Databricks en SIGMOD 2026
por Indrajit Roy
- Descubre cómo Databricks está liderando la próxima generación de ingeniería de datos con Spark Declarative Pipelines (SDP), simplificando cargas de trabajo complejas de ETL y streaming.
- Obtén una inmersión profunda en Enzyme, nuestro motor de mantenimiento incremental de vistas, que ganó una mención de honor en la conferencia SIGMOD.
- Conoce a nuestros ingenieros en la conferencia para discutir estas innovaciones líderes en la industria.
Databricks continúa liderando la innovación en ingeniería, ampliando constantemente los límites de lo posible en el espacio de Datos e IA. Nos complace anunciar que nuestro trabajo en Spark Declarative Pipelines se presentará en SIGMOD 2026 y ha recibido una mención de honor en la conferencia. Asistiremos a SIGMOD, del 1 al 5 de junio, como patrocinador Platino. SIGMOD se llevará a cabo en Bangalore, India, que también es un gran centro de I+D de Databricks.
Nuestros próximos artículos sobre ingeniería de datos muestran cómo Databricks ha simplificado el procesamiento incremental para los clientes. Hay dos formas de escribir programas incrementales en Spark Declarative Pipelines (SDP), y los clientes pueden combinarlas dentro de una canalización:
- Los ingenieros de datos pueden especificar Vistas Materializadas para las transformaciones. El motor Enzyme las mantiene incrementalmente a medida que llegan nuevos datos. Toda la complejidad del procesamiento incremental está completamente oculta para los creadores de las vistas materializadas. El artículo de SIGMOD 2026 “Enzyme: Incremental View Maintenance for Data Engineering” discute algunas de estas ideas.
- Los ingenieros de datos que dominan el procesamiento de flujos pueden usar en su lugar el motor de streaming de SDP para procesar datos incrementalmente. Las API de streaming proporcionan una amplia variedad de construcciones, desde operadores con estado hasta marcas de agua, lo que facilita la expresión de lógica de negocio complicada como agregaciones personalizadas. Las ideas clave de nuestro producto de streaming aparecerán en el artículo de VLDB 2026 “A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs”.
Aquí hay un adelanto del artículo de Enzyme y en qué ha estado trabajando el equipo:
Enzyme en SIGMOD 2026
Mantenimiento Incremental de Vistas
Digamos que eres un analista en una empresa y quieres analizar el número total de pedidos vendidos en una región. La vista materializada a continuación proporciona la respuesta.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
A medida que se agregan nuevos pedidos, esperas que la vista materializada se mantenga actualizada. Este mantenimiento de datos es esencialmente el problema de mantenimiento incremental de vistas. Si bien mantener actualizada la MV de juguete anterior parece simple, imagina si la MV necesitara unir datos de múltiples tablas, tuviera funciones de ventana o hiciera llamadas a funciones LLM.
Innovaciones de Enzyme
Las vistas materializadas (MV) son populares para la aceleración de consultas, acelerando los paneles en datos que residen en almacenes de datos. Al crear Spark Declarative Pipelines, decidimos ir más allá de la aceleración de consultas y aplicar vistas materializadas a los casos de uso extract-transform-load (ETL). Nuestra observación clave es que si las MV se pueden mantener de manera eficiente e incremental, simplificarán significativamente las cargas de trabajo ETL que de otro modo requerirían escribir código personalizado complejo.
Enzyme se suma a la rica literatura sobre el mantenimiento incremental de vistas materializadas y demuestra cómo escalar estas técnicas en cargas de trabajo de producción. Algunas de las innovaciones en las que trabajó el equipo son:
- Soporte para patrones extensos de MV: Enzyme mantiene incrementalmente MV complejas en producción, incluidas aquellas con uniones, funciones de ventana, agregaciones y sus combinaciones. A diferencia de otras soluciones de la industria, Enzyme también admite funciones no deterministas como current_date() y funciones específicas de IA.
- Soporte multilingüe: Mientras que la mayoría de las soluciones de la industria solo se centran en SQL, Enzyme también admite MV especificadas en Python. Python es ahora el lenguaje de elección para la mayoría de las cargas de trabajo de ingeniería de datos e IA. Enzyme resuelve muchos desafíos interesantes que implica el soporte multilingüe, como la detección precisa de cambios en la definición de MV.
- Optimizaciones de rendimiento: Enzyme tiene múltiples optimizaciones para reducir la cantidad de datos que deben procesarse, incluidas técnicas que determinan automáticamente si las actualizaciones deben aplicarse a nivel de partición en lugar de a nivel de fila, reduciendo así los sobrecostos de reescritura. Almacena en caché selectivamente resultados intermedios para reducir los costos de E/S. Utiliza un modelo de costos que aprovecha la información del plan y las ejecuciones anteriores para determinar la estrategia de incrementalización más eficiente.
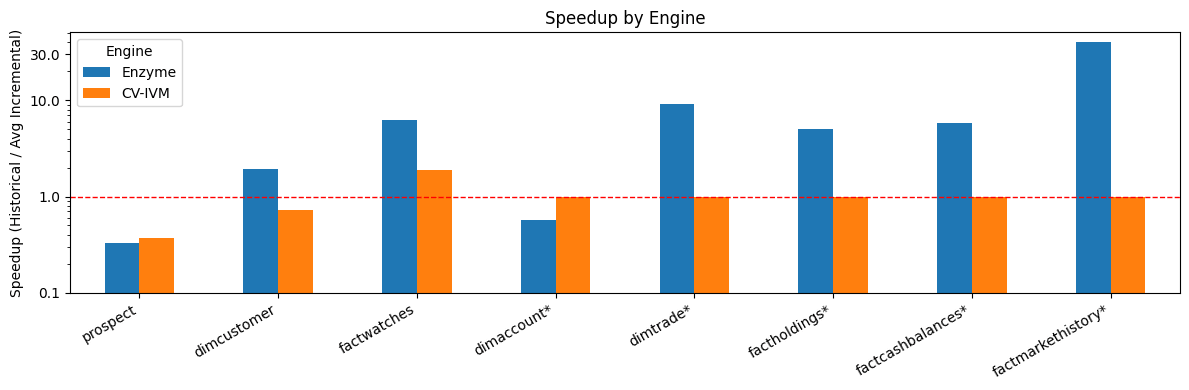
Figura 1: Enzyme tiene un rendimiento significativamente mejor que otra solución de la industria competidora (nombre anonimizado a CV-IVM debido a restricciones de licencia).
¿Interesado en aprender más? Consulta el artículo y si estás en SIGMOD, asiste a nuestra charla para más detalles.
Conoce al equipo en SIGMOD:
Pasa por nuestro stand para conocer al equipo y aprender más sobre la innovación que está ocurriendo en Databricks. ¡Además, no pierdas la oportunidad de escuchar directamente a Ritwik Yadav durante su presentación en SIGMOD!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.