Lleva Databricks a Kiro IDE con la potencia de AI Dev Kit
Dos formas de conectar Kiro IDE a Databricks Data Intelligence Platform: los cuatro servidores MCP gestionados por Databricks para una vía de 10 minutos, o el nuevo Databricks AI Dev Kit Power para obtener toda el área de cobertura.
- Dos vías para conectar Kiro IDE a Databricks: los cuatro servidores MCP gestionados por Databricks (Genie, SQL, Unity Catalog Functions, Vector Search) para una configuración de 10 minutos basada en PAT, o el nuevo Databricks AI Dev Kit Power: un clic, todas las herramientas y habilidades esenciales, cuatro opciones de autenticación.
- Desarrollo asistido por AI basado en metadatos reales del espacio de trabajo: ambas vías heredan los permisos basados en filas, columnas y etiquetas de Unity Catalog, por lo que el asistente escribe SQL con sus columnas reales y solo ve lo que usted puede ver: sin alucinaciones ni lecturas no autorizadas.
- Elija según el área de cobertura: la Vía A es la configuración más ligera para analistas y desarrolladores centrados en SQL; la Vía B abre la plataforma completa de Databricks (pipelines, jobs, Mosaic AI, Agent Bricks, Lakebase, Asset Bundles) dentro del IDE.
Por qué es importante
El desarrollo asistido por IA se desmorona en el momento en que el asistente tiene que adivinar los nombres de las columnas, los diseños de las tablas o qué catálogos puedes leer. La solución es el anclaje (grounding): conecta el asistente a los metadatos del espacio de trabajo en tiempo real a través de Model Context Protocol (MCP), y el SQL que escriba usará las columnas reales que tienes, los modelos de dbt unirán tablas reales y cada consulta heredará los permisos de Unity Catalog que ya tienes configurados. Nada sale de la plataforma. La IA solo ve lo que tú puedes ver.
Acaban de alcanzarse dos hitos que hacen que esto sea práctico en Kiro IDE:
Primero, Databricks AI Dev Kit agregó soporte para Kiro en la rama principal (upstream) en el PR #511. El instalador unificado trata a kiro como un objetivo de primera clase junto con claude, cursor, copilot, codex y gemini. Con un solo comando, Kiro incorpora el conjunto de herramientas completo en ~/.kiro/skills/ y ~/.kiro/settings/mcp.json.
Segundo, Databricks AI Dev Kit Power se lanzó en el catálogo de Kiro Powers en el PR #129. Abre el panel de Powers, haz clic en Try (Probar) y Power ejecutará todo el proceso de incorporación: instalador, conexión de MCP, detección de autenticación y carga de habilidades.
En combinación con los cuatro servidores MCP remotos administrados por Databricks que ya se incluyen en la plataforma, tienes dos formas de conectar Kiro a Databricks. Ambas comparten un resultado común: los desarrolladores implementan análisis, canalizaciones (pipelines) y flujos de trabajo de agentes más rápido cuando el asistente hereda los permisos reales del espacio de trabajo en lugar de adivinar esquemas, columnas y permisos.
Por qué elegir Databricks para el desarrollo asistido por IA
Los dos hitos anteriores hacen que Kiro × Databricks sea algo práctico. La razón por la que esto importa es lo que hay detrás. Tres aspectos hacen de Databricks la base de elección para el desarrollo asistido por IA, independientemente del camino que elijas.
Unity Catalog es la única capa de gobernanza que ancla la IA a nivel de datos. Cada llamada de MCP (Ruta A o Ruta B) hereda permisos basados en filas, columnas y etiquetas. El asistente no tiene una vista privilegiada de tus datos; ve exactamente lo que tú puedes ver. No hay una capa de control de acceso independiente que administrar, ni riesgo de que la IA escriba consultas en tablas que ni siquiera debería saber que existen.
Una sola copia de los datos, un solo conjunto de definiciones. Debido a que Databricks es un lakehouse, la tabla que el asistente consulta a través de databricks-sql es la misma tabla en la que escribe tu modelo de dbt, la misma tabla que expone tu espacio de Genie y la misma tabla de la que lee tu panel de AI/BI. No hay ninguna sincronización de almacén a lago (warehouse-to-lake) que pueda fallar, ni una capa semántica independiente que mantener sincronizada. Cuando el asistente se ancla en samples.tpch.lineitem, se está anclando en la misma definición que utilizan todas las demás herramientas.
Toda la pila de IA está integrada, no añadida como un parche. Mosaic AI Gateway enruta las llamadas del modelo. Agent Bricks orquesta flujos de trabajo de varios agentes. MLflow realiza el seguimiento de experimentos y evaluaciones. Vector Search potencia la búsqueda semántica. Lakebase gestiona el estado transaccional. Todo esto se muestra en el Power, todo en el mismo UC. No estás uniendo cinco productos diferentes; estás usando una sola plataforma.
Hay un cuarto aspecto que vale la pena mencionar: el propio Power está desarrollado por Databricks. Ninguna otra plataforma de datos ofrece un Power de IDE con un solo clic para Kiro, Cursor, Claude, Copilot, Codex y Gemini. La capa de MCP es abierta, el protocolo es abierto, la integración es abierta; pero la experiencia que la envuelve está diseñada por Databricks específicamente para la forma en que construyen nuestros clientes.
Las dos rutas de un vistazo
Dimensión | Ruta A: Servidores MCP administrados | Ruta B: Databricks AI Dev Kit Power |
|---|---|---|
Alcance | 4 servidores: Genie, SQL, UC Functions, Vector Search | Todas las herramientas y habilidades esenciales de Databricks |
Qué obtienes | SQL en lenguaje natural, búsqueda semántica, ejecución gobernada de funciones | El alcance de la Ruta A más canalizaciones (pipelines), trabajos (jobs), paneles (dashboards), Lakebase, Mosaic AI, Agent Bricks, Asset Bundles, MLflow, servicio de modelos (model serving) y Apps |
Alojamiento | Administrado por Databricks (HTTPS remoto) | Servidor MCP local de Python a través del instalador de AI Dev Kit |
Autenticación | PAT en el entorno de la shell | OAuth U2M (recomendado), OAuth M2M, perfil .databrickscfg o PAT |
Configuración | Edita | Instalación de Power con un solo clic y flujo de autenticación guiado |
Ideal para | Analistas y desarrolladores centrados en SQL que desean una vía de 10 minutos para hacer preguntas a su almacén de datos | Ingenieros de datos y desarrolladores de plataformas que necesitan todo el alcance de Databricks en un solo IDE |
Arquitectura de integración de un vistazo
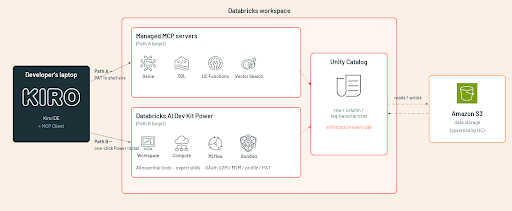
Ambas rutas comparten el mismo back-end: la aplicación de Unity Catalog y la identidad del espacio de trabajo de Databricks. Difieren en el alcance y el modelo de autenticación.
Ruta A: conectarse a los cuatro servidores MCP administrados
Esta es la configuración más ligera. Un archivo mcp.json, un token de acceso personal (PAT) de Databricks y la edición de un perfil de shell. En menos de 10 minutos, Kiro se comunicará con Genie, SQL, Unity Catalog Functions y Vector Search.
Requisitos previos
- Un espacio de trabajo de Databricks en AWS con Unity Catalog habilitado.
- Un token de acceso personal (PAT) de Databricks o un token de OAuth con alcance limitado a los servidores MCP que planeas usar (
sql,unity-catalog,genie,vector-search). Los PAT no utilizados se revocan automáticamente después de 90 días. - Kiro instalado e iniciado al menos una vez para que exista
~/.kiro/. - El nombre de host de tu espacio de trabajo en el formato
<workspace>.cloud.databricks.com.
Generar un PAT de Databricks
En el espacio de trabajo de Databricks, ve a Settings (Configuración), Developer (Desarrollador), Access tokens (Tokens de acceso), Manage (Administrar), Generate new token (Generar nuevo token). Establece una fecha de vencimiento que se alinee con la política de rotación de tu equipo. Selecciona solo los alcances de API que necesites; el principio de privilegio mínimo es mejor que la comodidad de seleccionar "todo". Copia el token de inmediato. Databricks no volverá a mostrarlo.
Dónde almacena Kiro la configuración de MCP
Kiro lee la configuración de MCP desde un JSON en dos alcances; el del espacio de trabajo anula al del usuario.
- Alcance del usuario:
~/.kiro/settings/mcp.jsonse aplica a todos los espacios de trabajo. - Alcance del espacio de trabajo:
$PWD/.kiro/settings/mcp.jsonse aplica solo al espacio de trabajo actual y anula la entrada del alcance del usuario con la misma clave.
Instalación con un solo clic desde el directorio del servidor de Kiro
Abre kiro.dev/docs/mcp/servers/, busca la fila de Databricks y haz clic en Add to Kiro (Agregar a Kiro). El navegador iniciará Kiro y abrirá un cuadro de diálogo de confirmación con una configuración precargada. Confirma para escribir la entrada databricks-sql en ~/.kiro/settings/mcp.json. La entrada hace referencia a dos variables de entorno que aún no existen; las configuraremos a continuación.
Verifica (o agrega) la entrada databricks-sql
Configura las variables de entorno
En el perfil de shell que inicia Kiro (normalmente ~/.zshrc en macOS):
Carga el perfil (source ~/.zshrc) antes de iniciar Kiro. Cierra Kiro por completo (Cmd+Q en macOS) y vuelve a abrirlo. Reload Window (Recargar ventana) no vuelve a leer las variables de entorno; solo lo hace un reinicio del proceso.
Agregar Genie, UC Functions y Vector Search
Los cuatro servidores administrados por Databricks se conectan como MCP HTTP remotos. El saludo de inicialización (handshake) se realiza correctamente incluso con una URL de marcador de posición; el servidor valida el recurso solo cuando se invoca una herramienta. Un estado de conexión con errores, donde tools/call devuelve RESOURCE_DOES_NOT_EXIST o PERMISSION_DENIED, es el modo de fallo más común. Ejecuta primero estas comprobaciones previas:
- Genie: confirma que existe un espacio de Genie y que puedes abrirlo. El ID del espacio aparece en la URL.
- Funciones de UC: confirme que la función existe y que tiene
EXECUTE. Enumere las funciones conSELECT * FROM system.information_schema.routines WHERE routine_type = 'FUNCTION'. - Vector Search: confirme que existe un endpoint con al menos un índice accesible en Catalog, Vector Search.
- Ámbito de PAT: un PAT con ámbito de espacio de trabajo aún puede alcanzar
PERMISSION_DENIEDen los espacios de Genie o índices de vectores si el usuario no tiene permisos de Can View en el recurso específico. Los espacios de Genie se comparten de forma individual.
Agregue las variables de entorno adicionales (DATABRICKS_GENIE_MCP_URL, DATABRICKS_UC_FUNCTIONS_MCP_URL, DATABRICKS_VECTOR_SEARCH_MCP_URL) y actualice mcp.json con la configuración completa:
Formatos de URL por servidor:
Servidor | Patrón de URL |
|---|---|
databricks-genie | https:// |
databricks-sql | https:// |
databricks-uc-functions | https:// |
databricks-vector-search | https:// |
Cierre y vuelva a iniciar Kiro. Abra la sección MCP SERVERS del panel de Kiro; las cuatro entradas de databricks-* aparecerán con indicadores de estado en verde. Haga clic en reconectar en cualquier elemento en rojo y vuelva a verificar la preparación previa (pre-flight). Pruebe una primera consulta de bajo riesgo en el panel de chat: "Listar los catálogos a los que tengo acceso".
Ruta B: instalar Databricks AI Dev Kit Power
Los cuatro servidores administrados cubren SQL, búsqueda semántica y análisis de lenguaje natural, lo cual es suficiente para muchos desarrolladores. Si su flujo de trabajo abarca canalizaciones (pipelines), trabajos (jobs), Model Serving, Lakebase, Asset Bundles, Mosaic AI, Agent Bricks, paneles de AI/BI, MLflow o Databricks Apps, la configuración de cuatro servidores hará que pase todo el día copiando y pegando de nuevo en la interfaz de usuario del espacio de trabajo.
Databricks AI Dev Kit Power resuelve eso. Una sola instalación. Todas las herramientas y habilidades esenciales, cuatro opciones de autenticación, todo cargable bajo demanda.
Qué obtiene
Área | Cobertura |
|---|---|
SQL y cómputo | Ejecutar SQL en warehouses; ejecutar Python o Scala en clústeres; administrar el ciclo de vida del cómputo |
Canalizaciones y trabajos | Spark Declarative Pipelines (tablas de streaming, CDC, SCD Tipo 2, Auto Loader); DAG de trabajos multitarea |
Unity Catalog | Tablas, volúmenes, concesiones (grants), etiquetas, credenciales de almacenamiento, tablas del sistema, vistas de métricas, lecturas externas de Iceberg |
Paneles de AI/BI | Visualizaciones, KPI, paneles de análisis |
Espacios de Genie | Exploración de datos en lenguaje natural sobre conjuntos de datos gobernados |
Agent Bricks | Asistentes de conocimiento (RAG) y supervisores multiagente |
Vector Search | Búsqueda semántica y RAG con índices administrados |
Model Serving | Modelos de ML, agentes de IA y API de modelos fundacionales (FMAPI) de pago por token, direccionables a través de AI Gateway |
MLflow | Experimentos, evaluaciones, instrumentación de trazas, consultas de métricas |
Lakebase | PostgreSQL administrado con aprovisionamiento y escalado automático para cargas de trabajo OLTP |
Databricks Apps | Aplicaciones web full-stack en el Lakehouse |
Asset Bundles | Infraestructura como código para recursos de Databricks |
Instalar con un solo clic
Dentro de Kiro, abra el panel de Powers, busque databricks y haga clic en Probar (Try). El Power ejecuta el instalador oficial de Databricks AI Dev Kit en modo Kiro no interactivo:
El instalador descarga el servidor MCP, crea un entorno virtual uv y extrae la biblioteca de habilidades expertas en ~/.kiro/skills/. El Power copia las habilidades en su propio directorio steering/ para que se carguen bajo demanda según la tarea en cuestión. No se incluye ningún contenido en el propio Power; todo se obtiene de forma ascendente (upstream), por lo que las habilidades se mantienen actualizadas.
Las cuatro opciones de autenticación
El flujo de incorporación del Power detecta las credenciales existentes y lo guía a través de la elección correcta. Las cuatro están documentadas en línea:
Opción | Qué es | Ideal para |
|---|---|---|
A: OAuth U2M (recomendado para uso interactivo) | La CLI de Databricks abre un navegador, usted se autentica como sí mismo y el SDK se actualiza automáticamente cada hora | Un único desarrollador humano en una estación de trabajo. El flujo interactivo más seguro, sin secretos de larga duración que puedan filtrarse |
B: OAuth M2M | Un usuario principal de servicio de Databricks se autentica con | Agentes desatendidos (headless), de CI/CD o de producción |
C: Perfil de | Apunte el Power a un perfil que ya utilice para la CLI de Databricks u otras herramientas | Ya tiene un perfil que funciona y no desea volver a configurar la autenticación |
D: Token de acceso personal (PAT) (heredado) | Token de portador (bearer token) en el bloque de entorno | Herramientas que no admiten OAuth, o espacios de trabajo sin OAuth U2M habilitado |
El mcp.json del Power se envía con disabled: true hasta que elija una opción; nada se conecta hasta que haya elegido y configurado explícitamente sus credenciales. El flujo de detección de credenciales es neutral. Si se detectan varias credenciales, se presentan las cuatro opciones en orden, sin valores predeterminados ni reutilización silenciosa.
Verificar la instalación
Reinicie Kiro, abra el panel MCP SERVERS y confirme que la entrada databricks esté conectada (en verde). Pregunte al chat: "Obtener mi usuario actual de Databricks". Esa única llamada pone a prueba la autenticación, la resolución de variables de entorno y la habilitación del servidor. Si funciona, toda la cadena está en buen estado.
Cómo elegir entre las dos rutas
Un árbol de decisión sencillo:
- ¿Solo ejecuta SQL, realiza preguntas en lenguaje natural sobre conjuntos de datos gobernados a través de Genie y busca en índices de vectores? Utilice la Ruta A. Los cuatro servidores administrados hacen exactamente eso, y la configuración toma 10 minutos.
- ¿Crear pipelines, gestionar jobs, desplegar Asset Bundles, trabajar con Lakebase, crear Databricks Apps o llamar a Mosaic AI / Agent Bricks? Usa la Ruta B. El conjunto de herramientas completo abarca demasiada superficie para integrarlo como servidores MCP remotos independientes.
- ¿Híbrido? Ejecuta ambos. La Ruta A y la Ruta B no entran en conflicto. El Power escribe su propia entrada
mcpServers.databricks, mientras que los cuatro servidores de la Ruta A (databricks-genie,databricks-sql,databricks-uc-functions,databricks-vector-search) son claves independientes. Kiro los muestra todos en el panel de MCP.
Para los desarrolladores que planean trabajar en Kiro en su día a día con cargas de trabajo de Databricks, la Ruta B es la mejor opción a largo plazo. La Ruta A es la respuesta adecuada si tienes 10 minutos y un SQL warehouse con el que quieres chatear.
Desde la perspectiva del desarrollador
Ambas rutas se perciben de manera diferente según quién use el IDE. Cuatro perfiles, cuatro puntos de dolor, cuatro respuestas.
El ingeniero de analítica. Pasas la mitad del día haciendo consultas a tablas que nunca has visto y la otra mitad copiando y pegando entre tu editor y la interfaz de usuario del espacio de trabajo. La Ruta A resuelve esto en 10 minutos. Los servidores de Genie y SQL basan cada consulta en metadatos de esquemas reales; el asistente escribe sobre tus columnas reales, sin adivinanzas; y cada resultado hereda tus permisos de Unity Catalog. Dejarás de cambiar de pestaña.
El ingeniero de datos. Tu día a día consiste en pipelines, jobs, Asset Bundles y las promociones entre entornos que conllevan los tres. Crear databricks.yml a mano y ejecutar databricks bundle deploy desde la barra lateral de la terminal es el camino lento. La Ruta B es el camino rápido. Las habilidades de pipelines + jobs + Asset Bundles de Power producen, validan y despliegan IaC a partir de una sola conversación. Spark Declarative Pipelines, CDC, SCD Type 2, Auto Loader: todo generado a partir de tus tablas reales de UC y listo para hacer commit.
El desarrollador de IA y agentes. Estás conectando llamadas a modelos, evaluación, gobernanza y orquestación de agentes a través de tres o cuatro herramientas que no terminan de ponerse de acuerdo sobre el esquema. La Ruta B cubre toda la superficie de IA de Databricks: Mosaic AI Gateway para enrutamiento y alternativas (fallbacks), Agent Bricks para supervisores multiagente y asistentes de conocimiento, MLflow para evaluación, Vector Search para recuperación; todo gobernado por UC de extremo a extremo. Tu agente hereda los mismos permisos que quien lo llama, y tus trazas de evaluación terminan en el mismo espacio de trabajo que tus ejecuciones de entrenamiento.
El desarrollador de plataformas. Gestionas los recursos de Databricks como código, realizas promociones entre dev/stage/prod y respondes a la pregunta "¿tenemos desviaciones?" con una frecuencia semanal. La habilidad de Asset Bundles de la Ruta B, junto con las habilidades de gestión de Unity Catalog, generan el bundle completo, lo validan frente al estado real de tu espacio de trabajo y detectan cualquier desviación antes de que cause problemas. Dejarás de mantener un conjunto de YAML manualmente y otro en un documento.
Un flujo de trabajo que puedes ejecutar hoy mismo
Independientemente de la ruta que hayas tomado, este ejercicio basa el asistente en metadatos reales del espacio de trabajo utilizando el catálogo samples.tpch, disponible en todos los espacios de trabajo de Databricks.
Preguntas: "¿Qué columnas y tipos tiene samples.tpch.lineitem, y cuál es la distribución de datos por año de l_shipdate?"
Kiro devuelve el esquema real y un histograma a partir de una única consulta ejecutada por MCP. Nombres de columnas reales, distribución real, sin alucinaciones.
Preguntas: "Redacta un modelo de dbt que una lineitem con orders y agregue los ingresos por nación por trimestre."
Kiro genera SQL utilizando los nombres de columna reales (l_extendedprice, l_discount, o_orderdate) en lugar de adivinanzas. Dado que consultó primero el esquema, conoce los tipos exactos y la granularidad.
Preguntas: "Ejecuta mi nueva agregación en samples.tpch y compara el recuento de filas con la instantánea de la semana pasada en poc.gold.revenue_by_nation_qtr."
Kiro ejecuta ambas consultas y muestra las diferencias. Cuando un número parece incorrecto, "Muéstrame el linaje de gold.revenue_by_nation_qtr" extrae las tablas ascendentes de system.access.table_lineage. Una vez verificado, Kiro genera el JSON del job de Databricks para el modelo y enumera qué catálogos y esquemas afecta.
En la Ruta B, el mismo flujo de trabajo se extiende a "Generar el Asset Bundle para este job y desplegarlo en staging", o "Crear un panel de AI/BI respaldado por esta agregación", o "Conectar esto a un endpoint de Mosaic AI Gateway con un modelo alternativo", todo sin salir del IDE.
Buenas prácticas, independientemente de la ruta
- Autenticación de mínimo privilegio. Genera un PAT independiente por estación de trabajo y por conjunto de alcances (scopes). En la Ruta B, prefiere OAuth U2M para uso interactivo en lugar de PAT.
- Nunca hagas commit de credenciales. Almacena
DATABRICKS_ACCESS_TOKENen tu perfil de shell o en un gestor de secretos. Nunca lo pongas enmcp.jsonregistrado en el control de versiones. - Alcance por proyecto. Mantén los ID de espacio de Genie y las rutas de índice de Vector Search en
$PWD/.kiro/settings/mcp.jsonpara que cada proyecto tenga sus propias vinculaciones de recursos. - Confía en los permisos de UC. Todas las rutas aplican las concesiones basadas en filas, columnas y etiquetas de Unity Catalog. La IA hereda tus permisos efectivos en cada llamada. No hay una capa de control de acceso independiente que gestionar.
- Reinicia, no recargues. Kiro lee las variables de entorno una sola vez al iniciar el proceso. Después de editar tu perfil de shell o añadir autenticación, sal por completo (Cmd+Q en macOS) y vuelve a abrir.
Resolución de problemas
"Servidor no encontrado" o estado en rojo en una entrada de MCP.
Ruta A: comprueba echo $DATABRICKS_SQL_MCP_URL en la shell que inició Kiro. Un valor vacío significa que Kiro no puede resolver la URL. Confirma que mcp.json a nivel de espacio de trabajo no esté anulando tu configuración a nivel de usuario. Verifica que el PAT siga siendo válido en Configuración, Desarrollador, Tokens de acceso.
Ruta B: vuelve a entrar en el flujo de detección de credenciales desde el proceso de incorporación de Power. Si el servidor MCP devuelve Invalid access token o 401, el hook de recuperación 401 integrado de Power pausa las llamadas a herramientas y vuelve a mostrar las opciones de autenticación.
Conectado a MCP pero las llamadas a herramientas devuelven RESOURCE_DOES_NOT_EXIST o PERMISSION_DENIED.
El fallo más común de la Ruta A. El handshake de inicialización tiene éxito con una URL provisional porque el servidor pospone la validación de recursos hasta la invocación. Vuelve a ejecutar las comprobaciones previas para el servidor específico (el espacio de Genie existe y está compartido contigo, la función existe y tienes EXECUTE, el índice vectorial existe y tienes permisos de visualización [Can View]).
Pruébalo hoy mismo. El Databricks AI Dev Kit Power es la forma más rápida de tener la plataforma completa (pipelines, jobs, Lakebase, Mosaic AI, Agent Bricks y todo lo demás mencionado anteriormente) dentro de Kiro. Instálalo directamente desde el catálogo de Kiro Powers en github.com/kirodotdev/powers, o visita github.com/databricks-solutions/ai-dev-kit para instalar el conjunto de herramientas subyacente para Kiro o cualquier IDE compatible (Claude, Cursor, Copilot, Codex, Gemini). Para los cuatro servidores MCP gestionados por Databricks, la instalación con un solo clic se encuentra en kiro.dev/docs/mcp/servers/.
¿Tienes comentarios o has tenido algún problema? Crea una incidencia en databricks-solutions/ai-dev-kit; las leemos todas.
Las opiniones e ideas compartidas aquí son propias y no representan la política oficial de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.