La forma más rápida de federar datos de SAP HANA en tiempo real en Databricks usando Spark JDBC
El reciente anuncio de SAP de una asociación estratégica con Databricks ha generado un gran entusiasmo entre los clientes de SAP. Databricks, los expertos en datos e IA, presenta una oportunidad convincente para aprovechar las capacidades de análisis y ML/IA integrando SAP HANA con Databricks. Dado el inmenso interés en esta colaboración, estamos encantados de embarcarnos en una serie de blogs de análisis profundos.
En muchos escenarios de clientes, un sistema SAP HANA sirve como la entidad principal para la base de datos de varios sistemas de origen, incluidos SAP CRM, SAP ERP/ECC, SAP BW. Ahora, surge la emocionante posibilidad de integrar sin problemas este robusto sistema secundario de análisis de SAP HANA con Databricks, mejorando aún más las capacidades de datos de la organización. Al conectar SAP HANA (con licencia de HANA Enterprise Edition) con Databricks, las empresas pueden aprovechar las capacidades avanzadas de análisis y aprendizaje automático (como MLflow, AutoML, MLOps) de Databricks mientras aprovechan los datos ricos y consolidados almacenados en SAP HANA. Esta integración abre un mundo de posibilidades para que las organizaciones obtengan información valiosa e impulsen la toma de decisiones basada en datos en sus sistemas SAP.
Hay varios enfoques disponibles para federar tablas de SAP HANA, vistas SQL y vistas de cálculo en Databricks. Sin embargo, la forma más rápida es usar SparkJDBC. La ventaja más significativa es que SparkJDBC admite conexiones JDBC paralelas desde los nodos trabajadores de Spark al punto final remoto de HANA.
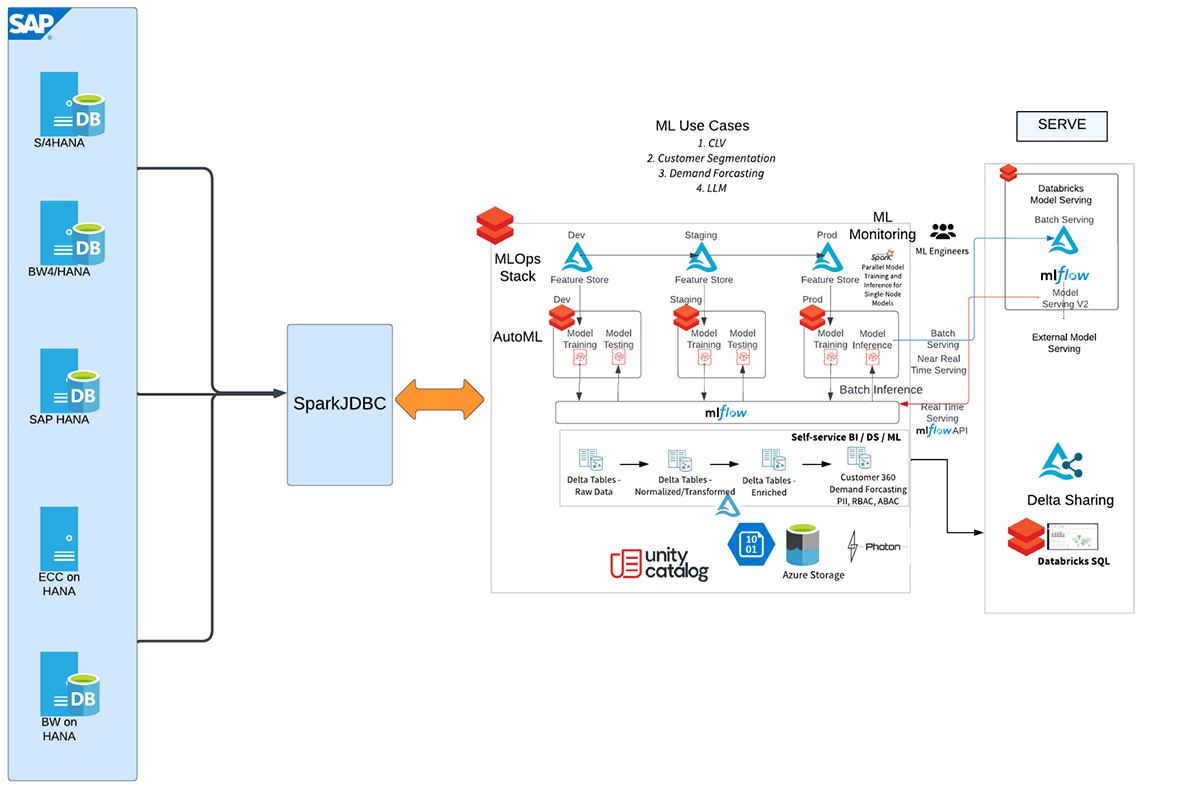
Comencemos con la integración de SAP HANA y Databricks
Primero, SAP HANA 2.0 se instala en la nube de Azure y probamos la integración con Databricks.
Información de SAP HANA instalada en Azure:
| versión | 2.00.061.00.1644229038 |
| rama | fa/hana2sp06 |
| Sistema Operativo | SUSE Linux Enterprise Server 15 SP1 |
Aquí está el flujo de trabajo de alto nivel que representa los diferentes pasos de esta integración.
Consulte el notebook adjunto para obtener instrucciones más detalladas para extraer datos de las vistas de cálculo y tablas de SAP HANA en Databricks usando SparkJDBC.

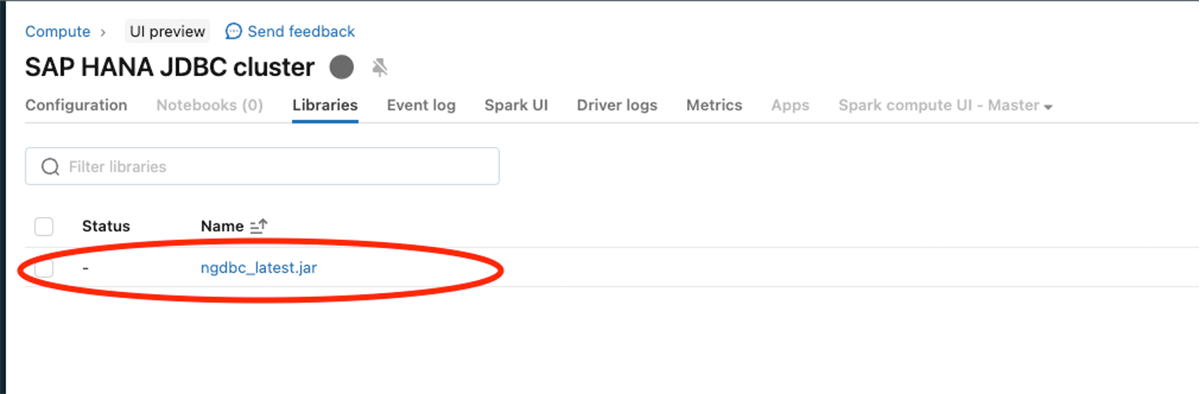
Configure el JAR de SAP HANA JDBC (ngdbc.jar) como se muestra en la imagen a continuación
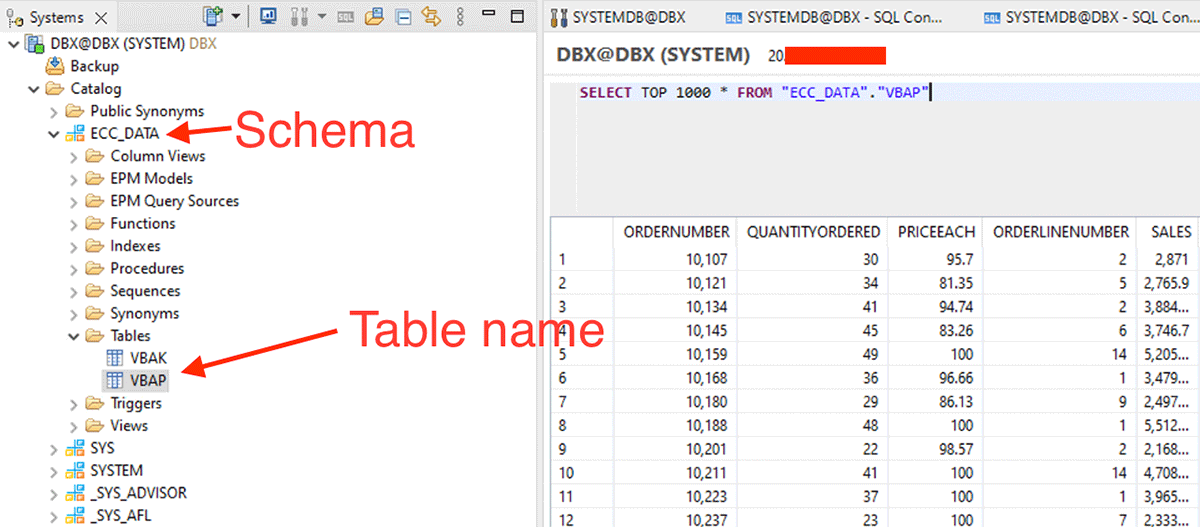
Una vez que se realizan los pasos anteriores, realice una lectura de spark usando el servidor SAP HANA y el puerto JDBC.
Comience a crear los dataframes usando el código que se muestra a continuación con el esquema y el nombre de la tabla.
Además, podemos hacer una reducción de filtros pasando sentencias SQL en la opción dbtable.
Para obtener datos de la Vista de Cálculo, tenemos que hacer lo siguiente:
Por ejemplo, esta vista de cálculo XS-classic se crea en el esquema interno "_SYS_BIC".
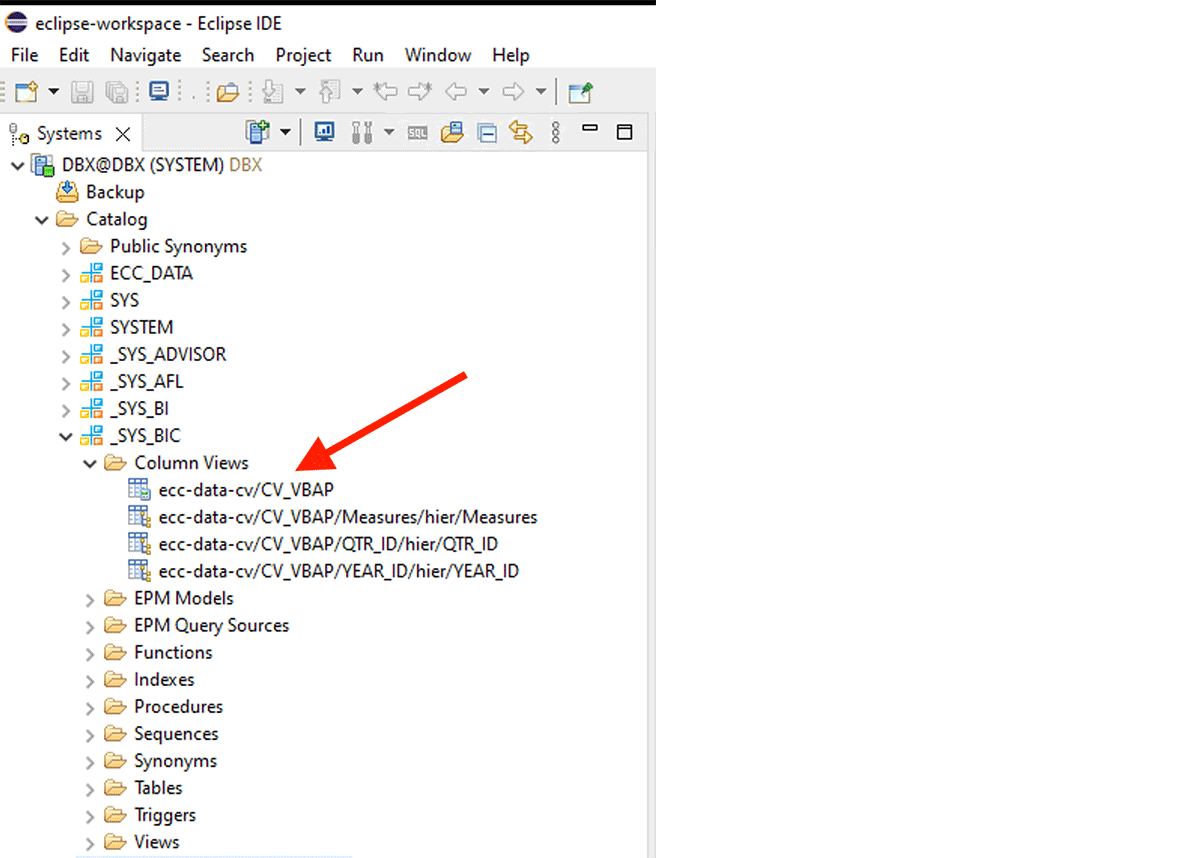
Este fragmento de código crea un dataframe PySpark llamado "df_sap_ecc_hana_cv_vbap" y lo puebla a partir de una Vista de Cálculo del sistema SAP HANA (en este caso, CV_VBAP).
Después de generar el dataframe PySpark, aproveche las infinitas capacidades de Databricks para el análisis exploratorio de datos (EDA) y el aprendizaje automático/inteligencia artificial (ML/AI).
Resumiendo los dataframes anteriores:
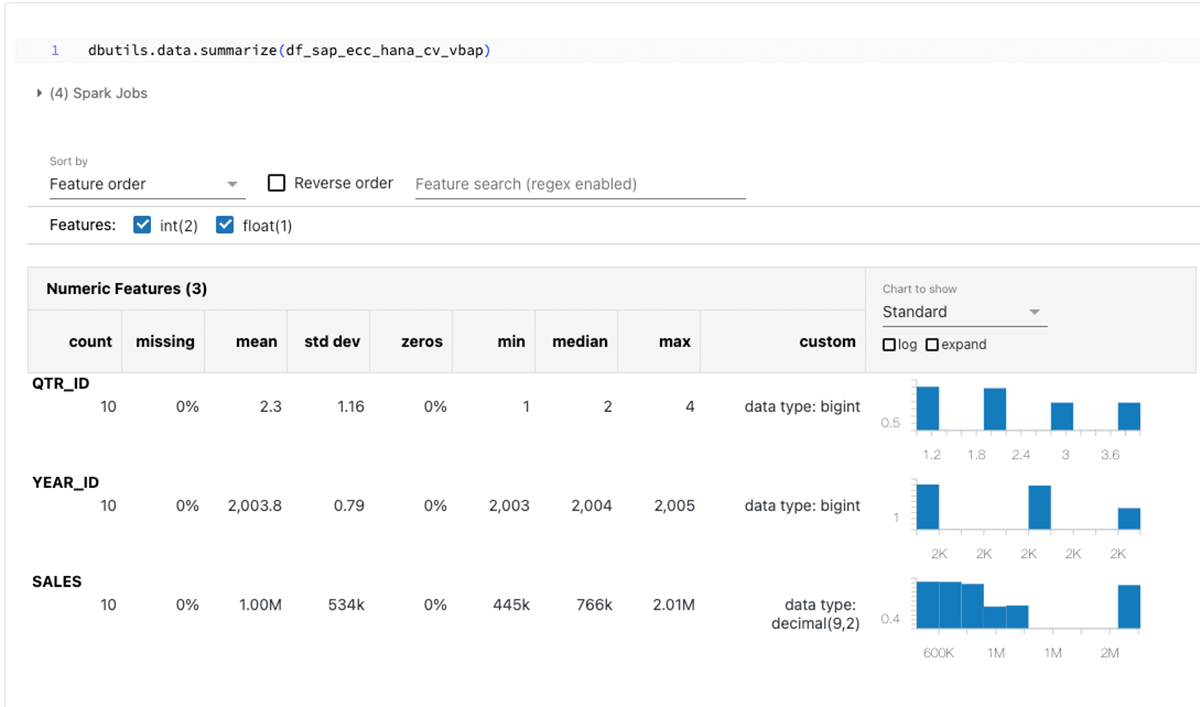
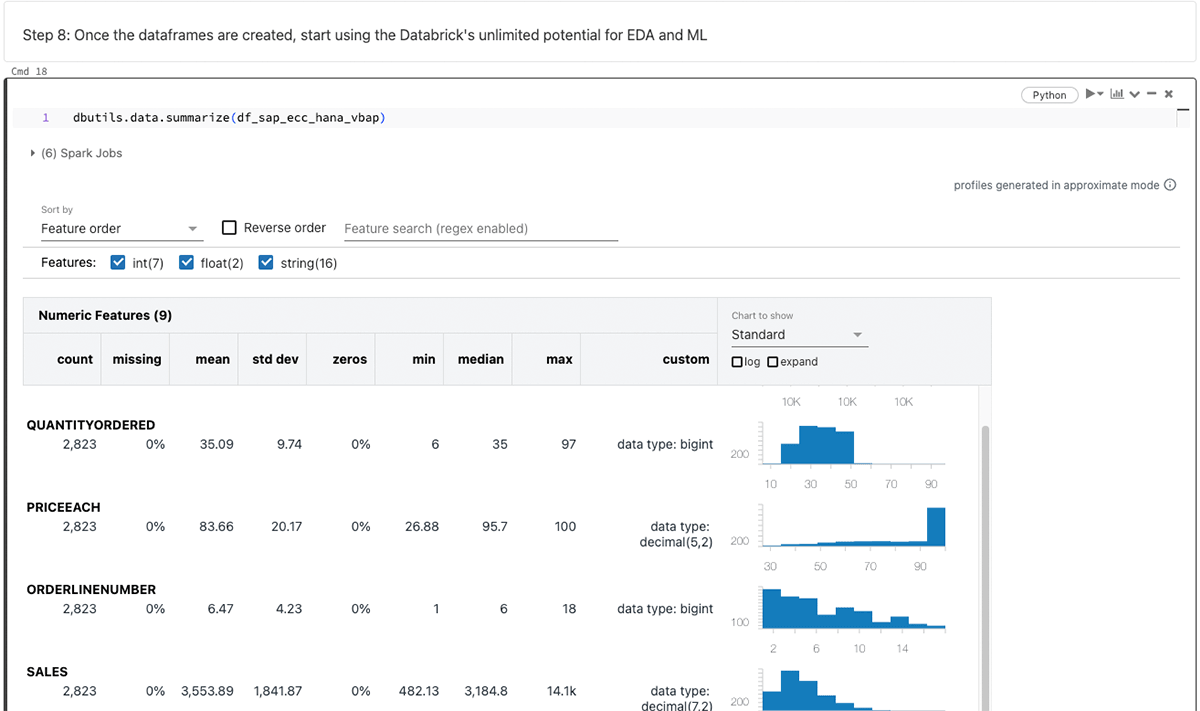
El enfoque de este blog gira en torno a SparkJDBC para SAP HANA, pero vale la pena señalar que existen métodos alternativos como FedML, hdbcli y hana_ml para fines similares.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.