Cómo depuramos miles de bases de datos con IA en Databricks
Lecciones al construir una plataforma de depuración de bases de datos asistida por IA
- En Databricks, operamos miles de instancias OLTP en cientos de regiones en AWS, Azure y GCP.
- Construimos una plataforma agentiva que unifica métricas, herramientas y experiencia para ayudar a nuestros ingenieros a administrar sus bases de datos a esta escala.
- Esta plataforma agentiva ahora se usa en toda la empresa, reduciendo el tiempo de depuración hasta en un 90% y la curva de aprendizaje para operar nuestra infraestructura.
En Databricks, hemos reemplazado las operaciones manuales de bases de datos con IA, reduciendo el tiempo dedicado a la depuración hasta en un 90%.
Nuestro agente de IA interpreta, ejecuta y depura recuperando métricas y registros clave, y correlacionando automáticamente las señales. Opera en una flota de bases de datos implementadas en cada nube principal y en casi todas las regiones en la nube.
Esta nueva capacidad de agente ha permitido a los ingenieros responder rutinariamente preguntas en lenguaje natural sobre la salud y el rendimiento de su servicio sin necesidad de contactar a los ingenieros de guardia en los equipos de almacenamiento.
Lo que comenzó como un pequeño proyecto de hackathon para simplificar el flujo de investigación ha evolucionado hasta convertirse en una plataforma inteligente con adopción en toda la empresa. Este es nuestro viaje.
Antes de la IA: Todo Funcionaba, pero Nada Funcionaba en Conjunto
Durante una investigación típica de incidentes de MySQL, un ingeniero a menudo
- Consultaba métricas en Grafana
- Cambiaba a un panel de Databricks para comprender la carga de trabajo del cliente
- Ejecutaba comandos CLI para inspeccionar el estado de InnoDB, una instantánea del estado interno de MySQL que contiene información como el historial de transacciones, operaciones de E/S y detalles de interbloqueo
- Iniciaba sesión en una consola en la nube para descargar registros de consultas lentas
Cada herramienta funcionaba bien por sí sola, pero juntas no lograban formar un flujo de trabajo coherente ni proporcionar información de extremo a extremo. Un ingeniero experimentado de MySQL podía armar una hipótesis saltando entre pestañas y comandos en la secuencia correcta; sin embargo, esto consume un valioso presupuesto de SLO y tiempo en el proceso. Un ingeniero más nuevo a menudo no sabía por dónde empezar.
Irónicamente, esta fragmentación en nuestras herramientas internas reflejaba el desafío que Databricks ayuda a nuestros clientes a superar.
La Plataforma de Inteligencia de Datos de Databricks unifica datos, gobernanza e IA, permitiendo a los usuarios autorizados comprender sus datos y actuar sobre ellos. Internamente, nuestros ingenieros requieren lo mismo: una plataforma unificada que consolide los datos y flujos de trabajo que sustentan nuestra infraestructura. Con esa base, podemos aplicar inteligencia utilizando IA para interpretar los datos y guiar a los ingenieros hacia el siguiente paso correcto.
Nuestro Viaje: De Hackathon a Agentes Inteligentes
No empezamos con una iniciativa grande de varios trimestres. En cambio, probamos la idea durante un hackathon en toda la empresa. En dos días, construimos un prototipo simple que unificó algunas métricas y paneles de bases de datos principales en una sola vista. No estaba pulido, pero mejoró inmediatamente los flujos de trabajo básicos de investigación. Eso estableció nuestro principio rector: actuar rápido y mantenernos obsesionados con el cliente.
Construyendo Plataformas con Obsesión por el Cliente
Antes de escribir más código, entrevistamos a los equipos de servicio para comprender sus puntos débiles en la depuración. Los temas eran consistentes: los ingenieros junior no sabían por dónde empezar, y los ingenieros senior encontraban las herramientas fragmentadas y engorrosas.
Para ver el problema de primera mano, seguimos sesiones de guardia y observamos a los ingenieros depurar problemas en tiempo real. Tres patrones se destacaron:
- Herramientas fragmentadas
Los ingenieros manejaban paneles, CLIs y pasos manuales para la investigación y operaciones como reinicios o restauraciones. Cada herramienta funcionaba de forma aislada, pero la falta de integración hacía que el flujo de trabajo fuera lento y propenso a errores. - Tiempo perdido recopilando contexto
La mayor parte del trabajo consistía en averiguar qué había cambiado, cómo era lo “normal” y quién tenía el contexto adecuado para ayudar, pero no en mitigar el incidente en sí. - Guía poco clara sobre mitigación segura
Durante los incidentes, los ingenieros a menudo no estaban seguros de qué acciones eran seguras o efectivas. Sin runbooks claros o automatización, recurrían a largas investigaciones o esperaban a los expertos.
En retrospectiva, los postmortems rara vez exponían esta brecha: los equipos no carecían de datos o herramientas; carecían de depuración inteligente para interpretar el torrente de señales y guiarlos hacia acciones seguras y efectivas.
Iterando Hacia la Inteligencia
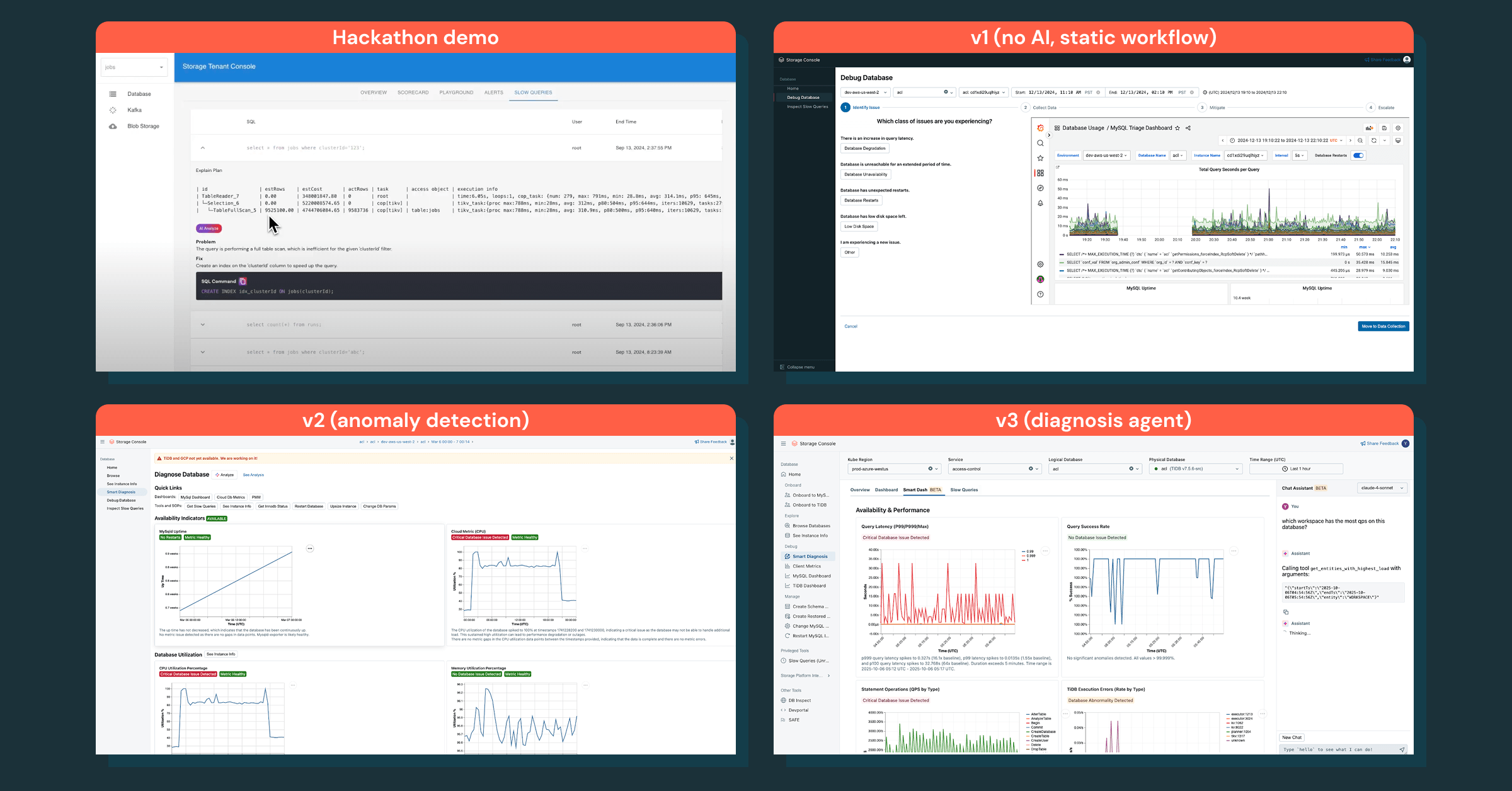
Empezamos poco a poco, con la investigación de bases de datos como primer caso de uso. Nuestra v1 fue un flujo de trabajo agentivo estático que seguía un SOP de depuración, pero no fue efectivo: los ingenieros querían un informe de diagnóstico con información inmediata, no una lista de verificación manual.
Cambiamos nuestro enfoque a obtener los datos correctos y superponer inteligencia. Esta estrategia condujo a la detección de anomalías, que mostró las anomalías correctas, pero aún no proporcionaba los próximos pasos claros.
El verdadero avance llegó con un asistente de chat que codifica el conocimiento de depuración, responde preguntas de seguimiento y convierte las investigaciones en un proceso interactivo. Esto transformó la forma en que los ingenieros depuran incidentes de extremo a extremo.
Una Base: Abstracción y Centralización
Dando un paso atrás, nos dimos cuenta de que, si bien nuestro marco existente podía unificar flujos de trabajo y datos en una sola interfaz, nuestro ecosistema no estaba diseñado para que la IA razone sobre nuestro panorama operativo. Cualquier agente necesitaría manejar la lógica específica de la región y la nube. Y sin controles de acceso centralizados, se volvería demasiado restrictivo para ser útil o demasiado permisivo para ser seguro.
Estos problemas son especialmente difíciles de resolver en Databricks, ya que operamos miles de instancias de bases de datos en cientos de regiones, ocho dominios regulatorios y tres nubes. Sin una base sólida que abstraiga las diferencias de nube y regulatorias, la integración de IA se toparía rápidamente con una serie de obstáculos inevitables:
- Fragmentación de contexto: Los datos de depuración vivían en diferentes lugares, lo que dificultaba que un agente construyera una imagen coherente.
- Límites de gobernanza poco claros: Sin autorización centralizada y aplicación de políticas, garantizar que el agente (y los ingenieros) permanezcan dentro de los permisos correctos se vuelve difícil.
- Bucles de iteración lentos: Las abstracciones inconsistentes dificultan la prueba y evolución del comportamiento de la IA, lo que ralentiza severamente la iteración con el tiempo.
Para que el desarrollo de IA sea seguro y escalable, nos centramos en fortalecer la base de la plataforma en torno a tres principios:
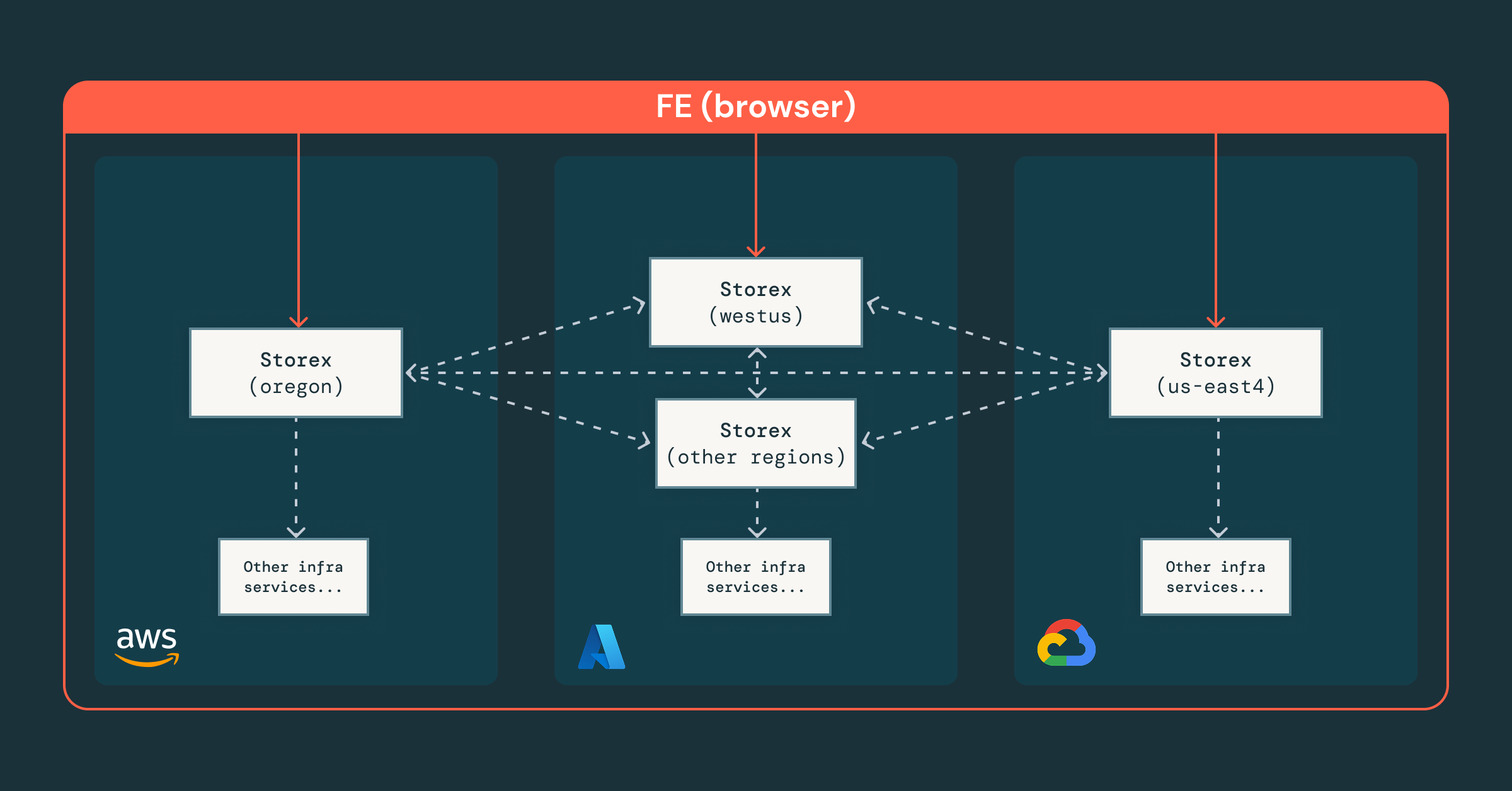
- Arquitectura fragmentada con enfoque central, donde una instancia global de Storex coordina fragmentos regionales, proporcionando una interfaz única mientras mantiene los datos sensibles locales y conformes.
- Control de acceso granular, aplicado a nivel de equipo, recurso y RPC, asegurando que los ingenieros y agentes operen de forma segura dentro de los permisos correctos.
- Orquestación unificada, donde nuestra plataforma integra servicios de infraestructura existentes, lo que permite abstracciones consistentes en todas las nubes y regiones.
Con los datos y el contexto centralizados, el siguiente paso se volvió claro: ¿cómo podíamos hacer que la plataforma no solo fuera unificada, sino también inteligente?
De la Visibilidad a la Inteligencia
Con una base unificada en su lugar, implementar y exponer capacidades como la recuperación de esquemas de bases de datos, métricas o registros de consultas lentas al agente de IA fue sencillo. En unas pocas semanas, construimos un agente que podía agregar información básica de la base de datos, razonar sobre ella y presentarla al usuario.
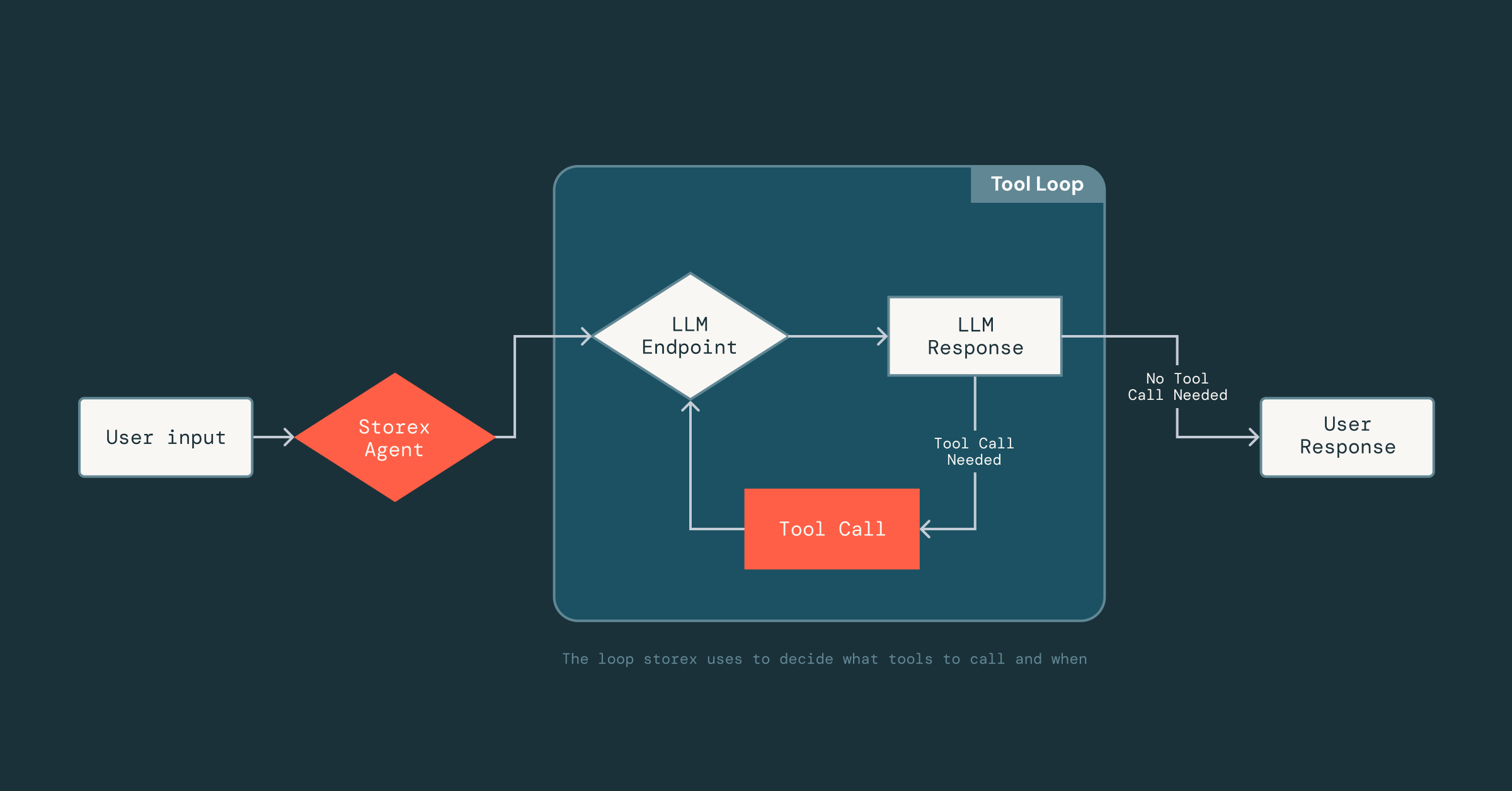
Ahora, la parte difícil era hacer que el agente fuera confiable: dado que los LLM no son deterministas, no sabíamos cómo respondería a las herramientas, los datos y los prompts a los que tenía acceso. Lograr esto requirió mucha experimentación para comprender qué herramientas eran efectivas y qué contexto incluir (o excluir) en los prompts.
Para permitir esta rápida iteración, construimos un marco ligero inspirado en las tecnologías de optimización de prompts de MLflow que aprovecha DsPy, que desacopla la generación de prompts de la implementación de herramientas. Los ingenieros pueden definir herramientas como clases Scala normales y firmas de funciones, y simplemente agregar una breve cadena de documentación que describa la herramienta. A partir de ahí, el LLM puede inferir el formato de entrada de la herramienta, la estructura de salida y cómo interpretar los resultados. Este desacoplamiento nos permite avanzar rápidamente: podemos iterar en los prompts o intercambiar herramientas dentro y fuera del agente sin cambiar constantemente la infraestructura subyacente que maneja el análisis, las conexiones LLM o el estado de la conversación.
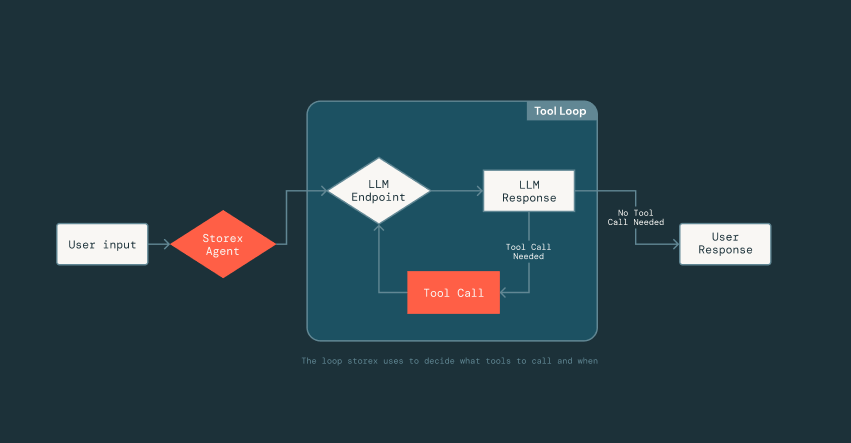{kind=link}
A medida que iteramos, ¿cómo demostramos que el agente está mejorando sin introducir regresiones? Para abordar esto, creamos un marco de validación que captura instantáneas del estado de producción y las reproduce a través del agente, utilizando un LLM "juez" separado para calificar las respuestas en cuanto a precisión y utilidad a medida que modificamos los prompts y las herramientas.
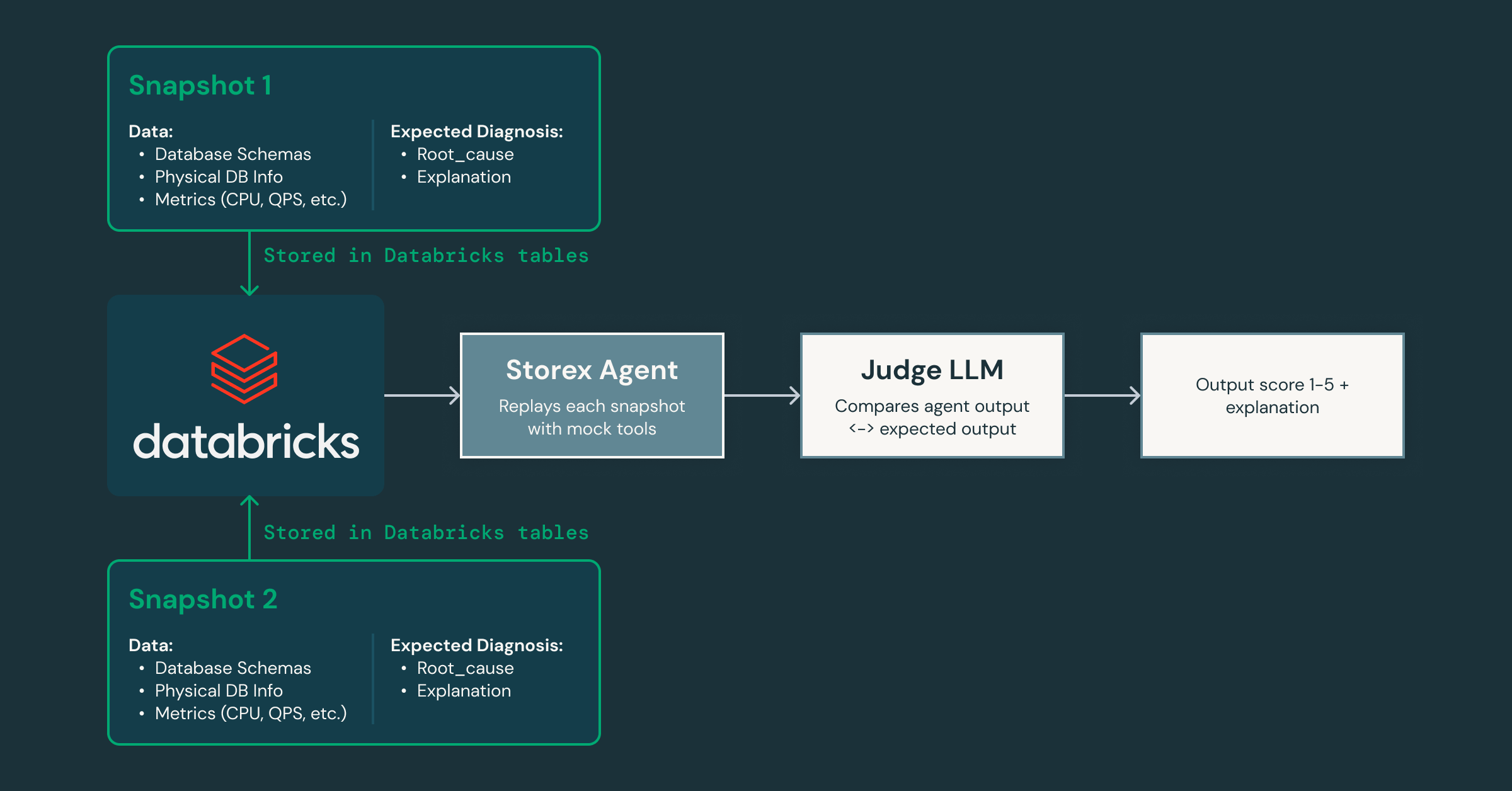
Dado que este marco nos permite iterar rápidamente, podemos crear fácilmente agentes especializados para diferentes dominios: uno enfocado en problemas del sistema y la base de datos, otro en patrones de tráfico del lado del cliente, y así sucesivamente. Esta descomposición permite que cada agente desarrolle una profunda experiencia en su área mientras colabora con otros para ofrecer un análisis de causa raíz más completo. También allana el camino para integrar agentes de IA en otras partes de nuestra infraestructura, extendiéndose más allá de las bases de datos.
Con el conocimiento experto y el contexto operativo codificados en su razonamiento, nuestro agente puede extraer información significativa y guiar activamente a los ingenieros a través de las investigaciones. En cuestión de minutos, presenta registros y métricas relevantes que los ingenieros podrían no haber considerado examinar. Conecta síntomas entre capas, como identificar el espacio de trabajo que impulsa la carga inesperada y correlacionar los picos de IOPS con migraciones de esquemas recientes. Incluso explica la causa y el efecto subyacentes, y recomienda los próximos pasos para la mitigación.
En conjunto, estas piezas marcan nuestro cambio de la visibilidad a la inteligencia. Hemos ido más allá de la visibilidad de herramientas y métricas hacia una capa de razonamiento que comprende nuestros sistemas, aplica conocimientos expertos y guía a los ingenieros hacia mitigaciones seguras y efectivas. Es una base sobre la que podemos seguir construyendo no solo para las bases de datos, sino también para la forma en que operamos la infraestructura en su conjunto.
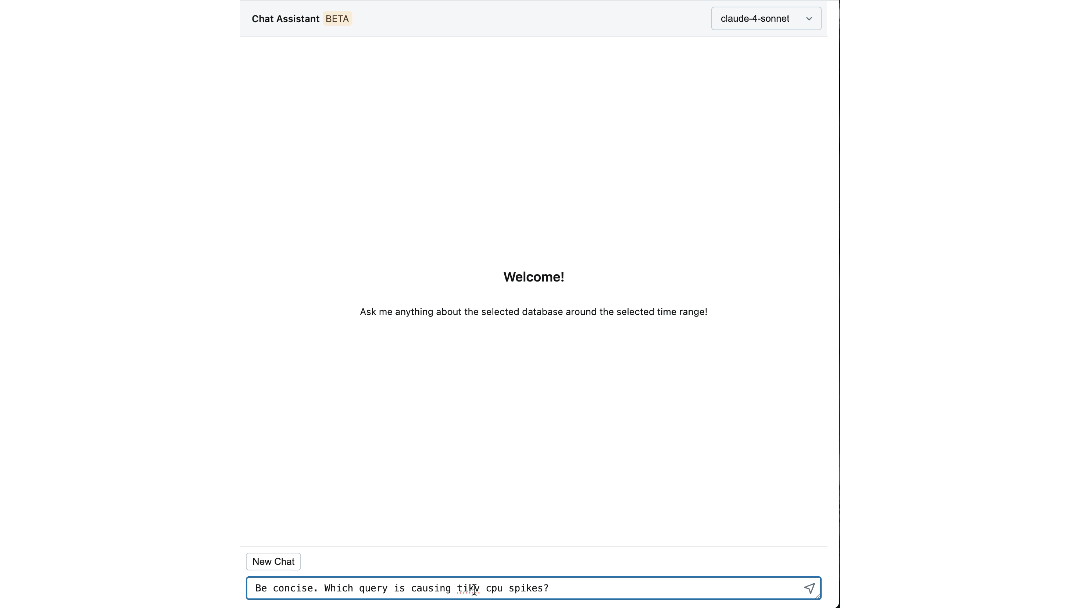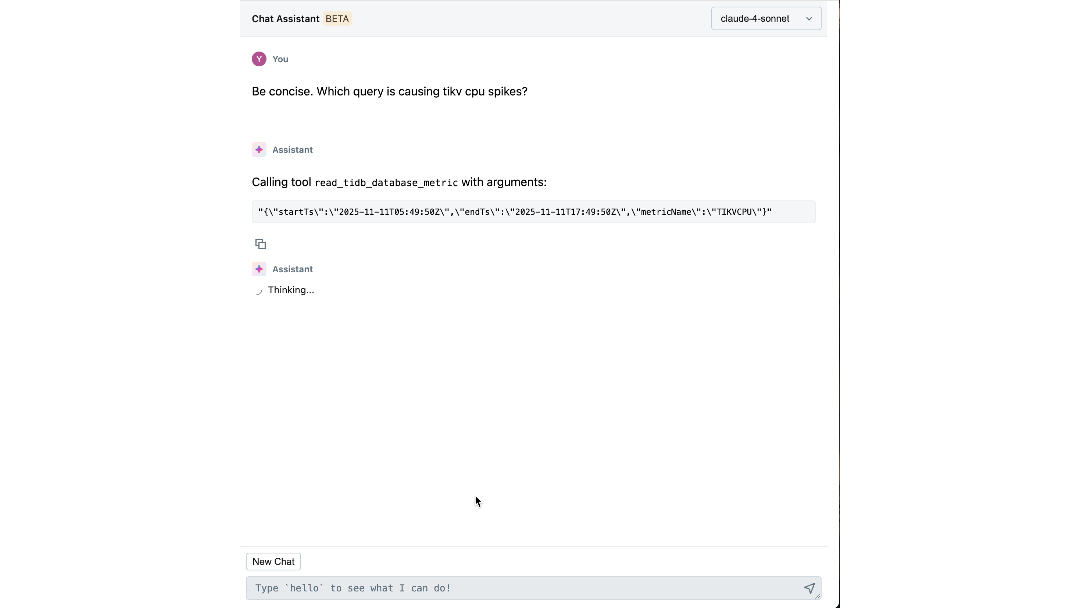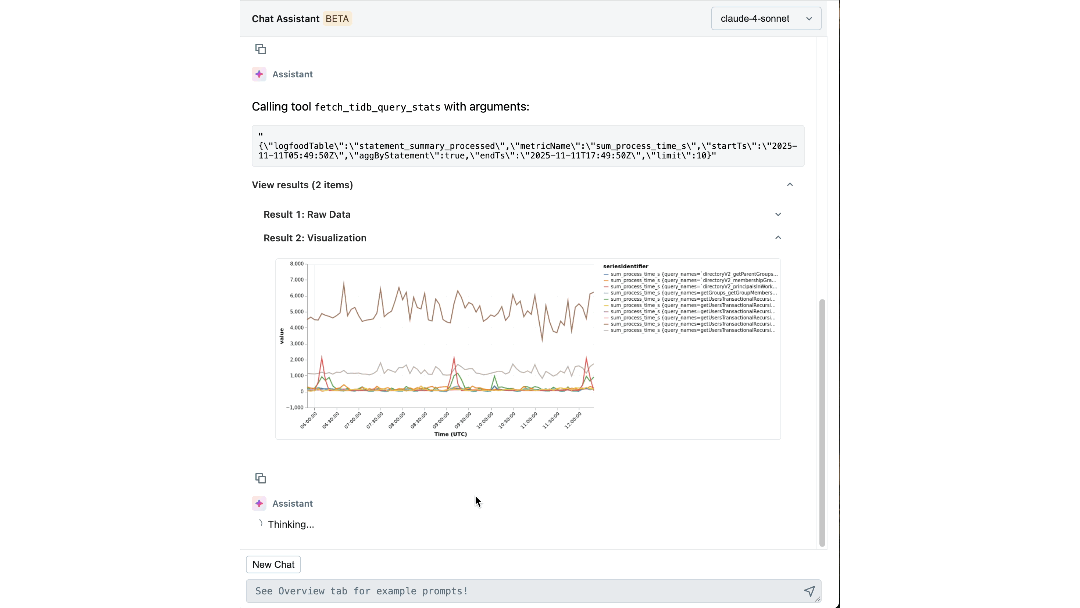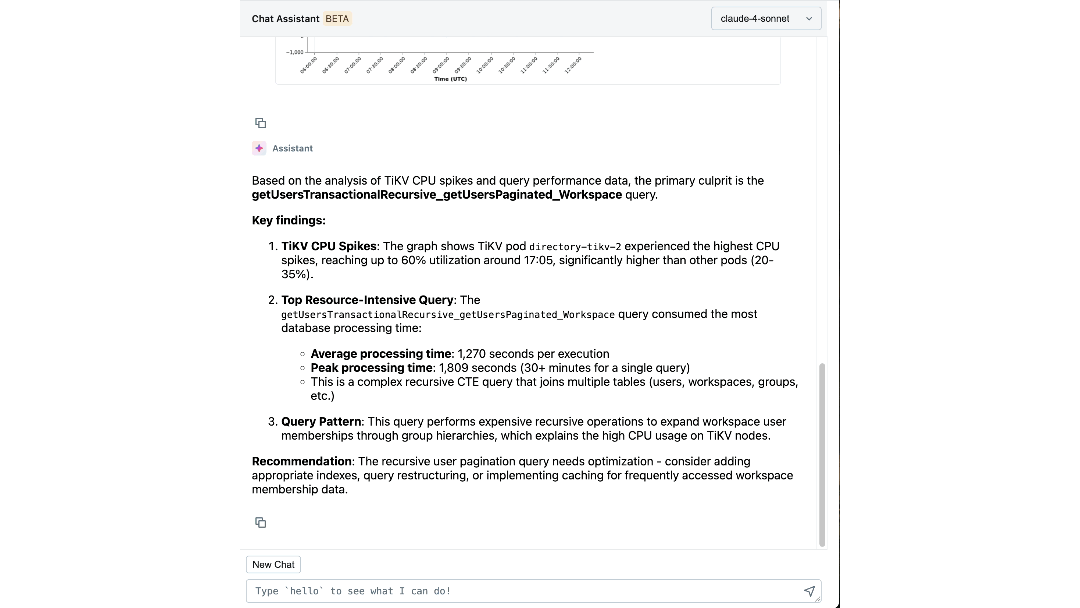
El Impacto: Redefiniendo Cómo Construimos y Operamos a Escala
La plataforma ha cambiado la forma en que los ingenieros de Databricks interactúan con su infraestructura. Los pasos individuales que antes requerían cambiar entre paneles, CLIs y SOPs ahora pueden ser respondidos fácilmente por nuestro asistente de chat, reduciendo el tiempo empleado hasta en un 90%.
La curva de aprendizaje de nuestra infraestructura entre los nuevos ingenieros también se redujo drásticamente. Los nuevos empleados sin contexto previo ahora pueden iniciar una investigación de base de datos en menos de 5 minutos, algo que habría sido casi imposible antes. Y hemos recibido excelentes comentarios desde el lanzamiento de esta plataforma:
El asistente de bases de datos realmente me ahorra mucho tiempo, ya que no necesito recordar dónde están todos mis paneles de consulta. Simplemente puedo preguntarle qué espacio de trabajo está generando la carga. ¡La mejor herramienta!—Yuchen Huo, Ingeniero Principal
Soy un usuario habitual y no puedo creer que viviéramos en su ausencia. El nivel de pulido y utilidad es muy impresionante. Gracias equipo, es un cambio radical en la experiencia del desarrollador.—Dmitriy Kunitskiy, Ingeniero Principal
Me encanta especialmente cómo estamos aportando información impulsada por IA a la depuración de problemas de infraestructura. Aprecio lo previsor que ha sido el equipo al diseñar esta consola desde cero teniéndolo en cuenta.—Ankit Mathur, Ingeniero Principal Senior
Arquitectónicamente, la plataforma sienta las bases para la próxima evolución: operaciones de producción asistidas por IA. Con datos, contexto y salvaguardas unificados, ahora podemos explorar cómo el agente puede ayudar con restauraciones, consultas de producción y actualizaciones de configuración: el siguiente paso hacia un flujo de trabajo operativo asistido por IA.
Pero el impacto más significativo no fue solo la reducción del trabajo pesado o la incorporación más rápida: fue un cambio de mentalidad. Nuestro enfoque ha pasado de la arquitectura técnica a los recorridos críticos del usuario (CUJs) que definen cómo los ingenieros experimentan nuestros sistemas. Este enfoque centrado en el usuario es lo que permite a nuestros equipos de infraestructura crear plataformas sobre las cuales nuestros ingenieros pueden construir productos ganadores en su categoría.
Conclusiones
Al final, nuestro viaje se redujo a tres conclusiones:
- La iteración rápida es esencial para el desarrollo de agentes: Los agentes mejoran a través de la experimentación, validación y refinamiento rápidos. Nuestro marco inspirado en DsPy lo permitió al permitirnos evolucionar rápidamente los prompts y las herramientas.
- La velocidad de iteración está limitada por la base subyacente: Los datos unificados, las abstracciones consistentes y el control de acceso granular eliminaron nuestros mayores cuellos de botella, haciendo que la plataforma sea confiable, escalable y lista para la IA.
- La velocidad solo importa cuando tiene la dirección correcta: No nos propusimos construir una plataforma de agentes. Cada iteración simplemente siguió los comentarios de los usuarios y nos acercó a la solución que los ingenieros necesitaban.
Construir plataformas internas es engañosamente difícil. Incluso dentro de la misma empresa, los equipos de producto y plataforma operan bajo restricciones muy diferentes. En Databricks, estamos cerrando esa brecha construyendo con obsesión por el cliente, simplificando a través de abstracciones y elevando con inteligencia, tratando a nuestros clientes internos con el mismo cuidado y rigor que aplicamos a nuestros clientes externos.
Únete a Nosotros
Mientras miramos hacia el futuro, estamos emocionados de seguir superando los límites de cómo la IA puede dar forma a los sistemas de producción y hacer que la infraestructura compleja se sienta sin esfuerzo. Si te apasiona construir la próxima generación de plataformas internas impulsadas por IA, ¡únete a nosotros!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.