Desacoplado por diseño: búsqueda de vectores a escala de miles de millones
por Zero Qu, Erik Lindgren, Sheng Zhan, Ankit Vij, Sergei Tsarev y Dima Kotlyarov
Introducción
La búsqueda vectorial se ha convertido en una infraestructura fundamental para las aplicaciones de IA, desde la búsqueda dentro del producto hasta los sistemas de recomendación, la resolución de entidades y la generación aumentada por recuperación. Pero a medida que los conjuntos de datos crecen de millones a miles de millones de vectores, los sistemas creados para servirlos comienzan a fallar de maneras costosas: los costos de memoria se disparan, la ingesta detiene el servicio y el escalado requiere replicar todo.
En Databricks, nos encontramos con estos límites con nuestra solución original de búsqueda vectorial, por lo que volvimos a los principios básicos y la rediseñamos desde cero. Hoy en día, AI Search de Databricks ofrece dos opciones de implementación: endpoints estándar, que mantienen vectores de precisión completa totalmente en memoria para una latencia de decenas de milisegundos, y endpoints optimizados para el almacenamiento, que separan el almacenamiento del cómputo para servir miles de millones de vectores a una fracción del costo, con latencias de consulta de cientos de milisegundos, una compensación deliberada para cargas de trabajo donde el costo y la escala importan más que los tiempos de respuesta de pocos milisegundos.
Storage Optimized AI Search se basó en tres decisiones de ingeniería fundamentales:
- Separar el almacenamiento del cómputo. Los índices vectoriales residen en el almacenamiento de objetos en la nube y se cargan en la memoria solo para el servicio. La ingesta se ejecuta en clústeres efímeros de Spark sin servidor, completamente aislada de la ruta de consulta.
- Desarrolla algoritmos de indexación distribuida en Spark. En lugar de depender de bibliotecas de indexación de una sola máquina, desarrollamos las nuestras (clustering distribuido, compresión de vectores y diseño de datos alineado a particiones) como trabajos nativos de Spark que escalan linealmente con el tamaño del clúster.
- Procesa consultas desde un motor de Rust con una arquitectura de tiempo de ejecución dual. Un motor de consultas diseñado específicamente utiliza grupos de subprocesos separados para E/S asíncrona y computación de vectores vinculada a la CPU, de modo que ninguno sature al otro.
El resultado: índices de mil millones de vectores creados en menos de 8 horas, una indexación 20 veces más rápida y costos de servicio hasta 7 veces más bajos.
Este post es la historia de ingeniería de cómo lo construimos.
El problema de las bases de datos vectoriales tradicionales
Los límites del acoplamiento estricto
Muchas bases de datos de vectores de producción, incluida nuestra Búsqueda de Vectores Estándar, siguen una arquitectura de nada compartido tomada de la búsqueda de palabras clave distribuida. Cada nodo posee un fragmento aleatorio del conjunto de datos y mantiene un gráfico de HNSW (mundo pequeño navegable jerárquico) independiente en memoria sobre vectores de precisión completa. HNSW ofrece una excelente calidad de búsqueda, pero el gráfico en sí debe residir completamente en la memoria, lo que lo convierte en uno de los componentes más caros de escalar. Este diseño ofrece baja latencia y admite actualizaciones transaccionales. Funciona bien hasta con cientos de millones de vectores.
A miles de millones, se desmorona.
El problema principal es el acoplamiento. El índice, los datos sin procesar y la computación que los sirve están todos vinculados al mismo nodo. Escalar significa replicarlo todo: más vectores requieren más memoria, lo que requiere más nodos, y cada uno de ellos lleva una copia completa del índice y los datos de su shard. No hay forma de escalar el almacenamiento independientemente de la computación.
El acoplamiento se extiende a la ingesta. La creación del índice se realiza dentro del propio motor de búsqueda: los mismos recursos de computación que gestionan las consultas también se encargan de la reorganización de datos, las reconstrucciones de índices y la compactación. Bajo cargas de trabajo con mucha escritura, la latencia de las consultas se degrada. Bajo cargas de trabajo con muchas consultas, la ingesta se vuelve extremadamente lenta. Peor aún, cada cambio en los datos (una actualización o inserción, una eliminación, una compactación) desencadena reconstrucciones de subíndices, lo que consume ciclos de CPU en mantenimiento en lugar de atender consultas.
Los índices residentes en memoria son costosos
Esa residencia en memoria es lo que hace que la arquitectura sea rápida, y lo que la hace costosa. Con 768 dimensiones con flotantes de 32 bits, 100 millones de vectores consumen aproximadamente 286 GiB de RAM, solo para los vectores, antes de cualquier sobrecarga del índice. Mil millones de vectores requerirían terabytes. A diferencia del almacenamiento en disco o de objetos, donde el costo por gigabyte es insignificante, la memoria es el recurso más caro del stack. Cada vector agregado aumenta la factura de RAM directamente.
La fragmentación aleatoria agrava el problema. Debido a que los vectores se distribuyen sin tener en cuenta la similitud semántica, cada consulta debe dispersarse en todos los fragmentos y recopilar los resultados, independientemente de cuán relevante sea cada fragmento. El uso de CPU, la sobrecarga de red y la latencia de cola aumentan con el número de fragmentos. Agregar vectores significa agregar shards, y cada nuevo shard contiene su propio índice residente en memoria.
Desacoplado por diseño
La respuesta no es optimizar dentro de esta arquitectura, sino romper el acoplamiento en sí.
La búsqueda de vectores optimizada para el almacenamiento parte de una única premisa: todos los datos residen en el almacenamiento de objetos en la nube y los nodos de consulta son sin estado. Esto divide el sistema en dos límites (el almacenamiento del cómputo, de modo que los nodos de consulta no poseen datos; la ingesta del servicio, de modo que la creación de índices nunca compite con las consultas en tiempo real) y da lugar a una arquitectura de tres capas:
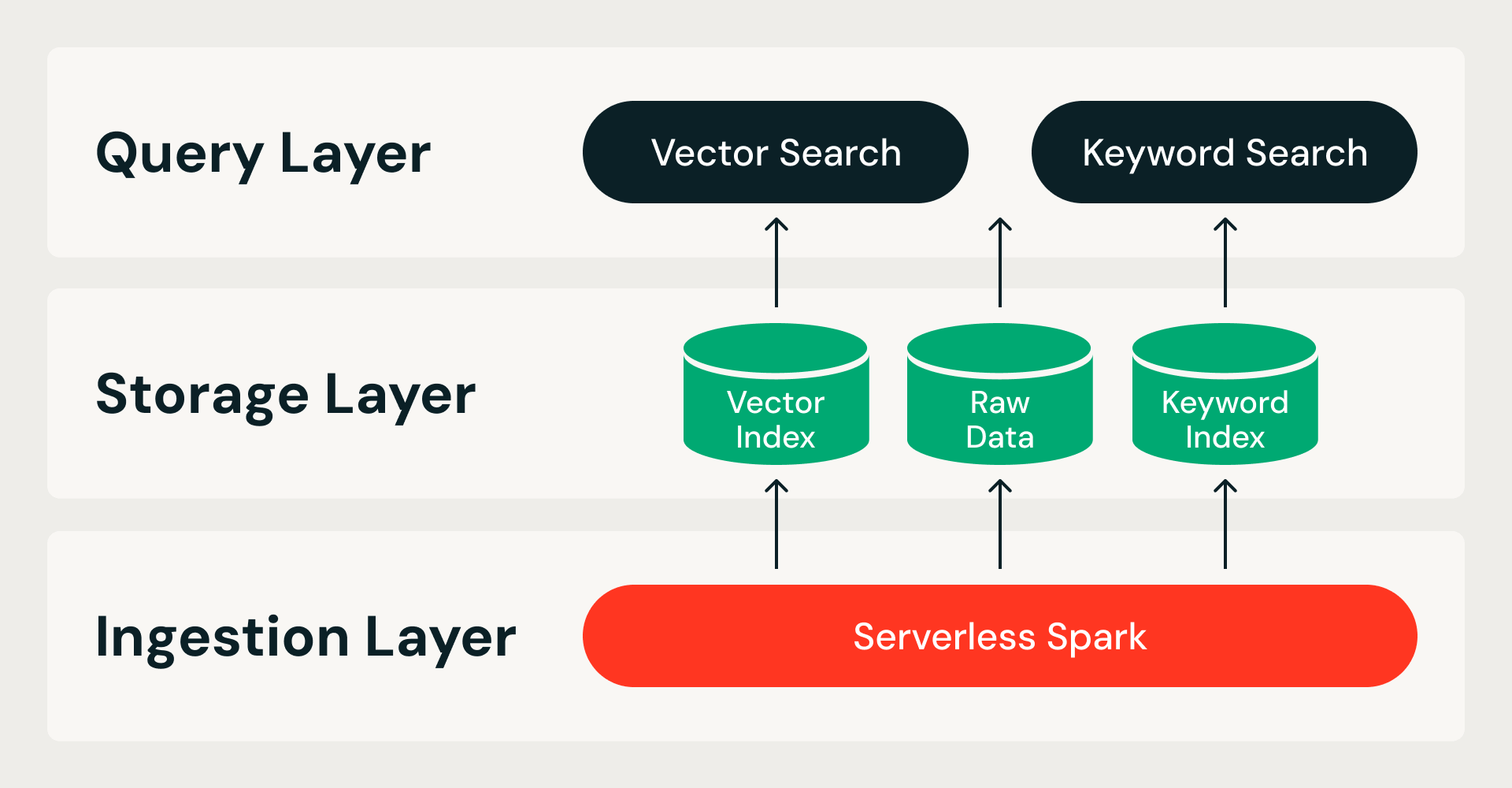
- Capa de ingesta. Un pipeline distribuido en Spark sin servidor maneja toda la construcción del índice, desde los datos brutos hasta el índice finalizado. Cada ejecución es idempotente y reintentable.
- Capa de almacenamiento. Un formato de almacenamiento personalizado y nativo de la nube sirve como el sistema de registro. Combina un formato de archivo columnar para datos sin procesar e índices de vectores con un formato de índice invertido para la búsqueda de palabras clave, todo bajo transacciones ACID con fragmentos de datos inmutables.
- Capa de consulta. Dos servicios sin estado gestionan las lecturas. El servicio de búsqueda de vectores mantiene un índice comprimido en la memoria y obtiene datos de precisión completa del almacenamiento de objetos bajo demanda. La búsqueda por palabras clave sirve índices invertidos para el filtrado de metadatos y la búsqueda por palabras clave. Ambos servicios se escalan de forma independiente, de modo que los recursos se pueden ajustar para que coincidan con la carga de trabajo.
Una estructura de índice para el almacenamiento de objetos
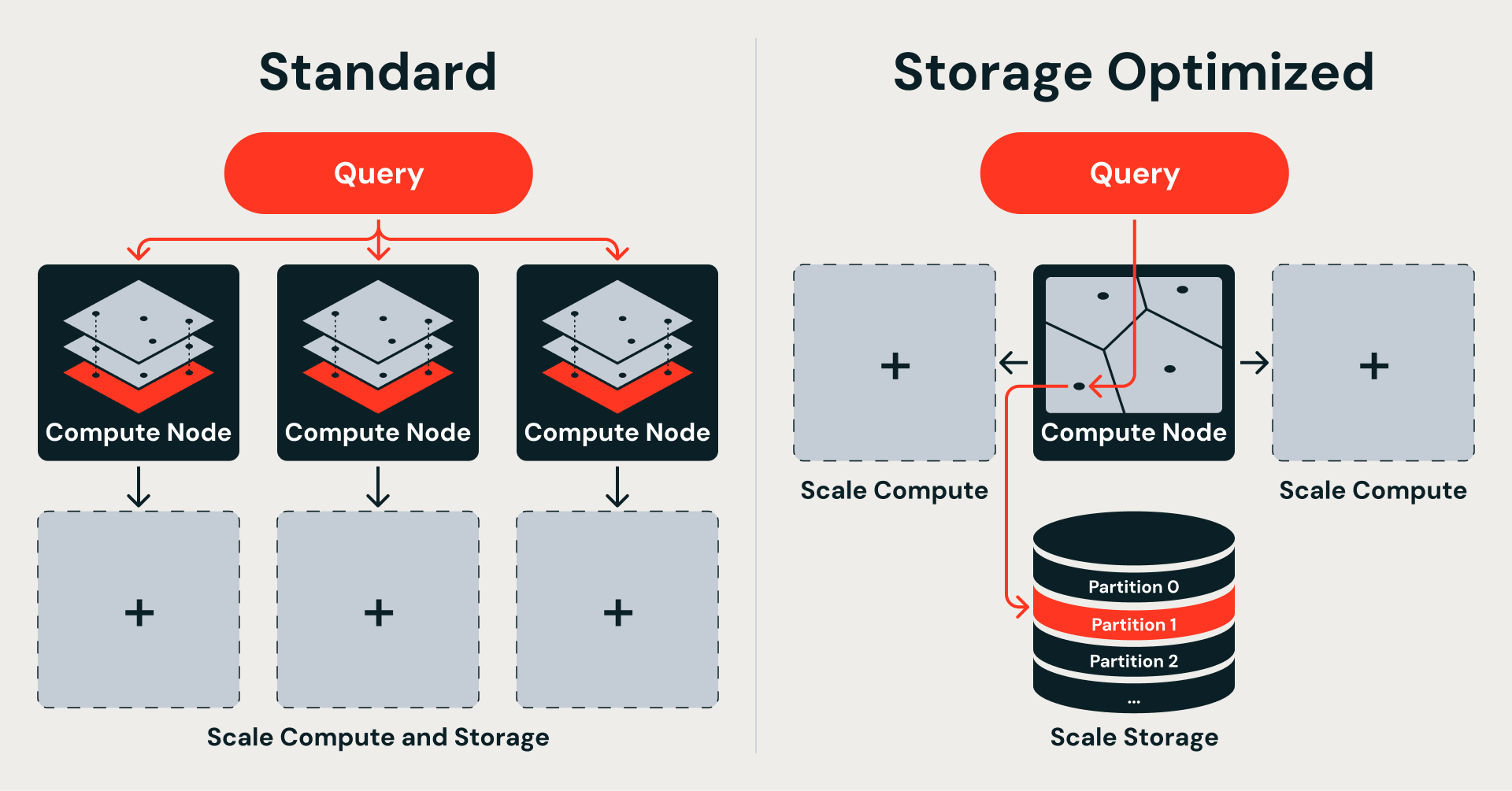
Si los datos residen en un almacenamiento de objetos, el índice debe ser particionable: el motor de consultas necesita obtener solo las porciones relevantes, no cargar toda la estructura en la memoria.
Los grafos HNSW no tienen esa propiedad. Cada salto de búsqueda puede saltar a cualquier parte del grafo, por lo que la estructura completa debe residir en la memoria para atender una sola consulta. No hay una forma natural de dividir un grafo HNSW en fragmentos que se asignen a archivos de almacenamiento de objetos.
El IVF (Índice de archivos invertidos) adopta un enfoque diferente: agrupa los vectores por proximidad alrededor de centroides aprendidos y busca solo en los clústeres más cercanos en el momento de la consulta. Cada clúster se asigna directamente a un fragmento de datos en el almacenamiento de objetos, y se puede recuperar de forma independiente, sin cargar el resto del índice.
Esta elección del algoritmo se deriva directamente de dónde residen los datos. La búsqueda vectorial estándar mantiene el índice completo en la memoria para mayor velocidad, lo que vincula el almacenamiento y el cómputo. La optimización para el almacenamiento traslada los datos al almacenamiento de objetos para escalar, lo que los libera, pero requiere un índice que se descomponga en particiones autónomas y recuperables. IVF proporciona exactamente eso:
Indexación de vectores distribuida en Spark
IVF nos da la estructura de índice adecuada para el almacenamiento separado. El desafío de ingeniería es construirlo a escala. La mayoría de las bibliotecas de indexación de vectores (FAISS, ScaNN, Annoy) asumen que todos tus datos caben en una sola máquina. Eso funciona con decenas de millones de vectores. Con mil millones de vectores con incrustaciones de 768 dimensiones, estamos hablando de terabytes de datos brutos de punto flotante incluso antes de empezar a crear un índice. Ninguna máquina por sí sola lo gestiona bien, e incluso si lo hiciera, el tiempo de ingesta se convierte en un cuello de botella en serie que crece con cada nueva fila.
Necesitábamos una indexación que escalara horizontalmente. Así que implementamos cada algoritmo de indexación desde cero (K-means distribuido, cuantización de productos y diseño de datos alineado con particiones) como trabajos nativos de PySpark que se ejecutan en clústeres efímeros de Spark sin servidor. Sin bibliotecas de indexación de una sola máquina en la ruta crítica. Agregar más ejecutores reduce linealmente el tiempo para los pasos más costosos.
La canalización de ingesta
Cada ejecución de ingesta se ejecuta como un grafo acíclico dirigido de etapas, envuelto en una transacción ACID.
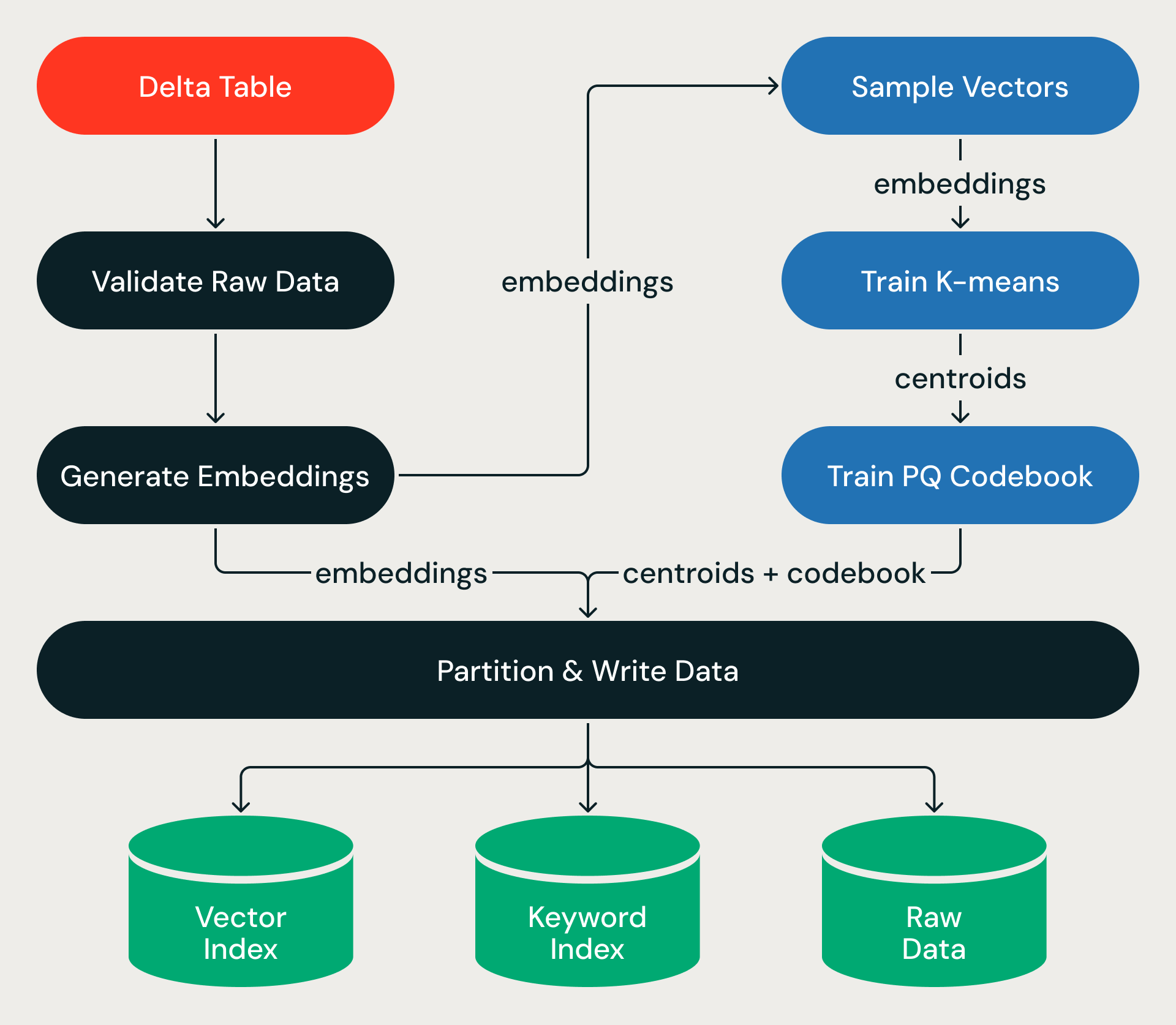
El pipeline se inicia a partir de una Delta Table de origen. Para los índices respaldados por texto de origen (en lugar de vectores precalculados), después de validar los datos de origen, el pipeline llama a Databricks Model Serving para generar incrustaciones de vectores para filas nuevas o actualizadas, convirtiendo miles de millones de registros de texto en vectores de alta dimensión a gran escala.
A partir de ahí, la canalización se entrena con una pequeña muestra (aprendiendo la estructura del espacio vectorial) y luego aplica esa estructura al conjunto de datos completo, asignando cada vector a una partición, comprimiéndolo y escribiendo los resultados en el almacenamiento de objetos. El entrenamiento es barato; la pasada por el conjunto de datos completo, que mueve terabytes de datos entre ejecutores, es donde se va el tiempo de ejecución real.
K-means: Particionamiento a escala
El agrupamiento K-means particiona el espacio vectorial en regiones (las particiones IVF) que permiten a las consultas buscar una fracción de los datos en lugar de la totalidad. Para un conjunto de datos de mil millones de filas, creamos aproximadamente 32K particiones. La pregunta es: ¿cómo se ejecuta K-means a esta escala cuando las implementaciones estándar suponen que todos los datos caben en una sola máquina?
Lo construyes desde cero en Spark.
Nuestra implementación utiliza un modelo híbrido: Spark se encarga del movimiento de datos distribuido, mientras que JAX (una biblioteca de computación numérica con álgebra lineal acelerada por hardware) se encarga de las matemáticas dentro de cada ejecutor. Cada iteración de K-means es un pipeline de Spark de tres pasos:
- Asignar: cada ejecutor calcula las distancias desde su lote local de vectores a todos los centroides actuales, encontrando el clúster más cercano para cada vector.
- Shuffle: Spark reparticiona los datos por ID de centroide, coubicando todos los vectores asignados al mismo clúster.
- Agregar: cada ejecutor calcula las nuevas posiciones de los centroides a partir de sus vectores coubicados.
El cálculo de la distancia es el bucle crítico. JAX lo compila en una única operación de matriz por lotes por ejecutor, calculando la matriz completa de distancia de lote por centroide de una vez en lugar de iterar sobre vectores individuales.
El entrenamiento se ejecuta sobre una muestra, no sobre el conjunto de datos completo; para mil millones de filas, aproximadamente 8 millones de vectores (~0.8 % de los datos). Esto no es arbitrario: el costo por iteración de K-means es O(n × k × d), donde n es el tamaño de la muestra, k el número de clústeres y d la dimensión. Establecer tanto n como k proporcionales a √N hace que el costo total de entrenamiento sea O(N × d), lineal con respecto al tamaño del conjunto de datos, independientemente de la escala.
Esta elección también tiene un buen fundamento estadístico: la teoría de coreset muestra que las muestras O(k) son suficientes para un agrupamiento k-means de alta calidad en datos bien distribuidos y, como k escala con √N, nuestro tamaño de muestra es demostrablemente adecuado. El entrenamiento se completa en unas pocas iteraciones y guarda los centroides en el almacenamiento de objetos para las etapas posteriores de la canalización.
Cuantización de productos: Compresión de memoria de 64x
K-means nos da particiones generales. La Cuantificación de Producto (PQ) comprime los vectores para que podamos realizar búsquedas dentro de ellos a escala. La idea: dividir cada vector de 768 dimensiones en 48 subvectores de 16 dimensiones cada uno y reemplazar cada subvector con un único byte que apunte a la entrada más cercana en un libro de códigos aprendido. Un vector de 3072 bytes se convierte en 48 bytes, una relación de compresión de 64x. Para mil millones de vectores de 768 dimensiones, eso reduce casi 3 TiB de datos sin procesar a aproximadamente 45 GiB.
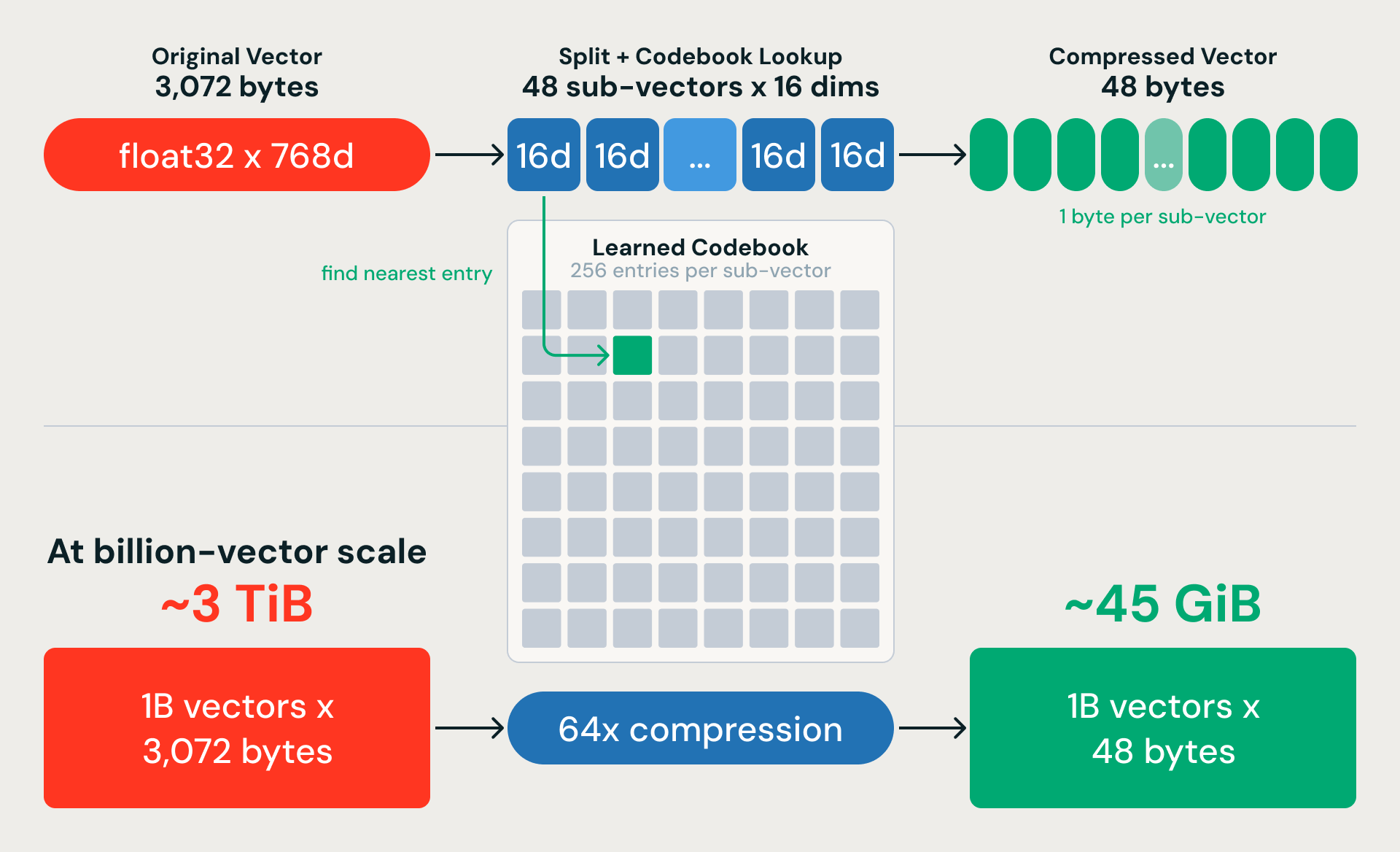
La compresión es con pérdida, pero una decisión de diseño clave recupera la mayor parte de la precisión: entrenamos PQ en vectores residuales (la diferencia entre cada embedding y su centroide de K-means más cercano) en lugar de en los embeddings sin procesar. K-means captura la estructura a gran escala; PQ solo necesita codificar la variación detallada dentro de cada partición.
Del entrenamiento al almacenamiento
Con los centroides y los libros de códigos de PQ entrenados en la muestra, la canalización ahora procesa cada fila, asignando a cada vector un ID de partición (su centroide más cercano) y un código de PQ comprimido. Para un conjunto de datos de mil millones de filas, esta es la etapa más intensiva en datos del pipeline: un trabajo de Spark de conjunto de datos completo que calcula distancias y codificaciones en cada ejecutor.
Luego viene la redistribución. El pipeline vuelve a particionar todo el conjunto de datos por ID de partición, coubicando físicamente los vectores de la misma partición IVF en los mismos fragmentos de datos en el almacenamiento de objetos. Esto es costoso (terabytes de datos se mueven entre los executors), pero es lo que hace que las consultas sean rápidas. Sin la coubicación, sondear una sola partición IVF dispersaría las lecturas a través de miles de archivos. Con ella, el mismo sondeo accede a un puñado de fragmentos contiguos.
La escritura produce tres salidas, cada una optimizada para una ruta de consulta diferente:
- Índice de vectores: códigos PQ comprimidos y metadatos de partición, escritos en un formato que el motor de consultas carga en la memoria para una búsqueda rápida de ANN.
- Índice de palabras clave: archivos de índice invertido para el filtrado de metadatos y la búsqueda híbrida por palabras clave.
- Datos en bruto: incrustaciones de precisión completa almacenadas en un formato columnar optimizado tanto para escaneos secuenciales como para acceso aleatorio, que se recuperan bajo demanda durante la reclasificación.
Los tres se escriben como fragmentos inmutables: una vez escritos, nunca se modifican. Cuando se completa la escritura, un manifiesto de versión publica atómicamente el nuevo índice. Este es el contrato entre la ingesta y el servicio: un conjunto de fragmentos de datos inmutables y alineados por partición en el almacenamiento de objetos, listos para que el motor de consultas los lea directamente.
Ingesta a escala
La opción optimizada para el almacenamiento admite índices de más de mil millones de vectores de 768 dimensiones, un gran avance en comparación con la búsqueda vectorial estándar, que tiene un límite de 320 millones de vectores.
Debido a que la ingesta se ejecuta en clústeres efímeros de Spark, totalmente desacoplada del servicio, escalar es una cuestión de añadir ejecutores. En la práctica, esto se traduce en mejoras de un orden de magnitud en las compilaciones de índices de producción:

Una vez que el índice se escribe y se publica atómicamente en el almacenamiento de objetos, la siguiente pregunta es: ¿cómo se atienden las consultas contra este lo suficientemente rápido para producción?
Un motor de consultas para el almacenamiento de objetos
Separar el almacenamiento del cómputo resuelve el problema del costo. Pero introduce uno nuevo: cada consulta ahora implica viajes de ida y vuelta de red al almacenamiento de objetos. El índice comprimido (lo suficientemente pequeño como para caber en la memoria) se carga al iniciar, pero los embeddings de precisión completa permanecen en el almacenamiento de blobs y se recuperan bajo demanda o se sirven desde una caché de disco local. La capa de servicio tiene que ser lo suficientemente rápida para que el movimiento de datos fuera del nodo no comprometa la latencia de la consulta.
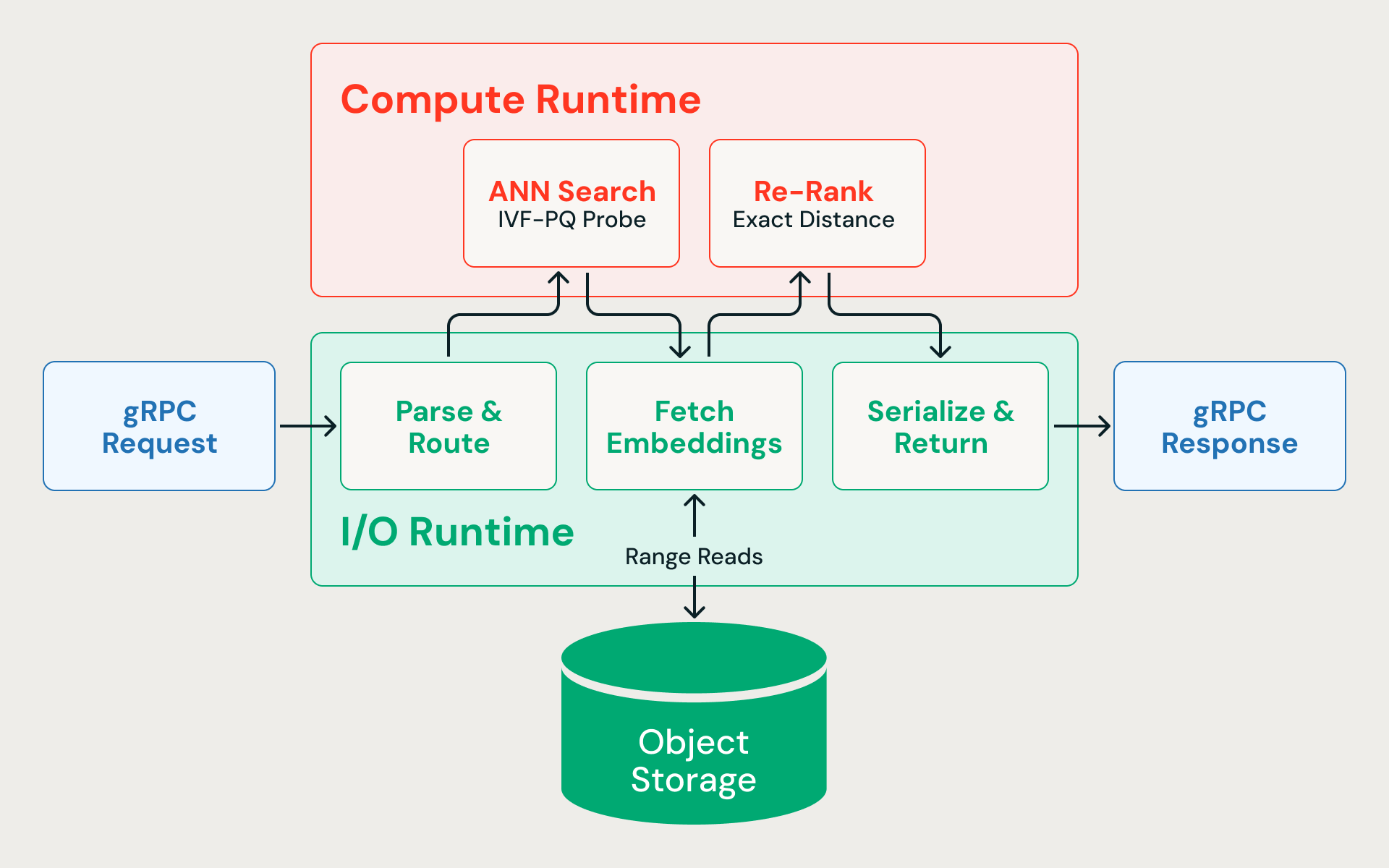
Anatomía de una consulta
Esto es lo que sucede cuando una búsqueda de vecino más cercano llega al motor:
- Analizar & enrutar (E/S). La solicitud gRPC llega al entorno de ejecución de E/S asíncrono, se deserializa y se enruta al índice correcto.
- Búsqueda ANN (CPU). El vector de consulta se compara con los centroides del clúster IVF para identificar las particiones más relevantes. Solo se sondean esas particiones, escaneando los vectores comprimidos para calcular distancias aproximadas. La búsqueda recupera deliberadamente un exceso de candidatos (por ejemplo, recuperando 400 cuando el solicitante pide 10) porque las distancias cuantificadas son aproximadas y una red inicial más amplia mejora el 'recall' final después de la reclasificación.
- Recuperar vectores de precisión completa (E/S). Las lecturas concurrentes de rango de bytes recuperan los embeddings sin procesar para cada candidato del almacenamiento en la nube. Debido a que el pipeline de ingesta coubica las filas de la misma partición IVF en el mismo fragmento de datos, estas lecturas se podan por partición, accediendo a un número reducido de archivos en lugar de acceder aleatoriamente a todo el conjunto de datos. Este paso domina la latencia de extremo a extremo.
- Reordenar (CPU). Las incrustaciones de precisión completa se puntúan mediante el cálculo de distancia exacta, recuperando la precisión perdida por la compresión.
- Serializar & devolver (E/S). Los resultados finales top N se serializan con sus metadatos asociados y se envían de vuelta a quien realizó la llamada.
Cada consulta alterna entre E/S asíncrona y cómputo ligado a la CPU. Si los cálculos de distancia bloquean el runtime asíncrono, las lecturas de almacenamiento pendientes se acumulan y la latencia se dispara.
Dos runtimes
La solución es nunca dejar que compitan por los mismos hilos. El motor de consultas, escrito en Rust para una latencia predecible sin pausas de GC, divide la ejecución en dos grupos de hilos dedicados: uno para E/S asíncrona y otro para cálculos vectoriales ligados a la CPU. Ninguna de las cargas de trabajo puede dejar sin recursos a la otra.
El tiempo de ejecución de E/S se ejecuta en el ejecutor asíncrono de Tokio y gestiona el análisis de solicitudes gRPC, las lecturas de rango del almacenamiento de blobs, la comunicación entre servicios y la serialización de respuestas. Debido a que las lecturas de almacenamiento son el cuello de botella de la latencia, este tiempo de ejecución necesita mantener cientos de solicitudes simultáneas en curso sin bloqueo.
El entorno de ejecución de cómputo ejecuta cálculos de distancia de vectores, sondeo de particiones y reclasificación en su propio grupo de hilos. Un subconjunto de núcleos de CPU se reserva explícitamente para el entorno de ejecución de E/S; al cómputo nunca se le permite consumir la máquina completa.
Fusión de lectura
Más allá del aislamiento de subprocesos, la propia ruta de E/S requería ajustes. El análisis de rendimiento inicial reveló que el motor estaba emitiendo muchas lecturas de rango pequeñas de un solo vector al almacenamiento de objetos. Cada llamada conlleva una sobrecarga por solicitud y variabilidad de la latencia (con colas largas que alcanzan cientos de milisegundos), por lo que muchas solicitudes diminutas significaban una alta varianza de latencia por consulta.
La solución fue la coalescencia de lectura: en lugar de emitir una lectura de rango por vector, la capa de almacenamiento ordena las solicitudes de rango de bytes pendientes por desplazamiento de archivo y fusiona cualquiera que se encuentre dentro de una ventana de tamaño de bloque configurable en una sola lectura. Menos solicitudes, pero de mayor tamaño, implican menos sobrecarga por llamada, pero cada lectura fusionada también recupera bytes que la consulta no necesita: amplificación de lectura. La compensación requirió un ajuste empírico.
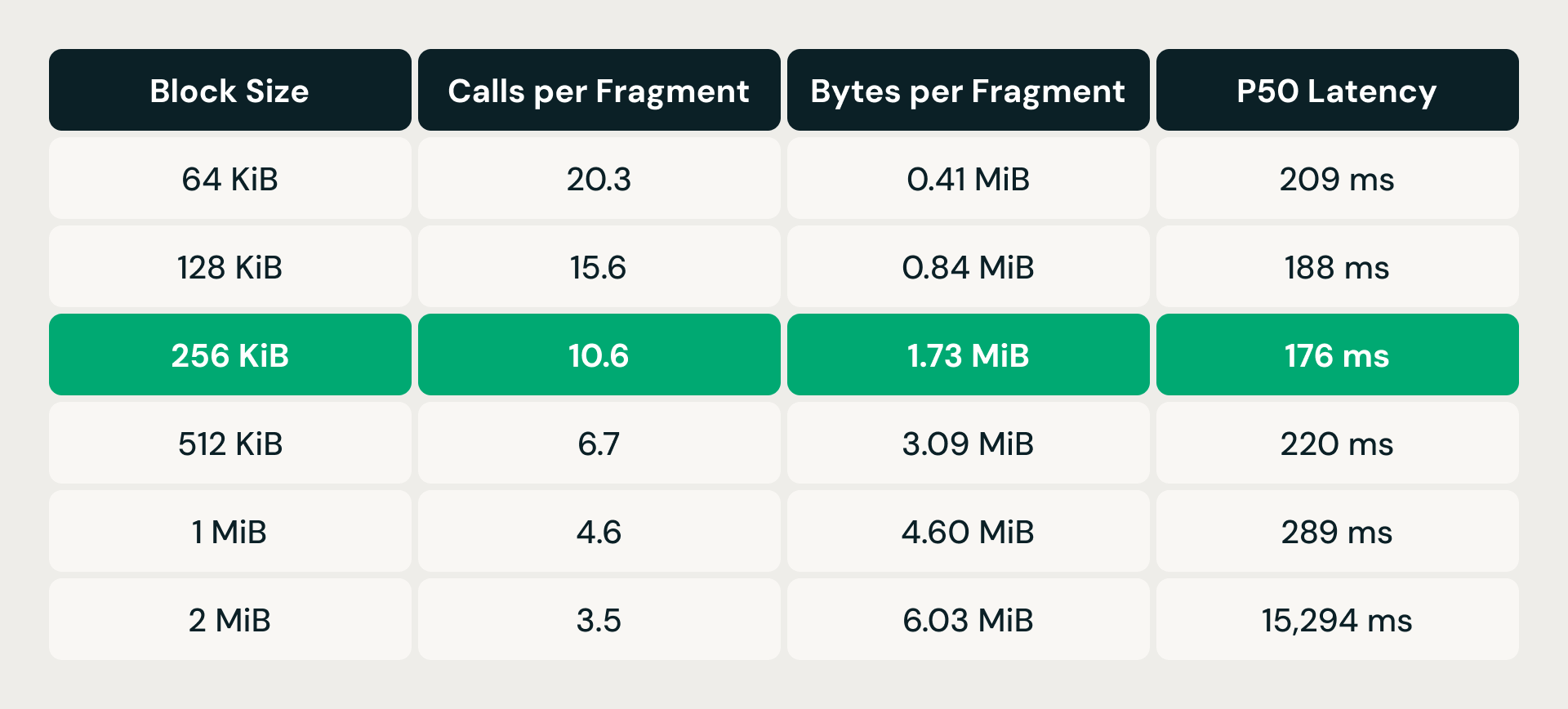
A 64 KiB, cada fragmento de datos requería más de 20 llamadas de almacenamiento, pero recuperaba menos de medio megabyte; la sobrecarga por solicitud era lo que predominaba. Duplicar el tamaño del bloque redujo constantemente el número de llamadas, y la latencia mejoró hasta los 256 KiB. Pero pasado ese punto, la amplificación de lectura tomó el control: a 512 KiB, la latencia volvió a superar la línea de base de 64 KiB a pesar de que hubo muchas menos llamadas. A 2 MiB, se disparó a más de 15 segundos. El punto óptimo de 256 KiB redujo las llamadas aproximadamente a la mitad y, a la vez, mantuvo la amplificación de lectura por debajo de 2 MiB por fragmento, lo que ofreció la latencia p50 más baja de todas las configuraciones probadas.
Uniendo todas las piezas
Todo en esta arquitectura intercambia la latencia de consulta por escalabilidad y costo. Con 768 dimensiones y los 10 mejores resultados, la exhaustividad (recall) —la fracción de vecinos más cercanos reales devueltos— se mantiene por encima del 94 % con 10 millones de vectores, por encima del 91 % con 100 millones y se mantiene en el 90 % incluso con mil millones: el paso de reclasificación, que recupera vectores de precisión completa del almacenamiento de objetos y recalcula las distancias exactas, recupera la precisión que los códigos comprimidos por sí solos perderían a escala. Ese viaje de ida y vuelta de la reclasificación es también lo que domina el tiempo de consulta: las consultas se resuelven en unos 300 milisegundos con 10 millones de vectores y aproximadamente 500 milisegundos con mil millones, en comparación con los 20-50 milisegundos en los endpoints Estándar, que mantienen todo en memoria.
Lo que se obtiene por esos milisegundos adicionales: las compilaciones de índices a una escala de mil millones de vectores se completan en menos de 8 horas, 20 veces más rápido que el Estándar en grandes conjuntos de datos. La cuantificación de productos comprime la huella en memoria en más de un orden de magnitud, la ingesta se ejecuta en clústeres efímeros de Spark que liberan recursos después de cada compilación y desacoplar el almacenamiento del servicio significa que ninguna de las partes está sobreaprovisionada. El resultado es un costo hasta 7 veces menor para los clientes a la misma escala.
Para muchas cargas de trabajo (búsqueda semántica, pipelines de recomendación, generación aumentada por recuperación), esa compensación favorece claramente la escala y el costo. Las etapas posteriores a la recuperación (clasificación, filtrado, generación de LLM) suelen dominar el tiempo de extremo a extremo, lo que hace que la diferencia entre 40 y 400 milisegundos sea invisible para el usuario final. Para el servicio sensible a la latencia, donde cada milisegundo cuenta, la búsqueda vectorial estándar sigue siendo la mejor herramienta. Las dos opciones son complementarias: herramientas diferentes para cargas de trabajo diferentes.
Lo que aprendimos
Construir un sistema de búsqueda de vectores desde cero, en lugar de optimizar el que teníamos, nos forzó a hacer una serie de apuestas que solo rinden frutos en combinación.
La separación entre almacenamiento y cómputo solo funciona si el motor de consultas es lo suficientemente rápido. Mover los datos fuera del nodo ahorra dinero, pero añade E/S a cada consulta, ya sean viajes de ida y vuelta en la red al almacenamiento de objetos o lecturas de una caché de disco local. El motor de Rust de doble tiempo de ejecución existe específicamente para absorber esa latencia: la E/S asíncrona mantiene cientos de lecturas en curso mientras los hilos de la CPU manejan el cálculo de distancia sin bloquear. Sin ese motor, la arquitectura ofrecería almacenamiento barato y consultas lentas; una compensación poco atractiva.
La indexación distribuida solo funciona si el formato del índice la admite. Construir K-means y PQ en Spark nos da escalabilidad horizontal para la ingesta, pero el resultado tiene que ser algo que el motor de consulta pueda servir directamente desde el almacenamiento de objetos sin un paso de reconstrucción. El formato de almacenamiento personalizado —fragmentos de datos inmutables, manifiestos de transacciones separados, semántica ACID en el almacenamiento en la nube— cierra ese ciclo. La ingesta escribe directamente en el formato que lee el motor de consulta.
La compresión es la palanca económica. La Cuantificación de Producto no solo reduce el costo de la memoria. Cambia la viabilidad de la arquitectura. Sin este nivel de compresión, almacenar códigos cuantificados en la memoria para mil millones de vectores aún requeriría terabytes de RAM, y la ventaja de costos sobre la Búsqueda de Vectores Estándar se evaporaría. La PQ hace posible mantener la fase de búsqueda ANN en memoria mientras se traslada todo lo demás al almacenamiento de objetos.
Estas no son optimizaciones independientes. Elimina cualquiera de ellas y el sistema costará demasiado, se compilará con demasiada lentitud o servirá las consultas con demasiada lentitud como para ser práctico.
Conclusión
Los problemas difíciles que se avecinan se derivan directamente de estas compensaciones. Llevar más allá el rendimiento de las consultas (respuestas más rápidas, mayor rendimiento, mejor concurrencia) mediante un almacenamiento en caché más inteligente, almacenamiento por niveles y representaciones en memoria más densas. Actualizaciones casi en tiempo real a escala de miles de millones. Ir más allá de la distancia vectorial bruta como señal de clasificación final hacia una clasificación aprendida y de varias etapas que combina la similitud de vectores, la relevancia de las palabras clave y el contexto del dominio en resultados que no solo son los más cercanos, sino los más útiles.
Creemos que la próxima generación de productos de IA se construirá sobre una infraestructura que aún no se ha inventado, y que los ingenieros que construyan esa infraestructura darán forma a lo que la IA puede hacer. Si quieres ser uno de ellos, ¡ven a construir con nosotros!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.