Cómo Superhuman y Databricks crearon juntos una plataforma de inferencia de 200K QPS
Superhuman e ingenieros de Databricks comparten cómo migraron conjuntamente cargas de trabajo de corrección ortográfica y gramatical a la Plataforma de Servicio de Modelos de Databricks, sirviendo más de 200k QPS, con ganancias de rendimiento del 60%...
por Christoph Stüber, Wai Wu, Arjun DCunha, Amine El Helou, Tian Ouyang y Alex Coleman
- Superhuman migró de una pila vLLM DIY a Databricks FMAPI Provisioned Throughput, sirviendo ahora un LLM personalizado a más de 200K QPS con latencia P99 inferior a un segundo. Esto permitió al equipo de ingeniería de Superhuman centrarse en construir y mejorar su producto, mientras delegaba a la Plataforma Databricks para manejar la escala y la infraestructura.
- Las optimizaciones conjuntas de ingeniería ofrecieron una ganancia de rendimiento del 60% por GPU (750 → 1200 QPS por pod H100) y redujeron los costos de servicio a través de la cuantificación FP8, eliminando la sobrecarga del lado de la CPU y optimizando los núcleos de atención en la arquitectura Hopper, todo ello logrado sin regresiones de calidad.
- Databricks FMAPI escala de manera confiable a más de 250 GPUs a través de balanceo de carga de grado de producción, escalado automático y rápido inicio de contenedores; con pruebas de estrés de preproducción que garantizan que los objetivos de disponibilidad y latencia p99 se cumplan antes de que el tráfico llegue a producción.
De socios de análisis a socios de inferencia en tiempo real
Superhuman, la plataforma de productividad que incluye Superhuman, Coda, Superhuman Mail y Superhuman Go, atiende a más de 40 millones de usuarios diarios en docenas de idiomas. La asistencia de comunicación con IA de Superhuman proporciona sugerencias en tiempo real sobre corrección, claridad, tono y estilo en todas las superficies donde las personas escriben.
Databricks y Superhuman han sido socios durante años. El equipo de Superhuman ha utilizado históricamente la Plataforma de Inteligencia de Datos de Databricks como base para el análisis. Pero el análisis era solo la mitad de la historia.
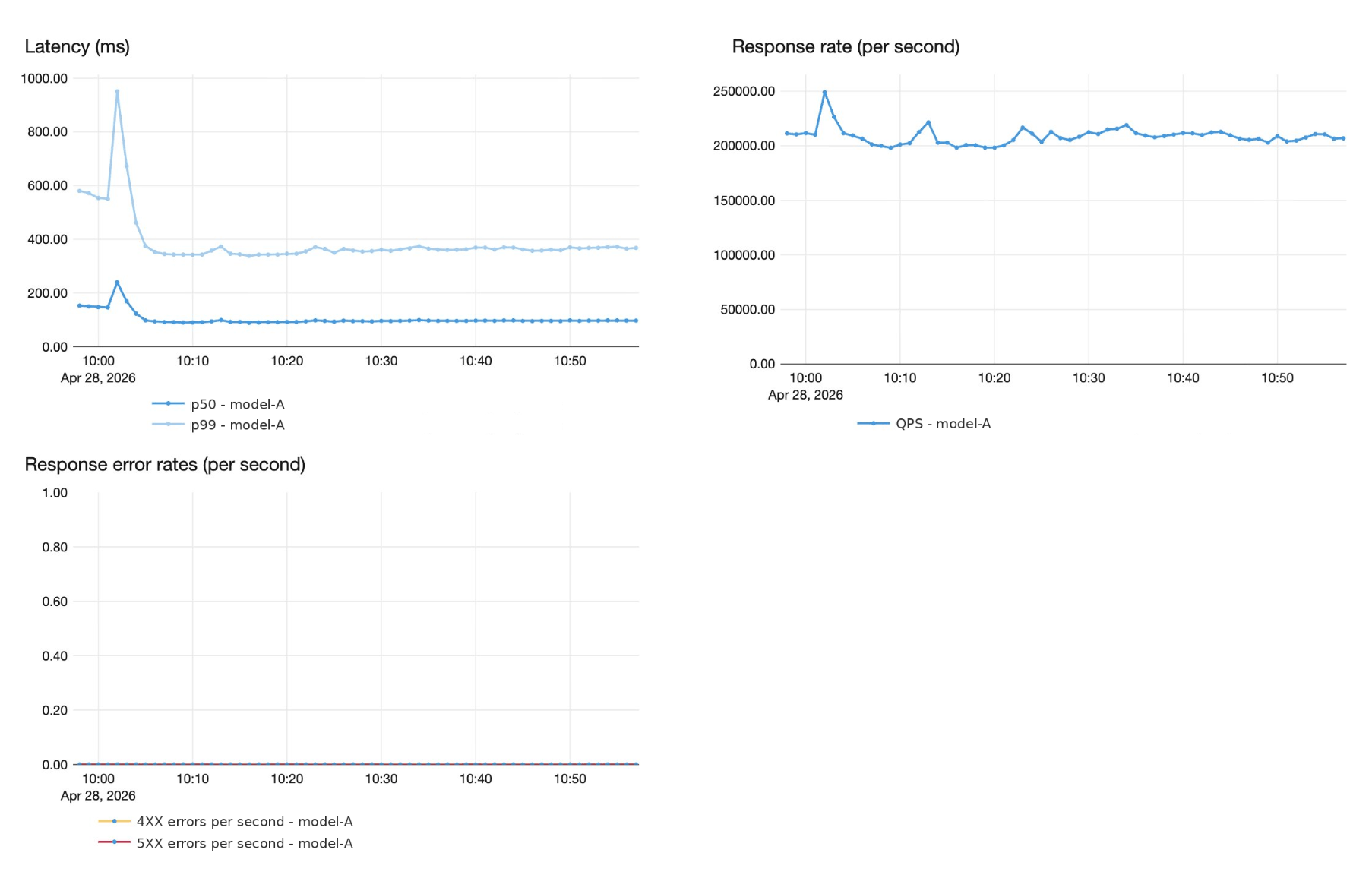
Detrás de muchas de las sugerencias en tiempo real de Superhuman se encuentra un modelo de IA personalizado y altamente sofisticado, servido a gran escala. Superhuman ejecuta este modelo con un tráfico pico de más de 200.000 consultas por segundo, con una latencia de extremo a extremo inferior a 1 segundo en P99 y estrictas garantías de fiabilidad de 4 nueves. Superhuman modernizó su pila de servicio para modelos de lenguaje grandes aprovechando el servicio de modelos de Databricks, lo que requirió un nuevo tipo de asociación, basada en el trabajo conjunto de productos e ingeniería.
Cómo Superhuman modernizó su pila de servicio
Antes de esta migración, Superhuman operaba una pila de servicio DIY construida sobre vLLM, junto con herramientas internas para entrenamiento y gestión de modelos. Un equipo de infraestructura de ML interno mantenía esta pila, que soportaba una escala masiva, pero varios puntos débiles se estaban acumulando al servir modelos de lenguaje grandes.
El modelo de lenguaje grande personalizado potencia la corrección de errores gramaticales a un volumen enorme, más de 200.000 QPS pico con aproximadamente 50 tokens de entrada y 50 tokens de salida por solicitud. Estaba empujando los límites de lo que la pila basada en L40S-gpus podía ofrecer. Cada nueva iteración del modelo requería meses de ajuste manual de rendimiento para incorporarlo. Mientras tanto, la carga operativa estaba creciendo, con la planificación de capacidad, el ajuste de rendimiento y el escalado automático consumiendo tiempo de un equipo reducido que necesitaba centrarse en la calidad del modelo y las innovaciones del producto.
Superhuman necesitaba un socio de plataforma que pudiera comprometerse con los SLA de rendimiento y latencia en la pila de servicio, y que co-invirtiera en la ingeniería necesaria para cumplirlos. Ambos equipos definieron SLOs de latencia en tiempo real objetivo por adelantado: latencia p99 inferior a un segundo y cero regresión de calidad en los sistemas de evaluación internos de Superhuman.
Cumplimiento de los SLA en tiempo real en la infraestructura de la plataforma
Alcanzar los objetivos de latencia en un solo pod es necesario pero no suficiente. Servir más de 200.000 QPS de forma fiable requiere una infraestructura que pueda equilibrar la carga, escalar dinámicamente y absorber picos. Lograr esto requirió una estrecha colaboración entre ambos equipos.
Optimización del balanceo de carga: elecciones de potencia de dos
El tráfico del punto final de corrección gramatical de Superhuman exhibe fuertes patrones diurnos con rápidas rampas en ciertos períodos, a menudo superando los 200.000 QPS. Si bien el balanceador de carga round robin predeterminado de Kubernetes es suficiente a QPS bajos, nuestras pruebas revelaron que este rendimiento se degrada a QPS más altos, con una distribución desigual de solicitudes que crea puntos calientes que aumentan la latencia de cola.
En el núcleo de nuestro enfoque se encuentra el Servicio de Descubrimiento de Puntos Finales (EDS), un plano de control ligero que monitorea continuamente la API de Kubernetes para detectar cambios en Servicios y EndpointSlices. EDS impulsa un algoritmo de balanceo de carga personalizado basado en la potencia de dos elecciones (cita). Para cada solicitud, se muestrean dos pods candidatos y el tráfico se dirige al que tenga menos solicitudes activas, evitando los puntos calientes que el round robin crea a QPS altos (ver blog).
Para mantener la plataforma rentable para patrones de tráfico variables, el sistema escala automáticamente de forma dinámica con la demanda del cliente. El escalador automático rastrea request_concurrency promediado en los pods, con objetivos de concurrencia por pod derivados de la evaluación comparativa del RPS máximo sostenible por réplica. La estrategia de escalado es intencionalmente asimétrica: el escalado ascendente es agresivo y receptivo, mientras que el escalado descendente es conservador, para evitar el aleteo que causa picos de latencia. A través de pruebas conjuntas de sombra entre Superhuman y Databricks, detectamos casos extremos y corregimos problemas al ajustar parámetros en el escalador automático, incluido cuándo escalar agresivamente, cuándo mantenerse estable y cuán conservador ser en el escalado descendente.
Optimización del inicio del contenedor mediante aceleración de imágenes
Cuando el tráfico del punto final de Superhuman aumenta de fuera de pico a pico, el escalador automático necesita agregar docenas de pods. Si cada pod tarda minutos en descargar su imagen de contenedor y arrancar, los usuarios experimentan picos de latencia durante la rampa. Reducir el tiempo de inicio del pod se traduce directamente en un escalado ascendente más rápido y una latencia más suave durante los picos de tráfico.
El equipo de servicio de modelos de Databricks adoptó el trabajo de aceleración de imágenes originalmente creado para la computación sin servidor (blog) para evitar arranques en frío. El enfoque se adapta bien a los modelos relativamente pequeños que servimos para Superhuman.
Al construir una imagen de contenedor, agregamos un paso adicional para convertir el formato de imagen estándar basado en gzip al formato basado en dispositivo de bloque adecuado para la carga diferida. Esto permite que la imagen del contenedor se represente como un dispositivo de bloque buscable con sectores de 4 MB en producción.
Al descargar imágenes de contenedor, nuestro tiempo de ejecución de contenedor personalizado recupera solo los metadatos necesarios para configurar el directorio raíz del contenedor, incluida la estructura del directorio, los nombres de archivo y los permisos, y crea un dispositivo de bloque virtual en consecuencia. Luego, monta el dispositivo de bloque virtual en el contenedor para que la aplicación pueda comenzar a ejecutarse de inmediato.
Cuando la aplicación lee un archivo por primera vez, la solicitud de E/S contra el dispositivo de bloque virtual emitirá una devolución de llamada al proceso de obtención de imágenes, que recupera el contenido real del bloque del registro de contenedores remoto. El contenido del bloque recuperado también se almacena en caché localmente para evitar viajes de ida y vuelta de red repetidos al registro de contenedores, lo que reduce el impacto de la latencia de red variable en lecturas futuras.
Este sistema de archivos de contenedor de carga diferida elimina la necesidad de descargar toda la imagen del contenedor antes de iniciar la aplicación, reduciendo el tiempo de inicio del contenedor de varios minutos a solo unos segundos.
Optimizaciones de tiempo de ejecución: 60% más de rendimiento por pod
Con la capa de plataforma manejando la escala de la flota, la siguiente pregunta fue cuántos QPS podía soportar cada pod y a qué costo.
En esta sección, presentamos las optimizaciones que aumentaron el rendimiento por pod de 750 QPS a 1.200 QPS en GPUs H100, una mejora del 60%, manteniendo cero regresiones de calidad.
Cuantización FP8
La cuantización FP8 fue la mayor mejora de rendimiento individual, logrando hasta un 30% de aumento en QPS por pod.
El equipo de ML de Superhuman pre-cuantizó el checkpoint a FP8 utilizando la biblioteca de cuantización en línea de vLLM, produciendo un checkpoint en formato de tensor comprimido que Databricks cargó para el servicio. En la configuración final, las proyecciones de atención (Q, K, V y salida) y las proyecciones MLP se ejecutaron a través de la ruta FP8, mientras que la cuantización de la caché KV se dejó deshabilitada, ya que la cuantización de pesos era de donde provenían las ganancias de rendimiento y la cuantización de la caché KV introducía sus propias compensaciones de calidad que no valían la pena para esta carga de trabajo.
Antes de decidir la configuración final, ambos equipos iteraron sobre qué capas cuantizar. Las proyecciones MLP se cuantizaron desde el principio, y la pregunta abierta era si cuantizar las capas de atención. El servicio de modelos de Databricks había diseñado el motor de servicio para admitir inferencia de precisión mixta desde el principio, de modo que si algún grupo de capas resultaba demasiado sensible a la calidad bajo cuantización, podríamos mantenerlo en mayor precisión sin cambiar la arquitectura general de servicio. Enviamos un indicador que nos permitió activar y desactivar la cuantización de atención, para que ambos equipos pudieran medir su impacto directamente. El experimento se resolvió limpiamente, cuantizar las proyecciones Q/K/V y de salida no produjo ninguna degradación medible de la calidad en las evaluaciones de Superhuman.
La otra consideración fue la granularidad de la cuantización. Los kernels listos para usar utilizaban escalado por tensor (un único factor de escala FP8 para todo un tensor de pesos). Los kernels de Databricks utilizan escalado por canal, calculando un factor de escala separado por canal de salida de cada capa lineal. Esto preserva el rango dinámico donde importa, mantiene el error de cuantización de la capa MLP muy por debajo del umbral donde aparece en las evaluaciones. Combinado con mejoras a nivel de kernel, la cuantización por canal igualó o superó otras bases de código abierto con el mismo rendimiento.
Eliminación de cuellos de botella del lado de la CPU
Para modelos pequeños y rápidos, el rendimiento a menudo se ve limitado por la CPU, no por la GPU. El equipo de Databricks ya había investigado la eliminación de cuellos de botella de la CPU en su trabajo sobre servicio PEFT rápido y aquí aplicaron optimizaciones de CPU similares directamente a la carga de trabajo de Superhuman.
Específicamente, el equipo introdujo un servidor de tiempo de ejecución multiproceso. Para la mayoría de las cargas de trabajo de servicio de modelos, un solo proceso es más que suficiente para mantener la GPU saturada, ya que la GPU es el cuello de botella, no la CPU. Pero con un modelo pequeño y rápido, la GPU completa su pase hacia adelante más rápido de lo que un solo proceso puede preparar el siguiente lote, invirtiendo el cuello de botella a la CPU.
El equipo abordó esto ejecutando múltiples procesos de servidor RPC. Al tener múltiples procesos de CPU que preparan y despachan trabajo a la GPU en paralelo, eliminamos el cuello de botella de serialización de un solo proceso. Esto entregó un 20% adicional de rendimiento.
Otras optimizaciones del lado de la CPU mejoraron el rendimiento en unos pocos puntos porcentuales.
- Reducción de la sobrecarga de Python. Reemplazamos el corte, copiado y relleno de tensores a nivel de Python al inicio de cada paso de decodificación del grafo CUDA con una sola llamada a C++. También exploramos estrategias paralelas (ThreadPool, OpenMP), pero C++ de un solo hilo fue óptimo debido a la sobrecarga de sincronización de CUDA. Esto redujo ligeramente el tiempo de inactividad de la GPU por pasada hacia adelante.
- Programación asíncrona para una mejor superposición del trabajo de CPU-GPU. Movimos el postprocesamiento del lado de la CPU fuera de la ruta crítica para que se ejecute concurrentemente con la siguiente pasada hacia adelante de la GPU. En lugar de terminar todo el postprocesamiento del lote N antes de lanzar el lote N+1, el programador despacha N+1 inmediatamente y maneja el postprocesamiento de N en paralelo. El postprocesamiento también itera solo sobre el subconjunto relevante de solicitudes en lugar del lote completo. Esto resultó en que la siguiente pasada hacia adelante comenzara antes.
¿Qué sigue?
Este trabajo es la base para una asociación más amplia. Superhuman está migrando modelos adicionales a Databricks, abarcando diferentes tamaños de modelos, tipos de tareas y requisitos de latencia, y adoptando la Plataforma de IA de manera más amplia para flujos de trabajo de entrenamiento, seguimiento de experimentos, evaluaciones (ML clásico, Deep-Learning e IA Generativa/Agentes), registro de modelos y jueces (LLM) e ingesta de trazas de agentes a escala.
La construcción de esta plataforma a gran escala fue un esfuerzo de toda la empresa en ambos lados, y una experiencia de aprendizaje extraordinaria. Muchas gracias a los equipos de ML e infraestructura de Superhuman por la profunda colaboración, la voluntad de iterar abiertamente en compensaciones difíciles y el rigor que aportaron a cada barra de calidad y prueba de carga. El manual de ingenier�ía que construimos juntos es suyo tanto como nuestro, y estamos emocionados de aportar el mismo nivel de asociación a cada carga de trabajo que siga.
Conclusiones clave
Usar un servicio de inferencia administrado no tiene por qué significar renunciar al control. Superhuman conserva la propiedad total del entrenamiento del modelo, la cuantización y los estándares de calidad, mientras que Databricks mantiene el rendimiento en tiempo de ejecución y la confiabilidad de la plataforma. Esta división de responsabilidades funciona bien con SLO compartidos, validación de calidad conjunta y pruebas de carga progresivas al integrar la plataforma Databricks.
¿Listo para servir sus modelos personalizados a escala? Descubra cómo la API de Modelos Fundacionales de Databricks puede cumplir con sus SLA de inferencia más exigentes y brindarle a su equipo un verdadero socio de ingeniería, no solo un servicio administrado. Contáctenos en https://www.databricks.com/company/contact para integrar su caso de uso de servicio de modelos de alto QPS.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.