Construyendo un Semantic Lakehouse con AtScale y Databricks
Descubra cómo una Capa Semántica Universal puede democratizar su Databricks Lakehouse y habilitar el BI de autoservicio
Esta es una publicación colaborativa entre AtScale y Databricks. Agradecemos a Kieran O'Driscoll, Gerente de Alianzas Tecnológicas de AtScale, por sus contribuciones.
Kyle Hale, Arquitecto de Soluciones de Databricks, acuñó el término "Semantic Lakehouse" en su blog hace unos meses. Es una buena descripción general del potencial para simplificar la pila de BI y aprovechar el poder del lakehouse. A medida que AtScale y Databricks colaboran cada vez más en el soporte a nuestros clientes conjuntos, el potencial de aprovechar la plataforma de capa semántica de AtScale con Databricks para crear rápidamente un Semantic Lakehouse ha tomado forma. Un semantic lakehouse proporciona una capa de abstracción sobre las tablas físicas y ofrece una vista amigable para los negocios del consumo de datos al definir y organizar los datos por diferentes áreas temáticas, y al definir las entidades, atributos y uniones. Todo esto simplifica el consumo de datos por parte de los analistas de negocios y los usuarios finales.
La mayoría de las empresas todavía luchan con la democratización de datos
Poner los datos a disposición de los responsables de la toma de decisiones es un desafío que la mayoría de las organizaciones enfrentan hoy en día. Cuanto más grande es la organización, más difícil se vuelve imponer un estándar único para consumir y preparar análisis. Más de la mitad de las empresas informan usar tres o más herramientas de BI, y más de un tercio usa cuatro o más. Además de los usuarios de BI, los científicos de datos tienen su propio rango de preferencias, al igual que los desarrolladores de aplicaciones.
Estas herramientas funcionan de diferentes maneras y hablan diferentes lenguajes de consulta. Los resultados de análisis conflictivos están casi garantizados cuando múltiples unidades de negocio toman decisiones recurriendo a diferentes copias de datos aisladas o a soluciones convencionales de OLAP cubing como Tableau Hyper Extracts, Power BI Premium Imports o Microsoft SQL Server Analysis Services (SSAS) para usuarios de Excel.
Mantener datos en diferentes data marts y data warehouses, extracciones en varias bases de datos y datos cacheados externamente en herramientas de informes no proporciona una única versión de la verdad para la empresa y aumenta el movimiento de datos, ETL, seguridad y complejidad. Se convierte en una pesadilla de gobernanza de datos y también significa que las organizaciones están ejecutando sus negocios con datos potencialmente obsoletos de diferentes silos de datos en las capas de BI y no aprovechando todo el poder del Databricks Lakehouse.
La necesidad de una capa semántica universal
La capa semántica de AtScale se sitúa entre todas sus herramientas de consumo de análisis y su Databricks Lakehouse. Al abstraer la forma física y la ubicación de los datos, la capa semántica hace que los datos almacenados en Delta Lake estén listos para el análisis y sean fácilmente consumibles por la herramienta de elección de los usuarios de negocio. Las herramientas de consumo pueden conectarse a AtScale a través de uno de los siguientes protocolos:
- Para SQL, el motor de AtScale aparece como un almacén Hive SQL.
- Para MDX o DAX, AtScale aparece como un cubo de SQL Server Analysis Services (SSAS).
- Para aplicaciones REST o Python, AtScale aparece como un servicio web.
En lugar de procesar datos localmente, AtScale envía las consultas entrantes a Databricks como SQL optimizado. Esto significa que las consultas de los usuarios se ejecutan directamente contra Delta Lake utilizando Databricks SQL para cómputo, escala y rendimiento.
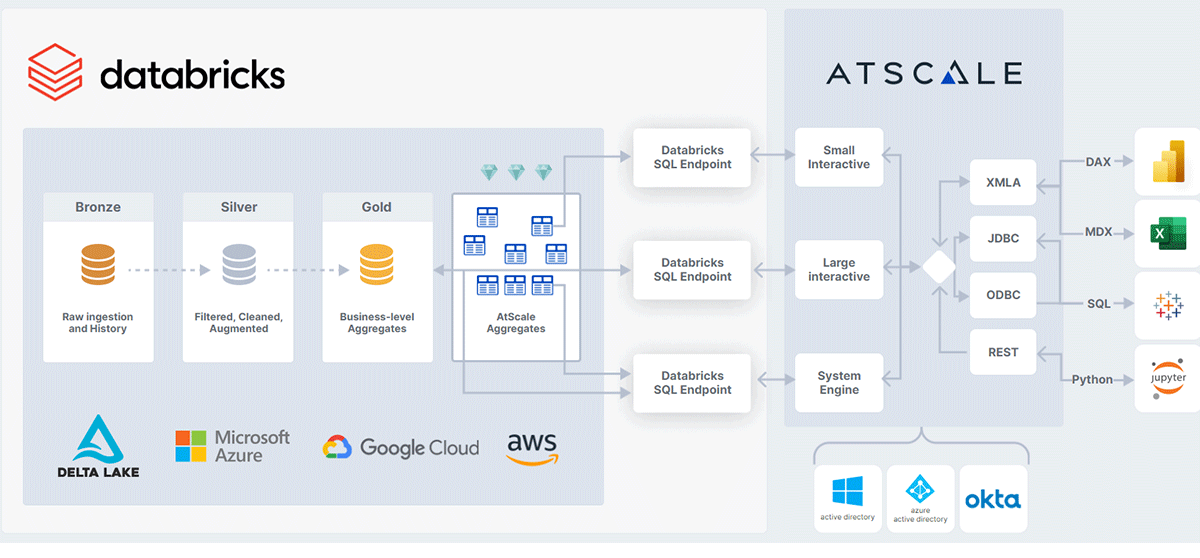
El beneficio adicional de usar una Capa Semántica Universal es que la tecnología de optimización de rendimiento autónoma de AtScale identifica los patrones de consulta del usuario para orquestar automáticamente la creación y el mantenimiento de agregados, al igual que lo haría el equipo de ingeniería de datos. Ahora nadie tiene que dedicar tiempo y esfuerzo de desarrollo para crear y mantener estos agregados, ya que son auto-creados y administrados por Atscale para un rendimiento óptimo. Estos agregados se crean en Delta Lake como Tablas Delta físicas y pueden considerarse como una "Capa Diamante". Estos agregados son completamente administrados por AtScale y mejoran la escala y el rendimiento de sus informes de BI en el Databricks Lakehouse, al tiempo que simplifican radicalmente las canalizaciones de datos de análisis y la ingeniería de datos asociada.
Creando un semantic lakehouse agnóstico a herramientas
La visión de la Plataforma Databricks Lakehouse es una única plataforma unificada para soportar todas sus cargas de trabajo de datos, análisis e IA. La descripción de Kyle del "Semantic Lakehouse" es un buen modelo para una pila de BI simplificada.
AtScale extiende esta idea de un Semantic Lakehouse al soportar cargas de trabajo de BI y casos de uso de IA/ML a través de nuestra Capa Semántica agnóstica a herramientas. La combinación de AtScale y Databricks significa que la arquitectura del semantic Lakehouse se extiende a cualquier capa de presentación; no importa si es Tableau, Power BI, Excel o Looker. Todos pueden usar la misma capa semántica en AtScale.

Con la llegada del lakehouse, las organizaciones ya no tienen a sus equipos de BI y IA/ML trabajando de forma aislada. La Capa Semántica Universal de AtScale ayuda a las organizaciones a obtener acceso consistente a todos sus datos empresariales, independientemente de si se trata de un usuario de negocio en Excel o de un científico de datos que utiliza un Notebook, al tiempo que aprovecha todo el poder de su Plataforma Databricks Lakehouse.
Recursos adicionales
Vea nuestra mesa redonda con Franco Patano, especialista principal de productos en Databricks para obtener más información y descubrir cómo estas herramientas pueden ayudarle a crear una plataforma de análisis ágil y escalable.
Si tiene alguna pregunta sobre AtScale o cómo modernizar y migrar su pila heredada de EDW, BI y reporting a Databricks y AtScale, no dude en ponerse en contacto con kieran.odriscoll@atscale.com o contactar con Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.