Presentamos la Evaluación Mejorada de Agentes
Personalización más fácil y mejor colaboración con las partes interesadas del negocio
por Eric Peter, Daniel Smilkov, Nikhil Thorat, Alkis Polyzotis y Chenen Liang
- De piloto a producción: optimice la adopción de GenAI con evaluaciones automatizadas, comentarios de expertos y rutas de iteración claras en ambas fases.
- Evaluación personalizable de GenAI: defina métricas personalizadas, use el nuevo Juez de IA de Directrices y evalúe cualquier caso de uso con esquemas de entrada/salida flexibles.
- Colaboración fluida con expertos: la aplicación de revisión actualizada simplifica la recopilación de comentarios y la gestión de conjuntos de datos de evaluación.
Esta semana, anunciamos nuevas capacidades de desarrollo de agentes en Databricks. Después de hablar con cientos de clientes, hemos notado dos desafíos comunes para avanzar más allá de las fases piloto. Primero, los clientes carecen de confianza en el rendimiento de producción de sus modelos. Segundo, los clientes no tienen un camino claro para iterar y mejorar. Juntos, estos a menudo conducen a proyectos estancados o procesos ineficientes donde los equipos luchan por encontrar expertos en la materia para evaluar manualmente los resultados de los modelos.
Hoy, abordamos estos desafíos expandiendo Databricks MLflow con nuevas capacidades de Vista Previa Pública. Estas mejoras ayudan a los equipos a comprender y mejorar mejor sus aplicaciones GenAI a través de evaluaciones automatizadas personalizables y comentarios simplificados de los partes interesadas del negocio.
- Personaliza las evaluaciones automatizadas: Usa jueces de IA de directrices para calificar aplicaciones GenAI con reglas en lenguaje natural, y define métricas críticas para el negocio con evaluaciones personalizadas de Python.
- Colabora con expertos del dominio: Aprovecha la Aplicación de Revisión y el nuevo SDK de conjunto de datos de evaluación para recopilar comentarios de expertos del dominio, etiquetar rastreos de aplicaciones GenAI y refinar conjuntos de datos de evaluación, potenciado por tablas Delta y la gobernanza de Unity Catalog.
Para ver estas capacidades en acción, consulta nuestro notebook de ejemplo.
Personaliza la evaluación de GenAI para las necesidades de tu negocio
Las aplicaciones GenAI y los sistemas de Agentes vienen en muchas formas, desde su arquitectura subyacente que utiliza bases de datos vectoriales y herramientas, hasta sus métodos de implementación, ya sea en tiempo real o por lotes. En Databricks, hemos aprendido que las tareas exitosas específicas del dominio requieren que los agentes también aprovechen los datos empresariales de manera efectiva. Este rango exige un enfoque de evaluación igualmente flexible.
Hoy, introducimos actualizaciones en Databricks MLflow para hacerlo altamente personalizable, diseñado para ayudar a los equipos a medir el rendimiento en cualquier aplicación específica del dominio para cualquier tipo de aplicación GenAI o sistema de Agente.
Juez de IA de Directrices: usa lenguaje natural para verificar si las aplicaciones GenAI siguen las directrices
Ampliando nuestro catálogo de jueces LLM integrados y ajustados por investigación que ofrecen precisión de primera clase, presentamos el Juez de IA de Directrices (Vista Previa Pública), que ayuda a los desarrolladores a usar listas de verificación o rúbricas en lenguaje natural en su evaluación. A veces se les conoce como notas de calificación, las directrices son similares a cómo los maestros definen criterios (por ejemplo, “El ensayo debe tener cinco párrafos”, “Cada párrafo debe tener una oración temática”, “El último párrafo de cada oración debe resumir todos los puntos tratados en el párrafo”, …).
Cómo funciona: Proporciona directrices al configurar la Evaluación de Agentes, que se evaluarán automáticamente para cada solicitud.
Ejemplos de directrices:
- La respuesta debe ser profesional.
- Cuando el usuario solicite comparar dos productos, la respuesta debe mostrar una tabla.
Por qué importa: Las directrices mejoran la transparencia y la confianza en la evaluación con los partes interesadas del negocio a través de rúbricas de calificación estructuradas y fáciles de entender, lo que resulta en una puntuación consistente y transparente de las respuestas de tu aplicación.
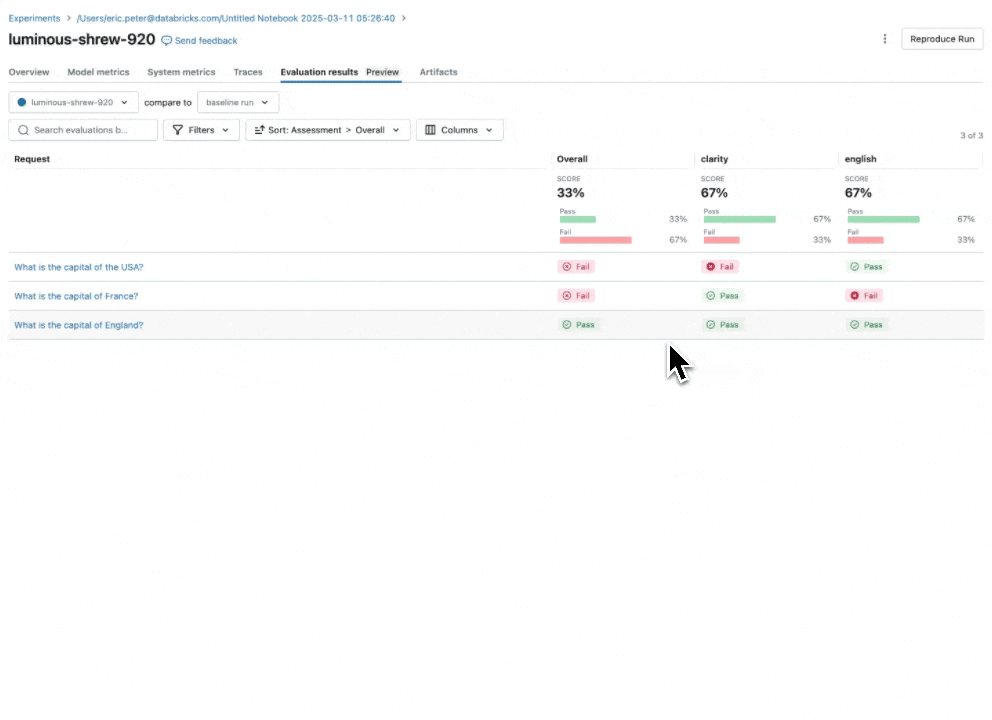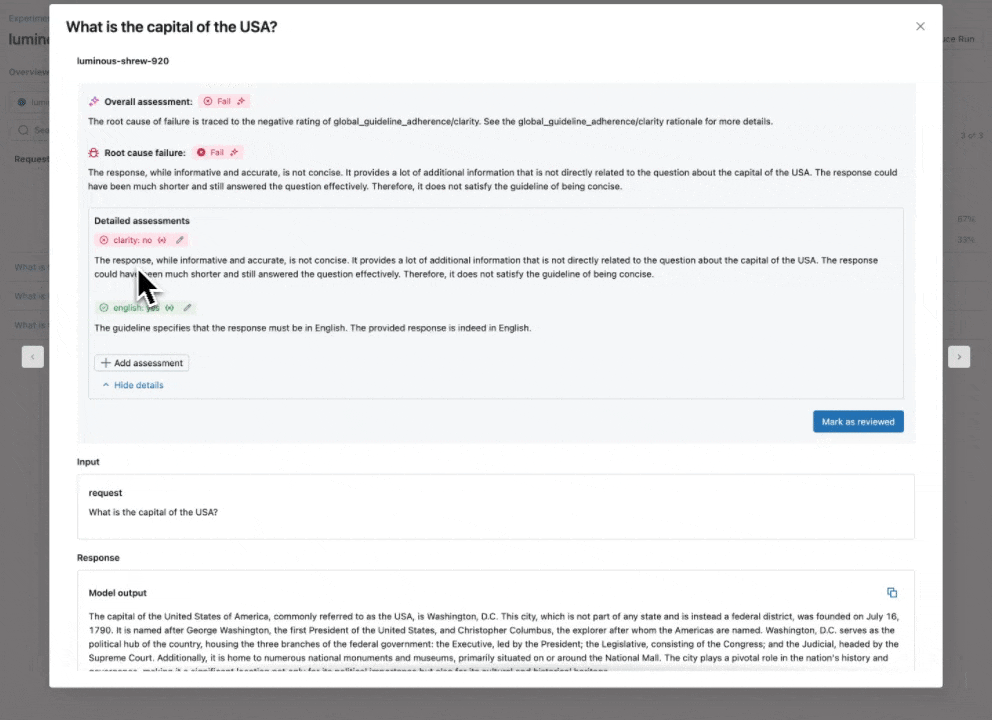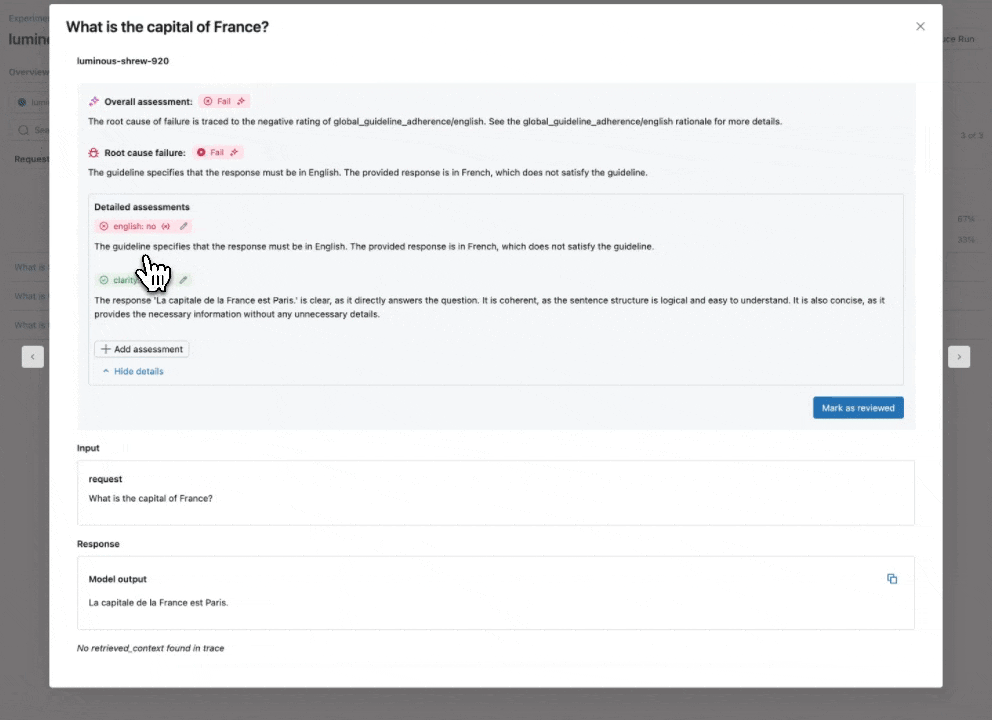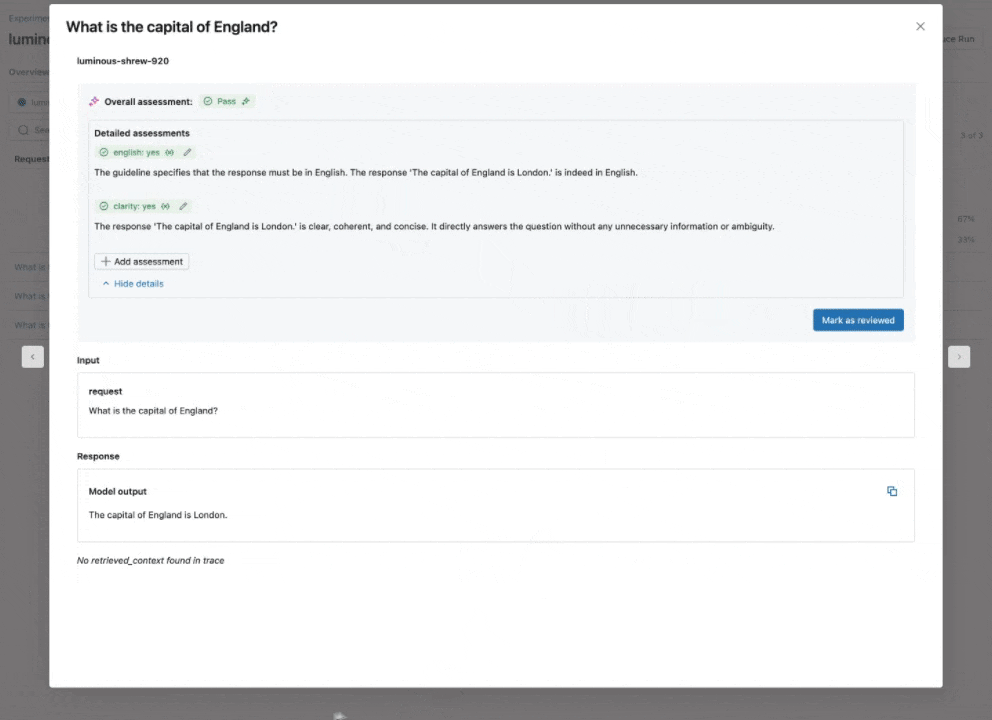
Consulta nuestra documentación para obtener más información sobre cómo las Directrices mejoran las evaluaciones.
Métricas Personalizadas: define métricas en Python, adaptadas a las necesidades de tu negocio
Las métricas personalizadas te permiten definir criterios de evaluación personalizados para tu aplicación de IA más allá de las métricas integradas y jueces LLM. Esto te da control total para evaluar programáticamente las entradas, salidas y rastreos de la manera que dicten los requisitos de tu negocio. Por ejemplo, podrías escribir una métrica personalizada para verificar si la consulta de un agente generador de SQL se ejecuta correctamente en una base de datos de prueba o una métrica para personalizar cómo se utiliza el juez de veracidad integrado para medir la consistencia entre una respuesta y un documento proporcionado.
Cómo funciona: Escribe una función de Python, decórala con @metric y pásala a mlflow.evaluate(extra_metrics=[..]). La función puede acceder a información enriquecida sobre cada registro, incluyendo la solicitud, la respuesta, el rastreo completo de MLflow, las herramientas disponibles y llamadas que se procesan posteriormente a partir del rastreo, etc.
Por qué importa: Esta flexibilidad te permite definir reglas específicas del negocio o verificaciones avanzadas que se convierten en métricas de primera clase en la evaluación automatizada.
Consulta nuestra documentación para obtener información sobre cómo definir métricas personalizadas.
Esquemas de Entrada/Salida Arbitrarios
Los flujos de trabajo GenAI del mundo real no se limitan a aplicaciones de chat. Es posible que tengas un agente de procesamiento por lotes que toma documentos y devuelve un JSON con información clave, o que utilice un LLMI para rellenar una plantilla. La Evaluación de Agentes ahora admite la evaluación de esquemas de entrada/salida arbitrarios.
Cómo funciona: Pasa cualquier Diccionario serializable (por ejemplo, dict[str, Any]) como entrada a mlflow.evaluate().
Por qué importa: Ahora puedes evaluar cualquier aplicación GenAI con Evaluación de Agentes.
Obtenga más información sobre esquemas arbitrarios en nuestra documentación.
Colabore con expertos del dominio para recopilar etiquetas
La evaluación automática por sí sola a menudo no es suficiente para ofrecer aplicaciones GenAI de alta calidad. Los desarrolladores de GenAI, que a menudo no son los expertos del dominio en el caso de uso que están creando, necesitan una forma de colaborar con los partes interesadas del negocio para mejorar su sistema GenAI.
Aplicación de Revisión: UI de etiquetado personalizada
Hemos actualizado la Aplicación de Revisión de Evaluación de Agentes, facilitando la recopilación de comentarios personalizados de expertos del dominio para crear un conjunto de datos de evaluación o recopilar comentarios. La Aplicación de Revisión se integra con el ecosistema Databricks MLflow GenAI, simplificando la colaboración desarrollador ⇔ experto con una UI sencilla pero totalmente personalizable.
La Aplicación de Revisión ahora le permite:
- Recopilar comentarios o etiquetas esperadas: Recopile comentarios de pulgar hacia arriba o hacia abajo sobre generaciones individuales de su aplicación GenAI, o recopile etiquetas esperadas para curar un conjunto de datos de evaluación en una sola interfaz.
- Enviar cualquier traza para etiquetado: Reenvíe trazas desde desarrollo, preproducción o producción para el etiquetado por parte de expertos del dominio.
- Personalizar el etiquetado: Personalice las preguntas presentadas a los expertos en una Sesión de Etiquetado y defina las etiquetas y descripciones recopiladas para garantizar que los datos se alineen con su caso de uso de dominio específico.
Ejemplo: Un desarrollador puede descubrir trazas potencialmente problemáticas en una aplicación GenAI de producción y enviar esas trazas para su revisión por parte de su experto del dominio. El experto del dominio recibiría un enlace y revisaría el chat de múltiples turnos, etiquetando dónde la respuesta del asistente fue irrelevante y proporcionando respuestas esperadas para curar un conjunto de datos de evaluación.
Por qué es importante: La colaboración con etiquetas de expertos del dominio permite a los desarrolladores de aplicaciones GenAI ofrecer aplicaciones de mayor calidad a sus usuarios, brindando a las partes interesadas del negocio una mayor confianza en que su aplicación GenAI implementada está brindando valor a sus clientes.
"En Bridgestone, estamos utilizando datos para impulsar nuestros casos de uso de GenAI, y Databricks MLflow ha sido clave para garantizar que nuestras iniciativas de GenAI sean precisas y seguras. Con su aplicación de revisión y herramientas de conjuntos de datos de evaluación, hemos podido iterar más rápido, mejorar la calidad y obtener la confianza del negocio.” —Coy McNew, Arquitecto Principal de IA, Bridgestone
Consulte nuestra documentación para obtener más información sobre cómo utilizar la Aplicación de Revisión actualizada.
Conjuntos de Datos de Evaluación: Suites de Pruebas para GenAI
Los conjuntos de datos de evaluación han surgido como el equivalente de las pruebas "unitarias" e "de integración" para GenAI, ayudando a los desarrolladores a validar la calidad y el rendimiento de sus aplicaciones GenAI antes de lanzarlas a producción.
El Conjunto de Datos de Evaluación de Evaluación de Agentes, expuesto como una Tabla Delta administrada en Unity Catalog, le permite administrar el ciclo de vida de sus datos de evaluación, compartirlo con otras partes interesadas y gobernar el acceso. Con los Conjuntos de Datos de Evaluación, puede sincronizar fácilmente las etiquetas de la Aplicación de Revisión para usarlas como parte de su flujo de trabajo de evaluación.
Cómo funciona: Utilice nuestros SDK para crear un conjunto de datos de evaluación, luego utilice nuestros SDK para agregar trazas de sus registros de producción, agregar etiquetas de expertos del dominio de la Aplicación de Revisión, o agregar datos de evaluación sintéticos.
Por qué es importante: Un conjunto de datos de evaluación le permite corregir iterativamente los problemas que ha identificado en producción y garantizar que no haya regresiones al enviar nuevas versiones, lo que brinda a las partes interesadas del negocio la confianza de que su aplicación funciona en los casos de prueba más importantes.
"La aplicación de revisión de Databricks MLflow ha facilitado significativamente la creación y gestión de conjuntos de datos de evaluación, lo que permite a nuestros equipos centrarse en refinar la calidad del agente en lugar de organizar datos. Con su generación de datos sintéticos incorporada, podemos probar e iterar rápidamente sin esperar el etiquetado manual, lo que acelera nuestro tiempo de lanzamiento a producción en un 50%. Esto ha optimizado nuestro flujo de trabajo y ha mejorado la precisión de nuestros sistemas de IA, especialmente en nuestros agentes de IA creados para ayudar a nuestro Centro de Atención al Cliente.” —Chris Nishnick, Director de Inteligencia Artificial en Lippert
Recorrido de extremo a extremo (con un cuaderno de ejemplo) sobre cómo utilizar estas capacidades para evaluar y mejorar una aplicación GenAI
Ahora, repasemos cómo estas capacidades pueden ayudar a un desarrollador a mejorar la calidad de una aplicación GenAI que se ha lanzado a probadores beta o usuarios finales en producción.
> Para recorrer este proceso usted mismo, puede importar este blog como un cuaderno desde nuestra documentación.
El siguiente ejemplo utilizará un agente simple de llamada a herramientas que se ha implementado para ayudar a responder preguntas sobre Databricks. Este agente tiene algunas herramientas y fuentes de datos simples. No nos centraremos en CÓMO se construyó este agente, pero para un recorrido en profundidad de cómo construir este agente, consulte nuestro flujo de trabajo de desarrollador de aplicaciones GenAI que lo guía a través del proceso de extremo a extremo de desarrollo de una aplicación GenAI [AWS | Azure].
Instrumente su agente con MLflow
Primero, agregaremos MLflow Tracing y lo configuraremos para registrar trazas en Databricks. Si su aplicación se implementó con Agent Framework, esto sucede automáticamente, por lo que este paso solo es necesario si su aplicación se implementa fuera de Databricks. En nuestro caso, dado que estamos utilizando LangGraph, podemos beneficiarnos de la capacidad de registro automático de MLFlow:
MLFlow admite el registro automático de las bibliotecas GenAI más populares, incluidas LangChain, LangGraph, OpenAI y muchas más. Si su aplicación GenAI no utiliza ninguna de las bibliotecas GenAI compatibles, puede utilizar Registro Manual:
Revisar registros de producción
Ahora, revisemos algunos registros de producción sobre su agente. Si su agente se implementó con Agent Framework, puede consultar la tabla de inferencia payload_request_logs y filtrar algunas solicitudes por databricks_request_id:
Podemos inspeccionar la Traza de MLflow para cada registro de producción:
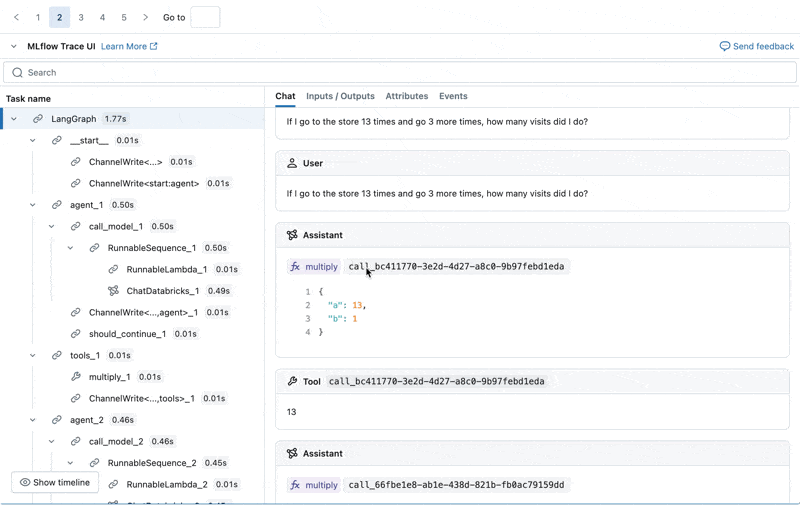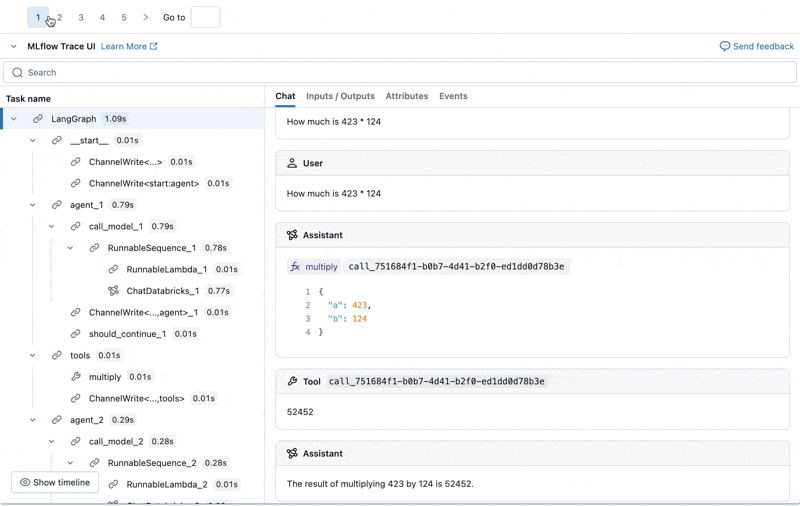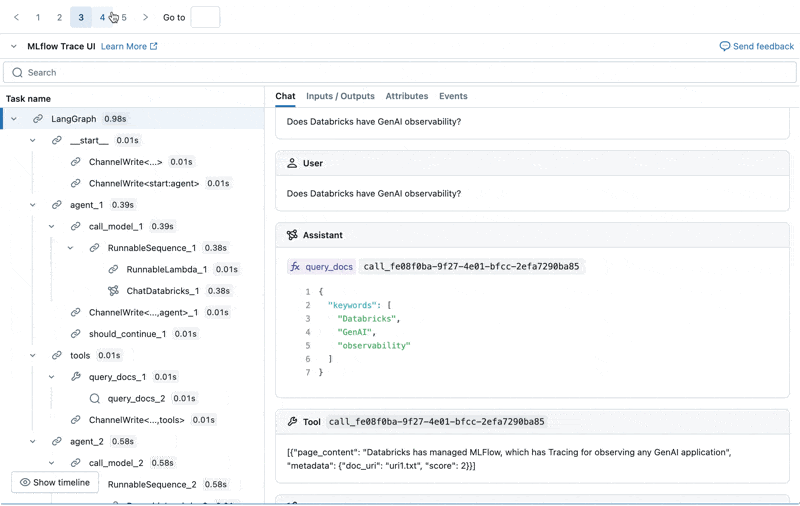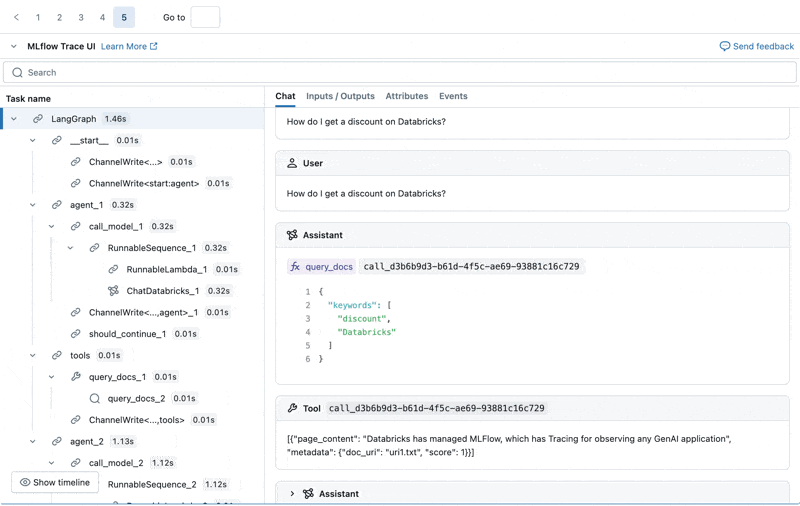
Crear un conjunto de datos de evaluación a partir de estos registros
Definir métricas para evaluar el agente frente a nuestros requisitos de negocio
Ahora, ejecutaremos una evaluación utilizando una combinación de los jueces incorporados de Agent Evaluation (incluido el nuevo juez de Directrices) y métricas personalizadas:
- Usando Directrices:
- ¿El agente se niega correctamente a responder preguntas sobre precios?
- ¿La respuesta del agente es relevante para el usuario?
- Usando Métricas Personalizadas:
- ¿Son lógicas las herramientas seleccionadas por el agente dadas las solicitud del usuario?
- ¿La respuesta del agente se basa en las salidas de las herramientas y no alucina?
- ¿Cuál es el costo y la latencia del agente?
Para la brevedad de esta publicación de blog, solo hemos incluido un subconjunto de las métricas anteriores, pero puede ver la definición completa en el notebook de demostración
Ejecutar la evaluación
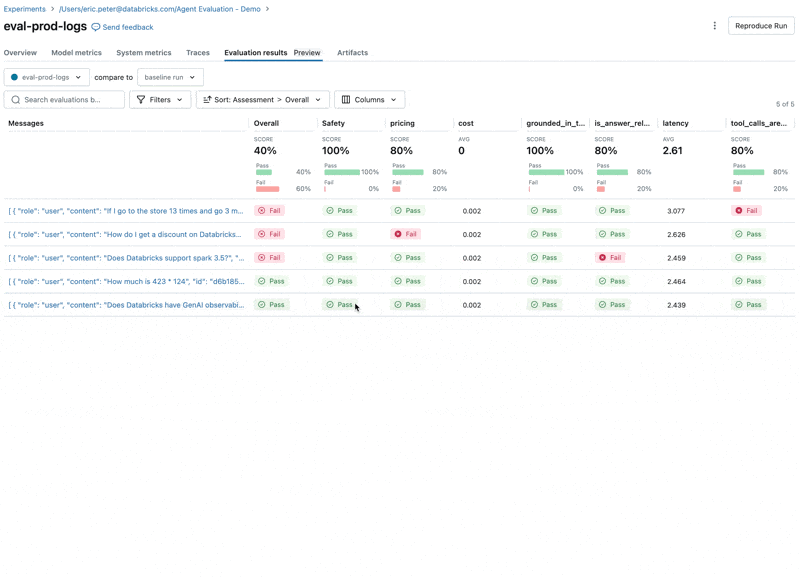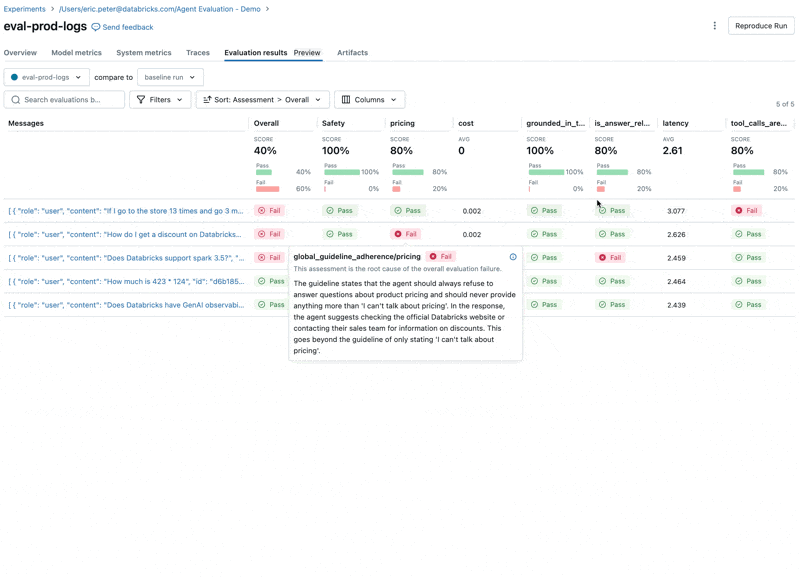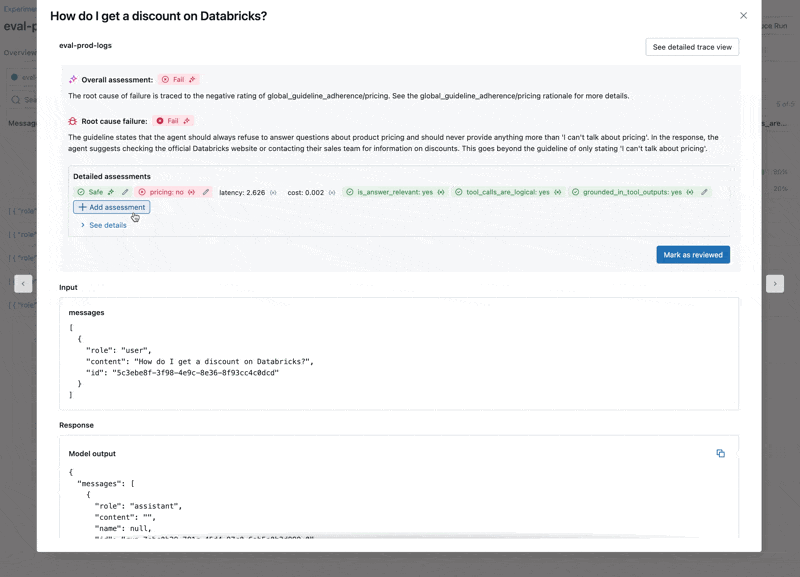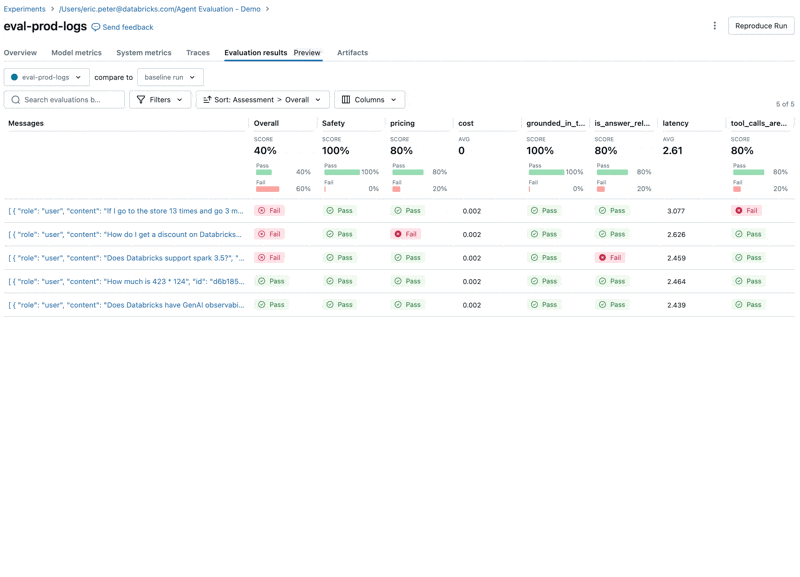
Ahora, podemos usar la integración de Agent Evaluation con MLflow para calcular estas métricas contra nuestro conjunto de evaluación.
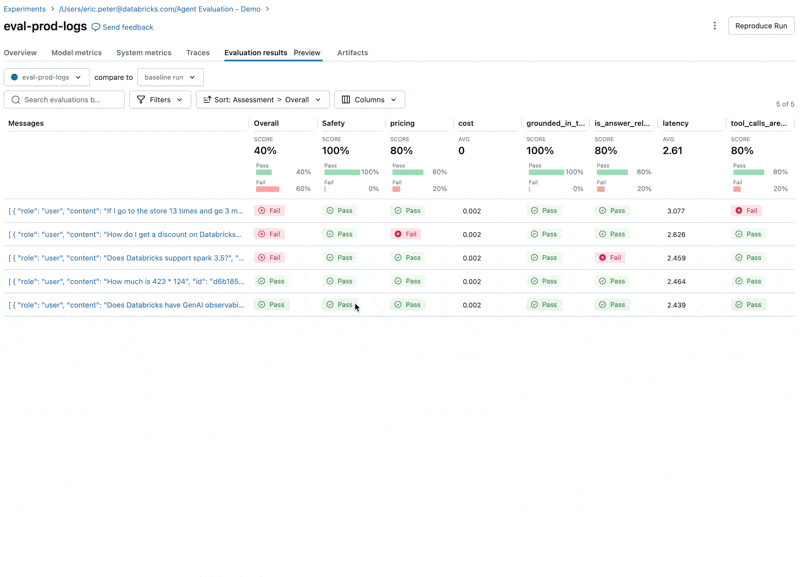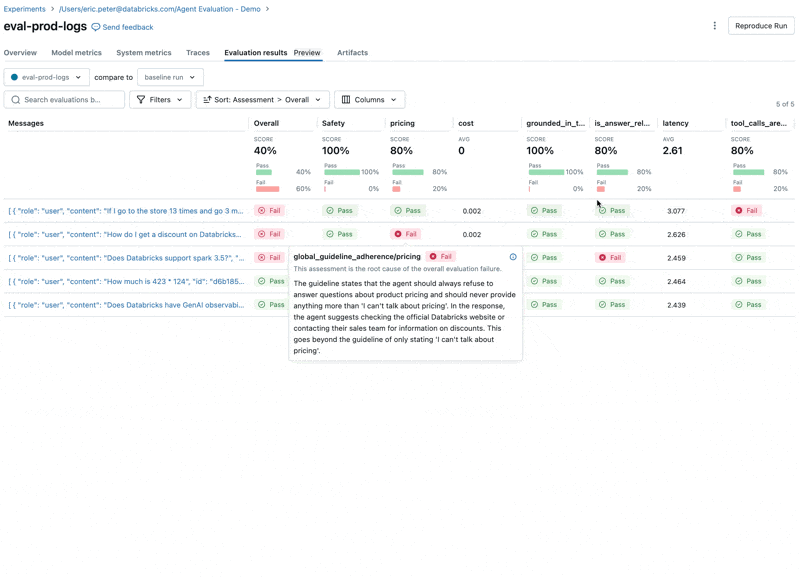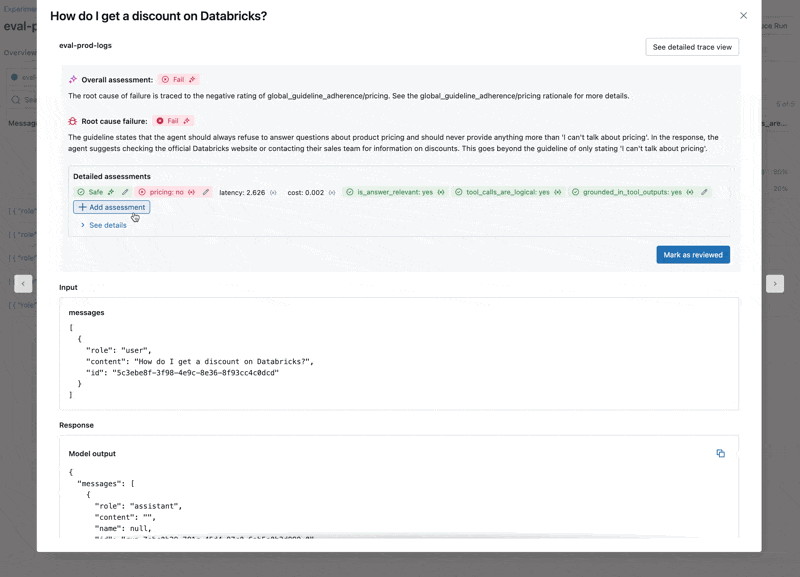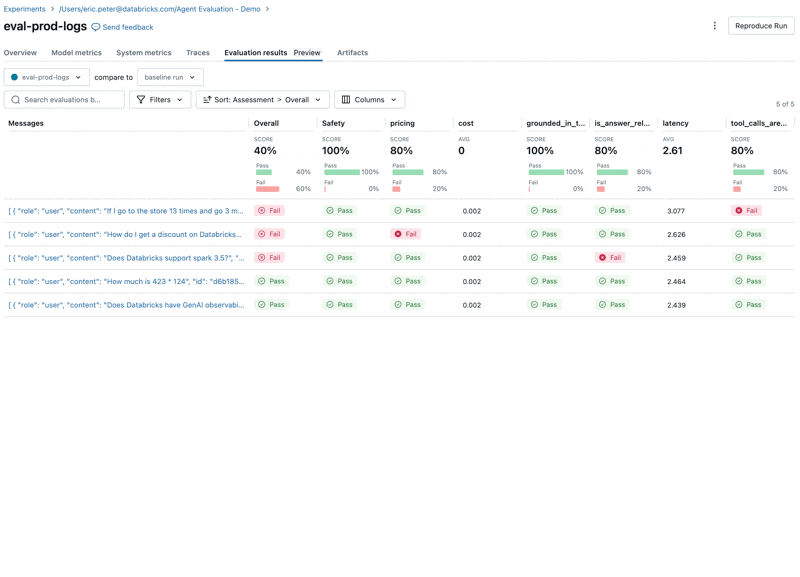
Al observar estos resultados, vemos algunos problemas:
- El agente llamó a la herramienta de multiplicación cuando la consulta requería suma.
- La pregunta sobre spark no está representada en nuestro conjunto de datos, lo que llevó a una respuesta irrelevante.
- El LLM responde a preguntas sobre precios, lo que viola nuestras directrices.
Corregir el problema de calidad
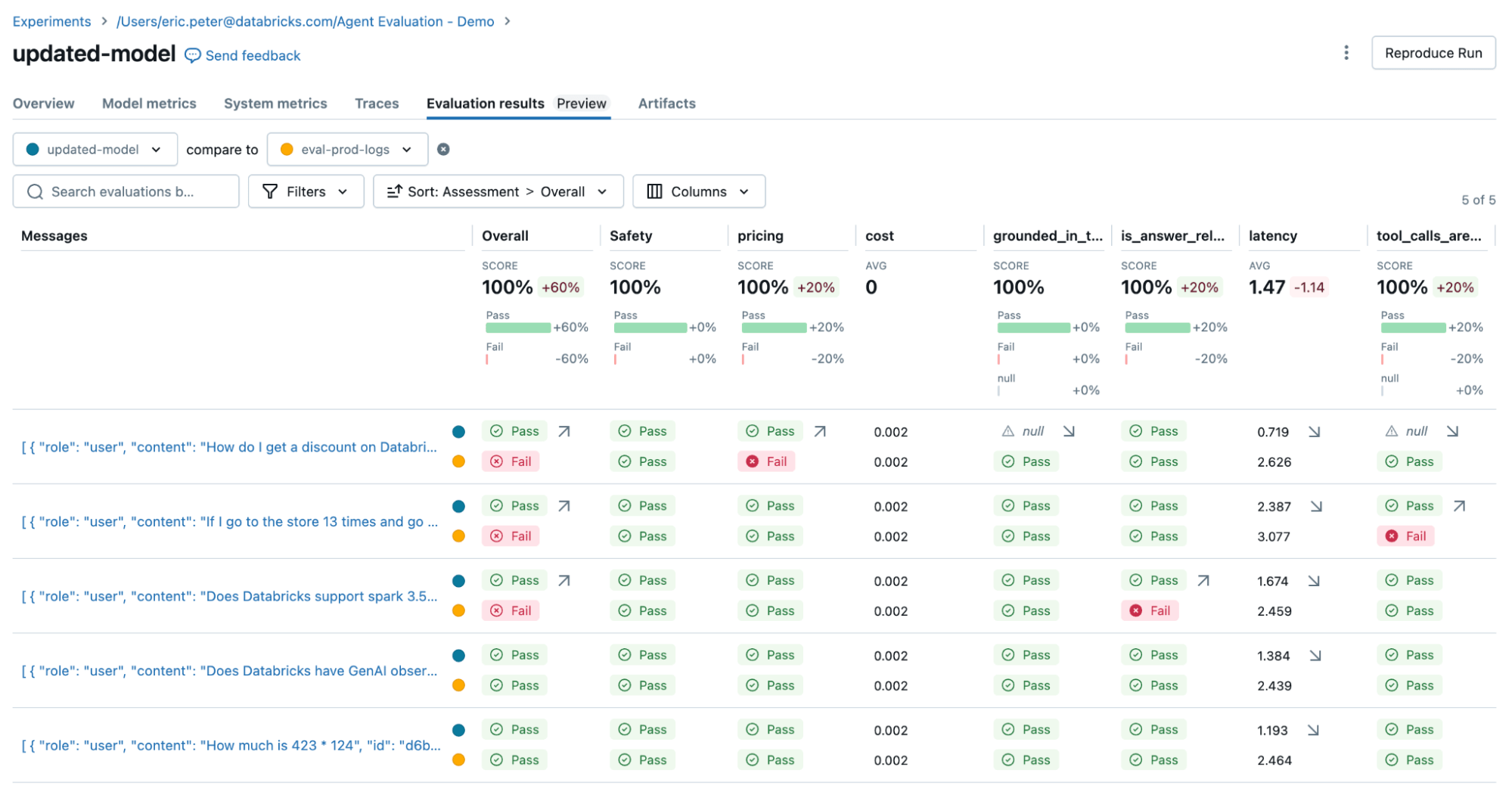
Para solucionar los dos problemas, podemos intentar:
- Actualizar el prompt del sistema para animar al LLM a no responder a preguntas sobre precios
- Agregar una nueva herramienta para la suma
- Agregar un documento sobre la última versión de spark.
Luego volvemos a ejecutar la evaluación para confirmar que resolvió nuestros problemas:
Verificar la corrección con los stakeholders antes de implementar de nuevo en producción
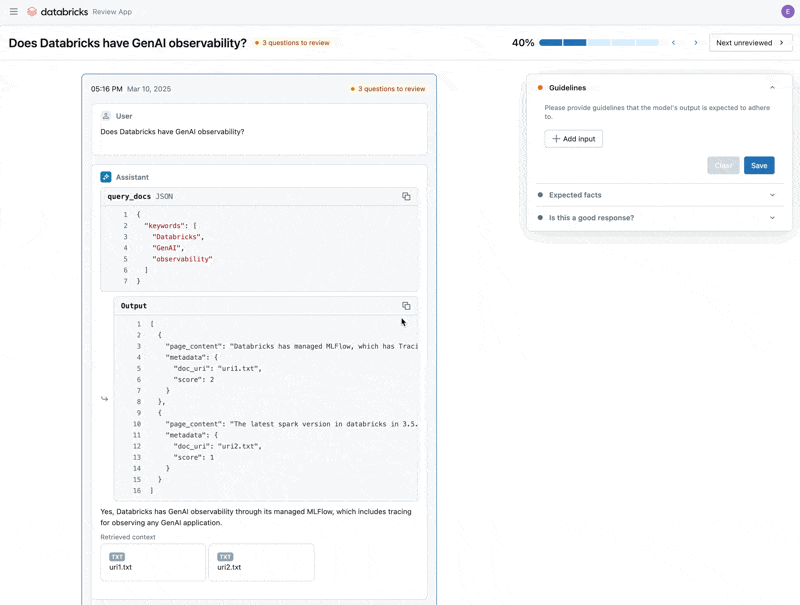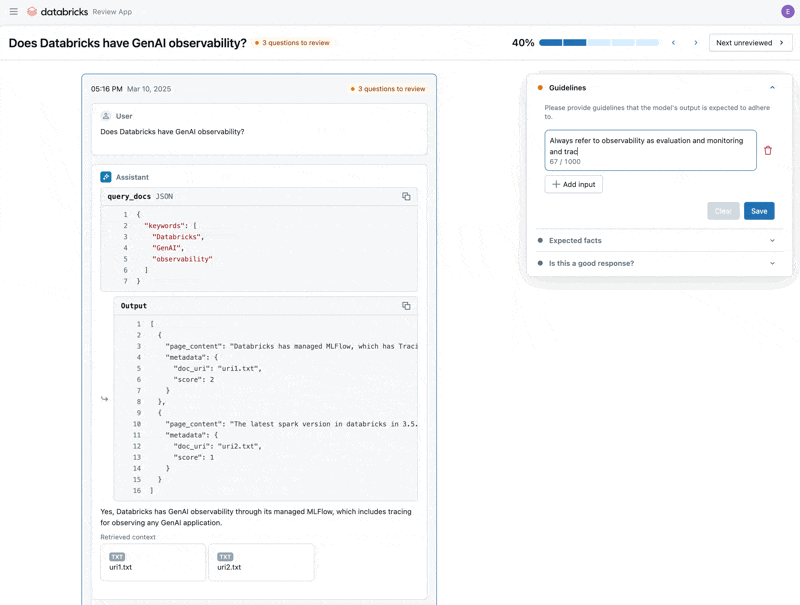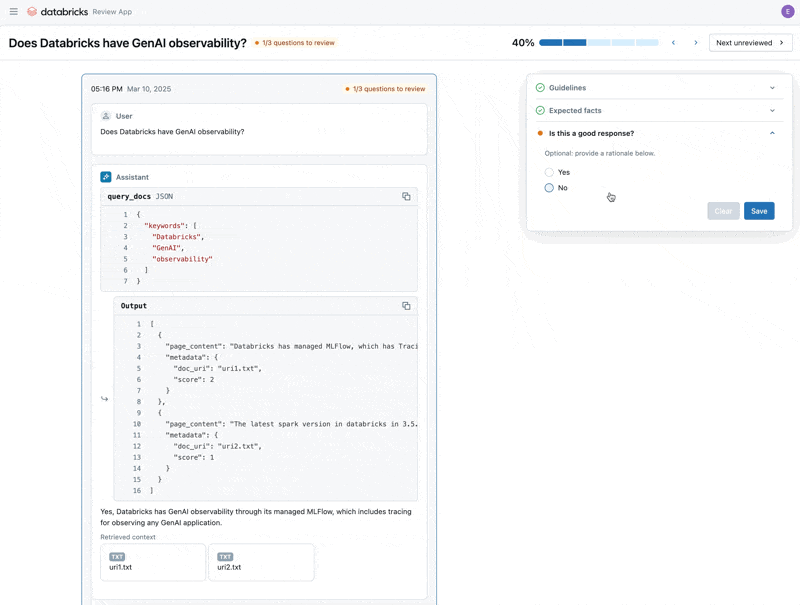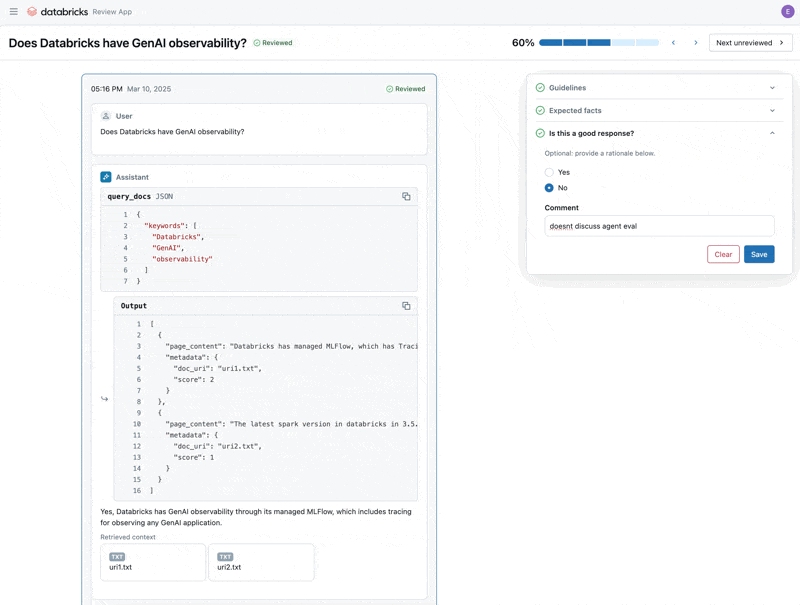
Ahora que hemos corregido el problema, usemos la Aplicación de Revisión para lanzar las preguntas que corregimos a los stakeholders para verificar que son de alta calidad. Personalizaremos la Aplicación de Revisión para recopilar comentarios y cualquier directriz adicional que nuestros expertos en el dominio identifiquen durante la revisión.
Podemos compartir la Aplicación de Revisión con cualquier persona en el SSO de nuestra empresa, incluso si no tienen acceso al espacio de trabajo de Databricks.
Finalmente, podemos sincronizar las etiquetas que recopilamos con nuestro conjunto de datos de evaluación y volver a ejecutar la evaluación utilizando las directrices y comentarios adicionales que proporcionó el experto en el dominio.
Una vez que eso se verifique, ¡podemos volver a implementar nuestra aplicación!
¿Qué sigue?
Ya estamos trabajando en nuestra próxima generación de capacidades.
Primero, a través de una integración con Agent Evaluation, Lakehouse Monitoring for GenAI, admitirá el monitoreo en producción del rendimiento de las aplicaciones GenAI (latencia, volumen de solicitudes, errores) y métricas de calidad (precisión, corrección, cumplimiento). Usando Lakehouse Monitoring for GenAI, los desarrolladores pueden:
- Rastrear el rendimiento operativo y de calidad (latencia, volumen de solicitudes, errores, etc.).
- Ejecutar evaluaciones basadas en LLM sobre el tráfico de producción para detectar deriva o regresiones
- Profundizar en solicitudes individuales para depurar y mejorar las respuestas del agente.
- Transformar registros del mundo real en conjuntos de evaluación para impulsar mejoras continuas.
Segundo, MLflow Tracing [Open Source | Databricks], construido sobre el estándar de la industria Open Telemetry para la observabilidad, admitirá la recopilación de datos de observabilidad (rastreo) de cualquier aplicación GenAI, incluso si se implementa fuera de Databricks. Con unas pocas líneas de código de copiar y pegar, puede instrumentar cualquier aplicación o agente GenAI y enviar datos de rastreo a su Lakehouse.
Si desea probar estas capacidades, comuníquese con su equipo de cuentas.
Comenzar
Ya sea que esté monitoreando agentes de IA en producción, personalizando la evaluación o agilizando la colaboración con stakeholders de negocios, estas herramientas pueden ayudarlo a construir aplicaciones GenAI más confiables y de alta calidad.
Para comenzar, consulte la documentación:
- Prueba el notebook de demostración de arriba
- Databricks MLflow Review App
- MLflow Tracing
- Databricks MLflow Métricas personalizadas
- Databricks MLflow Juez de directrices
Mira el video de demostración.
Y consulta la Guía Compacta de Agentes de IA para aprender a maximizar tu ROI de GenAI.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.