Introducción a la predicción de series temporales con IA generativa
por Ryuta Yoshimatsu , Puneet Jain y Bryan Smith
Introducción a la predicción de series temporales con IA generativa
La predicción de series temporales ha sido un pilar de la planificación de recursos empresariales durante décadas. Las predicciones sobre la demanda futura guían decisiones críticas como el número de unidades a almacenar, el personal a contratar, las inversiones de capital en infraestructura de producción y cumplimiento, y la fijación de precios de bienes y servicios. Las previsiones de demanda precisas son esenciales para estas y muchas otras decisiones empresariales.
Sin embargo, las previsiones rara vez son perfectas, si es que lo son alguna vez. A mediados de la década de 2010, muchas organizaciones que lidiaban con limitaciones computacionales y acceso limitado a capacidades avanzadas de pronóstico informaron de precisiones de pronóstico de solo 50-60%. Pero con la mayor adopción de la nube, la introducción de tecnologías mucho más accesibles y la mejora del acceso a fuentes de datos externas como datos meteorológicos y de eventos, las organizaciones están comenzando a ver mejoras.
A medida que entramos en la era de la IA generativa, una nueva clase de modelos, denominados transformadores de series temporales, parece capaz de ayudar a las organizaciones a lograr aún más mejoras. De manera similar a los grandes modelos de lenguaje (como ChatGPT) que se destacan en la predicción de la siguiente palabra en una oración, los transformadores de series temporales predicen el siguiente valor en una secuencia numérica. Con la exposición a grandes volúmenes de datos de series temporales, estos modelos se vuelven expertos en captar patrones sutiles de relaciones entre los valores de estas series con éxito demostrado en una variedad de dominios.
En este blog, proporcionaremos una introducción de alto nivel a esta clase de modelos de pronóstico, destinada a ayudar a gerentes, analistas y científicos de datos a desarrollar una comprensión básica de cómo funcionan. Luego, proporcionaremos acceso a una serie de notebooks creados en torno a conjuntos de datos disponibles públicamente que demuestran cómo las organizaciones que alojan sus datos en Databricks pueden aprovechar fácilmente varios de los modelos más populares para sus necesidades de pronóstico. Esperamos que esto ayude a las organizaciones a aprovechar el potencial de la IA generativa para lograr mejores precisiones de pronóstico.
Comprendiendo los Transformadores de Series Temporales
Los modelos de IA generativa son una forma de red neuronal profunda, un modelo complejo de machine learning dentro del cual un gran número de entradas se combinan de diversas maneras para llegar a un valor predicho. La mecánica de cómo el modelo aprende a combinar entradas para llegar a una predicción precisa se denomina la arquitectura de un modelo.
El avance en las redes neuronales profundas que ha dado lugar a la IA generativa ha sido el diseño de una arquitectura de modelo especializada llamada transformador. Si bien los detalles exactos de cómo los transformadores difieren de otras arquitecturas de redes neuronales profundas son bastante complejos, la cuestión simple es que el transformador es muy bueno para captar las relaciones complejas entre valores en secuencias largas.
Para entrenar un transformador de series temporales, una red neuronal profunda adecuadamente arquitectada se expone a un gran volumen de datos de series temporales. Después de haber tenido la oportunidad de entrenar con millones, si no miles de millones, de valores de series temporales, aprende los patrones complejos de relaciones que se encuentran en estos conjuntos de datos. Cuando luego se expone a una serie temporal previamente no vista, puede utilizar este conocimiento fundamental para identificar dónde existen patrones de relaciones similares dentro de la serie temporal y predecir nuevos valores en la secuencia.
Este proceso de aprendizaje de relaciones a partir de grandes volúmenes de datos se denomina preentrenamiento. Debido a que el conocimiento adquirido por el modelo durante el preentrenamiento es altamente generalizable, los modelos preentrenados, denominados modelos fundacionales, pueden emplearse contra series temporales no vistas sin entrenamiento adicional. Dicho esto, el entrenamiento adicional con los datos propietarios de una organización, un proceso denominado ajuste fino (fine-tuning), puede en algunos casos ayudar a la organización a lograr una precisión de pronóstico aún mayor. De cualquier manera, una vez que se considera que el modelo está en un estado satisfactorio, la organización simplemente necesita presentarlo con una serie temporal y preguntar: ¿qué sigue?
Abordando Desafíos Comunes de Series Temporales
Si bien esta comprensión de alto nivel de un transformador de series temporales puede tener sentido, la mayoría de los profesionales de pronóstico probablemente tendrán tres preguntas inmediatas. Primero, si bien dos series temporales pueden seguir un patrón similar, pueden operar en escalas completamente diferentes, ¿cómo supera un transformador ese problema? Segundo, dentro de la mayoría de los modelos de series temporales existen patrones de estacionalidad diarios, semanales y anuales que deben considerarse, ¿cómo saben los modelos que deben buscar esos patrones? Tercero, muchas series temporales están influenciadas por factores externos, ¿cómo se pueden incorporar estos datos en el proceso de generación de pronósticos?
El primero de estos desafíos se aborda estandarizando matemáticamente todos los datos de series temporales utilizando un conjunto de técnicas denominadas escalado. La mecánica de esto es interna a la arquitectura de cada modelo, pero esencialmente los valores entrantes de la serie temporal se convierten a una escala estándar que permite al modelo reconocer patrones en los datos basándose en su conocimiento fundamental. Las predicciones se realizan y luego se devuelven a la escala original de los datos originales.
En cuanto a los patrones estacionales, en el corazón de la arquitectura del transformador se encuentra un proceso llamado autoatención (self-attention). Si bien este proceso es bastante complejo, fundamentalmente este mecanismo permite al modelo aprender el grado en que los valores previos específicos influyen en un valor futuro dado.
Si bien eso suena como la solución para la estacionalidad, es importante entender que los modelos difieren en su capacidad para captar patrones de estacionalidad de bajo nivel según cómo dividen las entradas de series temporales. A través de un proceso llamado tokenización, los valores en una serie temporal se dividen en unidades llamadas tokens. Un token puede ser un único valor de serie temporal o una secuencia corta de valores (a menudo denominada parche).
El tamaño del token determina el nivel más bajo de granularidad en el que se pueden detectar patrones estacionales. (La tokenización también define la lógica para tratar los valores faltantes). Al explorar un modelo en particular, es importante leer la información, a veces técnica, sobre la tokenización para comprender si el modelo es apropiado para sus datos.
Finalmente, con respecto a las variables externas, los transformadores de series temporales emplean una variedad de enfoques. En algunos, los modelos se entrenan tanto con datos de series temporales como con variables externas relacionadas. En otros, los modelos se arquitectan para comprender que una sola serie temporal puede estar compuesta por múltiples secuencias paralelas y relacionadas. Independientemente de la técnica precisa empleada, se puede encontrar cierto soporte limitado para variables externas con estos modelos.
Un Breve Vistazo a Cuatro Transformadores Populares de Series Temporales
Con una comprensión de alto nivel de los transformadores de series temporales, tomemos un momento para observar cuatro modelos populares de transformadores de series temporales fundacionales:
Chronos
Chronos es una familia de modelos de pronóstico de series temporales preentrenados y de código abierto de Amazon. Estos modelos adoptan un enfoque relativamente ingenuo para el pronóstico al interpretar una serie temporal como un lenguaje especializado con sus propios patrones de relaciones entre tokens. A pesar de este enfoque relativamente simplista, que incluye soporte para valores faltantes pero no para variables externas, la familia de modelos Chronos ha demostrado resultados impresionantes como solución de pronóstico de propósito general (Figura 1).

Figura 1. Métricas de evaluación para Chronos y otros modelos de pronóstico aplicados a 27 conjuntos de datos de referencia (de https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM es un modelo fundacional de código abierto desarrollado por Google Research, preentrenado en más de 100 mil millones de puntos de series temporales del mundo real. A diferencia de Chronos, TimesFM incluye mecanismos específicos para series temporales en su arquitectura que permiten al usuario ejercer un control detallado sobre cómo se organizan las entradas y salidas. Esto tiene un impacto en cómo se detectan los patrones estacionales, pero también en los tiempos de cálculo asociados con el modelo. TimesFM ha demostrado ser una herramienta de pronóstico de series temporales muy potente y flexible (Figura 2).
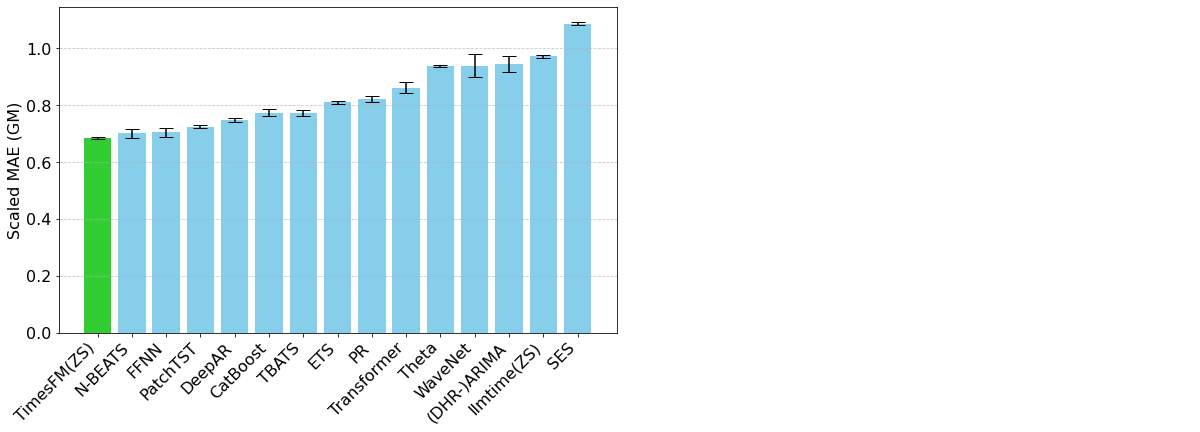
Figura 2. Métricas de evaluación para TimesFM y varios otros modelos frente al conjunto de datos Monash Forecasting Archive (de https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, desarrollado por Salesforce AI Research, es otro modelo fundacional de código abierto para la predicción de series temporales. Entrenado con "27 mil millones de observaciones que abarcan 9 dominios distintos", Moirai se presenta como un pronosticador universal capaz de admitir tanto valores faltantes como variables externas. Los tamaños de parche variables permiten a las organizaciones ajustar el modelo a los patrones estacionales de sus conjuntos de datos y, cuando se aplican correctamente, han demostrado funcionar bastante bien frente a otros modelos (Figura 3).

Figura 3. Métricas de evaluación para Moirai y varios otros modelos frente al Monash Time Series Forecasting Benchmark (de https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT es un modelo propietario con soporte para variables externas (exógenas) pero no para valores faltantes. Centrado en la facilidad de uso, TimeGPT se aloja a través de una API pública que permite a las organizaciones generar predicciones con tan solo una línea de código. Al comparar el modelo con 300.000 series únicas en diferentes niveles de granularidad temporal, se demostró que el modelo producía resultados impresionantes con una latencia de predicción muy baja (Figura 4).
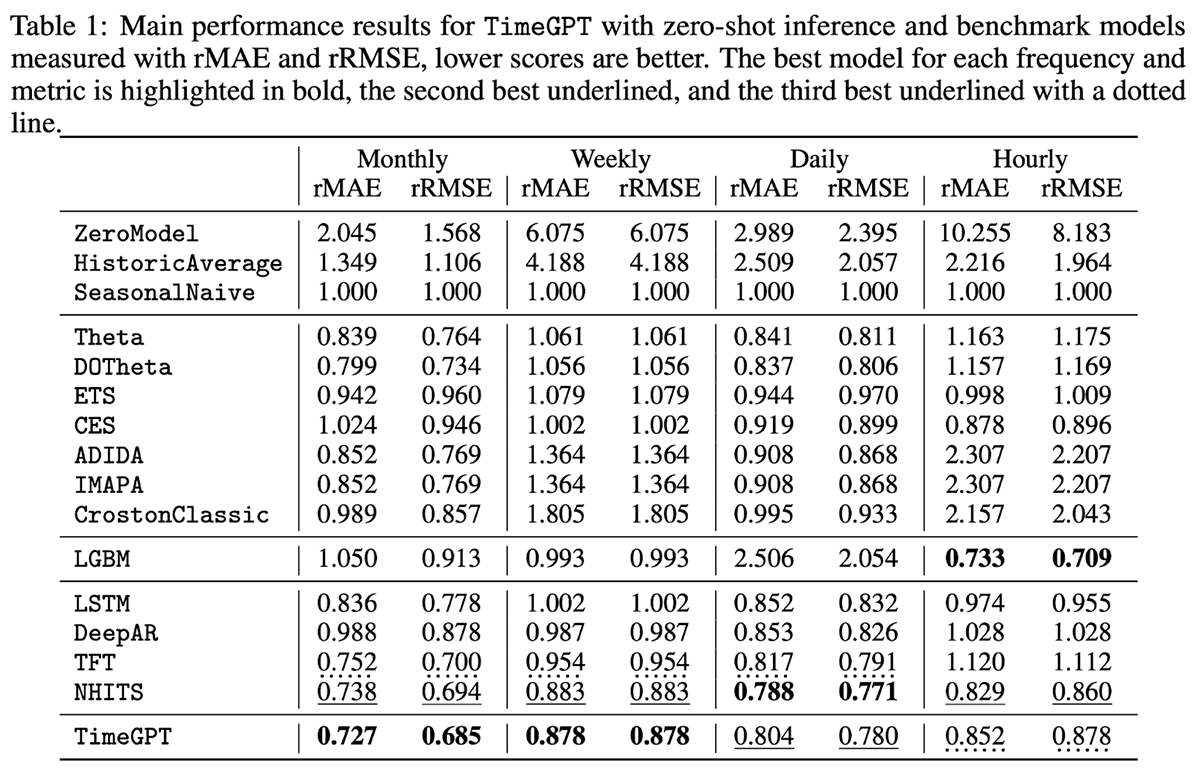
Figura 4. Métricas de evaluación para TimeGPT y varios otros modelos frente a 300.000 series únicas (de https://arxiv.org/pdf/2310.03589)
Cómo empezar con Transformer Forecasting en Databricks
Con tantas opciones de modelos y más por venir, la pregunta clave para la mayoría de las organizaciones es: ¿cómo empezar a evaluar estos modelos utilizando sus propios datos propietarios? Al igual que con cualquier otro enfoque de predicción, las organizaciones que utilizan modelos de predicción de series temporales deben presentar sus datos históricos al modelo para crear predicciones, y esas predicciones deben evaluarse cuidadosamente y, finalmente, implementarse en sistemas posteriores para hacerlas accionables.
Debido a la escalabilidad de Databricks y al uso eficiente de los recursos en la nube, muchas organizaciones lo han utilizado durante mucho tiempo como base para su trabajo de predicción, produciendo decenas de millones de predicciones a diario e incluso con mayor frecuencia para ejecutar sus operaciones comerciales. La introducción de una nueva clase de modelos de predicción no cambia la naturaleza de este trabajo, simplemente proporciona a estas organizaciones más opciones para hacerlo dentro de este entorno.
Eso no quiere decir que no haya algunas novedades con estos modelos. Basados en una arquitectura de red neuronal profunda, muchos de estos modelos funcionan mejor cuando se emplean en una GPU y, en el caso de TimeGPT, pueden requerir llamadas a API a una infraestructura externa como parte del proceso de generación de predicciones. Pero fundamentalmente, el patrón de alojar los datos históricos de series temporales de una organización, presentar esos datos a un modelo y capturar la salida en una tabla consultable permanece sin cambios.
Para ayudar a las organizaciones a comprender cómo pueden utilizar estos modelos dentro de un entorno Databricks, hemos reunido una serie de notebooks que demuestran cómo se pueden generar predicciones con cada uno de los cuatro modelos descritos anteriormente. Los profesionales pueden descargar libremente estos notebooks y emplearlos en su entorno Databricks para familiarizarse con su uso. El código presentado puede adaptarse a otros modelos similares, proporcionando a las organizaciones que utilizan Databricks como base para sus esfuerzos de predicción opciones adicionales para utilizar IA generativa en sus procesos de planificación de recursos.
Comience hoy mismo con Databricks para la modelización de predicciones con esta serie de notebooks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.