Más allá del aprovisionamiento: la guía para desarrolladores sobre el autoescalado de Databricks Lakebase
por Bryan Clark y Susan Pierce
- El ajuste automático de escala de Databricks Lakebase elimina el tradicional dilema del sobreaprovisionamiento o subaprovisionamiento, ya que ajusta dinámicamente las Unidades de procesamiento según la carga de la CPU, el uso de memoria y el tamaño del conjunto de trabajo.
- Los desarrolladores definen barreras de protección de CU mínimas y máximas para equilibrar el rendimiento y el costo, con un ajuste de escala que se produce automáticamente y sin reinicios de la base de datos.
- La combinación del escalamiento automático con el escalado a cero reduce drásticamente el gasto en computación inactiva y, al mismo tiempo, ofrece un rendimiento instantáneo para cargas de trabajo de IA, de desarrollo e intermitentes.
Solo tienes 2 opciones para aprovisionar bases de datos:
- Sobreaprovisionamiento: configure su capacidad de cómputo a un nivel alto para el peor de los casos y pague de más por CPU inactiva
- Aprovisionamiento insuficiente: ahorra dinero ahora al configurar la computación en un nivel bajo, pero un pico en la carga de trabajo paralizará tu sistema más adelante
Esta es la “paradoja del aprovisionamiento” y, si alguna vez administraste una base de datos de producción, te has enfrentado a este desafío.
Durante años, hemos aceptado esto como el costo de operar con bases de datos relacionales. Pero con la introducción de Databricks Lakebase, Postgres sin servidor integrado con Databricks, las reglas del juego han cambiado. Nos hemos alejado de las instancias de tamaño fijo y "siempre activas" para adoptar un modelo más inteligente y elástico: el escalamiento automático.
En esta publicación, vamos a profundizar en cómo funciona realmente el autoescalado de Lakebase, por qué es un salvavidas para los flujos de trabajo de los desarrolladores modernos y cómo configurar las barreras de protección para que puedas concentrarte en desarrollar funcionalidades en lugar de administrar la infraestructura.
¿Qué es el autoescalado de Lakebase?
El Autoescalado de Lakebase es un modelo de computación inteligente que garantiza que el tamaño de tu base de datos coincida con los requisitos inmediatos de tu aplicación.
El dimensionamiento correcto para tu base de datos es el que tu aplicación requiera. La capacidad de cómputo de la base de datos debe ser reactiva, no estática ni limitada a un tamaño predefinido. Con el autoescalado, defines el rango de recursos que quieres asignar a la base de datos. Luego, el sistema ajusta dinámicamente la cantidad de capacidad de cómputo disponible para tu base de datos según la carga actual.
En Lakebase, esto se maneja a través de una abstracción llamada Unidades de Cómputo (CUs). El autoescalado utiliza un enfoque granular en el que 1 CU asigna 2 GB de memoria. Esto le permite al sistema escalar en incrementos más pequeños y precisos, lo que le brinda un control más estricto tanto del rendimiento como del costo.
Especificación | Valor |
Memoria por unidad de computo | 2 GB |
Rango máximo de escalamiento automático | 32 CU |
Diferencia máxima de CU entre el mínimo y el máximo | 8 CU |
Tiempo de espera de inactividad para escalar a cero | Definido por el usuario (p. ej., 15 min) |
Ahorro de costos estimado (escalado a cero) | Más del 70 % para cargas de trabajo en ráfagas o de desarrollo |
Se requiere reiniciar la base de datos para escalar | No |
La mecánica: cómo funciona el algoritmo de escalamiento
Es fácil suponer que el escalamiento automático solo se fija en el uso bruto de la CPU, pero Lakebase es más inteligente que eso. Para garantizar que el rendimiento de tu aplicación no se degrade, el algoritmo de escalamiento automático supervisa tres pilares técnicos clave:
1. Carga de la CPU
La métrica más intuitiva. Si su aplicación comienza a ejecutar joins complejos o el volumen de solicitudes simultáneas aumenta, el sistema detecta el pico en la utilización del procesador y agrega más CU para garantizar que la latencia de las consultas se mantenga baja.
2. Uso de la memoria
Las bases de datos relacionales son famosas por consumir mucha memoria. Esta métrica rastrea cuánta memoria consumen tus procesos y búferes activos. Al supervisar la memoria, Lakebase puede escalar verticalmente para prevenir problemas de falta de memoria (OOM) antes de que bloqueen tu sesión, lo que garantiza una disponibilidad constante incluso con una carga pesada.
3. Tamaño del conjunto de trabajo
Esta es quizás la métrica más importante a nivel profesional. El conjunto de trabajo es la porción de tus datos a la que se accede con frecuencia y que, idealmente, debería permanecer “caliente” en la caché. Si tu conjunto de trabajo crece más que la memoria RAM asignada actualmente, la base de datos tiene que "intercambiar" datos al disco, lo cual es órdenes de magnitud más lento. Lakebase estima el tamaño de tu conjunto de trabajo y escala verticalmente tu computo para garantizar que tus datos "calientes" permanezcan en la memoria de alta velocidad.
Lo bueno de este enfoque es que todo sucede sin reinicios. Las conexiones de tu base de datos permanecen abiertas y tu aplicación sigue respondiendo mientras la infraestructura subyacente se adapta de forma fluida a tu tráfico.
Configuración de los límites de protección: CU mínimas y máximas
El autoescalado no significa recursos infinitos ni facturas infinitas. Como desarrollador, necesitas control sobre el rendimiento mínimo y el costo máximo. Esto lo haces estableciendo un rango de escalado.
Cómo definir los límites de escalamiento
Al configurar una instancia de computación de Lakebase, establecerás dos valores principales:
- CU mínima: Esta es tu base. Garantiza que, incluso durante los períodos de poco tráfico, tu base de datos tenga suficiente "agilidad" para responder a tareas administrativas o trabajos en segundo plano.
- CU máximas: Esta es tu red de seguridad para el presupuesto. Evita que un proceso descontrolado, un error de consulta recursiva o un aumento inesperado del tráfico escalen tus costos más allá de lo que autorizaste.
Nota importante sobre los límites: Para que el escalamiento sea predecible y muy receptivo, Lakebase requiere que la diferencia entre el tamaño de computo máximo y mínimo no supere las 8 CU (por ejemplo, un rango de 2 a 10 CU). El escalamiento automático de Lakebase admite rangos de hasta 32 CU. Para cargas de trabajo que requieren constantemente más potencia, también hay disponibles unidades de computo de tamaño fijo más grandes.
Escenarios del mundo real: cuando el autoescalado es la mejor opción
1. Cargas de trabajo de agentes de IA y aplicaciones interactivas
Si está creando aplicaciones impulsadas por IA o agentes autónomos en Databricks, sus patrones de tráfico casi nunca son lineales. Un agente podría permanecer inactivo durante horas y, de repente, desencadenar una cadena masiva de consultas al procesar un prompt complejo o incorporar un nuevo conjunto de datos.
El escalamiento automático asegura que la base de datos gestione estos picos repentinos de actividad sin que tengas que "precalentar" la infraestructura. Cuando el agente termina su tarea, la base de datos reduce su escala automáticamente, lo que protege el presupuesto de tu proyecto.
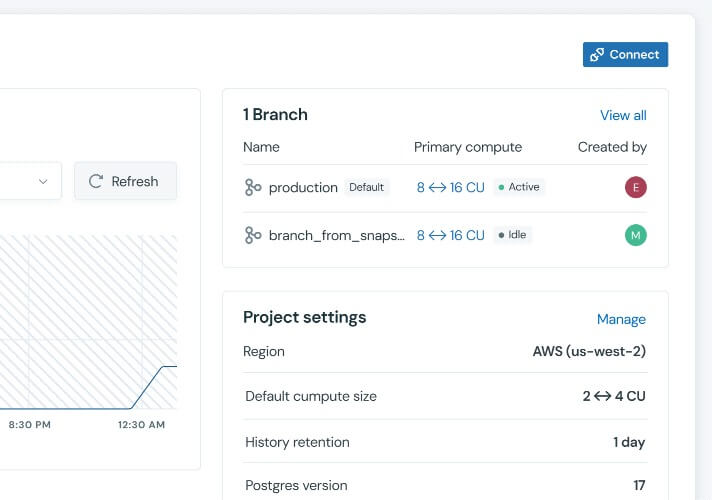
2. Desarrollo, pruebas y ramificación
Los flujos de trabajo de bases de datos modernos en Lakebase suelen incluir la ramificación de bases de datos, que es la capacidad de crear entornos aislados de copia en escritura para funcionalidades específicas o PR.
La mayoría de estas ramas de desarrollo permanecen inactivas el 90 % del tiempo. Con el escalamiento automático, estos entornos se mantienen en su mínimo de CU cuando no están en uso. Sin embargo, en el momento en que una canalización de CI/CD comienza a ejecutar una prueba de integración pesada o un desarrollador inicia una validación de datos manual, el entorno se escala instantáneamente para ofrecer un rendimiento de nivel de producción.
La ventaja de escalar a cero
El escalamiento automático se encarga de las horas de mayor actividad, pero ¿qué sucede cuando termina la jornada laboral?
Aquí es donde la función de escalar a cero se convierte en la herramienta definitiva para optimizar costos. Cuando se habilita junto con el autoescalado, Lakebase puede detectar períodos de inactividad total. Después de un tiempo de espera definido por el usuario, como 15 minutos sin consultas, la instancia de cómputo se suspende por completo.
- Costo de computación cero: Mientras la instancia está suspendida, su factura de computación se reduce a cero.
- Reinicio instantáneo: En el momento en que llega una nueva conexión o consulta, la base de datos se reanuda instantáneamente con el tamaño mínimo de escalamiento automático que definiste.
Para los entornos de desarrollo o los paneles internos que se utilizan solo durante el horario laboral, esta combinación puede reducir los costos mensuales de computación en un 70 % o más.
Por qué los desarrolladores modernos se están cambiando a Lakebase
El cambio a autoscaling se trata tanto de la simplicidad operativa como de los costos.
- Sin redimensionamiento manual: No tienes que estar pendiente de los tableros de Grafana ni redimensionar manualmente las instancias cuando alcanzas el 80 % del uso de la CPU.
- Rendimiento predecible: Al monitorear el conjunto de trabajo y el uso de la memoria, Lakebase escala antes de que tus usuarios noten una ralentización.
- Control granular: El modelo de 2 GB por CU permite un ajuste mucho más preciso que el de los proveedores de nube tradicionales, que te obligan a duplicar el tamaño de tu instancia y tu factura solo para obtener un poco más de RAM.
Conclusión
La era de dimensionar las bases de datos a ojo ha terminado. Al aprovechar el escalamiento automático de Databricks Lakebase, puedes dejar de actuar como un administrador de sistemas a tiempo parcial y empezar a centrarte en lo que importa: tu código y tus datos.
Establece tus límites, habilita la función de escalar a cero para tus ramas de desarrollo y deja que el algoritmo de Lakebase se encargue del trabajo pesado. Tus usuarios y las partes interesadas te lo agradecerán.
¿Listo para empezar?
Consulta la Documentación de autoescalado de Lakebase para aprender a configurar hoy mismo tu primera instancia de cómputo con autoescalado.
Preguntas frecuentes (FAQ)
¿Qué es el escalamiento automático? El escalamiento automático es un modelo de computo inteligente que garantiza que el tamaño de tu base de datos coincida con los requisitos de tu aplicación. Se aleja de las instancias de tamaño fijo a un modelo elástico que ajusta el computo disponible para tu base de datos en función de la carga actual.
¿Cuál es el objetivo principal del autoescalado? El objetivo principal es resolver la paradoja del aprovisionamiento, donde los desarrolladores tradicionalmente tenían que elegir entre pagar de más por una CPU inactiva o arriesgarse a una falla del sistema durante los picos de carga de trabajo. Permite que la capacidad de cómputo de la base de datos sea reactiva y tenga un tamaño preciso en lugar de estar limitada a un tamaño estático.
¿Cuáles son los beneficios de usar el escalamiento automático? Entre los beneficios se incluyen la simplicidad operativa, ya que se elimina la necesidad de cambiar el tamaño manualmente, y un rendimiento predecible a través del monitoreo proactivo de la memoria y los conjuntos de trabajo. Además, el modelo granular de 2 GB por CU ofrece un ajuste más preciso de los costos y el rendimiento en comparación con los proveedores que requieren duplicar el tamaño de las instancias para obtener más RAM.
¿Cómo gestiona la capacidad el escalamiento automático de forma dinámica? La capacidad se gestiona a través de una abstracción granular llamada Unidades de Cómputo, donde una unidad asigna 2 GB de memoria. El sistema agrega o elimina estas unidades sin necesidad de reiniciar la base de datos, lo que garantiza que las conexiones permanezcan abiertas mientras la infraestructura subyacente se adapta.
¿Cómo mejora el escalamiento automático la escalabilidad en la nube? El escalamiento automático mejora la escalabilidad al permitir que las bases de datos manejen picos repentinos de actividad sin requerir un precalentamiento manual. Esta elasticidad garantiza que la infraestructura pueda escalar para obtener un rendimiento de nivel de producción durante tareas pesadas y reducirse automáticamente para proteger los presupuestos cuando finalicen.
¿Qué métricas supervisa el escalamiento automático de Lakebase? El algoritmo supervisa tres pilares técnicos clave: la carga de la CPU para mantener una baja latencia en las consultas, el uso de la memoria para evitar problemas de falta de memoria y el tamaño del conjunto de trabajo para garantizar que los datos a los que se accede con frecuencia permanezcan en la caché.
¿Qué es una unidad de cómputo (CU) en Lakebase? Una unidad de cómputo es una abstracción de recursos granular que se utiliza en Lakebase para definir el rango de escalado. Cada unidad individual proporciona exactamente 2 GB de memoria.
¿Cuál es el rango máximo de CU que admite el Autoescalado de Lakebase? El Autoescalado de Lakebase admite rangos de hasta un máximo de 32 CU. Dentro de ese rango, el sistema requiere que la diferencia entre el mínimo y el máximo de CU definidos por el usuario no exceda las 8 CU.
¿Cómo funciona el escalado a cero en Lakebase? El escalado a cero detecta períodos de inactividad total y suspende por completo la instancia de computación después de un tiempo de espera definido por el usuario. Cuando llega una nueva conexión o consulta, la base de datos se reanuda con el tamaño mínimo de autoescalado definido.
¿Cuál es la diferencia entre el escalamiento automático y el escalado a cero en Lakebase? El escalamiento automático gestiona las horas activas ajustando el tamaño del cómputo dentro de un rango establecido para que coincida con la demanda fluctuante. El escalado a cero gestiona los períodos de inactividad suspendiendo la instancia por completo para eliminar los costos de cómputo cuando no hay consultas.
¿Puedo usar el Autoescalado de Lakebase con la ramificación de bases de datos? El autoescalado es muy beneficioso para la ramificación de bases de datos porque permite que los entornos aislados para las funcionalidades se mantengan en un mínimo de CU mientras están inactivos. Luego, estos entornos ramificados se escalan para proporcionar un rendimiento de nivel de producción cada vez que un desarrollador comienza la validación o una canalización de CI/CD ejecuta pruebas.
¿El escalamiento automático requiere el reinicio de la base de datos? No. Las conexiones de su base de datos permanecen activas y abiertas mientras Lakebase escala de forma fluida los recursos subyacentes.
¿Cuál es la relación RAM-CU en Lakebase? Cada unidad de computo (CU) proporciona exactamente 2 GB de memoria.
¿Cuánto puedo ahorrar con el escalado a cero? Para las cargas de trabajo que solo están activas durante ciertas partes del día, como las ramas de desarrollo o los paneles internos, los usuarios suelen ver reducciones en los costos de computación del 70 % o más.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.