Ajuste Fino Eficiente con LoRA: Una Guía para la Selección Óptima de Parámetros para Grandes Modelos de Lenguaje
Con el rápido avance de las técnicas basadas en redes neuronales y la investigación de Modelos de Lenguaje Grandes (LLM), las empresas están cada vez más interesadas en las aplicaciones de IA para la generación de valor. Emplean diversos enfoques de aprendizaje automático, tanto generativos como no generativos, para abordar desafíos relacionados con el texto, como la clasificación, el resumen, las tareas de secuencia a secuencia y la generación de texto controlado. Las organizaciones pueden optar por APIs de terceros, pero el ajuste fino de modelos con datos propietarios ofrece resultados específicos del dominio y pertinentes, lo que permite soluciones rentables e independientes desplegables en diferentes entornos de forma segura.
Garantizar la utilización eficiente de los recursos y la rentabilidad es crucial al elegir una estrategia para el ajuste fino. Este blog explora la variante posiblemente más popular y efectiva de dichos métodos eficientes en parámetros, Low Rank Adaptation (LoRA), con un énfasis particular en QLoRA (una variante aún más eficiente de LoRA). El enfoque aquí será tomar un modelo de lenguaje grande abierto y ajustarlo para generar descripciones de productos ficticias cuando se le solicite con un nombre de producto y una categoría. El modelo elegido para este ejercicio es OpenLLaMA-3b-v2, un modelo de lenguaje grande abierto con una licencia permisiva (Apache 2.0), y el conjunto de datos elegido es Red Dot Design Award Product Descriptions, ambos pueden descargarse del HuggingFace Hub en los enlaces proporcionados.
Ajuste Fino, LoRA y QLoRA
En el ámbito de los modelos de lenguaje, el ajuste fino de un modelo de lenguaje existente para realizar una tarea específica con datos específicos es una práctica común. Esto implica añadir una capa de salida específica para la tarea, si es necesario, y actualizar los pesos de la red neuronal mediante retropropagación durante el proceso de entrenamiento. Es importante señalar la distinción entre este proceso de ajuste fino y el entrenamiento desde cero. En el último escenario, los pesos del modelo se inicializan aleatoriamente, mientras que en el ajuste fino, los pesos ya están optimizados hasta cierto punto durante la fase de preentrenamiento. La decisión de qué pesos optimizar o actualizar, y cuáles mantener congelados, depende de la técnica elegida.
El ajuste fino completo implica optimizar o entrenar todas las capas de la red neuronal. Aunque este enfoque suele producir los mejores resultados, también es el que consume más recursos y tiempo.
Afortunadamente, existen enfoques eficientes en parámetros para el ajuste fino que han demostrado ser efectivos. Aunque la mayoría de estos enfoques han ofrecido un rendimiento menor, Low Rank Adaptation (LoRA) ha roto esta tendencia, superando incluso el ajuste fino completo en algunos casos, como consecuencia de evitar el olvido catastrófico (un fenómeno que ocurre cuando el conocimiento del modelo preentrenado se pierde durante el proceso de ajuste fino).
LoRA es un método de ajuste fino mejorado donde, en lugar de ajustar todos los pesos que constituyen la matriz de pesos del modelo de lenguaje grande preentrenado, se ajustan dos matrices más pequeñas que aproximan esta matriz más grande. Estas matrices constituyen el adaptador LoRA. Este adaptador ajustado se carga luego en el modelo preentrenado y se utiliza para la inferencia.
QLoRA es una versión aún más eficiente en memoria de LoRA, donde el modelo preentrenado se carga en la memoria de la GPU como pesos cuantificados de 4 bits (en comparación con 8 bits en el caso de LoRA), manteniendo una efectividad similar a LoRA. Investigar este método, comparar los dos métodos cuando sea necesario y determinar la mejor combinación de hiperparámetros de QLoRA para lograr un rendimiento óptimo con el tiempo de entrenamiento más rápido será el enfoque aquí.
LoRA está implementado en la biblioteca Hugging Face Parameter Efficient Fine-Tuning (PEFT), ofreciendo facilidad de uso, y QLoRA puede aprovecharse utilizando bitsandbytes y PEFT juntos. La biblioteca HuggingFace Transformer Reinforcement Learning (TRL) ofrece un entrenador conveniente para el ajuste fino supervisado con una integración perfecta para LoRA. Estas tres bibliotecas proporcionarán las herramientas necesarias para ajustar el modelo preentrenado elegido y generar descripciones de productos coherentes y convincentes una vez que se le solicite con una instrucción que indique los atributos deseados.
Preparación de los datos para el ajuste fino supervisado
Para investigar la efectividad de QLoRA para el ajuste fino de un modelo para seguir instrucciones, es esencial transformar los datos a un formato adecuado para el ajuste fino supervisado. El ajuste fino supervisado, en esencia, entrena aún más un modelo preentrenado para generar texto condicionado a una instrucción proporcionada. Es supervisado en el sentido de que el modelo se ajusta en un conjunto de datos que tiene pares de instrucción-respuesta formateados de manera consistente.
Una observación de ejemplo de nuestro conjunto de datos elegido del Hugging Face hub es la siguiente:
|
producto |
categoría |
descripción |
texto |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
"“High recognition value, uniform aesthetics and practical scalability – this has been impressively achieved with the Biamp brand language …" |
"Product Name: Biamp Rack Products; Product Category: Digital Audio Processors; Product Description: “High recognition value, uniform aesthetics and practical scalability – this has been impressively achieved with the Biamp brand language …
|
Por muy útil que sea este conjunto de datos, no está bien formateado para el ajuste fino de un modelo de lenguaje para seguir instrucciones de la manera descrita anteriormente.
El siguiente fragmento de código carga el conjunto de datos del Hugging Face hub en la memoria, transforma los campos necesarios en una cadena con formato consistente que representa la instrucción, e inserta la respuesta (es decir, la descripción) inmediatamente después. Este formato se conoce como el 'formato Alpaca' en los círculos de investigación de modelos de lenguaje grandes, ya que fue el formato utilizado para ajustar el modelo LlaMA original de Meta para dar como resultado el modelo Alpaca, uno de los primeros modelos de lenguaje grandes de seguimiento de instrucciones ampliamente distribuidos (aunque no tiene licencia para uso comercial).
Las instrucciones resultantes se cargan luego en un conjunto de datos de Hugging Face para el ajuste fino supervisado. Cada una de estas instrucciones tiene el siguiente formato.
Para facilitar la experimentación rápida, cada ejercicio de ajuste fino se realizará en un subconjunto de 5000 observaciones de estos datos.
Evaluación del rendimiento del modelo antes del ajuste fino
Antes de cualquier ajuste fino, es una buena idea verificar cómo se desempeña el modelo sin ningún ajuste fino para obtener una línea de base del rendimiento del modelo preentrenado.
El modelo se puede cargar en 8 bits de la siguiente manera y se le puede dar una instrucción con el formato especificado en la tarjeta del modelo en Hugging Face.
La salida obtenida no es exactamente lo que queremos.
La primera parte del resultado es realmente satisfactoria, pero el resto es más bien un divagación sin sentido.
De manera similar, si se le da una instrucción al modelo con el texto de entrada en el 'formato Alpaca' como se discutió anteriormente, se espera que la salida sea igual de subóptima:
Y, efectivamente, lo es:
El modelo realiza lo que fue entrenado para hacer, predice el siguiente token más probable. El objetivo del ajuste fino supervisado en este contexto es generar el texto deseado de manera controlable. Tenga en cuenta que en los experimentos posteriores, si bien QLoRA aprovecha un modelo cargado en 4 bits con los pesos congelados, el proceso de inferencia para examinar la calidad de la salida se realiza una vez que el modelo se ha cargado en 8 bits como se mostró anteriormente para mayor consistencia.
Los Parámetros Ajustables
Al usar PEFT para entrenar un modelo con LoRA o QLoRA (tenga en cuenta que, como se mencionó anteriormente, la principal diferencia entre ambos es que en este último, los modelos preentrenados se congelan en 4 bits durante el proceso de ajuste fino), los hiperparámetros del proceso de adaptación de bajo rango se pueden definir en una configuración LoRA como se muestra a continuación:
Se ha demostrado empíricamente que dos de estos hiperparámetros, r y target_modules, afectan significativamente la calidad de la adaptación y serán el foco de las pruebas que siguen. Los otros hiperparámetros se mantienen constantes en los valores indicados anteriormente para simplificar.
r representa el rango de las matrices de bajo rango aprendidas durante el proceso de ajuste fino. A medida que se aumenta este valor, el número de parámetros que deben actualizarse durante la adaptación de bajo rango aumenta. Intuitivamente, un valor de r más bajo puede conducir a un proceso de entrenamiento más rápido y menos intensivo computacionalmente, pero puede afectar la calidad del modelo producido. Sin embargo, aumentar r más allá de un cierto valor puede no producir ningún aumento discernible en la calidad de la salida del modelo. Pronto se pondrá a prueba cómo el valor de r afecta la calidad de la adaptación (ajuste fino).
Al realizar el ajuste fino con LoRA, es posible apuntar a módulos específicos en la arquitectura del modelo. El proceso de adaptación apuntará a estos módulos y les aplicará las matrices de actualización. Similar a la situación con "r", apuntar a más módulos durante la adaptación de LoRA resulta en un mayor tiempo de entrenamiento y una mayor demanda de recursos computacionales. Por lo tanto, es una práctica común apuntar solo a los bloques de atención del transformador. Sin embargo, trabajos recientes, como se muestra en el artículo de QLoRA de Dettmers et al., sugieren que apuntar a todas las capas lineales resulta en una mejor calidad de adaptación. Esto también se explorará aquí.
Los nombres de las capas lineales del modelo se pueden añadir convenientemente a una lista con el siguiente fragmento de código:
Ajustando el ajuste fino con LoRA
La experiencia del desarrollador en el ajuste fino de modelos de lenguaje grandes en general ha mejorado drásticamente durante el último año aproximadamente. La última abstracción de alto nivel de Hugging Face es la clase SFTTrainer en la biblioteca TRL. Para realizar QLoRA, todo lo que se necesita es lo siguiente:
1. Cargar el modelo en la memoria de la GPU en 4 bits (bitsandbytes habilita este proceso).
2. Definir la configuración de LoRA como se discutió anteriormente.
3. Definir las divisiones de entrenamiento y prueba de los datos preparados para seguir instrucciones en objetos Dataset de Hugging Face.
4. Definir los argumentos de entrenamiento. Estos incluyen el número de épocas, el tamaño del lote y otros hiperparámetros de entrenamiento que se mantendrán constantes durante este ejercicio.
5. Pasar estos argumentos a una instancia de SFTTrainer.
Estos pasos se indican claramente en el archivo fuente en el repositorio asociado a este blog.
La lógica de entrenamiento real se abstrae de manera elegante de la siguiente manera:
Si el registro automático de MLflow está habilitado en el espacio de trabajo de Databricks, lo cual es muy recomendable, todos los parámetros y métricas de entrenamiento se rastrean y registran automáticamente con el servidor de seguimiento de MLflow. Esta funcionalidad es invaluable para monitorear tareas de entrenamiento de larga duración. Huelga decir que el proceso de ajuste fino se realiza utilizando un clúster de cómputo (en este caso, un solo nodo con una única GPU A100) creado con el último tiempo de ejecución de Databricks Machine con soporte para GPU.
Combinación de Hiperparámetros #1: QLoRA con r=8 y apuntando a “q_proj”, “v_proj”
La primera combinación de hiperparámetros de QLoRA intentada es r=8 y se dirige solo a los bloques de atención, es decir, “q_proj” y “v_proj” para la adaptación.
Los siguientes fragmentos de código muestran el número de parámetros entrenables:
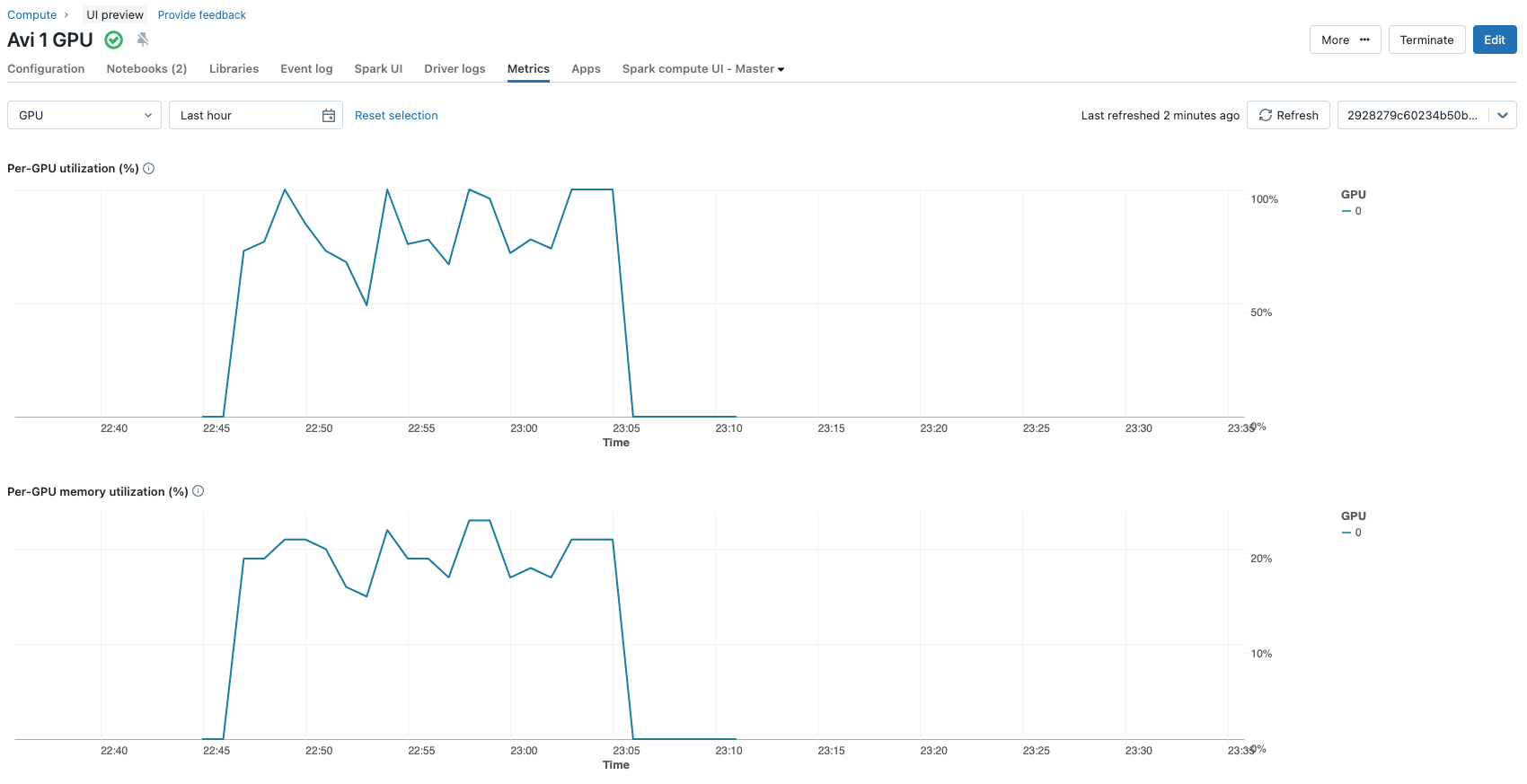
Estas elecciones dan como resultado 2.662.400 parámetros actualizados durante el proceso de ajuste fino (~2,6 millones) de un total de ~3,2 mil millones de parámetros que componen el modelo. Esto es menos del 0,1% de los parámetros del modelo. Todo el proceso de ajuste fino en una sola Nvidia A100 con 80 GBs de GPU durante 3 épocas solo tarda aproximadamente 12 minutos. Las métricas de utilización de la GPU se pueden ver cómodamente en la pestaña de métricas de las configuraciones del clúster.
Al final del proceso de entrenamiento, el modelo ajustado se obtiene cargando los pesos del adaptador en el modelo preentrenado de la siguiente manera:
Este modelo ahora se puede utilizar para inferencia como cualquier otro modelo.
Evaluación Cualitativa
A continuación se enumeran un par de ejemplos de pares de prompt-respuesta
Prompt (pasado al modelo en formato Alpaca, no mostrado aquí por brevedad):
Cree una descripción detallada para el siguiente producto: Corelogic Smooth Mouse, perteneciente a la categoría: Ratón Óptico
Respuesta:
Prompt:
Cree una descripción detallada para el siguiente producto: Hoover Lightspeed, perteneciente a la categoría: Aspiradora Inalámbrica
Respuesta:
El modelo ha sido claramente adaptado para generar descripciones más consistentes. Sin embargo, la respuesta al primer prompt sobre el ratón óptico es bastante corta y la siguiente frase “La aspiradora está equipada con un depósito de polvo que se puede vaciar a través de un depósito de polvo” es lógicamente defectuosa.
Combinación de Hiperparámetros #2: QLoRA con r=16 y apuntando a todas las capas lineales
Seguramente, las cosas pueden mejorar aquí. Vale la pena explorar el aumento del rango de las matrices de bajo rango aprendidas durante la adaptación a 16, es decir, duplicar el valor de r a 16 y mantener todo lo demás igual. Esto duplica el número de parámetros entrenables a 5.324.800 (~5,3 millones).
Evaluación Cualitativa
La calidad de la salida, sin embargo, permanece inalterada para los mismos prompts exactos.
Prompt:
Cree una descripción detallada para el siguiente producto: Corelogic Smooth Mouse, perteneciente a la categoría: Ratón Óptico
Respuesta:
Prompt:
Cree una descripción detallada para el siguiente producto: Hoover Lightspeed, perteneciente a la categoría: Aspiradora Inalámbrica
Respuesta:
Persiste la misma falta de detalle y fallos lógicos donde los detalles están disponibles. Si este modelo ajustado se utiliza para la generación de descripciones de productos en un escenario del mundo real, esta salida no es aceptable.
Combinación de Hiperparámetros #3: QLoRA con r=8 y apuntando a todas las capas lineales
Dado que duplicar r no parece resultar en ningún aumento perceptible en la calidad de la salida, vale la pena cambiar el otro parámetro importante. Es decir, apuntar a todas las capas lineales en lugar de solo a los bloques de atención. Aquí, los hiperparámetros de LoRA son r=8 y las capas objetivo son 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' y 'lm_head'. Esto aumenta el número de parámetros actualizados a 12.994.560 y el tiempo de entrenamiento a aproximadamente 15,5 minutos.
Evaluación Cualitativa
Al solicitar al modelo con los mismos prompts se obtiene lo siguiente:
Prompt:
Cree una descripción detallada para el siguiente producto: Corelogic Smooth Mouse, perteneciente a la categoría: Ratón Óptico
Respuesta:
Prompt:
Cree una descripción detallada para el siguiente producto: Hoover Lightspeed, perteneciente a la categoría: Aspiradora Inalámbrica
Respuesta:
Ahora es posible ver una descripción coherente y algo más larga del ratón óptico ficticio y no hay fallos lógicos en la descripción de la aspiradora. Las descripciones de los productos no solo son lógicas, sino también relevantes. Como recordatorio, estos resultados de calidad relativamente alta se obtienen ajustando menos del 1% de los pesos del modelo con un conjunto de datos total de 5000 pares de prompt-descripción formateados de manera consistente.
Combinación de Hiperparámetros #4: LoRA con r=8 y apuntando a todas las capas lineales del transformador
También vale la pena explorar si la calidad de la salida del modelo mejora si el modelo preentrenado se congela en 8 bits en lugar de 4 bits. En otras palabras, replicar el proceso exacto de ajuste fino utilizando LoRA en lugar de QLoRA. Aquí, los hiperparámetros de LoRA se mantienen igual que antes, en la configuración óptima recién encontrada, es decir, r=8 y apuntando a todas las capas lineales del transformador durante el proceso de adaptación.
Evaluación Cualitativa
Los resultados para los dos prompts utilizados a lo largo del artículo son los siguientes:
Prompt:
Cree una descripción detallada para el siguiente producto: Corelogic Smooth Mouse, perteneciente a la categoría: Ratón Óptico
Respuesta:
Prompt:
Cree una descripción detallada para el siguiente producto: Hoover Lightspeed, perteneciente a la categoría: Aspiradora Inalámbrica
Respuesta:
De nuevo, no hay mucha mejora en la calidad del texto de salida.
Observaciones Clave
Basándose en el conjunto de pruebas anterior y en la evidencia adicional detallada en la excelente publicación que presenta QLoRA, se puede deducir que el valor de r (el rango de las matrices actualizadas durante la adaptación) no mejora la calidad de la adaptación más allá de cierto punto. La mayor mejora se observa al apuntar a todas las capas lineales en el proceso de adaptación, a diferencia de solo los bloques de atención, como se documenta comúnmente en la literatura técnica que detalla LoRA y QLoRA. Las pruebas ejecutadas anteriormente y otras evidencias empíricas sugieren que QLoRA no sufre ninguna reducción discernible en la calidad del texto generado, en comparación con LoRA.
Consideraciones Adicionales para el uso de adaptadores LoRA en la implementación
Es importante optimizar el uso de adaptadores y comprender las limitaciones de la técnica. El tamaño del adaptador LoRA obtenido mediante el ajuste fino (finetuning) suele ser de solo unos pocos megabytes, mientras que el modelo base preentrenado puede ocupar varios gigabytes en memoria y en disco. Durante la inferencia, tanto el adaptador como el LLM preentrenado deben cargarse, por lo que el requisito de memoria sigue siendo similar.
Además, si los pesos del LLM preentrenado y del adaptador no se fusionan, habrá un ligero aumento en la latencia de inferencia. Afortunadamente, con la biblioteca PEFT, el proceso de fusionar los pesos con el adaptador se puede realizar con una sola línea de código, como se muestra aquí:
La siguiente figura describe el proceso desde el ajuste fino de un adaptador hasta el despliegue del modelo.

Si bien el patrón de adaptador ofrece beneficios significativos, la fusión de adaptadores no es una solución universal. Una ventaja del patrón de adaptador es la capacidad de desplegar un único modelo preentrenado grande con adaptadores específicos para cada tarea. Esto permite una inferencia eficiente al utilizar el modelo preentrenado como columna vertebral para diferentes tareas. Sin embargo, la fusión de pesos hace que este enfoque sea imposible. La decisión de fusionar pesos depende del caso de uso específico y de la latencia de inferencia aceptable. No obstante, LoRA/QLoRA sigue siendo un método altamente efectivo para el ajuste fino eficiente en parámetros y es ampliamente utilizado.
Conclusión
La Adaptación de Bajo Rango (Low Rank Adaptation) es una potente técnica de ajuste fino que puede producir excelentes resultados si se utiliza con la configuración adecuada. Elegir el valor correcto del rango y las capas de la arquitectura de la red neuronal a las que apuntar durante la adaptación podría determinar la calidad de la salida del modelo ajustado. QLoRA permite un ahorro adicional de memoria al tiempo que preserva la calidad de la adaptación. Incluso cuando se realiza el ajuste fino, hay varias consideraciones de ingeniería importantes para asegurar que el modelo adaptado se despliegue de la manera correcta.
En resumen, a continuación se muestra una tabla concisa que indica las diferentes combinaciones de parámetros LoRA intentadas, la calidad del texto de salida y el número de parámetros actualizados al ajustar OpenLLaMA-3b-v2 durante 3 épocas en 5000 observaciones en una única A100.
|
r |
módulos_objetivo |
Pesos del modelo base |
Calidad de la salida |
Número de parámetros actualizados (en millones) |
|
8 |
Bloques de atención |
4 |
baja |
2.662 |
|
16 |
Bloques de atención |
4 |
baja |
5.324 |
|
8 |
Todas las capas lineales |
4 |
alta |
12.995 |
|
8 |
Todas las capas lineales |
8 |
alta |
12.995 |
¡Prueba esto en Databricks! Clona el repositorio de GitHub asociado con el blog en un Repositorio de Databricks para empezar. Hay ejemplos más detallados para ajustar modelos en Databricks disponibles aquí.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.