Presentamos Spatial SQL en Databricks: más de 80 funciones para análisis geoespaciales de alto rendimiento
El mejor "almacén" de datos es un lakehouse
por Kent Marten y Michael Johns
- Acelera tus consultas geoespaciales a escala con más de 80 funciones de SQL Espacial, ahora disponibles en vista previa pública.
- Almacena sin problemas datos planares y geodésicos utilizando los tipos de datos nativos GEOMETRY y GEOGRAPHY.
- Mejora tu análisis espacial con uniones espaciales de alto rendimiento y olvídate de la indexación manual.
Cada día, miles de millones de puntos de datos están vinculados a lugares en el mapa. Rutas de entrega, visitas a tiendas, redes de carreteras, torres de telefonía móvil y campos de cultivo, todos aportan un contexto importante para la toma de decisiones empresariales. El problema es que analizar estos datos a escala ha sido difícil. Los sistemas espaciales heredados son lentos, requieren indexación manual y a menudo bloquean la información en formatos propietarios.
Hoy presentamos Spatial SQL en Databricks. Spatial SQL lleva el análisis geoespacial directamente a la Plataforma Databricks. Ahora puede trabajar con tipos de datos nativos GEOMETRY y GEOGRAPHY, utilizar más de 80 funciones SQL y ejecutar uniones espaciales a alta velocidad y rendimiento, todo ello manteniendo sus datos abiertos y listos para escalar.
Los datos de ubicación juegan un papel en casi todas las industrias, y Spatial SQL facilita el uso de esa información.
Aquí hay algunos ejemplos:
- Las operaciones minoristas pueden comprender de dónde provienen sus clientes analizando áreas y tráfico peatonal
- Los analistas de transporte pueden mejorar la seguridad y la experiencia del cliente analizando incidentes de vehículos y la conectividad de la red celular
- Las empresas de energía pueden optimizar el despliegue de equipos durante cortes de suministro y encontrar ubicaciones ideales para ubicar parques de energía eólica y solar
- Los operadores agrícolas pueden aplicar técnicas de agricultura de precisión para reducir costos y mejorar la eficiencia del rendimiento
- Los analistas de seguros pueden comprender el riesgo analizando las direcciones de los asegurados en zonas de inundación, incendios y huracanes
- Las organizaciones de atención médica pueden comparar y predecir resultados de salud analizando factores ambientales en geografías
- ¡Y mucho más!
Spatial SQL ya está ayudando a los clientes a acelerar el rendimiento y reducir los costos:
“Databricks Spatial SQL ha redefinido cómo ejecutamos uniones espaciales a gran escala. Al integrar las funciones de Spatial SQL en nuestros pipelines de procesamiento, hemos visto un rendimiento más de 20 veces más rápido y costos más de un 50% más bajos en las mismas cargas de trabajo. Este avance hace posible integrar y entregar datos de redes de carreteras enriquecidas a una escala y velocidad que simplemente no eran factibles antes.”
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
Los clientes han tenido dificultades previamente para gestionar y escalar cargas de trabajo espaciales con sistemas heredados, bibliotecas de terceros o recurriendo a estrategias de indexación manual. Con Spatial SQL, los clientes obtienen simplicidad y escalabilidad listas para usar.
“Spatial SQL nos permite escalar ETL geoespacial como nunca antes. En lugar de sobrecargar los servidores PostGIS con consultas pesadas, transferimos la carga a Databricks y aprovechamos el procesamiento distribuido, las uniones espaciales rápidas y el manejo eficiente de datos vectoriales. Es un enfoque más eficiente, resiliente y escalable para manejar conjuntos de datos geoespaciales grandes y complejos.”
— Pierre Chenaux, Tech Leader of Geospatial department, TotalEnergies
Un importante impulsor del rendimiento es el soporte para tipos de datos geoespaciales de primera clase. En lugar de almacenar datos geográficos en columnas de texto, binarias o decimales, ahora puede usar tipos de datos nativos GEOMETRY y GEOGRAPHY. Estos tipos incluyen estadísticas de bounding box que Databricks utiliza durante la ejecución de consultas para omitir datos irrelevantes y acelerar las uniones. Spatial SQL también proporciona funciones de importación para formatos estándar como Well Known Text, Well Known Binary, GeoJSON y valores simples de latitud o longitud.
Estos tipos de datos son completamente abiertos en Parquet, Iceberg y Delta. El equipo de Databricks ha contribuido a dar forma a las especificaciones propuestas, asegurando que no haya dependencia de almacenes de datos propietarios. Con el SPIP de Apache Spark™ aprobado, GEOMETRY y GEOGRAPHY pronto serán tipos de datos de primera clase en el motor de código abierto.
¿Qué puede hacer con Spatial SQL?
Spatial SQL es más que un conjunto de nuevas funciones. Le proporciona los componentes básicos para gestionar todo el ciclo de vida de los datos espaciales, desde el almacenamiento y la importación hasta el análisis y la transformación. Al trabajar con tipos de datos nativos y operaciones eficientes, puede incorporar la ubicación en las consultas diarias sin añadir complejidad.
Estas son algunas de las cosas principales que puede hacer:
- Almacenar datos espaciales de forma nativa con GEOMETRY y GEOGRAPHY
- Importar y exportar en formatos como WKT, WKB, GeoJSON y GeoHash
- Crear nuevos objetos con constructores como ST_Point o ST_MakeLine
- Calcular mediciones utilizando funciones como ST_Distance y ST_AREA
- Realizar uniones espaciales utilizando relaciones como ST_Contains y ST_Intersects
- Transformar entre sistemas de coordenadas con ST_Transform
- Editar, validar y combinar objetos espaciales utilizando ST_ISVALID o ST_UNION_AGG
- ¡Y mucho más!
Estas características le proporcionan un conjunto completo de herramientas para el análisis espacial directamente en SQL, también disponible con APIs de Python y Scala. Cuando las combina, desbloquean flujos de trabajo reales que importan en la práctica, que repasaremos en la siguiente sección.
Ejemplos de Spatial SQL en la práctica
Los datos geoespaciales están en todas partes y creciendo. Las trazas GPS con latitudes y longitudes se emiten desde un número creciente de dispositivos, sensores y vehículos cada segundo del día. El mundo se está catalogando y actualizando constantemente, con lugares, carreteras, redes y límites modelados como puntos, líneas y polígonos. En todas las industrias (minorista, transporte y logística, energía, clima y ciencias naturales, agricultura, sector público, servicios financieros, bienes raíces, seguros, telecomunicaciones), la ubicación es importante para cada decisor que necesita comprender el “dónde” en sus datos.
Hemos elaborado cuatro ejemplos breves para empezar a trabajar con los nuevos tipos de datos y expresiones espaciales con los siguientes objetivos.
- Preparar datos para un procesamiento eficiente utilizando el nuevo tipo GEOMETRY
- Realizar enriquecimiento de datos combinando dos conjuntos de datos espaciales mediante una unión espacial
- Transformar datos a un sistema de referencia espacial apropiado para mejorar la precisión de las mediciones de distancia
- Medir la distancia entre dos ciudades
En estos ejemplos, utilizaremos conjuntos de datos de direcciones, edificios y divisiones de OvertureMaps.org. Estos conjuntos de datos se ofrecen para descargar de diversas maneras, como GeoParquet.
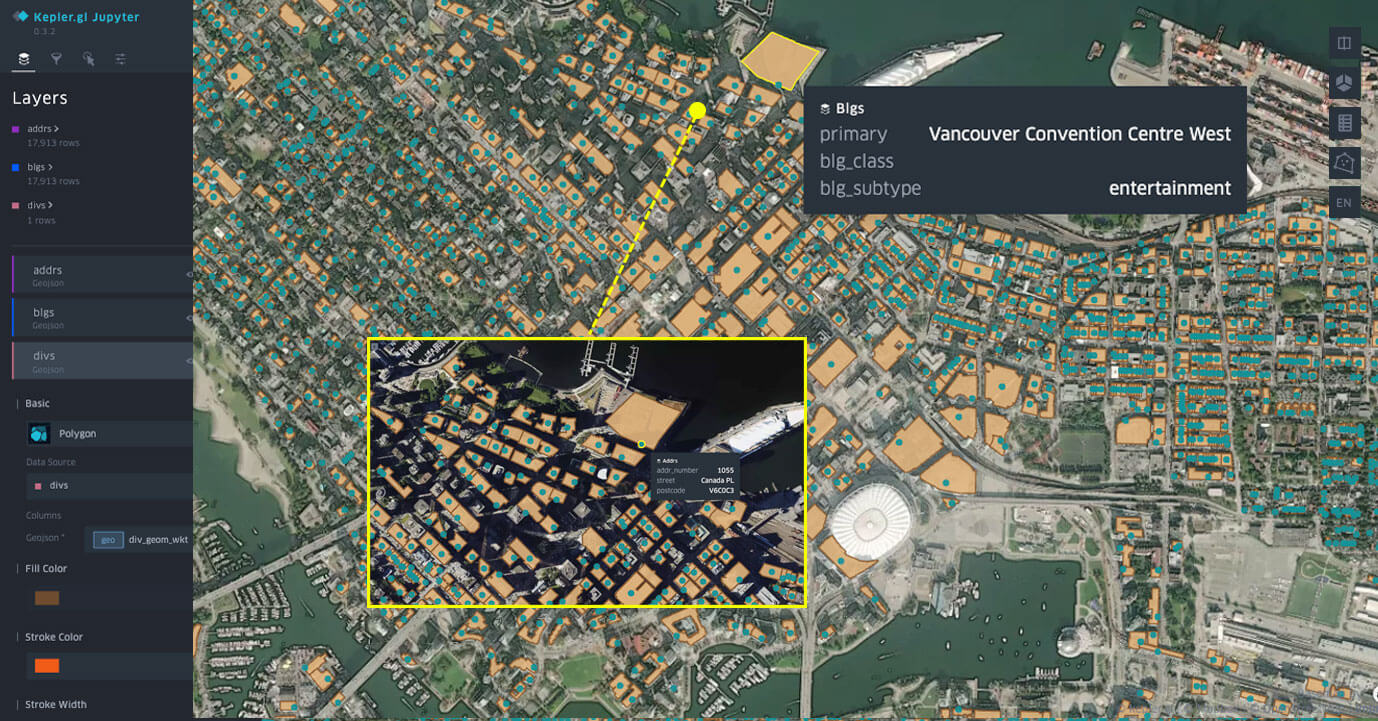
Conjuntos de datos de Overture Maps visualizados en Databricks Notebook con kepler.gl.
1. Creación de una columna GEOMETRY
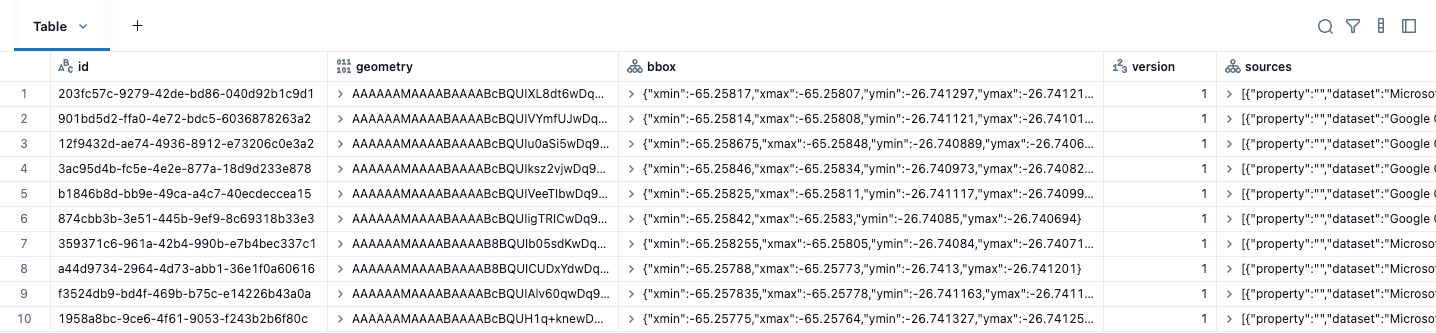
El primer paso antes de realizar cualquier análisis espacial es convertir sus datos para que utilicen los tipos de datos GEOMETRY o GEOGRAPHY. Después de descargar los datos de Overture Maps, simplemente necesitamos crear una columna GEOMETRY nativa a partir de la columna de geometría WKB proporcionada y eliminar otras columnas innecesarias como bbox. Un bounding box es el rectángulo más pequeño que contiene una geometría. En las consultas espaciales, los bounding boxes aceleran las consultas al descartar rápidamente los datos que no pueden superponerse. Si dos bounding boxes no se intersectan, las geometrías dentro de ellos definitivamente no lo hacen, por lo que la base de datos puede omitir la costosa comprobación de intersección y reducir la cantidad de datos que se procesan. No necesitamos el campo bbox porque esta información ahora se gestiona en las estadísticas de la columna. Para estos conjuntos de datos, las direcciones son PUNTOS, mientras que los edificios y las divisiones son POLÍGONOS / MULTIPOLÍGONOS. Aquí están los datos de edificios descargados inicialmente, mostrando las primeras cinco columnas.
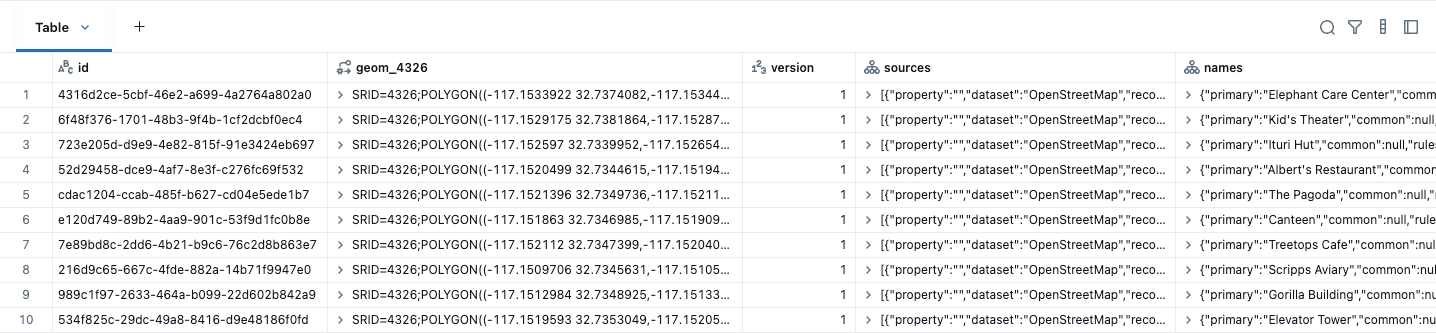
Estos datos se pueden convertir fácilmente en una tabla Lakehouse con GEOMETRY nativa usando ST_GeomFromWKB, como se muestra en el ejemplo a continuación para edificios. Sabemos que nuestros datos están en WGS84 (EPSG:4326), por lo que lo especificamos en la creación del tipo espacial. Un SRID identifica el sistema de coordenadas de sus datos espaciales, que define las unidades (como grados o metros) utilizadas en cálculos como distancia y área. Debe establecer un SRID válido al crear una columna de geometría, o la consulta devolverá un error. Además, tenga en cuenta que nuestros tipos nativos se muestran en un formato fácil de usar (EWKT).
Además de WKB, los datos espaciales también se pueden importar directamente a nuestros tipos nativos desde los formatos de intercambio más comunes:
- Coordenadas de latitud y longitud usando ST_POINT
- WKT usando ST_GeomFromWKT o ST_GeomFromText
- WKB usando ST_GeomFromWKB o ST_GeomFromBinary
- GeoJSON usando ST_GeomFromGeoJSON
- GeoHash usando ST_PointFromGeoHash
De manera similar, los datos espaciales se pueden exportar como varios formatos:
- WKT usando ST_AsWKT o ST_AsText
- WKB usando ST_AsWKB o ST_AsBinary
- GeoJSON usando ST_AsGeoJSON
- WKT extendido usando ST_AsEWKT
- WKB extendido usando ST_AsEWKB
- GeoHash usando ST_GeoHash
Nota: También tenemos expresiones de importación y exportación para tipos GEOGRAPHY.
2. Unión espacial de múltiples conjuntos de datos
Las uniones espaciales se encuentran entre las operaciones más importantes y utilizadas en el procesamiento de datos geoespaciales. Permiten combinar atributos de diferentes conjuntos de datos y realizar agregaciones o enriquecimiento de datos basándose en sus relaciones espaciales, como contención, intersección y proximidad. Esto hace que las uniones espaciales sean esenciales para responder preguntas del mundo real como identificar qué edificios caen dentro de una zona de inundación, asignar datos demográficos de censo a direcciones de clientes y analizar vehículos conectados dentro de áreas de cobertura celular. Dado que gran parte del análisis geoespacial depende de la integración de múltiples conjuntos de datos, las uniones espaciales suelen ser un primer paso en el análisis espacial exploratorio, la modelización espacial y la toma de decisiones basada en la ubicación.
A continuación, uniremos las tablas de direcciones y divisiones utilizando una unión espacial. Cualquiera que haya trabajado con fuentes de datos de direcciones sabe que las direcciones pueden ser datos desordenados (una causa común es que diferentes países usan diferentes sistemas de direccionamiento). Además, la tabla de direcciones no incluye una jerarquía administrativa completa (es decir, no hay información de condado para direcciones de EE. UU.). Por lo tanto, utilizaremos la tabla de divisiones para validar la información de la ciudad y enriquecerla agregando información equivalente al condado.
Este proceso de validación y enriquecimiento de datos sería diferente de resolver sin una unión espacial. Para ello, necesitamos encontrar la dirección dentro de la división. Utilizaremos ST_Contains para realizar una unión espacial de punto en polígono, permitiendo que Databricks maneje los detalles internos de la operación, sin necesidad de indexación espacial DIY.
Ahora podemos estandarizar más fácilmente a la ciudad, estado, condado y país correctos, por ejemplo, reemplazar las ciudades faltantes en las direcciones con las proporcionadas en la tabla de divisiones.
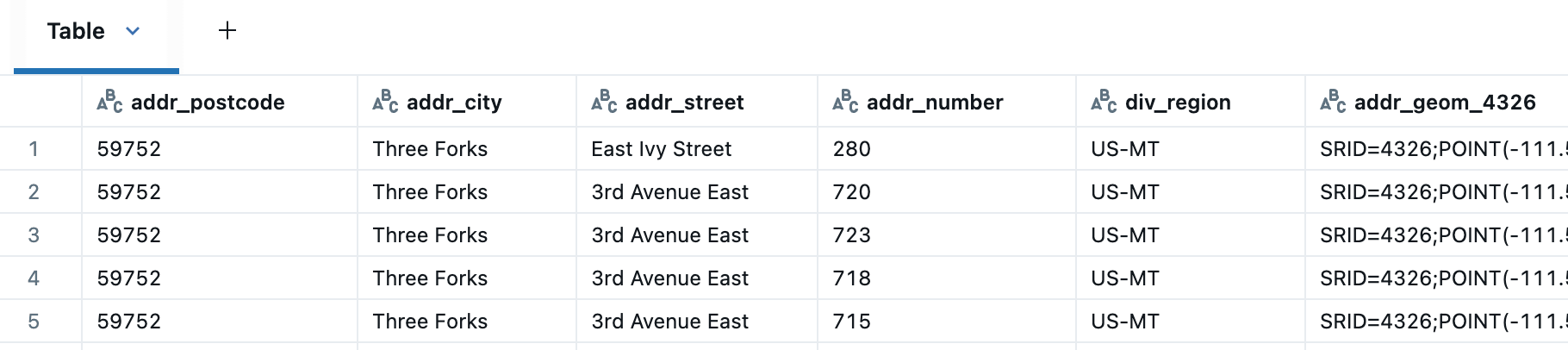
Después de validar las direcciones, seguimos un enfoque similar para unir las direcciones con los edificios usando ST_Intersects para enriquecer la tabla Buildings con información de direcciones. Para EE. UU., esta unión espacial emparejó 44 millones de direcciones con edificios, quedando 55 millones de edificios sin emparejar. En el siguiente ejemplo, veamos cómo podemos usar la proximidad para identificar potencialmente edificios que no se emparejaron con una dirección.
3. Transformación de datos a sistemas de referencia espacial específicos
Los conjuntos de datos geoespaciales a menudo se crean en diferentes sistemas de referencia de coordenadas (CRS), como latitud-longitud (WGS84) o sistemas proyectados como UTM, dependiendo de su origen y propósito. Si bien cada CRS define cómo se representa la superficie curva de la Tierra en un mapa plano, el uso de conjuntos de datos con proyecciones desajustadas puede hacer que las características se desalineen, distorsionen las distancias o produzcan uniones y mediciones espaciales incorrectas. Una tienda ubicada en una zona de inundación no coincidirá en una unión espacial si se utilizan sistemas de coordenadas diferentes. Para un análisis preciso, ya sea calculando áreas, uniendo capas o visualizando relaciones espaciales, es esencial asegurarse de que todos los conjuntos de datos se transformen a la misma proyección para que compartan una referencia espacial coherente.
Para identificar direcciones dentro de la proximidad de los 55 millones de edificios no emparejados restantes en EE. UU., proyectemos nuestros datos GEOMETRY WGS84 a Conus Albers (EPSG:5070) para América del Norte, lo que nos da unidades en metros. Esto se logra con la función ST_Transform.
Apliquemos ST_DWithin entre nuestros edificios y direcciones no emparejados de EE. UU., utilizando un valor de distancia dentro de solo 2 metros.
El valor de distancia dentro se puede aumentar según sea necesario para recopilar un conjunto de posibles coincidencias de direcciones; además, una CTE recursiva puede ser útil para iterar sobre múltiples distancias. Para este ejemplo, un polígono de filtro nos permite aislar fácilmente nuestra búsqueda en las cercanías de San Petersburgo, Florida. El polígono se prepara inicialmente a partir de WKT usando ST_GeomFromWKT, luego se transforma al SRID 5070 para que coincida con los datos de direcciones y edificios.
Para configurar los conjuntos de datos para la CTE recursiva, aplicamos un filtro espacial sobre nuestros datos al intersecar edificios y direcciones con el polígono de búsqueda, mostrando los edificios a continuación (las direcciones se manejan de manera similar).
La CTE recursiva a continuación itera sobre los edificios para identificar candidatos de direcciones dentro de 5, 10 y 15 metros. La tabla de resultados elimina las direcciones duplicadas en distancias sucesivas utilizando la siguiente expresión de ventana: QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
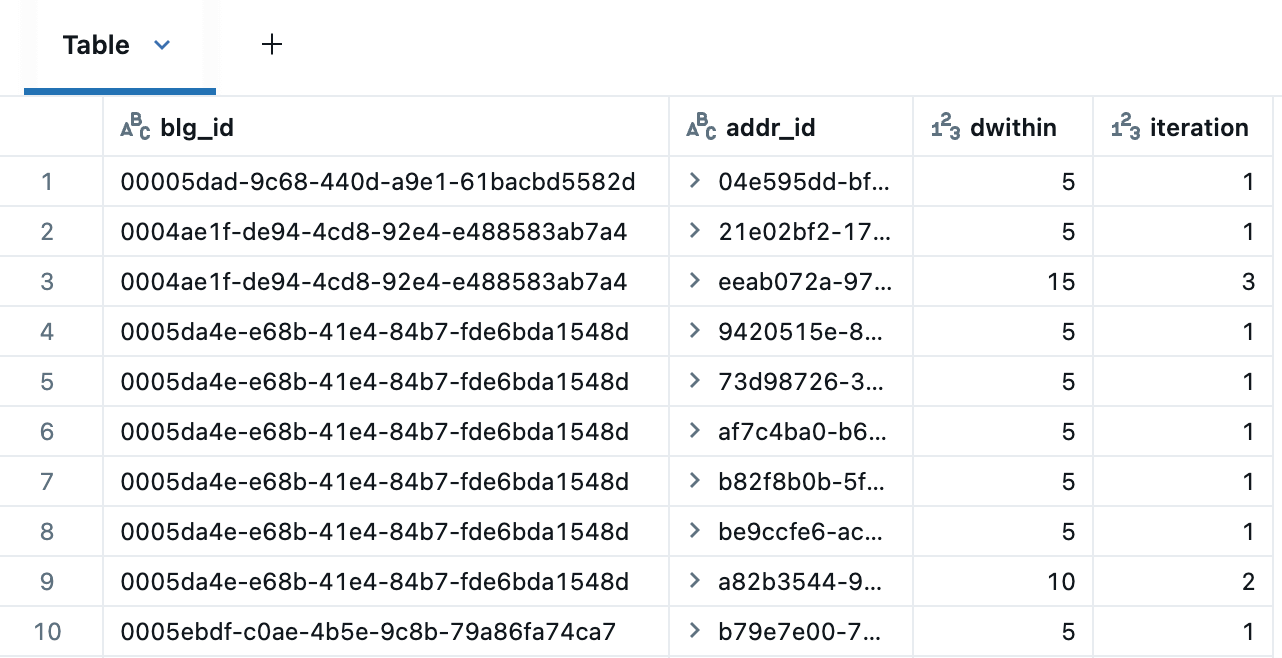
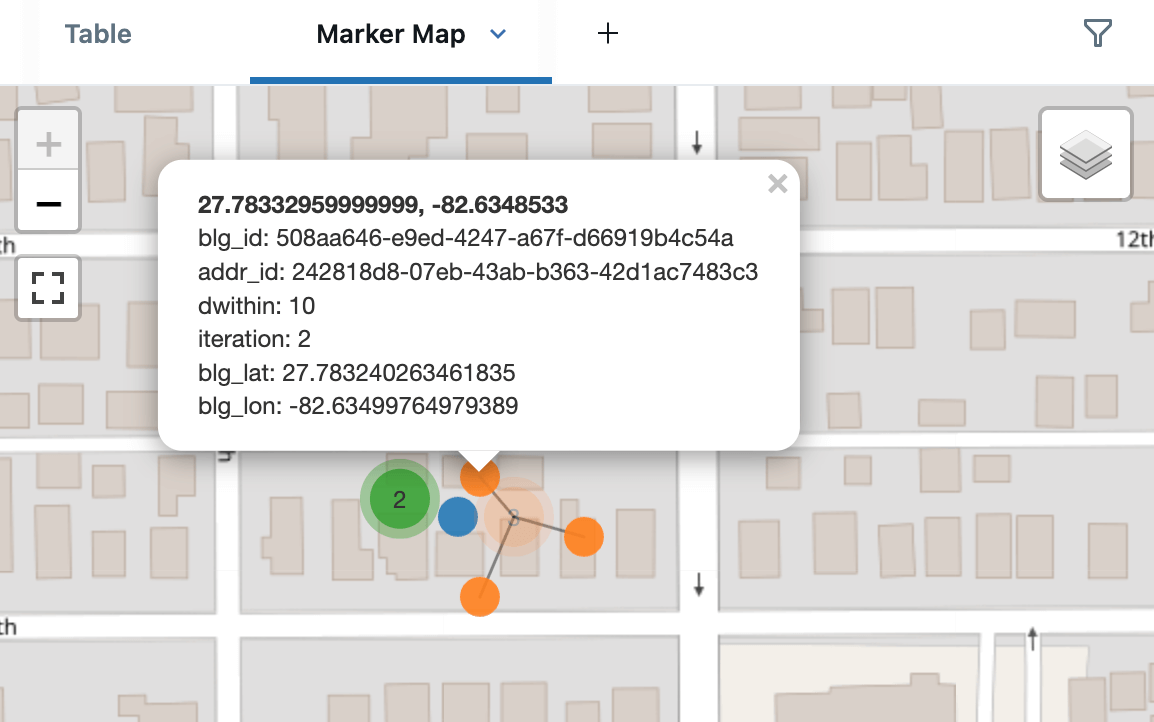
Aquí están los candidatos de direcciones alrededor de uno de los edificios, mostrando coincidencias a 5m (azul), 10m (naranja) y 15m (verde). Esto se renderiza usando los Marker Maps integrados de Databricks en modo de clúster, que separará los puntos cercanos para una visualización más fácil. Al crear un Dashboard, también podríamos haber utilizado AI/BI Point Maps, que admiten el filtrado cruzado y el drill-through.
Existen numerosos usos alternativos de las CTE recursivas para el procesamiento espacial, por ejemplo, implementando el algoritmo de Prim para construir un árbol de expansión mínima de sus puntos de entrega.
4. Medición de distancias entre ubicaciones
La proximidad es un concepto central en el análisis espacial porque la distancia a menudo determina la fuerza o relevancia de las relaciones entre ubicaciones. Ya sea identificando el hospital más cercano, analizando la competencia entre tiendas o mapeando patrones de desplazamiento, comprender la cercanía de las características entre sí proporciona un contexto crítico.
Continuando con nuestro conjunto de datos de ejemplo, realizamos la misma operación de transformación Conus Albers en nuestras ciudades de Florida para medir sus distancias. Estamos midiendo desde el centro geométrico de las ciudades, generado usando la función: ST_Centroid.
Al calcular la distancia entre dos GEOMETRÍAS, hay varias funciones diferentes a considerar:
- ST_Distance - Devuelve la distancia cartesiana en las unidades de las GEOMETRÍAS proporcionadas, calculando la ruta en línea recta basada en sus coordenadas x e y, como si la Tierra fuera plana.
- ST_DistanceSphere - Devuelve la distancia esférica (siempre en metros) entre dos GEOMETRÍAS de puntos, medida en el radio medio del elipsoide WGS84 de la Tierra, asumiendo que los puntos de coordenadas tienen unidades de grados, por ejemplo, SRID 4326 sería válido pero no SRID 5070.
- ST_DistanceSpheroid - Devuelve la distancia geodésica (siempre en metros) entre dos GEOMETRÍAS de puntos en el elipsoide WGS84 de la Tierra; también, asumiendo que los puntos de coordenadas tienen unidades de grados. Nuevamente, SRID 4326, o cualquier otro SRID con unidades en grados, serían entradas válidas para este ejemplo.
Los diversos cálculos de distancia se aplican entre city1 y city2 con ST_Distance utilizado para las GEOMETRÍAS en 5070, luego ST_DistanceSphere y ST_DistanceSpheroid para las GEOMETRÍAS en 4326.
Entre las funciones de distancia, anticiparíamos que ST_DistanceSpheriod (mediciones basadas en la forma elipsoidal de la Tierra) sería la más precisa en este caso, seguida de ST_DistanceSphere (las mediciones asumen que la Tierra es una esfera perfecta). Tenga en cuenta que ST_Distance es más útil cuando se trabaja con sistemas de referencia de coordenadas proyectadas o cuando la curvatura de la Tierra se puede ignorar. A pesar de que SRID 5070 está en metros, podemos ver los efectos de los cálculos cartesianos en distancias más grandes. ST_Distance generalmente no sería una opción adecuada para SRID 4326, dado que la distancia cubierta por un grado de longitud cambia drásticamente a medida que se mueve del ecuador hacia los polos, por ejemplo, 1 grado de longitud difiere hasta en 6 km solo dentro del estado de Florida.
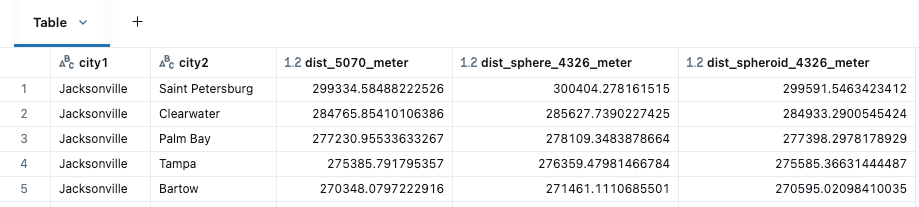
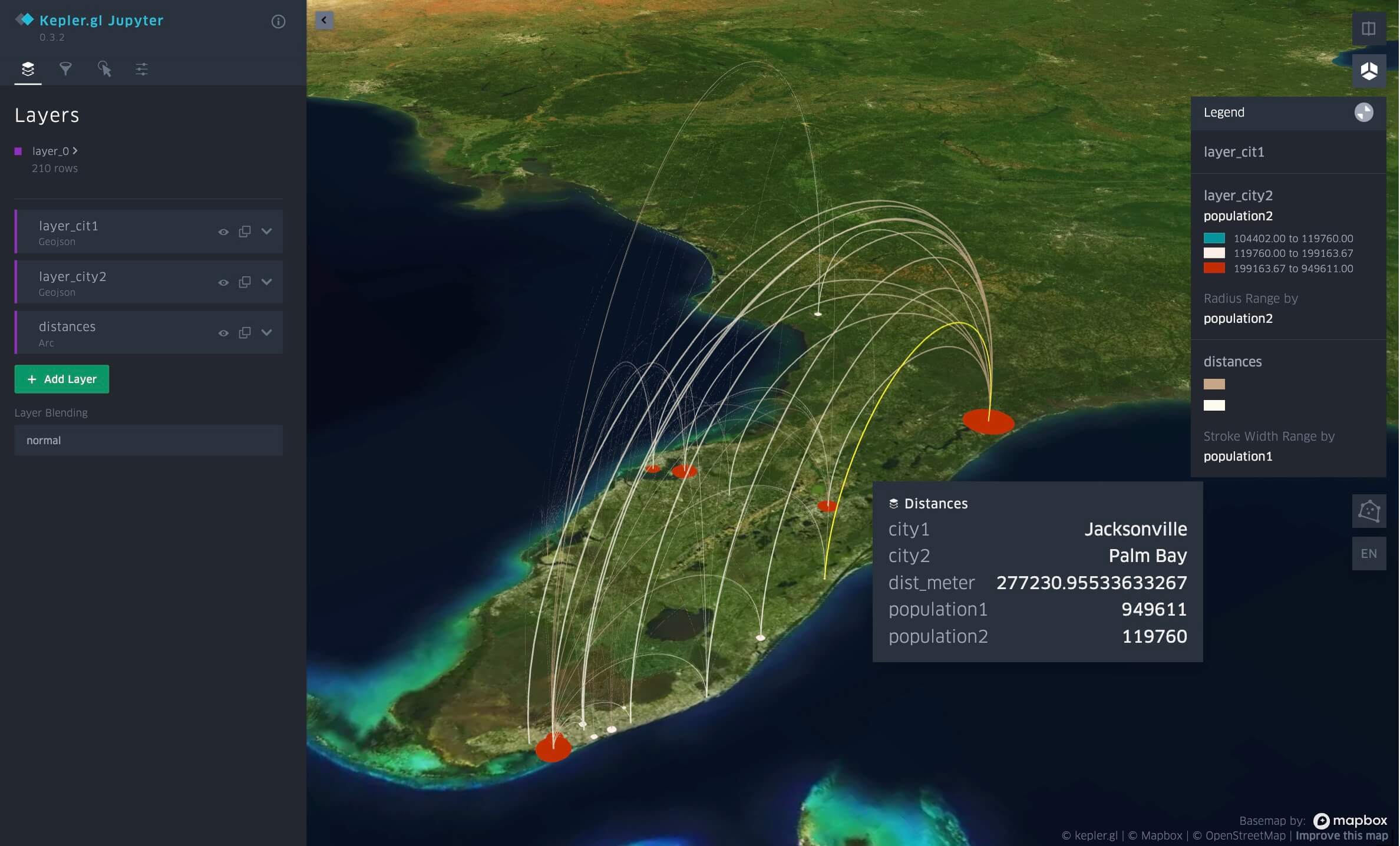
Proximidad por distancia entre ciudades de Florida, visualizada en Databricks Notebook con kepler.gl.
Spatial SQL incluye más de 80 funciones, lo que permite a los clientes realizar operaciones comunes de datos espaciales con simplicidad y escala. Impulsados por Spatial SQL, los clientes ahora están comenzando a cambiar su enfoque para administrar e integrar con sistemas GIS:
“Los datos espaciales están en el núcleo de todo lo que hacemos en OSPRI, ya sea Trazabilidad de Ganado, Erradicación de Enfermedades o Manejo de Plagas. Databricks Spatial SQL nos permite integrar completamente Databricks con todo nuestro trabajo. Estos avances nos permiten trasladar grandes tareas de modelado espacial basadas en escritorio a una plataforma donde están más cerca de los datos y se pueden ejecutar en paralelo, a gran velocidad. Las semanas de iteraciones entre los límites operativos se pueden ejecutar cómodamente en uno o dos días, lo que reduce nuestro tiempo de toma de decisiones. Estas nuevas funciones también nos permiten hacer de Databricks la capa de integración entre nuestros sistemas transaccionales y nuestra plataforma GIS, asegurando que pueda ser informada por datos de toda la organización sin compromisos.” - Campbell Fleury, Gerente de Productos de Datos e Información, OSPRI Nueva Zelanda
¿Qué sigue?
Hay mucho que puedes hacer con Spatial SQL en Databricks, y más por venir, incluyendo nuevas expresiones y uniones espaciales más rápidas. Si deseas compartir qué expresiones ST adicionales necesitas, por favor completa esta breve encuesta.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.