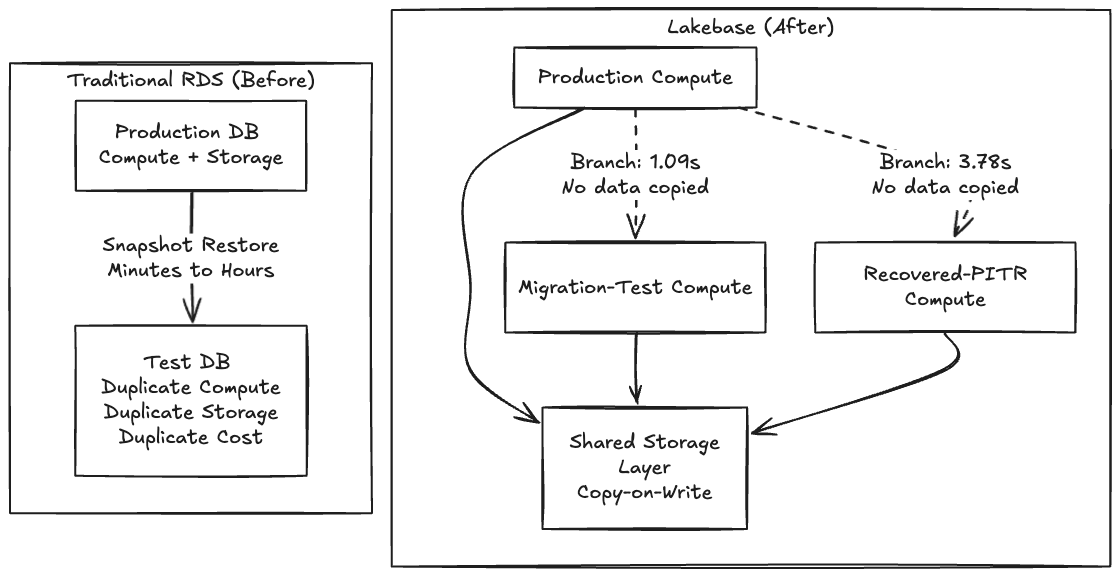
Thoughtworks ha sido un defensor constante de Backstage como base para un IDP a través del Technology Radar, por lo que, además de estar muy familiarizado con la herramienta, elegimos Backstage para este POC porque sus migraciones de esquema son notoriamente frágiles y parecía una oportunidad perfecta para probar una integración con Lakebase. En RDS tradicional, probar una migración arriesgada significa esperar minutos u horas para que una instantánea se restaure en una instancia paralela. Debido a que hacer una copia es lento y costoso, los equipos simplemente no prueban. Cruzan los dedos y ejecutan la migración en una ventana de mantenimiento.
Cuando hacer una copia se vuelve gratis, dejas de preguntar "¿es este cambio lo suficientemente seguro como para ejecutarlo?" y empiezas a preguntar "¿qué bifurcación de producción quiero probar primero?"
Debido a que Lakebase separa el almacenamiento del cómputo utilizando una arquitectura de copia en escritura, crear una rama no copia ningún dato, crea un puntero a las mismas páginas subyacentes y solo diverge al escribir. Es por eso que la operación es instantánea.
Un inconveniente que la documentación no deja claro: el cuerpo de la solicitud debe anidar todo dentro de un objeto de especificación, y debes especificar ttl, expire_time, o no_expiry. Sin eso, la API devuelve "Se debe especificar la expiración".
El plano de control lo reconoció instantáneamente. La copia del plano de datos real del catálogo de Backstage de ~63 MB aterrizó en 1.09 segundos.
Recuperación de Punto en el Tiempo: El Botón de Deshacer
Branching y Recuperación de Punto en el Tiempo (PITR) son esencialmente el mismo primitivo: branching es solo PITR con source_branch_time = now. Para probar la recuperación contra datos eliminados reales, borramos nuestra tabla final_entities, reduciendo el recuento de 32 a 0.
Luego creamos una rama de recuperación a partir de una marca de tiempo capturada segundos antes de la eliminación:
El tiempo transcurrido de extremo a extremo fue de 3.78 segundos.
La verificación de los datos confirmó que la rama recuperada tenía las 32 entidades de vuelta; la producción todavía estaba en cero, lo que confirma que la eliminación fue real y que las ramas están completamente aisladas. Notablemente, solicitamos 22:56:02Z, pero Lakebase se ajustó a 22:55:50Z, 12 segundos antes, retrocediendo al registro WAL más cercano. Esta granularidad a nivel de WAL es una advertencia importante para los flujos de trabajo de recuperación sensibles al tiempo, pero el ciclo del incidente aún se ejecutó en menos de un minuto.
Cuando el estado de la base de datos se convierte en un artefacto barato y bifurcable en lugar de un volumen EBS de 2 TB, cada operación arriesgada obtiene una ejecución de prueba y cada incidente obtiene un botón de deshacer.
De Capacidad de Infraestructura a Flujo de Trabajo del Desarrollador
Como se muestra arriba, demuestra que el branching de bases de datos funciona: una copia de 1 segundo, una recuperación de 4 segundos y una aplicación real que no nota la diferencia. Pero hay una brecha entre "la base de datos puede hacer branching" y "mi equipo hace branching de la base de datos tan naturalmente como hace branching de código". Cerrar esa brecha es donde se puede obtener un impacto masivo en la productividad del desarrollador en ganancias objetivas.
Hemos pasado los últimos meses trabajando con equipos de desarrollo para responder una pregunta específica: ¿qué le sucede a la velocidad de un equipo cuando el branching de bases de datos se vuelve invisible? Cuando no es un comando de CLI que ejecutas, sino algo que sucede automáticamente como parte de cómo trabajas en tu editor preferido. Se está trabajando en una extensión de VS Code/Cursor que sincroniza automáticamente las ramas de git y de bases de datos para demostrarlo, pero las herramientas son secundarias a lo que permiten.
Lo que Habilita el Branching
En los equipos con los que hemos tenido experiencia, el ciclo de sprint sin branching de bases de datos se ve así:
- Crear una rama de git para el desarrollo de funciones
- Escribir objetos simulados para cada interfaz de base de datos (MockUserRepository, MockOrderService...) para fines de prueba
- Escribir pruebas unitarias con una base de datos simulada o en memoria (H2, SQLite)
- Enviar una PR, obtener revisión y fusionar código
- Desplegar en un entorno de staging compartido
- Descubrir que la migración del esquema no funciona con datos reales o que el tamaño de los datos es un bloqueo
- Corregir la migración del esquema, volver a desplegar, repetir
Con la disponibilidad de la capacidad de ramificación de bases de datos, el ciclo de desarrollo de características de un desarrollador cambia:
- Crea una rama de git – una rama de base de datos Lakebase se puede crear automáticamente en 1 segundo
- Tu IDE se conecta inmediatamente a la base de datos de rama real
- Escribe código y ejecuta migraciones contra datos de base de datos reales y en vivo desde la primera línea de código
- Escribe pruebas de integración contra la base de datos real – no mocks de base de datos
- Se pueden experimentar múltiples soluciones, ya que la reversión de los cambios en la base de datos es trivial
- Envía y abre un PR – CI crea su propia rama de base de datos, valida tanto el código como el esquema, publica una diferencia de esquema
- Los miembros del equipo de QA pueden obtener su propia rama de base de datos para pruebas destructivas – se puede restablecer en segundos
- Fusiona – Una vez fusionado, el pipeline de CD puede migrar entornos superiores como UAT y producción y limpiar todas las ramas – código y datos.
Los objetos simulados desaparecen. Las colisiones de staging desaparecen. El "funciona en mi máquina pero falla en staging" desaparece, los desarrolladores obtienen una base de datos en vivo para probar múltiples soluciones. Los cambios en la base de datos que solían descubrirse en el despliegue ahora se detectan durante el desarrollo, donde son baratos de arreglar. Ramas instantáneas para pruebas de rendimiento, ramas desechables y aisladas para pruebas funcionales y una rama en ejecución para los stakeholders de UAT se vuelven triviales.
En nuestra experiencia en múltiples equipos asociados que evalúan este flujo de trabajo, los objetos simulados representan el 20-30% del código de prueba. Eso no es cobertura de prueba, es infraestructura de prueba. Infraestructura que diverge del comportamiento de producción con el tiempo, creando una falsa confianza. Cuando ramificar una base de datos equivalente a producción no cuesta nada, la simulación se convierte en la opción costosa.
La pregunta ahora es cuánto de tu sprint estás dedicando a soluciones alternativas para una restricción que ya no existe.
En la Parte 2 de esta serie, veremos qué sucede con la seguridad y el cumplimiento cuando esta base de datos operativa se integra directamente en Unity Catalog, la capa de gobernanza unificada de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.