DSPy en Databricks
Un Framework para Programar RAG y otros Sistemas de IA Compuestos
Los modelos de lenguaje grandes (LLM) han generado interés en la interacción efectiva entre humanos e IA mediante la optimización de técnicas de prompting. La “ingeniería de prompts” es una metodología en crecimiento para adaptar las salidas del modelo, mientras que técnicas avanzadas como la Generación Aumentada por Recuperación (RAG) mejoran las capacidades generativas de los LLM al buscar y responder con información relevante.
DSPy, desarrollado por el Stanford NLP Group, ha surgido como un framework para construir sistemas de IA compuestos mediante “programación, no prompting, de modelos fundacionales”. DSPy ahora admite integraciones con los endpoints de desarrollador de Databricks para Model Serving y AI Search.
Ingeniería de IA Compuesta
Estas técnicas de prompting señalan un cambio hacia “pipelines de prompting” complejos donde los desarrolladores de IA incorporan LLMs, modelos de recuperación (RM) y otros componentes al desarrollar sistemas de IA compuestos.
Programación no Prompting: DSPy
DSPy optimiza el rendimiento de los sistemas impulsados por IA componiendo llamadas a LLM junto con otras herramientas computacionales hacia métricas de tareas posteriores. A diferencia de la “ingeniería de prompts” tradicional, DSPy automatiza la sintonización de prompts traduciendo firmas de lenguaje natural definidas por el usuario en instrucciones completas y ejemplos de pocos disparos (few-shot). Reflejando la optimización de pipelines de extremo a extremo como en PyTorch, DSPy permite a los usuarios definir y componer sistemas de IA capa por capa mientras optimizan para el objetivo deseado.
Los programas en DSPy tienen dos métodos principales:
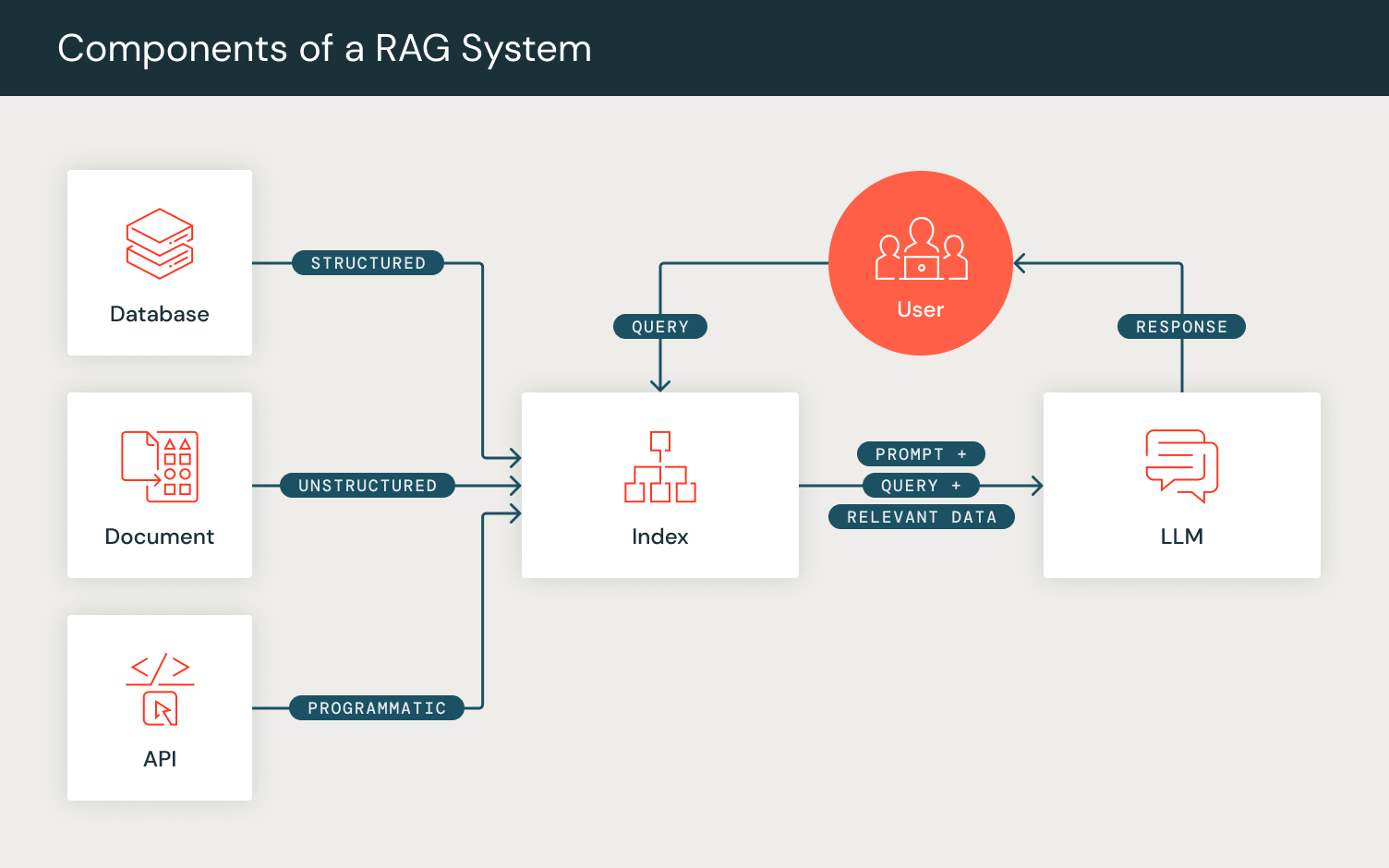
- Inicialización: Los usuarios pueden definir los componentes de sus pipelines de prompting como capas DSPy. Por ejemplo, para tener en cuenta los pasos involucrados en RAG, definimos una capa de recuperación y una capa de generación.
- Definimos una capa de recuperación `dspy.Retrieve` que utiliza el RM configurado por el usuario para recuperar un conjunto de pasajes/documentos relevantes para una consulta de búsqueda introducida.
- Luego inicializamos nuestra capa de generación, para la cual usamos el módulo `dspy.Predict`, que internamente prepara el prompt para la generación. Para configurar esta capa de generación, definimos nuestra tarea RAG en un formato de firma de lenguaje natural, especificado por un conjunto de campos de entrada (“contexto, consulta”) y el campo de salida esperado (“respuesta”). Este módulo luego formatea internamente el prompt para que coincida con este formato definido, y luego devuelve la generación del LM configurado por el usuario.
- Forward: Similar a los pases forward de PyTorch, la función forward del programa DSPy permite la composición por parte del usuario de la lógica del pipeline de prompting. Al usar las capas que inicializamos, configuramos el flujo computacional de RAG recuperando un conjunto de pasajes dada una consulta y luego usando estos pasajes como contexto junto con la consulta para generar una respuesta, devolviendo la salida esperada en un objeto de diccionario DSPy.
Veamos RAG en acción usando el programa DSPy y la generación de DBRX.
Para este ejemplo, usamos una pregunta de muestra del conjunto de datos HotPotQA, que incluye preguntas que requieren múltiples pasos para deducir la respuesta correcta.
Primero, configuremos nuestro LM y RM en DSPy. DSPy ofrece una variedad de integraciones de modelos de lenguaje y recuperación, y los usuarios pueden establecer estos parámetros para garantizar que cualquier programa definido en DSPy se ejecute a través de estas configuraciones.
Ahora, declaremos nuestro programa RAG definido en DSPy y simplemente pasemos la pregunta como entrada.
Durante el paso de recuperación, la consulta se pasa a la capa self.retrieve, que devuelve los 3 pasajes más relevantes, los cuales se formatean internamente de la siguiente manera:
Con estos pasajes recuperados, podemos pasarlos junto con nuestra consulta al módulo dspy.Predict self.generate_answer, coincidiendo con los campos de entrada de la firma del lenguaje natural “contexto, consulta”. Esto aplica internamente un formato y redacción básicos, y le permite dirigir el modelo con la descripción exacta de su tarea sin necesidad de ingeniería de prompts del LM.
Una vez declarado el formato, los campos de entrada “contexto” y “consulta” se rellenan y el prompt final se envía a DBRX:
DBRX genera una respuesta que se completa en el campo Respuesta:, y podemos observar esta generación de indicaciones llamando a:
Esto muestra la última generación de indicaciones del LM con la respuesta generada "Steve Yzerman", ¡que es la respuesta correcta!
DSPy se ha utilizado ampliamente en diversas tareas de modelos de lenguaje como fine-tuning, aprendizaje in-context, extracción de información, autorrefinamiento, y muchos otros. Este enfoque automatizado supera al prompting few-shot estándar con demostraciones escritas por humanos hasta en un 46% para GPT-3.5 y un 65% para Llama2-13b-chat en tareas de lenguaje natural como RAG multi-hop y benchmarks de matemáticas como GSM8K.
DSPy en Databricks
DSPy ahora admite integraciones con los puntos de conexión de desarrollador de Databricks para Servicio de Modelos y Búsqueda Vectorial. Los usuarios pueden configurar las APIs de modelos fundacionales alojados en Databricks a través del SDK de OpenAI mediante dspy.Databricks. Esto garantiza que los usuarios puedan evaluar sus pipelines DSPy de extremo a extremo en modelos alojados en Databricks. Actualmente, esto admite modelos en los Puntos de Conexión de Servicio de Modelos: chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), completion (MPT 7B Instruct) y embedding (BGE Large (En)).
Modelos de Chat
Modelos de Completion
Modelos de Embedding
Modelos Recuperadores/Búsqueda Vectorial
Además, los usuarios pueden configurar modelos recuperadores a través de Databricks AI Search. Tras la creación de un índice y un punto de conexión de Búsqueda Vectorial, los usuarios pueden especificar los parámetros de RM correspondientes a través de dspy.DatabricksRM:
Los usuarios pueden configurar esto globalmente estableciendo el LM y RM en los puntos de conexión de Databricks correspondientes y ejecutando programas DSPy.
¡Con esta integración, los usuarios pueden crear y evaluar aplicaciones DSPy de extremo a extremo, como RAG, utilizando puntos de conexión de Databricks!
Consulta el repositorio oficial de GitHub de DSPy, la documentación y Discord para obtener más información sobre cómo transformar tareas de IA generativa en pipelines DSPy versátiles con Databricks!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.