Cómo las tablas de sistema de Databricks ayudan a los ingenieros de datos a lograr una observabilidad avanzada
Las tablas del sistema proporcionan la amplitud y la profundidad que los ingenieros de datos necesitan para monitorear fácilmente el estado de sus canalizaciones de datos a escala para obtener cargas de trabajo más rentables y confiables.
por Theresa Hammer
- Aprenda cómo las Tablas del sistema exponen la telemetría de la plataforma como tablas consultables, incluidos los metadatos y la información de ejecución para los trabajos y pipelines de Lakeflow.
- Use consultas de ejemplo para convertir esta telemetría en información sobre las oportunidades de confiabilidad, costo y eficiencia a escala para los trabajos de Lakeflow.
- Centralice esta información en una vista operativa diaria y compartida para los equipos de ingeniería de datos con la plantilla del panel de Lakeflow.
El problema de las 3 a. m.
Son las 3 de la mañana y algo se rompió. El dashboard está desactualizado, un SLA no se cumplió y todos están tratando de adivinar qué parte de la plataforma se desvió. Quizás una tarea pasó horas ejecutándose sin un tiempo de espera. Quizás un pipeline actualizó una tabla que nadie ha leído en meses. Quizás un clúster todavía está en un runtime antiguo. Quizás la única persona que conoce al propietario de la tarea está de vacaciones.
Estos son los patrones que desgastan a los equipos de datos: cómputo desperdiciado por pipelines sin usar, brechas de confiabilidad por la falta de reglas de estado, problemas de mantenimiento por runtimes obsoletos y demoras causadas por una titularidad poco clara. Aparecen de forma silenciosa, crecen lentamente y, de repente, se convierten en lo que le quita el sueño al ingeniero de guardia.
Databricks System Tables ofrecen una capa consistente para detectar estos problemas a tiempo, ya que exponen los metadatos de los trabajos, los cronogramas de las tareas, el comportamiento de la ejecución, el historial de configuración, el linaje, las señales de costos y la propiedad en un solo lugar.
Con las recién lanzadas Tablas del sistema para trabajos de Lakeflow, ahora tiene acceso a esquemas ampliados que ofrecen detalles de ejecución y señales de metadatos más completos, y permiten una observabilidad más avanzada.
Visibilidad más profunda y centralizada de todos tus datos de manera sencilla con System Tables
¿Qué son las tablas del sistema?
Las tablas del sistema de Databricks son un conjunto de tablas de solo lectura, administradas por Databricks en el catálogo system, que proporcionan datos operativos y de observabilidad para su cuenta. Vienen listas para usar y cubren una amplia gama de datos, incluidos trabajos, canalizaciones, clústeres, facturación, linaje y más.
Categoría | Qué rastrea |
Trabajos de Lakeflow | Configuraciones de trabajos, definiciones de tareas, cronogramas de ejecución |
Canalizaciones declarativas de Lakeflow Spark | Metadatos de canalización, historial de actualizaciones |
Facturación | Uso, atribución de costos por carga de trabajo |
Linaje. | Dependencias de lectura/escritura a nivel de tabla |
Clústeres | Configuraciones de cómputo, utilización |
Por qué las Tablas del sistema son importantes para la observabilidad
Las Tablas del sistema admiten el análisis entre espacios de trabajo dentro de una región, lo que permite a los equipos de ingeniería de datos analizar fácilmente cualquier comportamiento de la carga de trabajo y los patrones operativos a escala desde una única interfaz consultable. Con estas tablas, los profesionales de datos pueden monitorear de forma centralizada el estado de todas sus canalizaciones, detectar oportunidades de ahorro de costos e identificar rápidamente las fallas para una mayor confiabilidad.
Algunas tablas del sistema utilizan la semántica de SCD tipo 2, que conserva el historial de cambios completo mediante la inserción de una fila nueva para cada actualización. Esto permite auditar la configuración y analizar el historial del estado de la plataforma a lo largo del tiempo.
Tablas del sistema Lakeflow
Las tablas de sistema de Lakeflow contienen datos de los últimos 365 días y consisten en las siguientes tablas.
Para obtener una lista completa de las tablas del sistema y sus relaciones, consulte la documentación.
Tablas de observabilidad de trabajos (disponibilidad general)
system.lakeflow.jobs: metadatos SCD2 para trabajos, que incluyen la configuración y las etiquetas. Útil para el inventario, la gobernanza y el análisis de la deriva de la configuración.system.lakeflow.job_tasks– Tabla SCD2 que describe todas las tareas de trabajo, sus definiciones y dependencias. Es útil para comprender las estructuras de las tareas a gran escala.system.lakeflow.job_run_timeline– Cronograma inmutable de ejecuciones de trabajos con estado, cómputo y tiempos. Ideal para el análisis de SLA y de tendencias de rendimiento.system.lakeflow.job_task_run_timeline– Línea de tiempo de las ejecuciones de tareas individuales dentro de cada trabajo. Ayuda a identificar cuellos de botella y problemas a nivel de tarea.
Tablas de observabilidad de canalizaciones (versión preliminar pública)
system.lakeflow.pipelines: tabla de metadatos SCD2 para las canalizaciones de SDP, que permite la visibilidad de las canalizaciones entre áreas de trabajo y el seguimiento de cambios.system.lakeflow.pipeline_update_timeline– Registros de ejecución inmutables para las actualizaciones de canalizaciones, lo que permite la depuración y optimización históricas.
Las Lakeflow System Tables han ganado popularidad rápidamente, con decenas de millones de consultas que se ejecutan cada día, lo que representa un aumento interanual de 17x. Este auge destaca el valor que los ingenieros de datos obtienen de las Lakeflow System Tables, que se han convertido en un componente crucial de la observabilidad diaria para muchos clientes de Databricks Lakeflow.
Veamos ahora los casos de uso que son posibles gracias a las tablas del sistema de trabajos, recientemente ampliadas y ahora disponibles de forma general.
Tablas del sistema en la vida real: estado operativo de los trabajos de Lakeflow
Como ingeniero de datos en un equipo de plataforma central, eres responsable de administrar cientos de trabajos en varios equipos. Tu objetivo es mantener la plataforma de datos rentable, confiable y con buen rendimiento, mientras te aseguras de que los equipos sigan las mejores prácticas operativas y de gobierno.
Para ello, te propones auditar tus trabajos y canalizaciones de Lakeflow en función de cuatro objetivos principales:
- Optimice los costos: identifique los trabajos programados que actualizan conjuntos de datos que nunca se usan en procesos posteriores.
- Garantizar la confiabilidad: Aplicar tiempos de espera y umbrales de tiempo de ejecución para evitar trabajos fuera de control e incumplimientos de los SLA.
- Mantener la higiene: Verificar la coherencia de las versiones de tiempo de ejecución y los estándares de configuración.
- Asigne la responsabilidad: Identifique a los propietarios de los trabajos para agilizar los seguimientos y la corrección.
Patrón 1: Encontrar trabajos que producen datos no utilizados
El problema: Las tareas programadas se ejecutan fielmente, actualizando tablas que ningún consumidor posterior lee. Estos suelen ser los ahorros de costos más fáciles de lograr, si puedes encontrarlos.
El enfoque: Unir las tablas de Lakeflow Jobs con las tablas de linaje y facturación para identificar los productores sin consumidores, clasificados por costo.
Próximos pasos: Revise los principales responsables con sus propietarios. Algunos se pueden pausar de inmediato de forma segura. Otros pueden necesitar un plan de desuso si sistemas externos dependen de ellos fuera de Databricks.
Patrón 2: Encontrar trabajos sin tiempos de espera o umbrales de duración
El problema: Las tareas sin tiempo de espera pueden ejecutarse indefinidamente. Una tarea atascada consume cómputo durante horas, o incluso días, antes de que alguien se dé cuenta. Además de aumentar los costos, esto también puede causar incumplimientos de SLA, por lo que necesita detectar los excesos a tiempo y tomar medidas antes de que los plazos o los procesos posteriores se vean afectados.
El enfoque: Consultar las configuraciones de trabajos actuales en busca de ajustes faltantes de tiempo de espera y umbral de duración.
Qué hacer a continuación: Compare con los tiempos de ejecución históricos de job_run_timeline para establecer umbrales realistas. Un trabajo que normalmente se ejecuta en 20 minutos podría justificar un tiempo de espera de 1 hora y un umbral de duración de 30 minutos. Un trabajo que varía mucho puede necesitar una investigación previa.
Patrón 3: Detectar versiones de runtime obsoletas
El problema: Los runtimes obsoletos carecen de parches de seguridad, mejoras de rendimiento y están sujetos a los próximos plazos de EOL. Pero con cientos de tareas, hacer un seguimiento de quién sigue usando versiones antiguas es tedioso.
El enfoque: consulte las configuraciones de las tareas del trabajo para las versiones de tiempo de ejecución y marque cualquier cosa por debajo de su umbral.
Próximos pasos: Prioriza las actualizaciones según los cronogramas de fin de vida útil (EOL). Comparte esta lista con los propietarios de los trabajos y haz un seguimiento del progreso en consultas de seguimiento.
Patrón 4: Identificar a los propietarios del job para la remediación
El problema: Cuando un trabajo falla o no está configurado correctamente, necesitas saber a quién contactar para solucionar el problema.
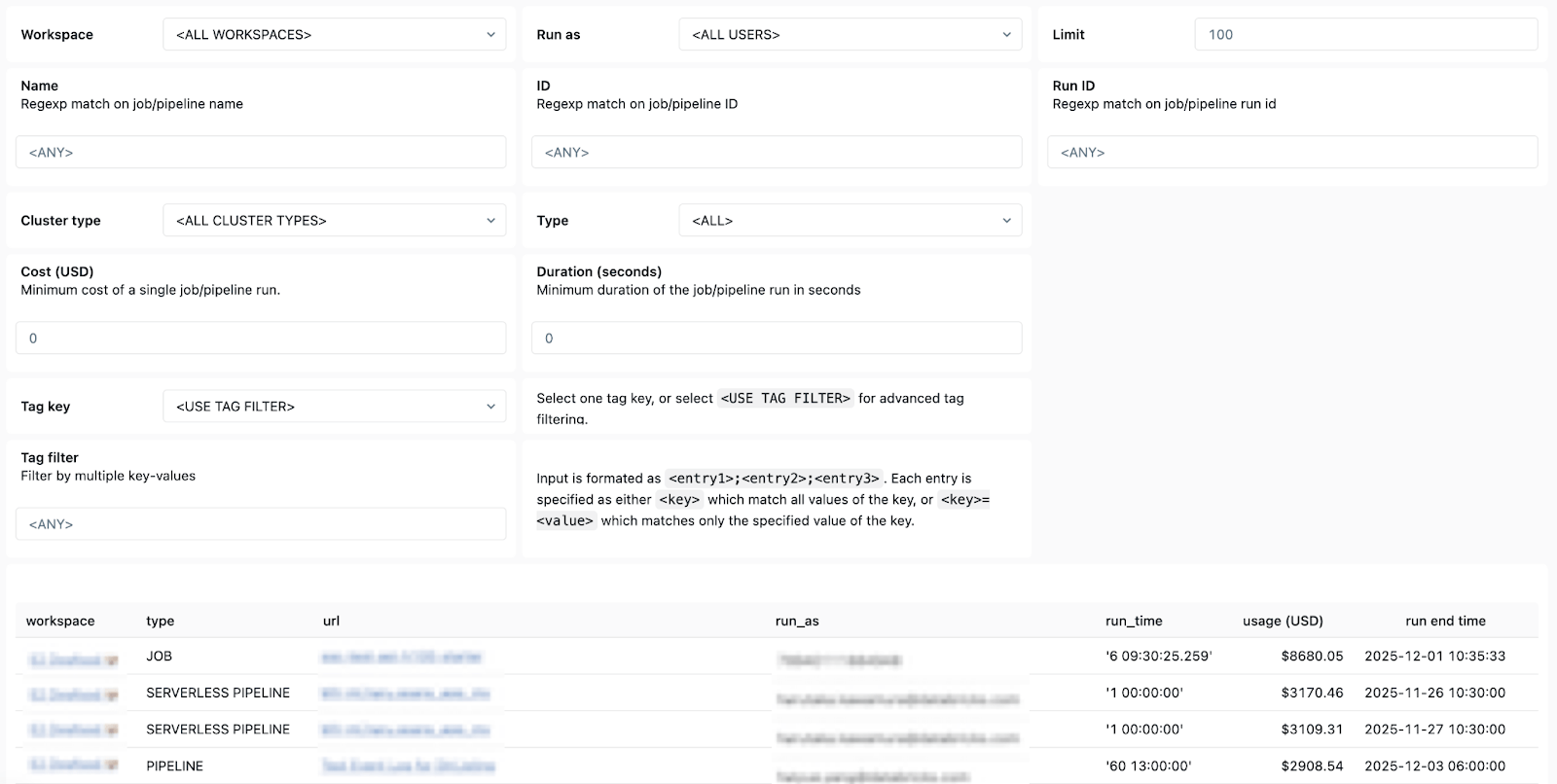
El enfoque: consulte las tablas del sistema para identificar fácilmente a los propietarios de los trabajos para cada acción que se deba tomar.
Qué hacer a continuación: Ponte en contacto con los propietarios del trabajo para asignar la propiedad de los problemas que requieren que se tome una medida.
Juntos, estos patrones lo ayudan a optimizar los costos, mantener los datos actualizados, aplicar mecanismos de protección de la confiabilidad y asignar una titularidad clara para la corrección. Forman la base para la observabilidad operativa.
Uniendo todo: operacionalización de la información con paneles
Ejecutar estas consultas ad hoc es útil. Pero para las operaciones diarias, es deseable tener una vista compartida que todo el equipo pueda consultar.
El panel de Lakeflow me da una vista panorámica de los trabajos en todos mis espacios de trabajo, no solo a nivel de costos, sino también para la higiene y las operaciones de las canalizaciones: seguimiento del gasto, identificación de canalizaciones obsoletas, monitoreo de fallas y detección de oportunidades de optimización. - Zoe Van Noppen, arquitecta de soluciones de datos, Cubigo
Para comenzar, importe el panel a su espacio de trabajo. Para obtener instrucciones paso a paso, consulte la documentación oficial.
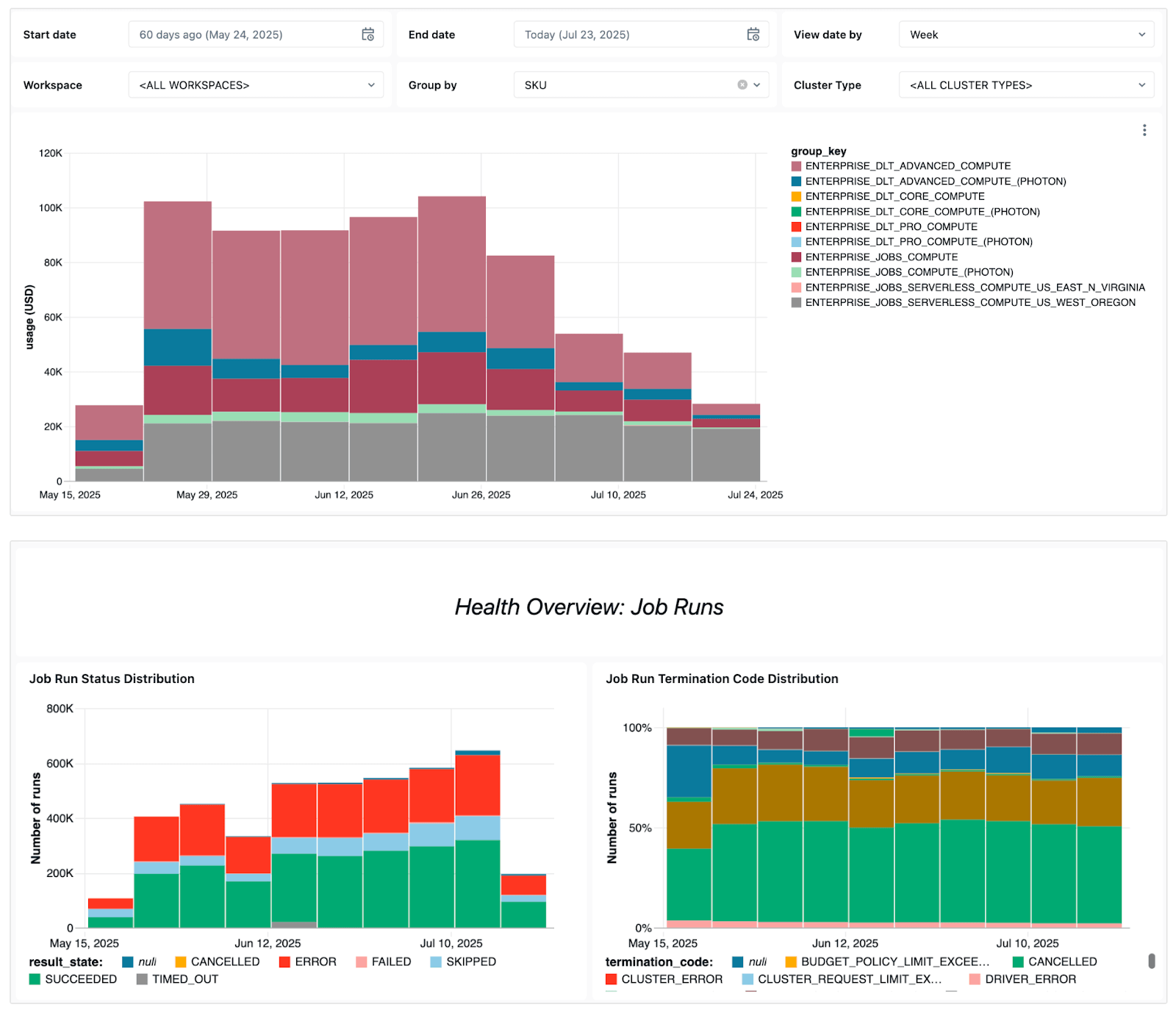
El dashboard muestra varias señales operativas clave, que incluyen:
- Tendencias de fallas - para que pueda ver qué trabajos fallan con más frecuencia, las tendencias generales de errores y los mensajes de error comunes.
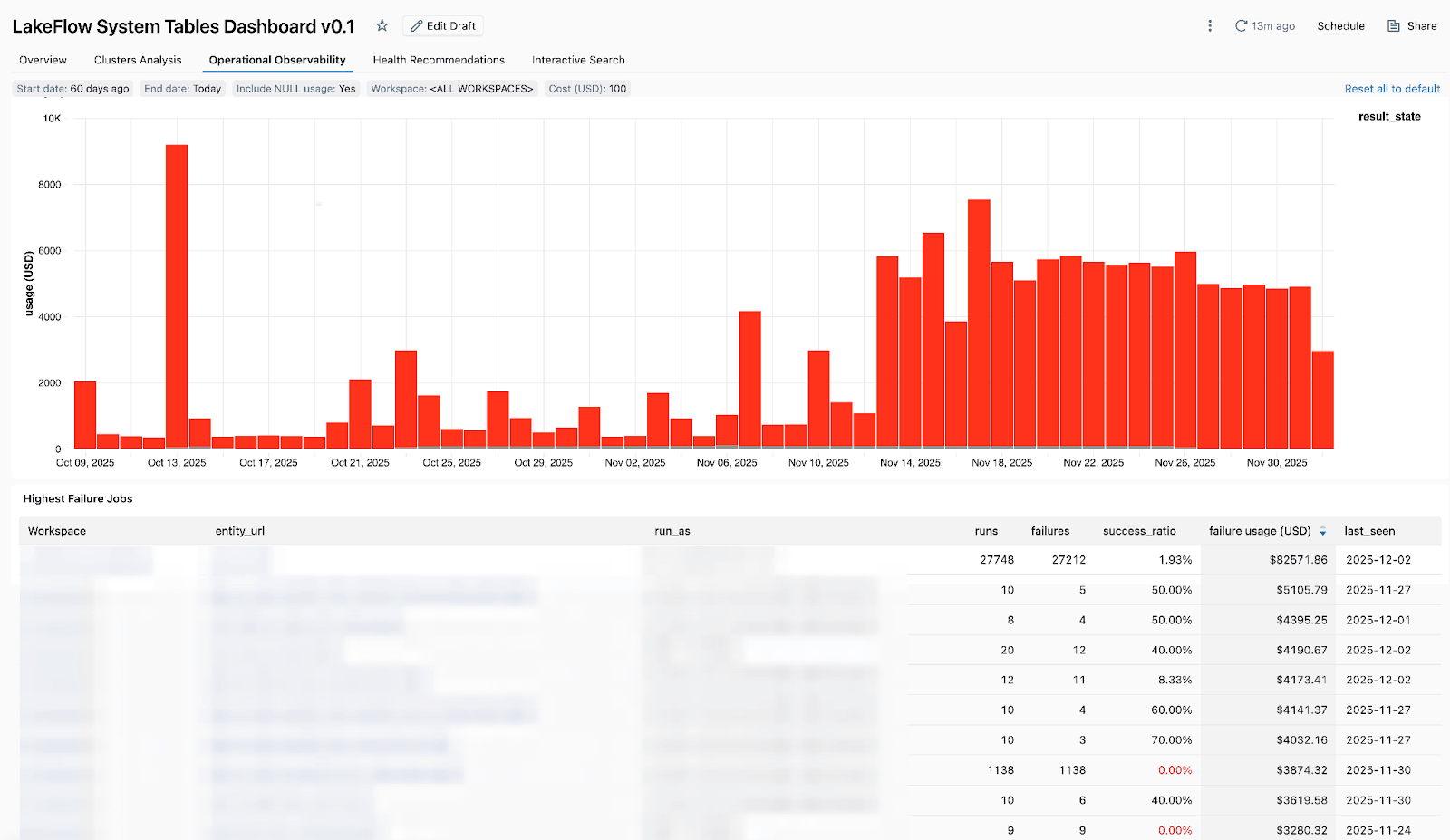
- Trabajos de alto costo: para que pueda identificar los trabajos más costosos y las ejecuciones de trabajos individuales de los últimos 30 días o a lo largo del tiempo. La siguiente tabla se ordena por los trabajos de mayor costo durante el período seleccionado y muestra sus tendencias de costos a lo largo del tiempo.
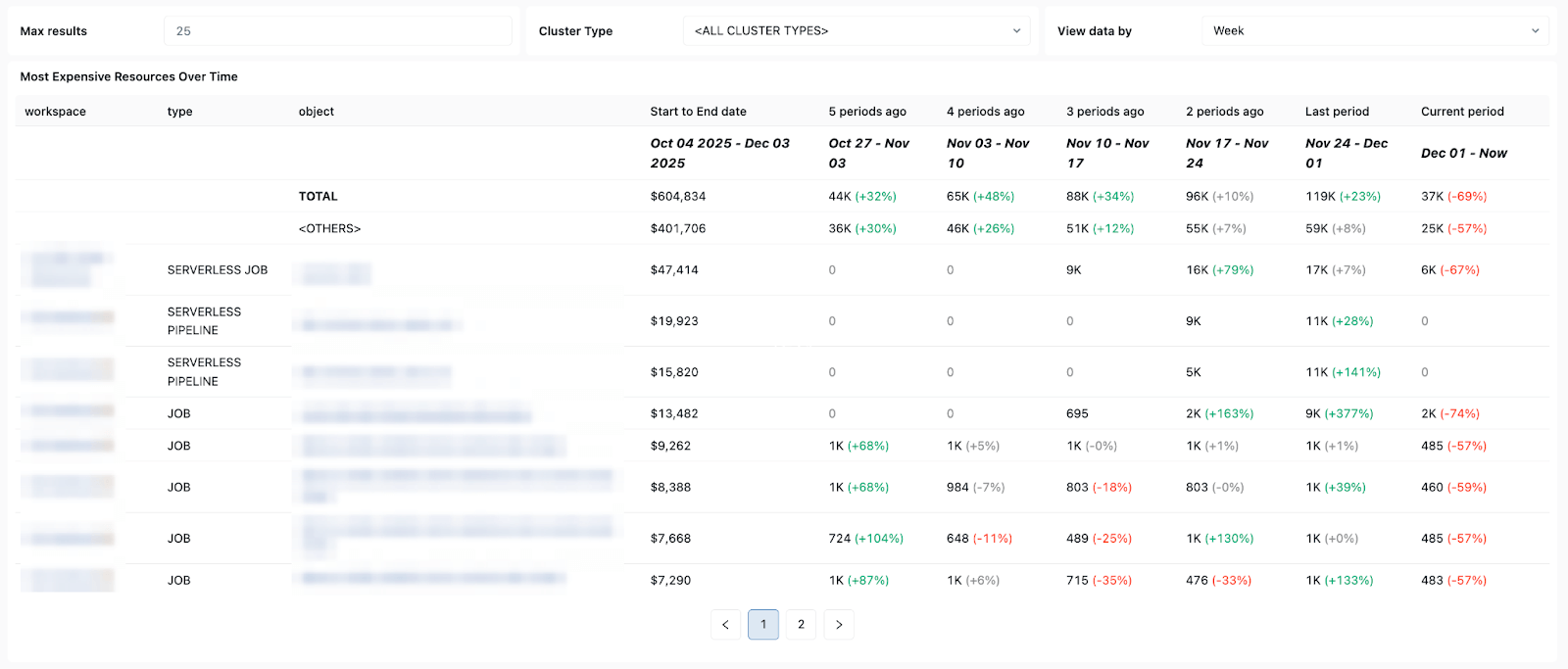
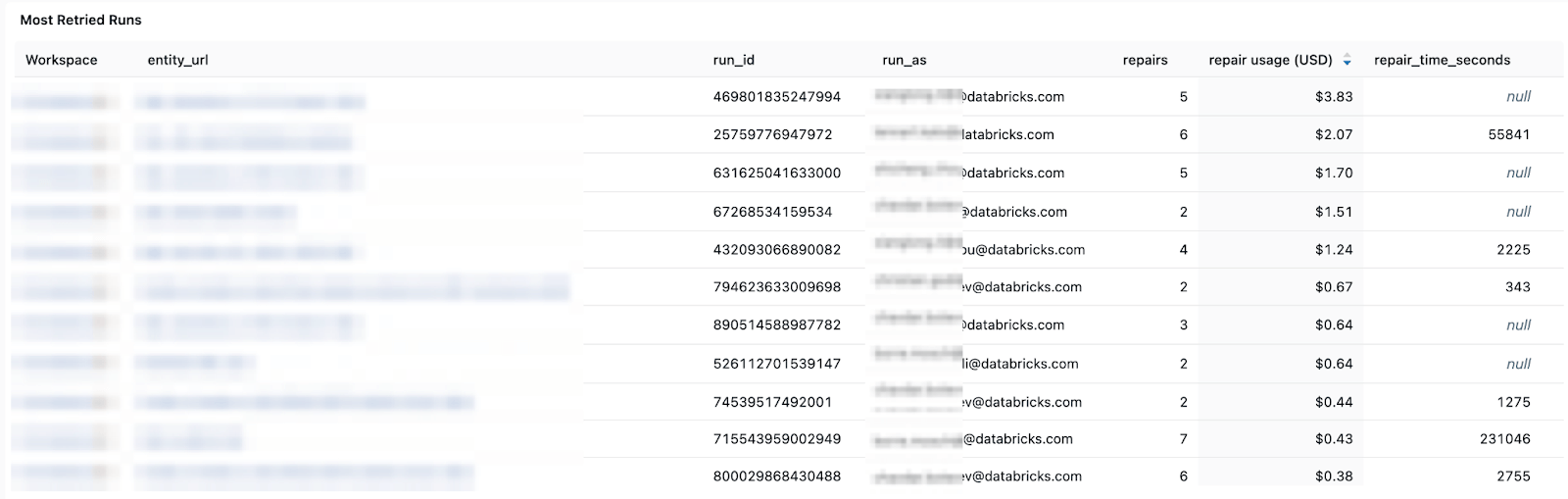
Patrones de costos y reintentos: lo que te ayuda a realizar un seguimiento de las tendencias de costos y el impacto de los reintentos o las ejecuciones de reparación en el gasto total.
- Información sobre la configuración - te permite comprobar la eficiencia del clúster, las reglas de estado, los tiempos de espera y las versiones de tiempo de ejecución para la higiene operativa.
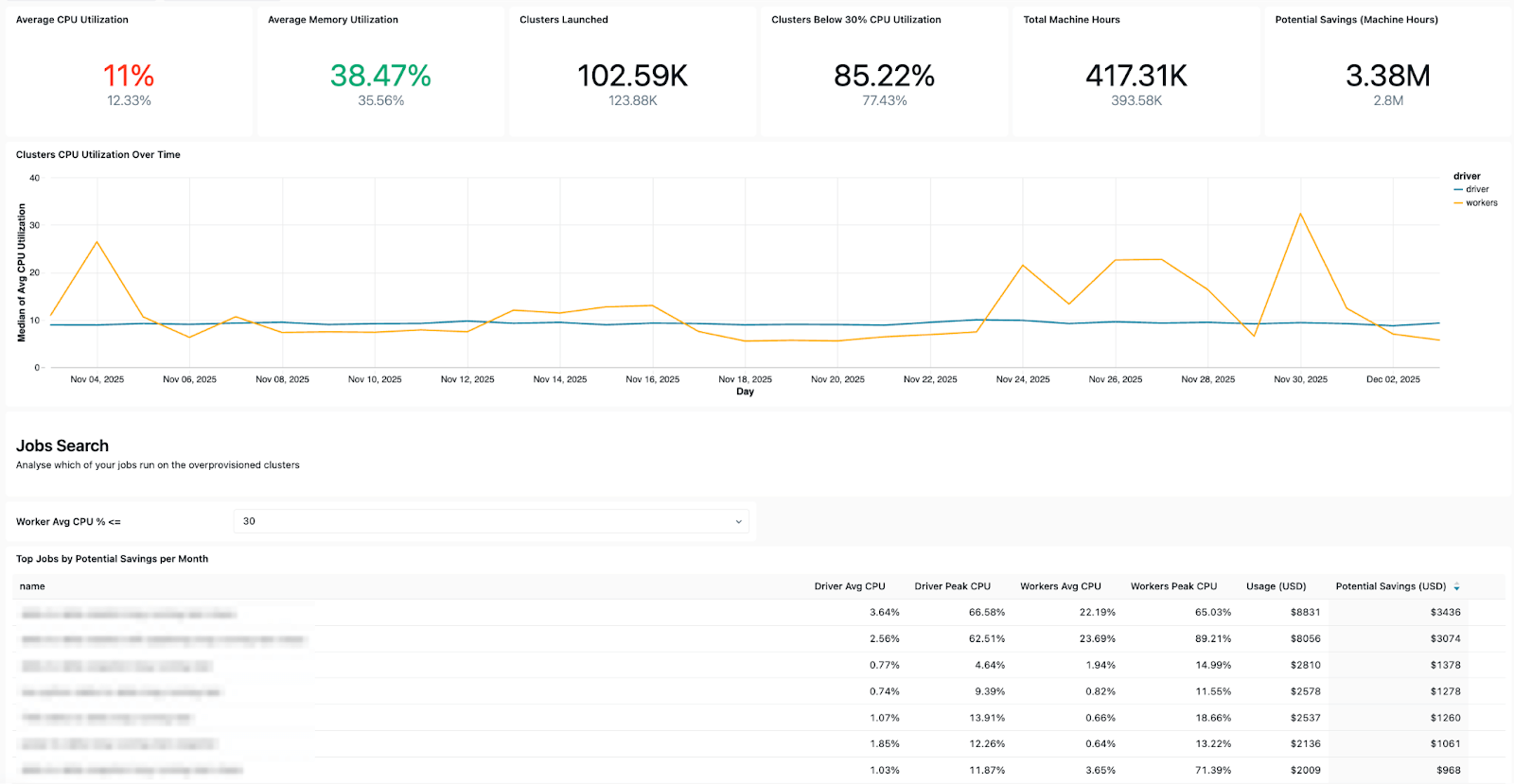
- Detalles de propiedad: para que puedas encontrar fácilmente a los usuarios de “ejecutar como” y a los creadores de trabajos para saber a quién contactar.
En resumen, las System Tables de Databricks facilitan el monitoreo, la auditoría y la solución de problemas de las tareas de Lakeflow de manera eficiente, a escala y entre workspaces. Con visualizaciones claras, simples y accesibles de sus tareas y pipelines disponibles en la plantilla de Dashboard, cada ingeniero de datos que use Lakeflow puede lograr una observabilidad avanzada y garantizar de manera consistente pipelines listos para producción, rentables y confiables.
Las System Tables convierten la telemetría de su plataforma en un activo consultable. En lugar de unir señales de cinco herramientas diferentes, usted escribe SQL en un esquema unificado y obtiene respuestas en segundos.
Tu yo de las 3 de la mañana te lo agradecerá.
Para obtener más información sobre las Tablas del sistema, consulta los siguientes recursos:
¿Es nuevo en Databricks? ¡Pruebe Databricks gratis hoy mismo!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.