Protección contra exfiltración de datos con Azure Databricks
Aprende los detalles sobre cómo configurar una arquitectura segura de Azure Databricks para proteger la exfiltración de datos
Última actualización: 30 de octubre de 2025
Lectura esencial
Antes de empezar, asegúrate de estar familiarizado con estos temas.
- Arquitectura de Azure Databricks Serverless Compute
- Terminología clave de Databricks
- ¿Qué es Azure Databricks Private Link (PL) de front-end y back-end?
- Requisitos del espacio de trabajo con Private Link habilitado
- ¿Qué son las Políticas de Service Endpoint para espacios de trabajo de Azure?
- Lista de acceso IP del controlador de ingesta
- Conectividad segura de clústeres
- Redes de Databricks
- Unity Catalog
La Plataforma Lakehouse de Azure Databricks proporciona un conjunto unificado de herramientas para crear, implementar, compartir y mantener soluciones de datos de nivel empresarial a escala. Databricks se integra con el almacenamiento y la seguridad en la nube de tu cuenta, y administra e implementa la infraestructura en la nube en tu nombre.
El objetivo principal de este artículo es mitigar los siguientes riesgos:
- Acceso a datos desde un navegador en Internet o una red no autorizada utilizando la aplicación web de Databricks.
- Acceso a datos desde un cliente en Internet o una red no autorizada utilizando la API de Databricks.
- Acceso a datos desde un cliente en Internet o una red no autorizada utilizando Azure Private Link o Service Endpoints.
- Una carga de trabajo comprometida en el clúster de Azure Databricks que escribe datos en un recurso de almacenamiento no autorizado en Azure o en Internet.
Azure Databricks es un servicio de primera clase y es compatible con las herramientas y servicios nativos de Azure que ayudan a proteger los datos en tránsito y en reposo. Azure Databricks admite controles de seguridad de red, como rutas definidas por el usuario, reglas de firewall y Network Security Groups.
Además de los objetivos técnicos de este blog, también queremos asegurarnos de que los conceptos que presentamos tengan en cuenta:
- Simplicidad: cualquier diseño de seguridad debe ser bien comprendido y mantenible, y adaptarse a las habilidades de tu organización. Una solución de seguridad que se implementa y no se comprende completamente puede verse comprometida inadvertidamente.
- El costo operativo de la solución siempre debe tenerse en cuenta. Si un diseño de seguridad se abandona porque el costo es demasiado alto, entonces la solución no fue efectiva. La seguridad debe ser consciente de los costos y sostenible.
Señalarémos áreas de ahorro o preocupación de costos, al tiempo que intentaremos aclarar por qué y cómo funcionan las cosas siempre que sea posible.
Antes de empezar, echemos un vistazo rápido a la arquitectura de implementación de Azure Databricks aquí:
Azure Databricks está estructurado para facilitar la colaboración segura entre equipos, mientras administra muchos servicios de back-end, lo que te permite concentrarte en la ciencia de datos, el análisis de datos y la ingeniería de datos.
Azure Databricks está estructurado en torno a dos componentes clave: el plano de control y el plano de cómputo.
Plano de control:
El plano de control de Azure Databricks, administrado por Databricks dentro de su propia cuenta de Azure, actúa como la inteligencia central de la plataforma. Proporciona servicios de back-end para la autenticación de usuarios, la orquestación de clústeres y trabajos, y la administración del espacio de trabajo, ofreciendo la interfaz web y los puntos de conexión de API para la interacción del servicio.
Si bien orquesta el ciclo de vida de los recursos de cómputo, no procesa datos directamente. En cambio, el plano de control dirige el procesamiento de datos al plano de cómputo separado, que opera dentro de la suscripción de Azure del cliente o en el tenant de Databricks para implementaciones sin servidor. Los comandos de notebook y muchas otras configuraciones del espacio de trabajo se almacenan en el plano de control y se cifran en reposo.
Plano de cómputo:
El plano de cómputo es responsable de procesar tus datos. El tipo específico de cómputo utilizado, sin servidor o clásico, depende de los recursos de cómputo y la configuración del espacio de trabajo elegidos. Tanto el cómputo sin servidor como el clásico comparten algunos recursos, como el almacenamiento predeterminado del espacio de trabajo (dbfs) y las identidades administradas que están vinculadas a tu tenant de Azure.
Cómputo sin servidor
Para el cómputo sin servidor, los recursos operan dentro de un plano de cómputo en Azure administrado por Databricks. Azure Databricks maneja casi toda la infraestructura subyacente, incluida la provisión, el escalado y el mantenimiento. Este enfoque ofrece:
- Operaciones simplificadas: Los usuarios pueden centrarse en tareas de ingeniería de datos y ciencia de datos sin necesidad de administrar clústeres o máquinas virtuales.
- Eficiencia de costos: Los usuarios solo pagan por los recursos de cómputo consumidos activamente durante la ejecución de la carga de trabajo, lo que elimina los costos asociados con los clústeres inactivos.
Los recursos sin servidor están disponibles según sea necesario, lo que reduce los costos de tiempo de inactividad. También se ejecutan dentro de un límite de red seguro en la cuenta de Azure Databricks, con múltiples capas de seguridad y controles de red.
Cómputo clásico de Azure Databricks
Con el cómputo clásico de Azure Databricks, los recursos se encuentran dentro de tu tenant de Azure Cloud. Esto proporciona cómputo administrado por el cliente, donde los clústeres de Databricks se ejecutan en recursos dentro de tu suscripción de Azure, no en el tenant de Databricks. Esto ofrece:
- Aislamiento natural: Las operaciones ocurren dentro de tu propia suscripción y red virtual de Azure.
- Conexiones seguras: Permite conexiones seguras a otros servicios de Azure a través de puntos de conexión de servicio o puntos de conexión privados que tú administras y controlas.
Nota importante: Los clústeres clásicos, incluidos los almacenes SQL clásicos, pueden experimentar tiempos de inicio más largos en comparación con las opciones sin servidor debido al requisito de aprovisionar recursos de tu suscripción de Azure.
Implementación de espacio de trabajo de Databricks solo sin servidor (nuevo): Los espacios de trabajo solo sin servidor son espacios de trabajo que solo pueden ejecutar cómputo sin servidor. No hay cómputo clásico, por lo que todos los recursos del sistema son administrados por Azure Databricks, que se encarga de toda la infraestructura subyacente, incluido el almacenamiento predeterminado del espacio de trabajo.
Arquitectura de alto nivel
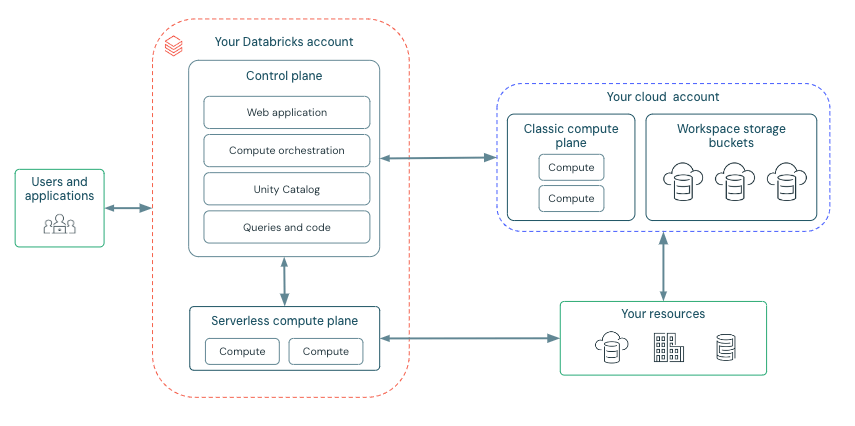
Ruta de comunicación de red
Comprendamos la ruta de comunicación que nos gustaría proteger. Azure Databricks puede ser consumido por usuarios y aplicaciones de numerosas maneras, como se muestra a continuación:
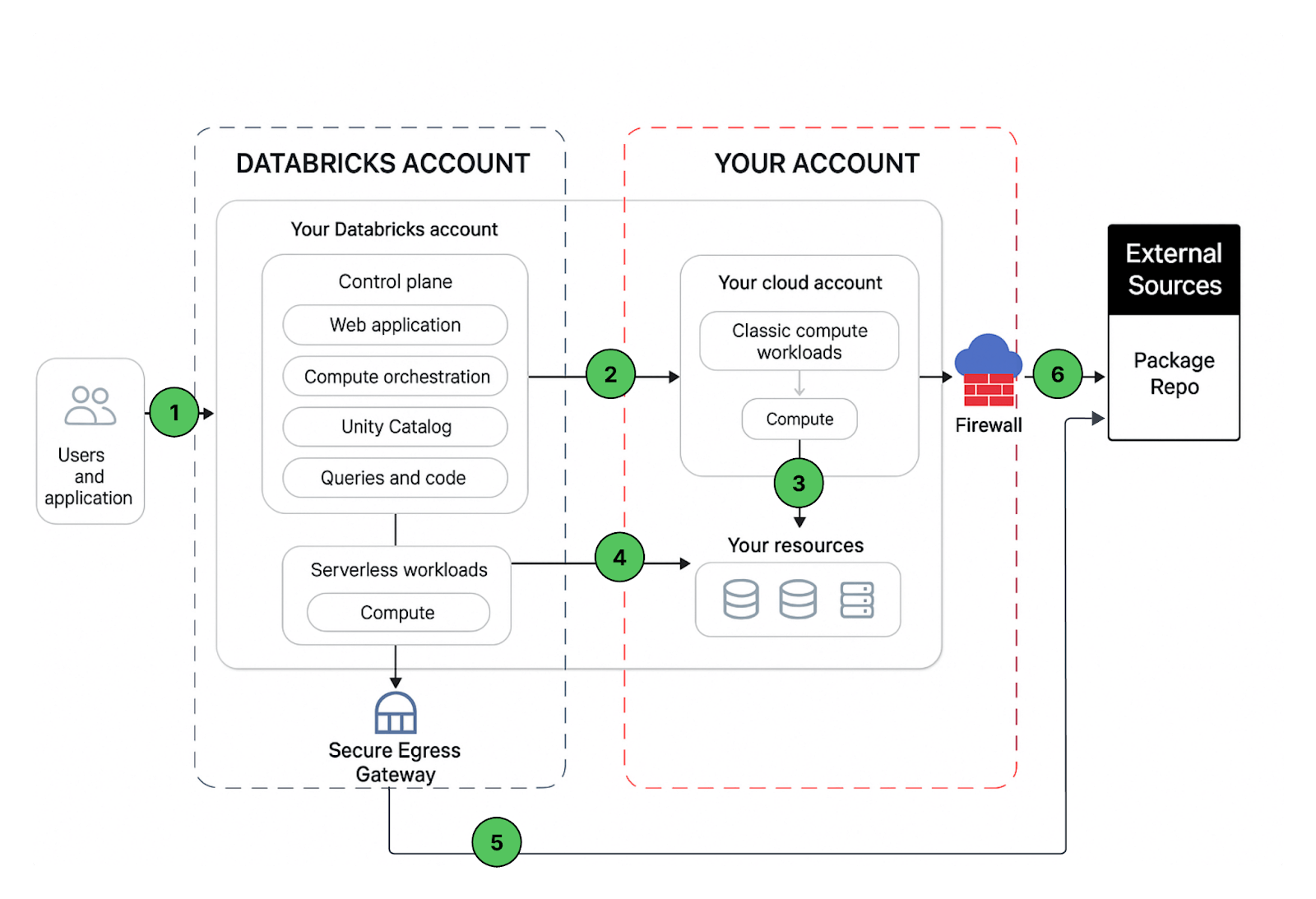
Una implementación de espacio de trabajo de Databricks incluye las siguientes rutas de red que podrías asegurar:
- Usuario o aplicaciones a la aplicación web de Azure Databricks (espacio de trabajo) o APIs REST de Databricks
- Red virtual del plano de cómputo clásico de Azure Databricks al servicio del plano de control de Azure Databricks. Esto incluye el relé de conectividad segura de clústeres y la conexión del espacio de trabajo para los puntos de conexión de la API REST.
- Plano de cómputo clásico a tus servicios de almacenamiento (por ejemplo, ADLS gen2, base de datos SQL)
- Plano de cómputo sin servidor a tus servicios de almacenamiento (por ejemplo, ADLS gen2, base de datos SQL)
- Salida segura desde el plano de cómputo sin servidor a través de políticas de red (firewall de salida) a fuentes de datos externas, por ejemplo, repositorios de paquetes como pypi o maven
- Salida segura desde el plano de cómputo clásico a través de firewall de salida a fuentes de datos externas, por ejemplo, repositorios de paquetes como pypi o maven (podría ser cualquier dispositivo de salida que se ejecute en Azure, por ejemplo, Palo Alto)
Desde la perspectiva del usuario final, el elemento 1 requiere controles de entrada y los elementos 2 a 6 requieren controles de salida.
En este artículo, nuestra área de enfoque es asegurar el tráfico de salida desde tus cargas de trabajo de Databricks, proporcionar al lector una guía prescriptiva sobre la arquitectura de implementación propuesta y, mientras lo hacemos, compartiremos las mejores prácticas para asegurar también el tráfico de entrada (usuario/cliente a Databricks).
Opciones de implementación de espacio de trabajo
Hay varias opciones disponibles para crear un espacio de trabajo seguro de Azure Databricks accesible desde conexiones locales o VPN (sin acceso a Internet). Como práctica recomendada, recomendamos proteger el acceso al espacio de trabajo usando puntos de conexión privados (Private Link), ya sea mediante una implementación estándar o simplificada. La opción recomendada es la implementación estándar. El espacio de trabajo se puede implementar a través del Portal de Azure o mediante las plantillas de ARM "Todo en uno" o utilizando las plantillas de Terraform de la Arquitectura de Referencia de Seguridad (SRA), que permiten la implementación de espacios de trabajo de Databricks y la infraestructura en la nube configurada con las mejores prácticas de seguridad.
Private Link de front-end frente a back-end: Private Link de front-end, también conocido como de usuario a espacio de trabajo. Private Link de back-end, también conocido como del plano de cómputo al plano de control:
Implementación estándar (recomendada): Para mejorar la seguridad, Databricks recomienda usar un punto de conexión privado separado para las conexiones de front-end (cliente) desde una VNet de tránsito separada. Puede implementar conexiones Private Link tanto de front-end como de back-end, o solo la conexión de back-end. Use una VNet separada para encapsular el acceso del usuario, separada de la VNet que utiliza para sus recursos de cómputo en el plano de datos clásico. Cree puntos de conexión Private Link separados para el acceso de back-end y front-end. Siga las instrucciones en Habilitar Azure Private Link como implementación estándar.
Se necesita consideración adicional para el acceso al almacenamiento del sistema, la mensajería y los metadatos desde el plano de cómputo, ya que no se puede acceder a estos servicios a través del punto de conexión privado de back-end.
Cuentas de almacenamiento administradas por el sistema (solo plano de cómputo clásico): Estas cuentas de almacenamiento son necesarias para iniciar y supervisar clústeres de Databricks. Estas cuentas de almacenamiento se encuentran en el tenant de Databricks y deben permitirse a través de políticas de puntos de conexión de servicio (recomendado); las alternativas serían usar etiquetas de servicio de almacenamiento, que tienden a ser demasiado amplias y facilitan la exfiltración de datos, o la lista de permitidos individual del FQDN o las direcciones IP (no recomendado):
- Artefacto: Imágenes de Databricks Runtime de solo lectura > 11 GB / nodo del clúster
- Registro: Mensajería intensiva de lectura/escritura, incluido el registro de auditoría.
- Tablas del sistema: Datos de auditoría, UC y del sistema de solo lectura.
Almacenamiento predeterminado del espacio de trabajo (DBFS): Sistema de archivos distribuido común utilizado para espacio temporal, servicios, resultados temporales de SQL (recuperación en la nube), controladores. Se puede proteger mediante puntos de conexión privados utilizando la función DBFS privada para el plano de cómputo clásico y el punto de conexión de servicio o el punto de conexión privado para el cómputo sin servidor.
Mensajería: (Event Hub, solo plano de cómputo clásico) Este es un recurso accesible públicamente utilizado para el seguimiento del linaje y otra mensajería ligera. Se puede permitir a través de la etiqueta de servicio EventHub en la UDR y/o el Firewall.
Metadatos: (SQL, solo plano de cómputo clásico): Este es un recurso accesible públicamente utilizado para el tráfico heredado del metastore de Hive.
Acceso a la cuenta de almacenamiento del nivel de usuario: Cuentas ALDS y Blob Storage utilizadas para datos del cliente en contraposición a datos del sistema.
Recursos de primera parte: Cosmos DB, Azure SQL, DataFactory, etc…
Recursos externos: S3, BigQuery, Snowflake, etc…
Arquitectura de Protección contra Exfiltración de Datos de Alto Nivel
Recomendamos una arquitectura de referencia de hub y spoke. En este modelo, la red virtual hub aloja la infraestructura compartida necesaria para conectarse a orígenes validados y, opcionalmente, a entornos locales. Las redes virtuales spoke se emparejan con el hub y contienen espacios de trabajo aislados de Azure Databricks para diferentes unidades de negocio o equipos.
Esta arquitectura de hub-and-spoke permite la creación de múltiples VNets de spoke adaptadas a diversos propósitos y equipos. El aislamiento también se puede lograr creando subredes separadas para diferentes equipos dentro de una única y gran red virtual. En estos casos, puede establecer múltiples espacios de trabajo aislados de Azure Databricks, cada uno dentro de su propio par de subredes, y desplegar Azure Firewall en una subred separada dentro de la misma red virtual.
Prerrequisitos
| Elemento | Detalles |
|---|---|
| Red Virtual |
|
| Subredes | Tres subredes: Host (Pública), Contenedor (Privada) y Subred de punto de conexión privado (para alojar puntos de conexión privados para el almacenamiento, DBFS y otros servicios de Azure que pueda utilizar) |
| Tablas de Rutas | Canalizar el tráfico de salida desde las subredes de Databricks hacia el dispositivo de red, Internet o las fuentes de datos locales |
| Azure Firewall | Inspeccionar cualquier tráfico de salida y tomar acciones de acuerdo con las políticas de permitir/denegar |
| Zonas DNS Privadas | Proporcionar un servicio DNS fiable y seguro para administrar y resolver nombres de dominio en una red virtual (se pueden crear automáticamente como parte de la implementación si no están disponibles) |
| Políticas de Puntos de Conexión de Servicio | Políticas para permitir el acceso a cualquier cuenta de almacenamiento que no sea de punto de conexión privado, incluido el almacenamiento del sistema para la cuenta de almacenamiento del espacio de trabajo (dbfs), el almacenamiento de artefactos y registros, y las tablas del sistema. |
| Azure Key Vault | Almacena la CMK para cifrar DBFS, Disco Administrado y Servicios Administrados. |
| Conector de Acceso de Azure Databricks | Requerido si se habilita Unity Catalog. Para conectar identidades administradas a una cuenta de Azure Databricks con el fin de acceder a los datos registrados en Unity Catalog |
| Lista de servicios de Azure Databricks para permitir en el Firewall | Siga esta documentación pública y cree una lista de todas las IP y nombres de dominio relevantes para su implementación de Databricks |
Arquitectura de Implementación
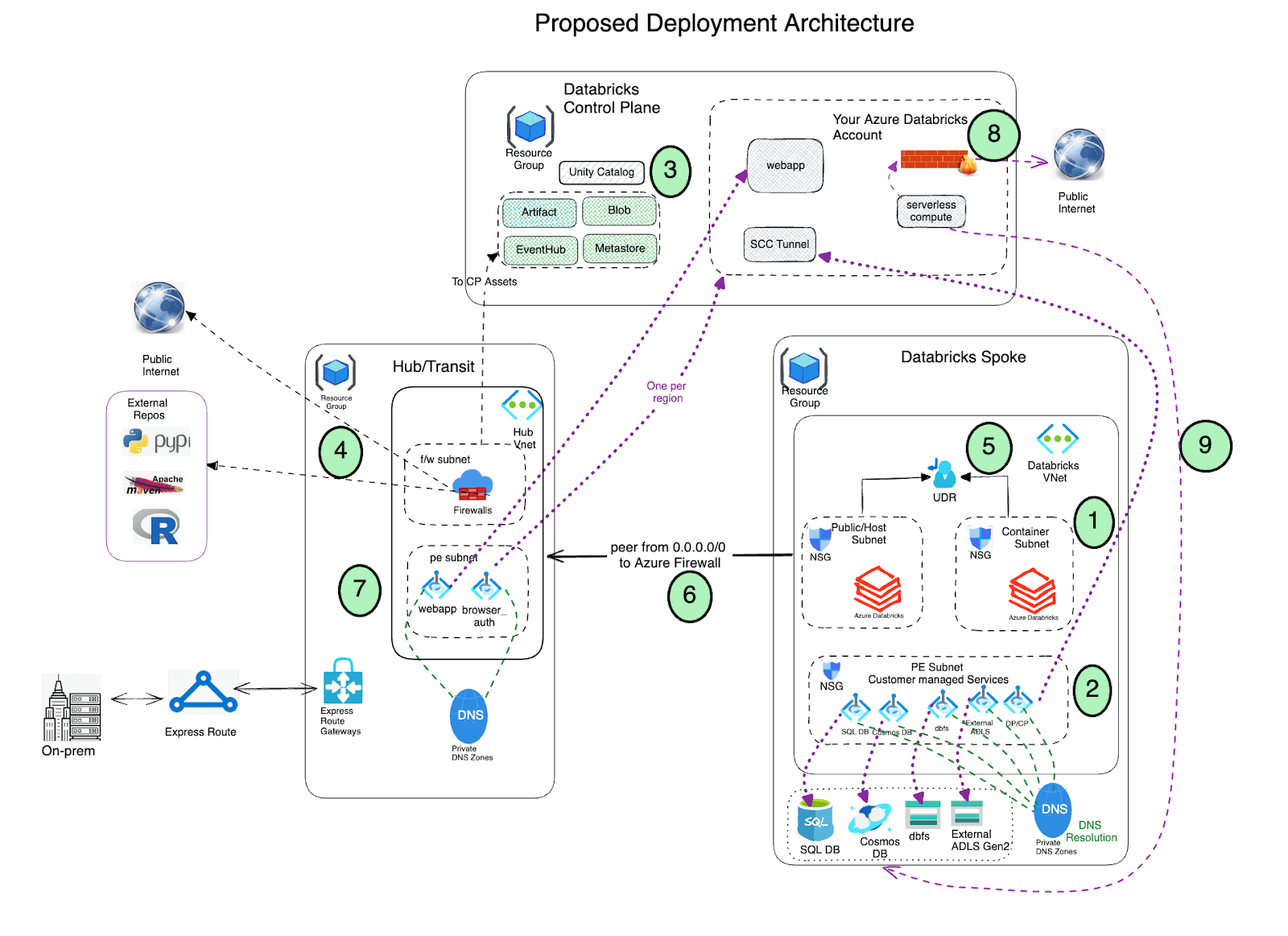
- Implemente Azure Databricks con conectividad de clúster segura (SCC) habilitada en una red virtual de spoke utilizando inyección de VNet y Private Link.
- La red virtual debe incluir dos subredes dedicadas a cada espacio de trabajo de Azure Databricks: una subred privada y una subred pública (siéntase libre de usar una nomenclatura diferente). Tenga en cuenta que existe una relación uno a uno entre estas subredes y un espacio de trabajo de Azure Databricks. No puede compartir varios espacios de trabajo en el mismo par de subredes y debe usar un nuevo par de subredes para cada espacio de trabajo diferente.
- Azure Databricks crea un blob de almacenamiento predeterminado (también conocido como almacenamiento raíz) durante el proceso de implementación, que se utiliza para almacenar registros y telemetría. Aunque el acceso público está habilitado en este almacenamiento, la Asignación de Denegación creada en este almacenamiento prohíbe cualquier acceso externo directo al almacenamiento; solo se puede acceder a él a través del espacio de trabajo de Databricks. Las implementaciones de Azure Databricks ahora admiten conectividad privada a la cuenta de almacenamiento predeterminada del espacio de trabajo (DBFS).
- Importante: Como práctica recomendada, NO se recomienda almacenar ningún dato de aplicación en el contenedor raíz (DBFS) de almacenamiento. El acceso al contenedor raíz de DBFS ahora se puede deshabilitar y, en su lugar, recomendamos usar volúmenes de Unity Catalog. Los volúmenes de Unity Catalog ofrecen gobernanza y seguridad modernas sobre el almacenamiento raíz de DBFS.
- Configura Private Link endpoints para tus servicios de datos de Azure (cuentas de almacenamiento, Eventhub, bases de datos SQL, etc.) en una subred separada dentro de la red virtual de radios de Azure Databricks. Esto aseguraría que todos los datos de la carga de trabajo se accedan de forma segura a través de la red troncal de Azure con protección de exfiltración de datos predeterminada implementada (consulta este blog para más detalles). Además, en general, está perfectamente bien implementar estos puntos de conexión en otra red virtual que esté emparejada con la que aloja el espacio de trabajo de Azure Databricks. Ten en cuenta que los puntos de conexión privados incurren en costos adicionales y está bien aprovechar (según las políticas de seguridad de tu organización) Service Endpoints en lugar de Private Endpoints para acceder a los servicios de datos de Azure, específicamente usando Service Endpoint Policies para un acceso seguro a las cuentas de almacenamiento
- Aprovecha Azure Databricks Unity Catalog para una solución de gobernanza unificada.
Implementa Azure Firewall (u otro Dispositivo de Red Virtual) en una red virtual de concentrador. Con Azure Firewall, podrías configurar:
- Reglas de aplicación que definen nombres de dominio completos (FQDN) accesibles a través del firewall. Se recomienda encarecidamente utilizar Reglas de aplicación para los recursos del plano de control de Azure Databricks control plane, por ejemplo, plano de control, aplicación web y relé SCC.
- Reglas de red que definen la dirección IP, el puerto y el protocolo para los puntos de conexión que no se pueden configurar mediante FQDN. Parte del tráfico requerido de Azure Databricks debe incluirse en la lista blanca utilizando las reglas de red.
Si utilizas un dispositivo de firewall de terceros en lugar de Azure Firewall, eso también funciona. Sin embargo, ten en cuenta que cada producto tiene sus propios matices y es mejor involucrar a los equipos de soporte de productos y seguridad de red relevantes para solucionar cualquier problema pertinente.
- La etiqueta de servicio de AzureDatabricks no es necesaria si se habilitan private endpoints para el espacio de trabajo.
- Al usar Service Endpoint Policies, no hay necesidad de reglas de red para las cuentas de almacenamiento de servicios de Databricks (artefactos, registro y tablas del sistema) en el firewall. Tampoco se necesitan ni se recomiendan etiquetas de servicio de almacenamiento.
- Azure Databricks también realiza llamadas adicionales al servicio NTP, CDN, Cloudflare, controladores de GPU y almacenamientos externos para conjuntos de datos de demostración que deben incluirse en la lista blanca de forma adecuada.
El tráfico de red no local desde las subredes del plano de cómputo de Databricks debe enrutarse a través de un dispositivo de egreso como Azure Firewall utilizando una ruta definida por el usuario (por ejemplo, una ruta predeterminada 0.0.0.0/0). Esto asegura que todo el tráfico saliente sea inspeccionado. Sin embargo, el egreso al plano de control, utilizando puntos de conexión privados, omitirá estas tablas de ruta y los dispositivos de egreso. Otros componentes del plano de control, como SQL, Event Hubs y almacenamiento, se enrutarán a través de tu dispositivo de egreso.
- Para las cuentas de almacenamiento de servicios de Databricks (artefactos, registro y tablas del sistema), puedes considerar la opción de omitir tu dispositivo de egreso (NVA o firewall) para evitar posibles limitaciones y reducir los costos de transferencia de datos. El acceso al almacenamiento de artefactos solo puede representar hasta 11 GB descargados por nodo de clúster. Recomendamos usar Service Endpoints para el almacenamiento junto con Service Endpoint Policies. Estas políticas aseguran que el espacio de trabajo solo pueda acceder a las cuentas de almacenamiento designadas de artefactos, registro y tablas del sistema incluidas en su política adjunta a través de su subred. Service Endpoint Policies también son compatibles con otro acceso a cuentas de almacenamiento que no sea de private link. Con Service Endpoint Policies, no se necesitan ni se recomiendan etiquetas de servicio de almacenamiento.
- Alternativamente, el tráfico de egreso a los activos del Plano de Control se puede enrutar directamente a Internet agregando reglas de etiqueta de servicio a la tabla de ruta, omitiendo el firewall. Esto puede ayudar a evitar limitaciones y costos adicionales de transferencia de datos asociados con los Dispositivos de Red Virtual.
Consideración importante: Ten en cuenta que esto permitirá el egreso a cuentas y servicios de almacenamiento en toda la región, no solo a aquellos a los que pretendes acceder. Este es un factor crítico a considerar cuidadosamente al diseñar tu arquitectura de seguridad.
- Configura el peering de red virtual entre los radios de Azure Databricks y las redes virtuales de concentrador de Azure Firewall.
- Implementa puntos de conexión privados para el front-end y la autenticación del navegador (para SSO) en el Vnet de Concentrador (subred de punto de conexión privado)
- Configura las políticas de red de cómputo sin servidor para gobernar el tráfico de red de egreso. Ten en cuenta que Serverless compute está vinculado a tu cuenta de Azure Databricks
- Configura la Configuración de Conectividad de Red (NCC) de Azure Databricks para establecer una conexión segura entre tus recursos de cómputo sin servidor y tus servicios de almacenamiento de Azure (como ADLS Gen2 y SQL Database) utilizando Azure Private Link.
Preguntas frecuentes sobre la arquitectura de protección contra la exfiltración de datos
¿Puedo usar Service Endpoints para proteger el egreso de datos a los servicios de datos de Azure?
Sí, Service Endpoints proporcionan conectividad segura y directa a servicios de Azure propiedad y administrados por clientes (por ejemplo, ADLS gen2, Azure KeyVault o Event Hub) a través de una ruta optimizada en la red troncal de Azure. Service Endpoints se pueden usar para asegurar la conectividad a recursos externos de Azure solo a tu red virtual.
¿Puedo usar Service Endpoint Policies con servicios de almacenamiento administrados por Databricks?
Sí, Service Endpoint Policies están disponibles en vista previa pública a partir del 10/1/2025. Ver: Configurar políticas de Service Endpoint de Azure Virtual Network para el acceso al almacenamiento desde cómputo clásico
¿Puedo usar un Dispositivo de Red Virtual (NVA) distinto de Azure Firewall?
Sí, puedes usar un NVA de terceros siempre que las reglas de tráfico de red estén configuradas como se describe en este artículo. Ten en cuenta que hemos probado esta configuración solo con Azure Firewall, aunque algunos de nuestros clientes utilizan otros dispositivos de terceros. Es ideal implementar el dispositivo en la nube en lugar de tenerlo en las instalaciones.
¿Puedo tener una subred de firewall en la misma red virtual que Azure Databricks?
Sí, puedes. Según la arquitectura de referencia de Azure, es aconsejable utilizar una topología de red virtual de concentrador y radios para planificar mejor el futuro. Si eliges crear la subred de Azure Firewall en la misma red virtual que las subredes del espacio de trabajo de Azure Databricks, no necesitarás configurar el peering de red virtual como se describe en el Paso 6 anterior.
¿Puedo filtrar el tráfico IP del relé SCC del plano de control de Azure Databricks a través de Azure Firewall?
Sí, puedes, pero nos gustaría que tuvieras en cuenta estos puntos:
- Cuando se utilizan puntos de conexión privados para el plano de control de Databricks, el tráfico entre los clústeres de Azure Databricks (plano de datos) y el servicio SCC Relay permanece privado a través de la Red de Azure y no fluye por Internet público. Este es principalmente tráfico de gestión para garantizar que el espacio de trabajo de Azure Databricks funcione correctamente.
- Cuando se utiliza acceso sin private link al plano de control de Databricks, los rangos CIDR de SCC Relay y WebUI están cubiertos por la etiqueta de servicio de AzureDatabricks. Para otros tipos de firewall / NVA, consulta la última versión de Direcciones IP y dominios para servicios y recursos de Azure Databricks. Recomendamos encarecidamente usar un FQDN de regla de aplicación para el túnel SCC en las configuraciones de reglas de tu firewall.
- El servicio SCC Relay y el plano de datos necesitan tener una comunicación de red estable y confiable. Tener un firewall o un dispositivo virtual entre ellos introduce un único punto de falla, por ejemplo, en caso de una mala configuración de alguna regla de firewall o tiempo de inactividad programado, lo que puede resultar en retrasos excesivos en el arranque del clúster (problema transitorio del firewall) o no poder crear nuevos clústeres, o afectar la programación y ejecución de trabajos.
¿Puedo analizar el tráfico aceptado o bloqueado por Azure Firewall?
Sí, recomendamos usar los Registros y métricas de Azure Firewall para ese requisito.
¿Puedo actualizar un clúster de Databricks administrado no NPIP existente a un área de trabajo NPIP o Habilitada para PL?
Sí, el despliegue administrado de Databricks se puede actualizar a un área de trabajo Inyectada en VNet.
¿Por qué necesitamos dos subredes por área de trabajo?
Un área de trabajo requiere dos subredes, conocidas popularmente como subredes de "host" (también conocidas como "públicas") y "contenedor" (también conocidas como "privadas"). Cada subred proporciona una dirección IP al host (Azure VM) y al contenedor (el runtime de Databricks, también conocido como dbr) que se ejecuta dentro de la VM.
¿La subred pública o de host tiene IPs públicas?
No, cuando crea un área de trabajo utilizando la conectividad segura de clúster, también conocida como SCC, ninguna de las subredes de Databricks tiene direcciones IP públicas. Es solo que el nombre predeterminado de la subred de host es subred-pública. SCC se asegura de que ningún tráfico de red desde fuera de su red entre, por ejemplo, por SSH a una de las instancias de cómputo del área de trabajo de Databricks.
¿Es posible cambiar el tamaño/modificar los tamaños de las subredes después del despliegue?
Sí, es posible cambiar el tamaño o modificar los tamaños de las subredes después del despliegue. También es posible cambiar la red virtual o cambiar los nombres de las subredes (vista previa pública controlada). Comuníquese con el soporte de Azure y envíe un caso de soporte para cambiar el tamaño de las subredes.
¿Es posible intercambiar/cambiar Redes Virtuales después del despliegue?
Sí, consulte la documentación pública.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.