Llevando los Pipelines Declarativos al Proyecto de Código Abierto Apache Spark™
Un Estándar Abierto y Probado para la Transformación de Datos
por Michael Armbrust, Sandy Ryza, Denny Lee, James Malone y Matt Jones
- Estamos donando Declarative Pipelines, una API declarativa probada para construir pipelines de datos robustos con una fracción del trabajo, a Apache Spark™.
- Este estándar simplifica el desarrollo de pipelines en cargas de trabajo batch y de streaming.
- Años de experiencia en el mundo real han dado forma a este enfoque flexible y nativo de Spark para pipelines batch y de streaming.
Apache Spark™ se ha convertido en el motor de facto para el procesamiento de big data, impulsando cargas de trabajo en algunas de las organizaciones más grandes del mundo. Durante la última década, hemos visto cómo Apache Spark evolucionaba de ser un potente motor de cómputo de propósito general a una capa crítica de la Arquitectura Open Lakehouse, con Spark SQL, Structured Streaming, formatos de tabla abiertos y gobernanza unificada sirviendo como pilares para las plataformas de datos modernas.
Con el reciente lanzamiento de Apache Spark 4.0, esa evolución continúa con avances importantes en streaming, Python, SQL y datos semiestructurados. Puede leer más sobre el lanzamiento aquí.
Basándonos en la sólida base de Apache Spark, nos complace anunciar una nueva adición al código abierto:
Estamos donando Declarative Pipelines, un estándar probado para construir pipelines de datos fiables y escalables, a Apache Spark.
Esta contribución extiende la potencia declarativa de Apache Spark desde consultas individuales a pipelines completos, permitiendo a los usuarios definir qué debe hacer su pipeline y dejando que Apache Spark determine cómo hacerlo. El diseño se basa en años de observación de cargas de trabajo reales de Apache Spark, codificando lo que hemos aprendido en una API declarativa que cubre los patrones más comunes, incluyendo flujos batch y de streaming.
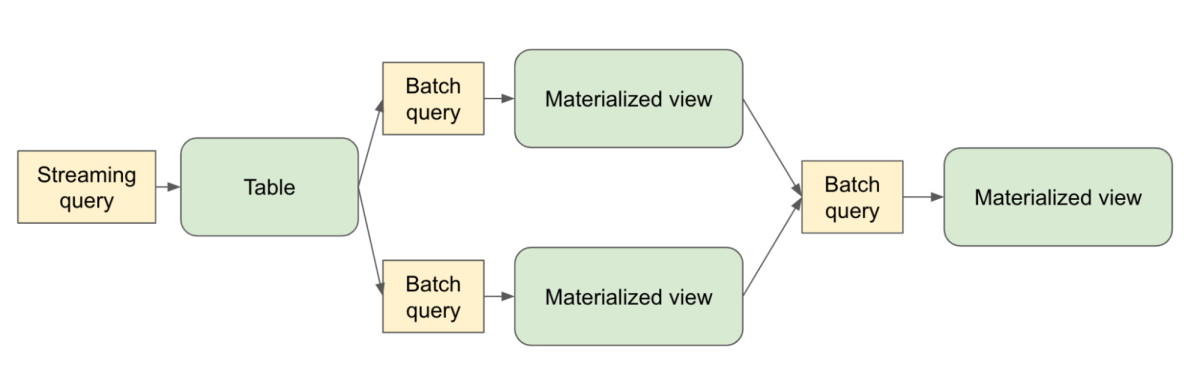
Las APIs declarativas hacen que ETL sea más simple y mantenible
A través de años de trabajo con usuarios reales de Spark, hemos visto surgir desafíos comunes al construir pipelines de producción:
- Demasiado tiempo dedicado a conectar pipelines con “código pegamento” para manejar la ingesta incremental o decidir cuándo materializar conjuntos de datos. Esto es un trabajo pesado no diferenciado que cada equipo termina manteniendo en lugar de centrarse en la lógica de negocio principal.
- Reimplementación de los mismos patrones en diferentes equipos, lo que genera inconsistencia y sobrecarga operativa.
- Falta de un marco estandarizado para pruebas, linaje, CI/CD y monitorización a escala.
En Databricks, comenzamos a abordar estos desafíos codificando las mejores prácticas de ingeniería comunes en un producto llamado DLT. DLT adoptó un enfoque declarativo: en lugar de conectar toda la lógica usted mismo, especifica el estado final de sus tablas y el motor se encarga de cosas como el mapeo de dependencias, el manejo de errores, el checkpointing, los fallos y las reintentos por usted.
El resultado fue un gran salto adelante en productividad, fiabilidad y mantenibilidad, especialmente para los equipos que gestionan pipelines de producción complejos.
Desde el lanzamiento de DLT, hemos aprendido mucho.
Hemos visto dónde el enfoque declarativo puede tener un impacto desproporcionado; y dónde los equipos necesitaban más flexibilidad y control. Hemos visto el valor de automatizar la lógica compleja y la orquestación de streaming; y la importancia de construir sobre APIs abiertas de Spark para garantizar la portabilidad y la libertad del desarrollador.
Esa experiencia informó una nueva dirección: un marco nativo de Spark, de primera clase y de código abierto para el desarrollo de pipelines declarativos.
De Consultas a Pipelines de Extremo a Extremo: El Siguiente Paso en la Evolución Declarativa de Spark
Apache Spark SQL hizo que la ejecución de consultas fuera declarativa: en lugar de implementar joins y agregaciones con código RDD de bajo nivel, los desarrolladores podían simplemente escribir SQL para describir el resultado que querían, y Spark se encargaba del resto.
Spark Declarative Pipelines se basa en esa base y va un paso más allá, extendiendo el modelo declarativo más allá de consultas individuales a pipelines completos que abarcan múltiples tablas. Ahora, los desarrolladores pueden definir qué conjuntos de datos deben existir y cómo se derivan, mientras que Spark determina el plan de ejecución óptimo, gestiona las dependencias y maneja el procesamiento incremental automáticamente.
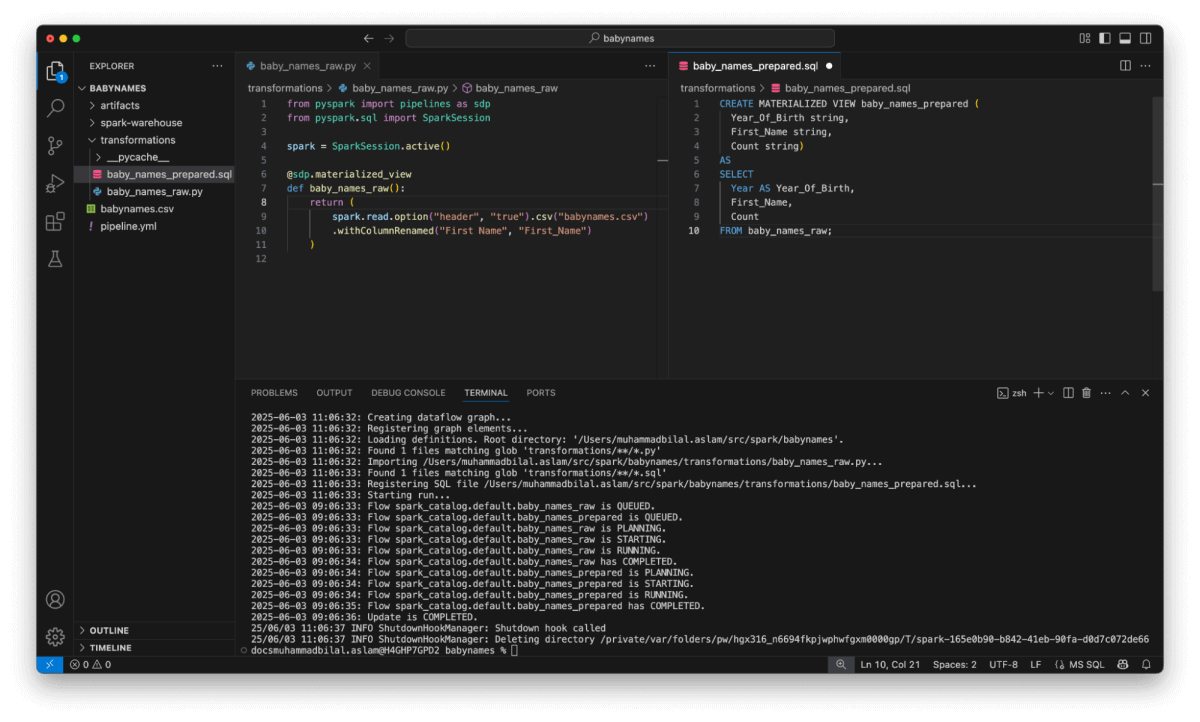
Construido pensando en la apertura y la composabilidad, Spark Declarative Pipelines ofrece:
- APIs declarativas para definir tablas y transformaciones
- Soporte nativo para flujos de datos batch y de streaming
- Orquestación consciente de los datos con seguimiento automático de dependencias, orden de ejecución y manejo de backfills
- Checkpointing automático, reintentos y procesamiento incremental para datos de streaming
- Soporte para SQL y Python
- Transparencia de ejecución con acceso completo a los planes de Spark subyacentes
Y lo más importante, es Apache Spark hasta el final, sin wrappers ni cajas negras.
Un Nuevo Estándar, Ahora Abierto
Esta contribución representa años de trabajo en Apache Spark, Delta Lake y la comunidad de datos abiertos en general. Está inspirada en lo que hemos aprendido al construir DLT, pero diseñada para ser más flexible, más extensible y completamente de código abierto.
Y apenas estamos empezando. Estamos contribuyendo esto como una capa común sobre la cual todo el ecosistema de Apache Spark puede construir, ya sea que esté orquestando pipelines en su propia plataforma, construyendo abstracciones específicas de dominio o contribuyendo directamente a Spark. Este marco está aquí para apoyarle.
“Los pipelines declarativos ocultan la complejidad de la ingeniería de datos moderna bajo un modelo de programación simple e intuitivo. Como gerente de ingeniería, me encanta el hecho de que mis ingenieros puedan centrarse en lo que más importa para el negocio. Es emocionante ver este nivel de innovación ahora en código abierto, haciéndolo accesible a aún más equipos.” —Jian (Miracle) Zhou, Gerente Senior de Ingeniería, Navy Federal Credit Union

“En 84.51 siempre estamos buscando formas de hacer que nuestros pipelines de datos sean más fáciles de construir y mantener, especialmente a medida que avanzamos hacia herramientas más abiertas y flexibles. El enfoque declarativo ha sido de gran ayuda para reducir la cantidad de código que tenemos que gestionar, y ha facilitado el soporte tanto para batch como para streaming sin tener que unir sistemas separados. La apertura de este marco como Spark Declarative Pipelines es un gran paso para la comunidad de Spark.” —Brad Turnbaugh, Ingeniero de Datos Senior, 84.51°

¿Qué Sigue?
Manténgase atento a más detalles en la documentación de Apache Spark. Mientras tanto, puede revisar el Jira y la discusión comunitaria para la propuesta.
Si está construyendo pipelines con Apache Spark hoy en día, le invitamos a explorar el modelo declarativo. Nuestro objetivo es hacer que el desarrollo de pipelines sea más simple, más fiable y más colaborativo para todos.
El Lakehouse es más que solo almacenamiento abierto. Se trata de formatos abiertos, motores abiertos y ahora, patrones abiertos para construir sobre ellos.
Creemos que los pipelines declarativos se convertirán en un nuevo estándar para el desarrollo de Apache Spark. Y estamos emocionados de construir ese futuro juntos, con la comunidad, en abierto.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.