Construcción, mejora y despliegue de sistemas RAG de grafos de conocimiento en Databricks
por Andrea Santurbano, Chandhana Padmanabhan, Jiayi Wu y Dan Pechi
- Resumen de GraphRAG: El blog explora cómo los sistemas de generación aumentada por recuperación (RAG) pueden mejorarse con bases de datos de grafos como Neo4j, lo que permite obtener resultados de IA más precisos al capturar las relaciones semánticas entre entidades en datos estructurados.
- Casos de uso y beneficios: GraphRAG se puede aplicar en ciberseguridad para la detección de amenazas, así como en industrias como la manufactura para el mantenimiento predictivo y la gestión de la cadena de suministro, proporcionando información más profunda a partir de conjuntos de datos complejos.
- Implementación en Databricks: El blog describe cómo construir e implementar un sistema GraphRAG en Databricks utilizando Neo4j, mostrando la integración de LLMs, Delta Tables y el Agent Bricks Custom Agents para la implementación de extremo a extremo.
Entendiendo GraphRAG
¿Qué es un Grafo de Conocimiento?
Para entender por qué se podría usar un Grafo de Conocimiento (KG) en lugar de otra representación de datos estructurados, es importante reconocer su enfoque en las relaciones explícitas entre entidades —como empresas, personas, maquinaria o clientes— y sus atributos o características asociadas. A diferencia de los embeddings o la búsqueda vectorial, que priorizan la similitud en espacios de alta dimensionalidad, un Grafo de Conocimiento se destaca en la representación de las conexiones semánticas y el contexto entre puntos de datos. Una unidad básica de un grafo de conocimiento es un hecho. Los hechos se pueden representar como un triplete de cualquiera de las siguientes maneras:
- HRT: <cabeza, relación, cola>
- SPO: <sujeto, predicado, objeto>
A continuación se muestran dos ejemplos simples de KG. El ejemplo de la izquierda de un hecho podría ser <Andrea, ama, Irene>. Se puede ver que el KG no es más que una colección de múltiples hechos como este. Pero como se puede notar, los grafos tienen semántica, ya que el ejemplo de la izquierda NO describe una relación romántica entre dos personas, mientras que el ejemplo de la derecha SÍ describe una relación romántica entre dos personas.

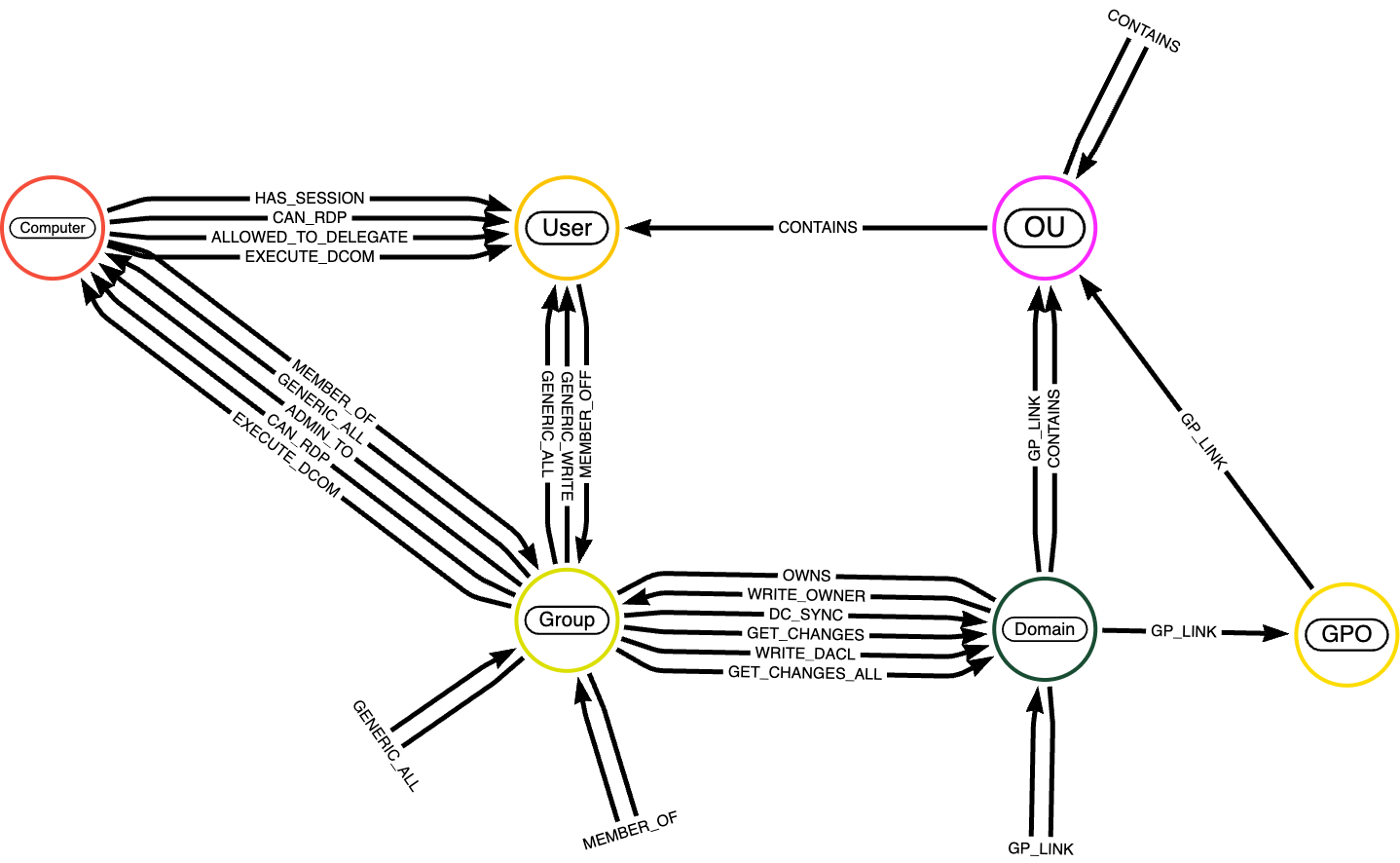
Ahora que entiende la importancia de la semántica en los Grafos de Conocimiento, le presentamos el conjunto de datos que utilizaremos en los próximos ejemplos de código: el conjunto de datos BloodHound. BloodHound es un conjunto de datos especializado diseñado para analizar relaciones e interacciones dentro de entornos de Active Directory. Se utiliza ampliamente para auditorías de seguridad, análisis de rutas de ataque y para obtener información sobre posibles vulnerabilidades en las estructuras de red.
Los nodos en el conjunto de datos BloodHound representan entidades dentro de un entorno de Active Directory. Estos típicamente incluyen:
- Usuarios: representa cuentas de usuario individuales en el dominio.
- Grupos: representa grupos de seguridad o distribución que agregan usuarios u otros grupos para la asignación de permisos.
- Computadoras: representa máquinas individuales en la red (estaciones de trabajo o servidores).
- Dominios: representa el dominio de Active Directory que organiza y administra usuarios, computadoras y grupos.
- Unidades Organizativas (OUs): representa contenedores utilizados para estructurar y administrar objetos como usuarios o grupos.
- GPOs (Objetos de Directiva de Grupo): representa políticas aplicadas a usuarios y computadoras dentro del dominio.
Una descripción detallada de las entidades de nodos está disponible aquí. Las relaciones en el grafo definen interacciones, membresías y permisos entre nodos; una descripción completa de las aristas está disponible aquí.
¿Cuándo elegir GraphRAG sobre RAG tradicional?
La principal ventaja de GraphRAG sobre RAG estándar radica en su capacidad para realizar coincidencias exactas durante el paso de recuperación. Esto es posible, en parte, al preservar explícitamente la semántica de las consultas en lenguaje natural en el lenguaje de consulta de grafos posterior. Si bien las técnicas de recuperación densa basadas en la similitud del coseno son excelentes para capturar semántica difusa y recuperar información relacionada incluso cuando la consulta no es una coincidencia exacta, hay casos en los que la precisión es fundamental. Esto hace que GraphRAG sea particularmente valioso en dominios donde la ambigüedad es inaceptable, como en cumplimiento normativo, legal o conjuntos de datos altamente curados.
Dicho esto, los dos enfoques no son mutuamente excluyentes y a menudo se combinan para aprovechar sus respectivas fortalezas. La recuperación densa puede lanzar una red amplia para la relevancia semántica, mientras que el grafo de conocimiento refina los resultados con coincidencias exactas o razonamiento sobre relaciones.
Cuándo elegir RAG tradicional sobre GraphRAG
Si bien GraphRAG tiene ventajas únicas, también presenta desafíos. Un obstáculo clave es definir el problema correctamente; no todos los datos o casos de uso son adecuados para un Grafo de Conocimiento. Si la tarea implica texto altamente no estructurado o no requiere relaciones explícitas, la complejidad adicional puede no valer la pena, lo que genera ineficiencias y resultados subóptimos.
Otro desafío es estructurar y mantener el Grafo de Conocimiento. Diseñar un esquema efectivo requiere una planificación cuidadosa para equilibrar el detalle y la complejidad. Un diseño de esquema deficiente puede afectar el rendimiento y la escalabilidad, mientras que el mantenimiento continuo exige recursos y experiencia.
El rendimiento en tiempo real es otra limitación. Las bases de datos de grafos como Neo4j pueden tener dificultades con las consultas en tiempo real en conjuntos de datos grandes o actualizados con frecuencia debido a recorridos complejos y consultas de múltiples saltos, lo que las hace más lentas que los sistemas de recuperación densa. En tales casos, un enfoque híbrido, que utiliza la recuperación densa para la velocidad y el refinamiento del grafo para el análisis posterior a la consulta, puede proporcionar una solución más práctica.
GraphDB y embeddings
Las bases de datos de grafos como Neo4j a menudo también proporcionan capacidades de búsqueda vectorial a través de índices HNSW. La diferencia aquí es cómo utilizan este índice para proporcionar mejores resultados en comparación con las bases de datos vectoriales. Cuando realiza una consulta, Neo4j utiliza el índice HNSW para identificar los embeddings que coinciden más de cerca según medidas como la similitud del coseno o la distancia euclidiana. Este paso es crucial para encontrar un punto de partida en sus datos que se alinee semánticamente con la consulta, aprovechando la semántica implícita proporcionada por la búsqueda vectorial.
Lo que distingue a las bases de datos de grafos es su capacidad para combinar esta recuperación inicial basada en vectores con sus potentes capacidades de recorrido. Después de encontrar el punto de entrada utilizando el índice HNSW, Neo4j aprovecha la semántica explícita definida por las relaciones en el grafo de conocimiento. Estas relaciones permiten a la base de datos recorrer el grafo y recopilar contexto adicional, descubriendo conexiones significativas entre nodos. Esta combinación de semántica implícita de los embeddings y semántica explícita de las relaciones de grafos permite a las bases de datos de grafos proporcionar respuestas más precisas y ricas en contexto de lo que cualquiera de los enfoques podría lograr por sí solo.
GraphRAG de extremo a extremo en Databricks
GraphRAG es un gran ejemplo de sistemas de IA compuestos en acción, donde múltiples componentes de IA trabajan juntos para hacer la recuperación más inteligente y consciente del contexto. En esta sección, echaremos un vistazo general a cómo encaja todo.
Arquitectura de GraphRAG
A continuación se muestra un diagrama de arquitectura que demuestra cómo las preguntas en lenguaje natural de un analista pueden recuperar información de un grafo de conocimiento de Neo4j.
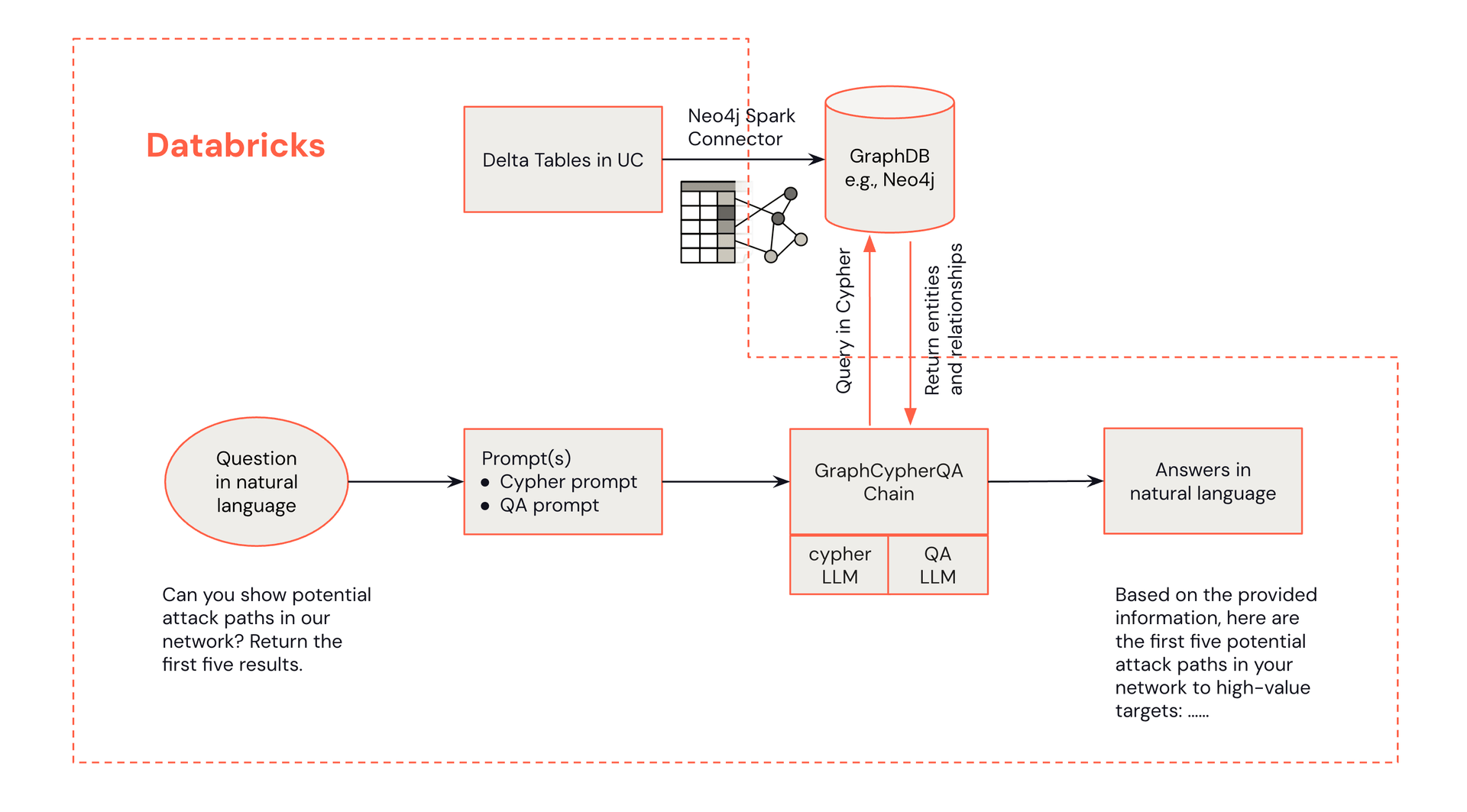
La arquitectura para la detección de amenazas impulsada por GraphRAG combina las fortalezas de Databricks y Neo4j:
- Interfaz del Analista del Centro de Operaciones de Seguridad (SOC): Los analistas interactúan con el sistema a través de Databricks, iniciando consultas y recibiendo recomendaciones de alertas.
- Procesamiento en Databricks: Databricks maneja el procesamiento de datos, la integración de LLM y sirve como centro central para la solución.
- Grafo de Conocimiento de Neo4j: Neo4j almacena y administra el grafo de conocimiento de ciberseguridad, lo que permite consultas de relaciones complejas.
Descripción general de la implementación
Para esta publicación de blog, omitimos los detalles del código; consulte el repositorio de GitHub para ver la implementación completa. Repasemos los pasos clave para construir y desplegar un agente GraphRAG.
- Construir un Grafo de Conocimiento a partir de Tablas Delta: En el notebook, discutimos escenarios sobre datos estructurados y no estructurados. El Conector Spark de Neo4j proporciona un medio muy sencillo para transformar datos en Unity Catalog en entidades de grafos (nodos/relaciones).
- Desplegar LLMs para Consultas Cypher y QA: GraphRAG requiere LLMs para la generación de consultas y la resumen. Demostramos cómo desplegar gpt-4o, llama-3.x, un modelo text2cypher ajustado desde HuggingFace y servirlos utilizando un punto final de rendimiento aprovisionado.
- Crear y Probar Cadena GraphRAG: Demostramos cómo usar diferentes LLM para LLM de Cypher y QA y prompts a través de GraphCypherQAChain. Esto nos permite ajustar aún más con resultados de rastreo de caja de cristal utilizando MLflow Tracing.
- Despliega el Agente con el Framework de Agentes de Databricks: Utiliza Agent Bricks Custom Agents y MLflow para desplegar el agente. En el notebook, el proceso incluye registrar el modelo, registrarlo en Unity Catalog, desplegarlo en un endpoint de servicio y lanzar una aplicación de revisión para chatear.

Conclusión
GraphRAG es un enfoque potente pero altamente personalizable para construir agentes que ofrecen resultados de IA más deterministas y contextualmente relevantes. Sin embargo, su diseño es específico para cada caso, requiriendo una arquitectura reflexiva y ajustes específicos para el problema. Al integrar grafos de conocimiento con la infraestructura y herramientas escalables de Databricks, puedes construir sistemas de Compound AI de extremo a extremo que combinan sin problemas datos estructurados y no estructurados para generar información procesable con una comprensión contextual más profunda.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.